随着大语言模型(LLM)正日益成为现代应用的核心驱动力,支撑其运行的基础设施也必须持续进化,以满足日益苛刻的性能、扩展性与成本要求。在生产环境中部署LLM面临着一系列独特挑战:模型资源需求巨大、推理工作负载波动显著、用户对低延迟与高吞吐量的期望也水涨船高。传统的负载均衡器与API网关在常规Web服务中表现出色,但在智能路由人工智能推理流量方面,却往往缺乏必要的“模型感知”能力。

Kthena Router正是为解决这些挑战而生。它是一个面向Kubernetes环境的独立推理路由器,专为LLM服务工作负载设计。与通用代理或负载均衡器不同,Kthena Router具备模型感知能力,能够依据推理引擎的实时指标做出智能路由决策,从而实现复杂的流量管理策略,显著提升吞吐量、降低延迟并优化运营成本。
Kthena Router能够无缝集成到现有的API网关基础设施中,同时提供一系列为AI工作负载量身打造的高级功能:
- 模型感知路由:利用来自vLLM、SGLang、TGI等推理引擎的实时指标进行智能决策。
- LoRA感知负载均衡:智能地将请求路由至已加载了所需LoRA Adapter的Pod,将原本数百毫秒的Adapter交换延迟降至近乎为零。
- 高级调度算法:集成了前缀缓存(Prefix Cache)感知、KV缓存(KV Cache)感知以及公平性调度等多种策略。
- PD分离支持:原生支持xPyD(x-prefill/y-decode)部署模式。
Kthena Router以独立二进制文件形式部署,依赖极简,确保了轻量化的运行与简单的部署流程。它持续监控推理引擎的各项指标,实时掌握模型状态,包括当前已加载的LoRA适配器、KV缓存利用率、请求队列长度以及延迟指标(TTFT/TPOT)。正是这种实时感知能力,使路由器能够做出传统负载均衡器根本无法实现的最优路由选择。
架构
Kthena Router采用了清晰、模块化的架构设计,专为高性能与可扩展性打造。系统由多个核心组件协同工作,共同提供智能的请求路由能力。
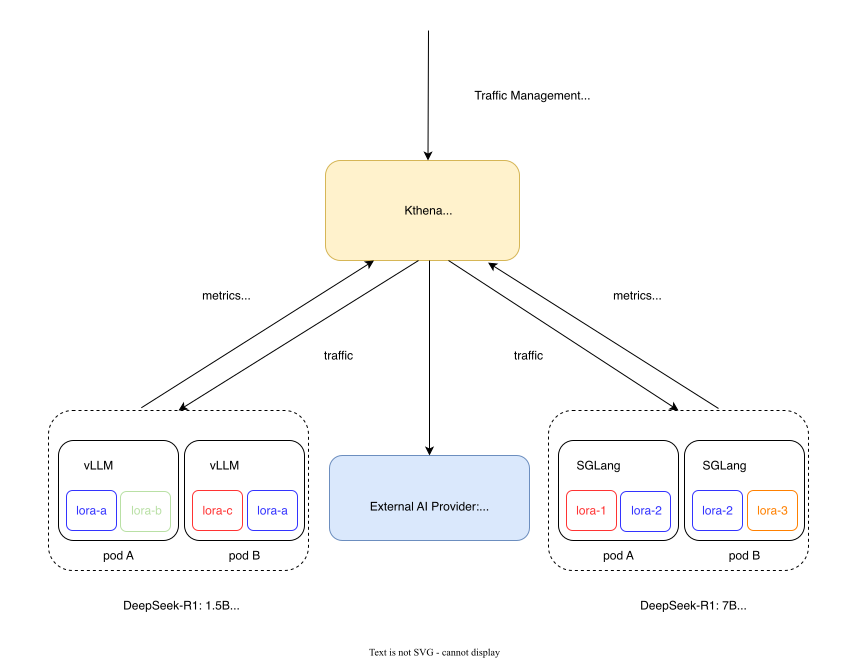
核心组件概述
Router:作为核心执行框架,负责接收、处理并转发请求。它协调所有组件间的交互,并管理从请求接收到最终响应的完整生命周期。
Listener:管理HTTP/HTTPS监听器,处理指定端口上的传入流量。它为不同协议提供灵活的配置选项,支持绑定到多个地址以服务各类请求,并能高效处理连接,支持流式与非流式两种请求模式。
Controller:这是一个云原生/IaaS组件,用于同步和处理Kubernetes中的Pod及自定义资源(CR),例如 ModelRoute 和 ModelServer。Controller监控集群变化,并相应地更新Router的内部状态,确保路由决策始终基于最新的集群拓扑。
Filters:包含两个关键子模块,用于在请求到达后端前进行处理:
- Auth:处理流量认证与授权,支持API Key、JWT等方式。
- RateLimit:管理全面的速率限制策略,包括输入token和输出token限制。
Backend:提供一个访问各类推理引擎的抽象层。它屏蔽了vLLM、SGLang、TGI等不同框架在指标接口访问方法和命名约定上的差异,为调度器提供统一的接口。
Metrics Fetcher:持续从运行模型的Pod上的推理引擎端点收集实时指标,包括:
