在生产环境中,我们曾遇到一个棘手的问题:海量的 HTTP 请求都设置了 Connection: close 头,这直接导致短连接数量激增,最终拖垮了服务器的性能。
更令人困惑的是,即便我们尝试在服务器端修改代码,移除收到的 Connection: close 头部,问题依然存在,治标不治本。
问题根因:谁打破了连接复用的默契?
简单来说,问题的核心在于 HTTP 持久连接(Keep-Alive)的约定被意外打破。
Connection: close 这个头部,就像是客户端发给服务器的一个明确信号:“咱们这次合作完就散伙,别再联系了”。按照 RFC 规范,服务器在收到这个指令后,会在完成本次请求的响应后,主动关闭底层的 TCP 连接。
关键在于,这个关闭行为是由操作系统内核的 TCP 协议栈根据标准语义自动执行的。这意味着,无论你的应用层代码(Go、Java 或其它语言)多么努力地想去忽略或移除这个头部,底层的网络库一旦识别出“关闭”的意图,就会启动 TCP 连接的挥手流程。应用层对此过程无能为力,无法单方面阻止一个已经达成共识的连接终结。
底层原理:一个头部如何触发四次挥手?
让我们深入底层,看看当 Connection: close 出现时,究竟发生了什么。
以下是 Connection: close 触发 TCP 连接关闭的完整流程:
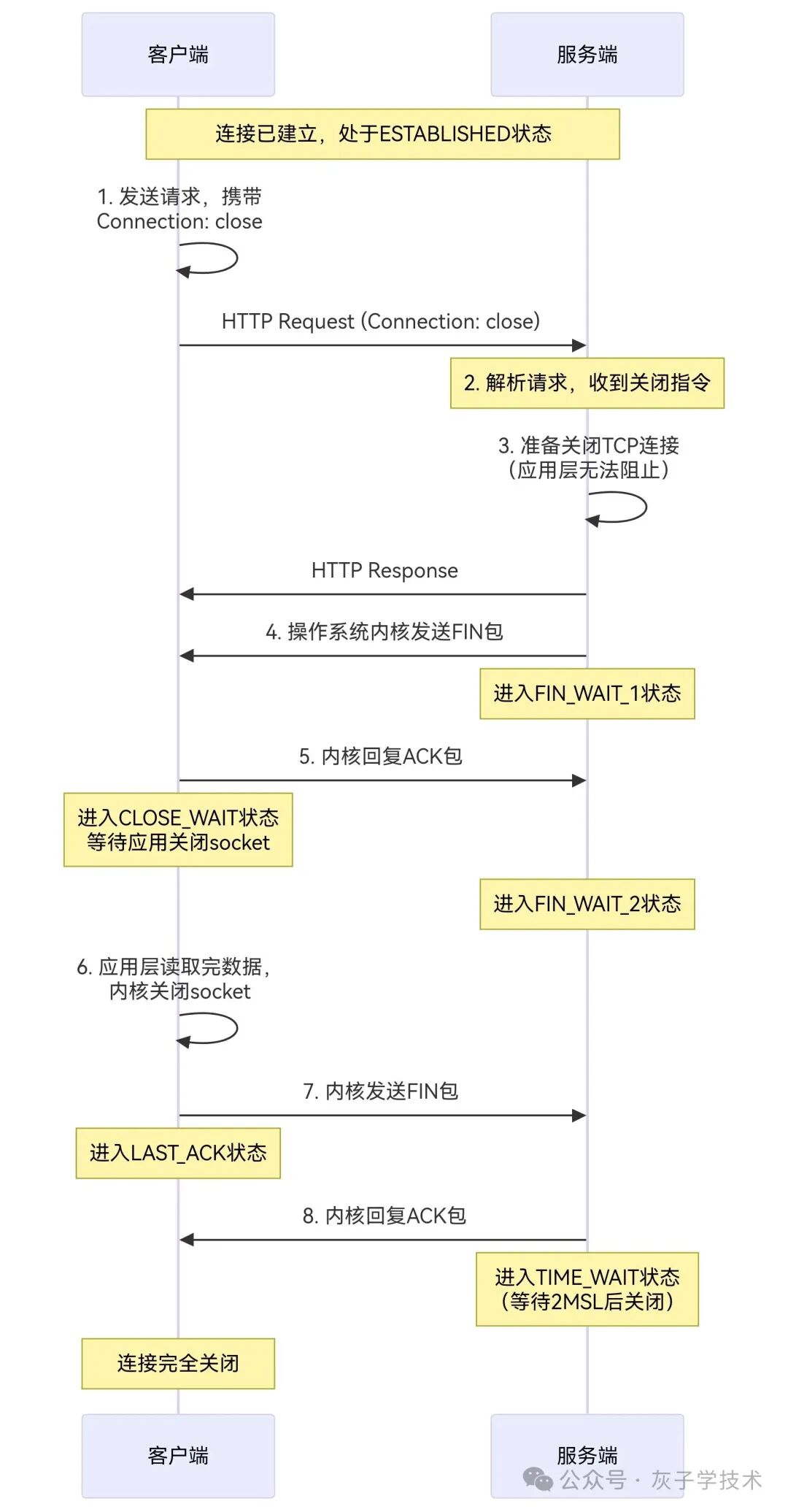
原理分步说明:
- 指令下达:客户端在 HTTP 请求头中明确设置了
Connection: close。
- 服务端响应:服务端在解析请求头后,知晓了客户端的关闭意图。它会在返回的 HTTP 响应头中也携带
Connection: close 作为确认,并更关键地,通知操作系统的 TCP 协议栈准备断开此连接。
- 发起挥手:在 HTTP 响应数据全部发送完毕后,服务端的 TCP 协议栈会主动发起 TCP 四次挥手过程,向客户端发送
FIN 包,正式开始关闭连接。
- 连接销毁:四次挥手完成后,这个 TCP 连接被内核彻底销毁。对于服务端应用层的连接池而言,它所管理的那个底层 Socket 句柄已经失效,不可复用。
这个过程清晰地展示了 TCP/IP 协议栈如何严格遵循应用层(HTTP)的指令,完成连接的优雅终止。
对连接池的毁灭性打击:从“复用”到“耗尽”
连接池设计的核心价值在于复用。它预先建立并维护一批 TCP 连接,当新请求到来时,直接从池中取出一个可用的连接,从而避免了重复进行 TCP 三次握手和可能的 TLS 握手,大幅降低了延迟和系统开销。
健康的连接池工作流程如下:
+---------------------+
| 客户端发起请求 |
+---------------------+
|
v