- KV缓存利用率
- 当前加载的LoRA适配器
- 请求队列长度
- 延迟指标(TTFT, TPOT)
Datastore:一个统一的数据存储层,提供对 ModelServer 到Pod的关联关系、基础模型/LoRA配置以及运行时指标的高效访问。它作为所有路由相关信息的中央存储库,并支持实时更新的回调机制。
Scheduler:作为Router的“大脑”,它实现了复杂的流量调度算法。由一个调度框架和一系列可插拔的调度算法插件构成。该框架负责集成并运行不同的调度插件,对与目标 ModelServer 关联的Pod集合进行过滤和评分,最终选出全局最优的Pod作为访问目标。
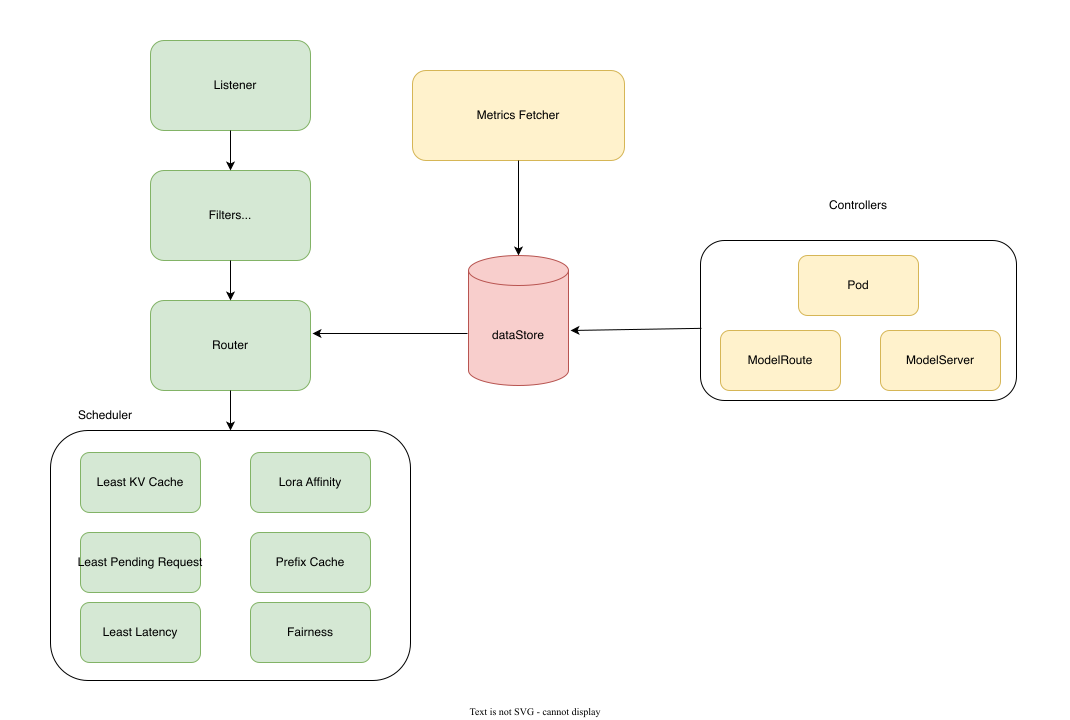
Router API
Kthena Router的路由行为由两个关键的自定义资源定义(CRD)控制:ModelServer 和 ModelRoute。这些声明式API允许您使用熟悉的Kubernetes模式来定义复杂的路由策略。
ModelRoute
ModelRoute 根据请求特征定义流量路由规则。它依据模型名称、LoRA适配器、HTTP头部或其他条件,决定应由哪个 ModelServer 来处理请求。
关键字段包括:
- ModelName:用于匹配传入请求的模型名称。
- LoRAAdapters:此路由所支持的LoRA适配器名称列表。
- Rules:有序的路由规则列表,每条规则包含:
- ModelMatch:匹配请求的条件(如Headers、URI等)。
- TargetModels:请求应被路由到的
ModelServer 列表,可附加权重。
- RateLimit:基于token的速率限制配置。
有关 ModelRoute 的更多详细信息,请参阅 定义。
ModelServer
ModelServer 定义了推理服务的实例及其访问策略。它标识了运行模型的Pod,指定了所使用的推理框架,并定义了如何处理流量。
关键字段包括:
- WorkloadSelector:通过标签选择器标识Pod,并支持PD(Prefill-Decode)组规范。
- Model:指定该服务托管的基础模型名称。
- InferenceFramework:指明推理引擎类型(如vLLM, SGLang, TGI等)。
- WorkloadPort:定义推理服务监听的端口。
- TrafficPolicy:配置超时、重试策略以及其他流量处理行为。
- KVConnector:为PD分离部署指定KV连接器类型(如HTTP, Nixl, LMCache, Mooncake)。
有关 ModelServer 的更多详细信息,请参阅 定义。
对于分层服务产品,可以根据HTTP头部信息将不同用户路由到不同大小的模型:
apiVersion: networking.serving.volcano.sh/v1alpha1
kind: ModelRoute
metadata:
name: deepseek-multi-models
namespace: default
spec:
modelName: "deepseek-multi-models"
rules:
- name: "premium"
modelMatch:
headers:
user-type:
exact: premium
targetModels:
- modelServerName: "deepseek-r1-7b"
- name: "default"
targetModels:
- modelServerName: "deepseek-r1-1-5b"
---
apiVersion: networking.serving.volcano.sh/v1alpha1
kind: ModelServer
metadata:
name: deepseek-r1-7b
namespace: default
spec:
workloadSelector:
matchLabels:
app: deepseek-r1-7b
workloadPort:
port: 8000
model: "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
inferenceEngine: "vLLM"
trafficPolicy:
timeout: 10s
---
apiVersion: networking.serving.volcano.sh/v1alpha1
kind: ModelServer
metadata:
name: deepseek-r1-1-5b
namespace: default
spec:
workloadSelector:
matchLabels:
app: deepseek-r1-1-5b
workloadPort:
port: 8000
model: "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
inferenceEngine: "vLLM"
trafficPolicy:
timeout: 10s
流量处理过程:
- 请求到达,模型名称为
"deepseek-multi-models"。
- Router检查HTTP头部中是否存在
user-type: premium。
- 如果是高级用户,则路由到更大的7B模型以获得更好的回答质量。
- 如果是普通用户,则路由到更小的1.5B模型以提高成本效率。
测试高级路由:
curl http://$ROUTER_IP/v1/completions \
-H "Content-Type: application/json" \
-H "user-type: premium" \
-d '{"model": "deepseek-multi-models", "prompt": "Explain quantum computing"}'
这个示例演示了 ModelRoute 和 ModelServer 这两种CRD如何通过标准的Kubernetes API,提供对复杂路由策略灵活且声明式的控制。
核心功能
智能调度插件
真正将Kthena Router与传统负载均衡器区分开来的,是其一套模型感知调度插件。这些插件利用推理引擎的实时指标来做出智能路由决策,从而显著提升性能。
LoRA 亲和性调度
LoRA(低秩适应)适配器允许在不重新部署基础模型的情况下微调模型行为。然而,加载和卸载适配器会引入额外的延迟。LoRA亲和性插件通过智能路由来最小化这种开销。
工作原理:
- 持续跟踪每个Pod上当前加载的LoRA适配器状态。
- 将需要特定LoRA的请求优先路由到已加载该适配器的Pod。
- 通过缓存命中来避免适配器的加载/卸载操作。
优势:
- 消除适配器切换延迟:将数百毫秒的切换延迟降至接近零。