+---------------------+
| 连接池有空闲连接? |
+---------------------+
| |
| 是 | 否
v v
+-----------+ +-----------+
| 复用现有 | | 创建新 |
| 连接 | | 连接 |
+-----------+ +-----------+
| |
+----------------+
|
v
+---------------------+
| 请求/响应完成 |
+---------------------+
|
v
+---------------------+
| 连接标记为“空闲” |
+---------------------+
|
v
+---------------------+
| 放回连接池等待复用 |
+---------------------+
而当 Connection: close 介入后,流程彻底紊乱:
+-------------------------------+
| 客户端发起请求(携带close头) |
+-------------------------------+
|
v
+-------------------------------+
| 连接池有空闲连接? |
+-------------------------------+
| |
| 是 | 否
v v
+-----------------+ +-----------------+
| 复用现有连接 | | 创建新连接 |
+-----------------+ +-----------------+
| |
+------------------+
|
v
+-------------------------------+
| 请求/响应完成 |
+-------------------------------+
|
v
+-------------------------------+
| 连接被强制关闭 |
| (四次挥手) |
+-------------------------------+
|
v
+-------------------------------+
| 从连接池中移除并销毁 |
+-------------------------------+
|
v
+-------------------------------+
| 连接池可用连接数 -1 |
+-------------------------------+
|
v
+-------------------------------+
| 新请求到来,若无空闲连接 |
| 则需创建新连接,开销大 |
+-------------------------------+
恶性循环是如何形成的?