- 提高响应速度:避免了动态加载适配器带来的额外等待时间。
- 支持多LoRA场景:高效处理混合了多个LoRA适配器的工作负载。
Least Latency 调度
Least Latency插件根据实时延迟指标,将请求路由到响应最快的Pod,从而优化用户体验和整体生成速度。
工作原理:
- 持续监控推理引擎的延迟指标。
- 综合评估TTFT(首Token时间)和TPOT(每输出Token时间)。
- 将请求路由到延迟最低的Pod。
- 动态适应Pod性能的变化。
关键指标:
- TTFT(首Token时间):影响流式响应和用户的感知延迟。
- TPOT(每输出Token时间):决定整体生成速度和吞吐量。
Least Request 调度
Least Request插件基于请求队列状态进行负载均衡,将请求路由到最不繁忙的Pod,确保负载均匀分布。
工作原理:
- 监控推理引擎的
num_requests_running(运行中请求数)和 num_requests_waiting(等待中请求数)指标。
- 计算每个Pod的总待处理工作负载(运行中 + 等待中)。
- 将新请求路由到负载最低的Pod。
- 动态平衡各Pod间的工作分配。
优势:
- 防止热点:避免部分Pod过载而其他Pod空闲。
- 均衡负载:确保所有Pod的利用率趋于一致。
- 提高吞吐量:通过最优的负载分配最大化整体处理能力。
GPU Usage 调度
GPU Usage插件基于GPU缓存使用率进行负载均衡,将请求路由到缓存压力较小的Pod,从而优化GPU资源利用率。
工作原理:
- 持续监控每个Pod的GPU缓存使用率指标。
- 计算可用缓存容量:
score = (1.0 - GPU缓存使用率) × 100。
- 优先将请求路由到GPU缓存使用率较低的Pod。
- 避免因缓存耗尽导致的性能下降和请求失败。
优势:
- 防止缓存溢出:避免将请求发送到缓存已满的Pod。
- 提高稳定性:减少因缓存不足导致的请求失败和重试。
- 负载均衡:确保GPU缓存资源在所有Pod间均衡使用。
- 提升吞吐量:保持各Pod在最优缓存利用率区间运行。
Prefix Cache 感知调度
现代推理引擎(如vLLM和SGLang)实现了Prefix Cache(前缀缓存)机制,将常用的Prompt前缀缓存起来以避免重复计算。Prefix Cache感知插件通过智能路由策略最大化前缀缓存的命中率,显著提升推理性能。
核心机制:
- 滚动哈希生成:
- 将Prompt按固定大小(默认64字节)划分为块。
- 使用xxHash算法为每个块生成滚动哈希。
- 每个哈希值结合前一个块的哈希,形成依赖链。
- 当哈希匹配时,能保证所有前置块也已匹配,实现高效的前缀识别。
- 内存缓存存储:
- 使用三层映射结构:模型 → 哈希 → Pod。
- 采用LRU(最近最少使用)缓存策略管理内存。
- 自动清理过期条目,保持缓存效率。
- 默认缓存容量为50,000条,返回Top-5最佳匹配。
- 智能评分算法:
- 根据前缀匹配长度对Pod进行评分。
- 评分公式:
score = (匹配块数 / 总块数) × 100。
- 优先选择具有最长匹配前缀的Pod,从而提高缓存命中率和推理效率。
适用场景:
- 多轮对话系统,用户在同一会话中发送多个相关请求。
- 具有固定系统提示词(System Prompt)的应用场景。
- 问答系统中频繁使用相同上下文的查询。
KV Cache Aware 调度
KV Cache Aware插件是一个高级调度插件,它通过基于Token级别的块匹配来智能路由请求,最大化KV缓存的命中率。与仅监控缓存利用率不同,该插件实现了细粒度的内容感知调度,性能提升显著。
核心机制:
- Token块哈希:
- 将传入的Prompt分词后,按固定大小(默认128个Token)划分为块。
- 使用SHA-256为每个块生成标准化的哈希值。
- 支持可配置的最大块数(默认128块),以平衡性能和准确性。
- 分布式缓存跟踪:
- 使用Redis维护全局的“块到Pod”映射关系。
- Redis键格式:
matrix:kv:block:{model}@{hash}
- 每个键存储包含该块的Pod列表及其缓存时间戳。
- 通过Redis Pipeline批量查询实现高效的分布式协调。
- 智能评分算法:
- 查找每个Token块在哪些Pod上已被缓存。
- 从第一个块开始计算连续匹配的长度。
- 优先选择具有最长连续匹配前缀的Pod。
- 评分公式:
score = (匹配块数 / 总块数) × 100。
- Tokenizer集成:
- 支持多种分词器后端(本地和远程vLLM)。
- 自动处理不同模型的分词差异。
- 确保一致的Token到块的映射关系。
优势:
- 精确匹配:不仅考虑缓存容量,还考虑实际缓存的内容。
- 避免冷启动:将请求路由到已经处理过相似Prompt的Pod。
- 提升吞吐量:减少重复计算,在长系统提示词场景下可实现2.73倍的吞吐量提升。
- 降低延迟:TTFT可降低73.5%,显著改善用户体验。
更多技术细节请参考 KV Cache Aware 插件设计文档。
插件配置
这些插件通过调度器框架协同工作。您可以通过Router配置来指定启用哪些插件及其相对权重。
调度器框架按顺序运行启用的插件:
- 过滤(Filter):插件过滤掉不合适的Pod(例如,缓存不足、未加载正确的LoRA适配器)。
- 评分(Score):插件根据其特定条件对剩余的Pod进行评分。
- 选择(Select):为请求选择得分最高的Pod作为最终目标。
这种可组合的架构允许您根据特定的工作负载需求来定制路由行为。
公平性调度
公平性调度确保基于Token消耗历史,在不同用户之间公平地分配资源。
工作原理:
- 跟踪每个用户在每个模型上的累积Token使用量(输入 + 输出)。
- 根据历史使用量的反比来分配请求的优先级。
- 将请求排队并按优先级顺序处理。
- 防止任何单个用户垄断系统资源。
用例:
- 具有共享基础设施的多租户平台。
- 采用公平共享策略的研究集群。
- 需要基于使用量进行节流的SLA驱动型系统。
PD分离支持
针对高级部署模式,Kthena Router原生支持PD分离(xPyD),即将计算密集型的Prefill(预填充)阶段与Token生成的Decode(解码)阶段分离。
工作原理:
- 从
ModelServer CRD中识别PD组的配置。
- 将Prefill请求路由到专门为Prefill优化的Pod。
- 通过可配置的连接器(如HTTP、Nixl等)传输KV缓存状态。
- 将Decode请求路由到专门为Decode优化的Pod。
- 整个过程对客户端完全透明。
优势:
- 优化硬件利用率:通过将工作负载特征与硬件特性匹配。
- 减少延迟:为每个阶段使用专用的硬件资源。