- 正常流程:未设置
close 头的请求完成后,连接会被安全归还至连接池,标记为空闲,等待下一次复用。
- 异常流程:携带
Connection: close 的请求,即便它“借用”了连接池里的一个现存连接,在请求结束后,该连接也会被强制关闭并从池中物理移除。
- 系统雪崩:在高并发场景下,若大量请求都携带此头部,连接池将陷入“只出不进”的境地,池内连接被迅速耗尽。系统为了响应后续请求,不得不以极高的频率创建全新的 TCP 连接。创建连接涉及内核资源分配、网络往返延迟等高昂开销,这会直接导致:
- 系统吞吐量急剧下降。
- 请求响应时间变慢。
- 最终,如果连接创建的速度赶不上被关闭的速度,连接池将完全枯竭,新请求要么长时间排队,要么直接超时失败。
为什么服务端“移除close头”的尝试会失败?
很多开发者的第一反应是:我在服务端拦截这个请求头,把它删掉不就行了?但答案是否定的。
问题出在职责分层上:
- HTTP 头部处理发生在应用层(你的 Go
net/http 处理器或 Java Servlet)。
- TCP 连接的最终关闭由操作系统内核的协议栈执行。
当服务端网络库(如 Go 的 net 包)在解析 HTTP 请求的早期阶段看到 Connection: close 时,它已经按照 HTTP/1.1 的语义做出了“此连接不可复用”的判定。这个判定会传递给内核。之后,即便你的业务逻辑代码删除了这个头部,也无法撤销内核已经接到的“关闭”指令。响应结束后,关闭流程仍会照常启动。
解决方案:从防御到根治
面对这一问题,我们需要从不同层面寻找解决方案。
1. 根治源头:修复客户端配置(首选方案)
最根本的方法是确保客户端行为正确。客户端应该:
- 停止发送
Connection: close 头部。
- 改为发送
Connection: Keep-Alive,或者遵循 HTTP/1.1 默认规范,不发送该头(即默认保持持久连接)。
- 正确配置客户端的 HTTP 连接池,启用 Keep-Alive 并设置合理的参数,如最大连接数、空闲连接超时时间等,以实现真正的连接复用。
2. 防御攻击:在代理层进行过滤和识别
如果问题源于不可控的客户端或恶意流量(如 CC 攻击),可以在流量入口处设置防护:
- 在反向代理(如 Nginx)或 API 网关层,识别并过滤携带
Connection: close 的异常请求。
- 可以设计更复杂的策略:代理层先移除可疑请求的
Connection: close 头,将其转发给专门的安全识别服务进行判断,只有被判定为正常的流量才会被导向后端应用服务器。
3. 运维与监控建议
- 主动监控:使用
netstat、ss 等命令持续监控服务器上 CLOSE_WAIT 状态连接的数量。如果该数值异常偏高且持续增长,这通常是客户端未正常关闭连接(或大量发送 close 头)的强烈信号,应触发告警。
- 合理配置服务端:虽然无法阻止关闭,但确保服务端自身的连接池、线程池等参数配置合理,能在一定程度上缓解突发流量带来的冲击。
理解 Connection: close 如何绕过应用逻辑、直接与内核交互并“掏空”连接池,是解决此类性能问题的关键。在微服务与分布式架构盛行的今天,高效的连接管理对于系统稳定性至关重要。如果你在开发中遇到过类似的网络疑难杂症,欢迎到 云栈社区 的“网络/系统”或“后端&架构”板块与大家交流探讨,共同拆解更多底层技术黑盒。
 发表于 2026-3-1 16:25:51
|
查看: 118|
回复: 0
发表于 2026-3-1 16:25:51
|
查看: 118|
回复: 0