- 提高成本效率:通过更精细的资源分配。
基于Token的RateLimit
Kthena Router提供全面的速率限制功能,以保护您的推理基础设施免受过载,并确保用户间资源的公平分配。
- Input Token限制:控制每个用户或API密钥的输入Prompt Token速率。
- Output Token限制:限制生成的Token数量,以管理计算成本。
- 本地RateLimit:基于每个Router实例实施限制。
- 全局RateLimit:使用Redis等中央存储,在所有Router实例之间实施共享的限制策略。
可观测性
Kthena Router提供了为生产级LLM服务设计的全面可观测性功能:
- 指标(Metrics):在
/metrics 端点暴露详细指标,包括请求延迟、Token消耗、调度器插件性能以及速率限制统计信息。
- 结构化访问日志:以JSON或文本格式记录完整的请求生命周期,包括路由决策、用时分布和Token跟踪。
- 调试端点(Debug Endpoint):提供
/debug/config_dump/* API,用于检查内部状态、ModelRoute/ModelServer配置以及实时Pod指标等。
- 标准集成:与Prometheus、Grafana、ELK等可观测性技术栈无缝协作,用于监控、告警和故障排查。
性能
Kthena Router中的ScorePlugin模块利用可配置的可插拔架构,实现对推理请求的多维评分和智能路由。为了演示智能调度的影响,我们基于DeepSeek-R1-Distill-Qwen-7B模型构建了一个标准化的基准测试环境,以评估不同调度策略在长短系统提示词场景下的性能。
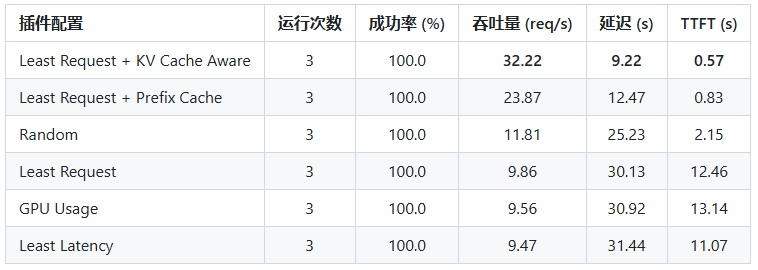
实验结果表明,在长系统提示词场景中,KV Cache Aware Plugin + Least Request Plugin 的组合实现了 2.73倍的吞吐量提升,并将 TTFT延迟降低了73.5%,显著优化了整体推理服务性能,验证了缓存感知调度对大规模模型推理的核心价值。
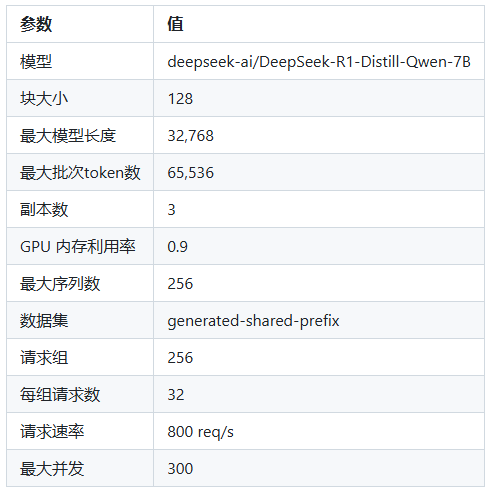
实验设置
使用 DeepSeek-R1-Distill-Qwen-7B 模型构建了标准化的基准测试环境。
表1:实验环境配置
Long System Prompt Scenario(4096 token)
表2:性能指标 - Long System Prompt
结论
Kthena Router代表了LLM服务基础设施的一次重要飞跃。通过超越简单的负载均衡,实现了模型感知、指标驱动的智能路由,它释放了以往无法获得的显著性能提升和成本节约潜力。
Kthena是开源项目,您现在就可以开始使用。Kthena文档 提供了全面的安装、配置和部署指南。Kthena-router 示例目录 则包含了面向常见场景的开箱即用配置。
无论您是在运行单个模型,还是管理一个复杂的多租户LLM平台,Kthena Router都提供了最大化性能、最小化成本以及提供卓越用户体验所需的智能路由功能。想了解更多关于系统架构和后端技术实践的讨论,欢迎访问 云栈社区 与更多开发者交流。
 发表于 2026-3-1 06:35:41
|
查看: 284|
回复: 0
发表于 2026-3-1 06:35:41
|
查看: 284|
回复: 0
