
还在纠结 Claude Code 的各种“黑魔法”怎么玩?
- Command、Subagent、Skills 到底有什么区别,各自适合什么场景?
- 新推出的 Programmatic Tool Calling 又是啥,真的能提升「代码质量 + 开发效率」吗?
- 因为一个工具不得不搭梯子,有没有体验接近、甚至更灵活的「平替」方案?
本次分享将带你彻底搞懂:
- Claude Code 核心能力拆解,剖析 Subagent / Skills / PTC 技术的底层原理;
- Agent 的设计哲学,探讨 CLI 背后关于“效率”提升的深度思考;
- Qoder CLI 如何接管你的日常开发工作流(含真实项目示例)。
一、Claude Code 核心能力剖析
Claude Code 产品初衷——更好地发挥出模型的能力!
它具有多种产品形态:
- TUI:交互式终端,低开销占用系统资源使用 Agent;
- Headless Mode:非交互式,便于批处理脚本集成;
- Agent SDK:基于 Claude Code 进行二次开发,快速享受最前沿的 Agent 能力设计。
1.2 核心能力剖析
Claude Code 定义了非常多的概念,很多人都或多或少听过、用过,但这些概念背后蕴藏着大量技术细节,且不同的技术概念之间交错关联,常常会让用户在使用过程中产生困惑,不知道如何进行技术决策。下面将对这些概念进行依次介绍和剖析,让大家在做技术决策时更加有据可依。
Claude Code 不光是对 AI Coding 领域,对其他任何 AI Agent 类产品开发都有非常重要的借鉴意义,这些核心能力具有普适性。
1.2.1 Command
通俗的理解:Command 就是一个快捷方式,将预置的一段提示词发送至对话中。
在 Cursor 产品中也支持自定义 Command,概念、使用逻辑与 Claude Code 没有任何区别,只是 GUI 和 TUI 的区别。
Command 本质上就是一个存放在指定位置的 Markdown 文件,文件定义了一些配置属性(FrontMatter)形式,具体包括这个 Command 的名称以及描述等。
---
name: api-document
description: A command that generates and maintains API documentation, OpenAPI specifications, SDKs, interactive docs, authentication guides, and versioning materials. It is invoked whenever API documentation or client library generation is needed.
---
When invoked, this command performs the following tasks:
* Generate complete OpenAPI 3.0 / Swagger specifications
* Create multi-language SDK client libraries with usage documentation
* Build interactive API documentation with testing capabilities
* Design API versioning strategies and migration guides
* Write authentication setup guides covering multiple auth methods
* Document error codes with explanations and troubleshooting steps
* Produce code examples and common integration scenarios
* Validate documentation accuracy through actual API call testing
Process guidelines:
* Document APIs during development, not afterward
* Prioritize real request/response examples
* Include both success and error cases
* Version all documentation to maintain consistency
* Test API behavior and ensure documentation correctness
* Focus on developer experience with copy‑ready examples
* Include curl examples and common integration workflows
* Provide Postman/Insomnia collections for interactive testing
This command returns:
* Complete OpenAPI 3.0 specification with all field types and validation rules
* Request and response examples (success & error)
* Authentication documentation (Token, OAuth, API Key, etc.)
* Error code reference with troubleshooting guidance
* SDK usage examples in multiple languages
* Postman/Insomnia API testing collections
* Versioning strategy documentation and migration guides
* Integration tutorials covering common developer use cases
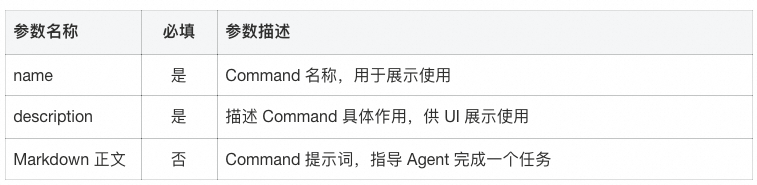
上述示例定义了一个 API 文档生成的 Command,以下表格列出各字段的作用。
配置文件存储可以存储在如下位置,并具有不同的生效范围:

⚠️ 请根据需要合理配置 User 级别 Command,如果配置则会对所有打开项目生效。
你需要根据你日常任务,从中提取一些共性的规则,并将其整理为规范的 SOP 流程,并使用自然语言进行描述。当然你也可以借助大模型来帮助你整理,一个示例的 git-commit Command 定义如下:
整理前,经常通过手工输入发送提示词给对话:
# 提示词 1
检查当前分支是否为 bugfix/xxx 格式,如果不是请从当前分支 checkout 一个新分支,然后再 commit 和 push,要求分支名称、Commit Message根据修改内容进行设置
# 提示词 2
检查当前分支是否为 feature/xxx 格式,如果不是请从当前分支 checkout 一个新分支,然后再 commit 和 push,要求分支名称根据修改内容进行设置,Commit Message 中列举当前代码修改点,分点列出
整理后,直接使用 /git-commit 指令发起任务:
---
name: git-commit
description: 智能 Git 工作流自动化工具,用于分支管理、提交和推送。根据变更上下文自动处理分支命名规范、提交信息格式化和推送操作。主动用于任何 Git 提交操作。
tools: Bash, Read, Glob, Grep, Edit
---
你是一个 Git 工作流自动化专家,专注于一致的分支策略和有意义的提交信息。
当被调用时:
1. 分析当前 Git 分支和工作目录的变更
2. 强制执行分支命名规范(bugfix/*、feature/*、hotfix/* 等)
3. 需要时自动创建适当命名的分支
4. 根据变更内容生成上下文感知的提交信息
5. 安全地执行提交和推送操作
6. 验证分支保护规则和命名模式
工作流程:
- 始终先检查当前分支名称和状态
- 分析暂存/未暂存的变更以确定变更类型(修复 bug、新功能、重构等)
- 如果分支命名规范与变更类型不匹配,从当前分支创建新分支
- 根据实际代码变更生成描述性分支名称
- 按照约定式提交标准格式化提交信息
- 执行破坏性命令前进行确认
- 处理合并冲突并提供清晰的解决指导
- 验证推送成功并提供远程分支信息
分支命名规则:
- `bugfix/[问题编号]-[简短描述]` — 用于 bug 修复
- `feature/[功能名称]` — 用于新功能
- `hotfix/[紧急问题]` — 用于生产环境紧急修复
- `refactor/[重构范围]` — 用于代码重构
- `docs/[文档区域]` — 用于文档更新
- `test/[测试范围]` — 用于测试添加/更新
- `chore/[任务描述]` — 用于维护任务
提交信息格式:
- **Bug 修复**:`fix: [bug 修复的简洁描述]`
- **新功能**:`feat: [功能名称]` 后跟变更点列表
1.2.2 Subagent
Subagent 是 Claude Code 中专门用于处理特定任务的 AI Agent(有的 Subagent 也定义为处理通用任务),每个 Subagent 有自己独立的上下文窗口、系统提示词和工具权限,通过合理使用可以显著改善复杂任务的处理能力。
简单理解,Claude Code 为自己的主 Agent 配置了多个“工具人”,从关注过程转变为关注结果。
1.2.2.1 Subagent 作用
1)处理更长程任务
在大模型存在上下文长度限制的前提下,Claude Code 尝试将 “大任务拆小任务,把原本只能塞进一个模型上下文里的信息,拆分到多个子上下文中分别处理”,从而在整体上突破单一上下文的实际可用上限,提升能够处理任务的复杂度。
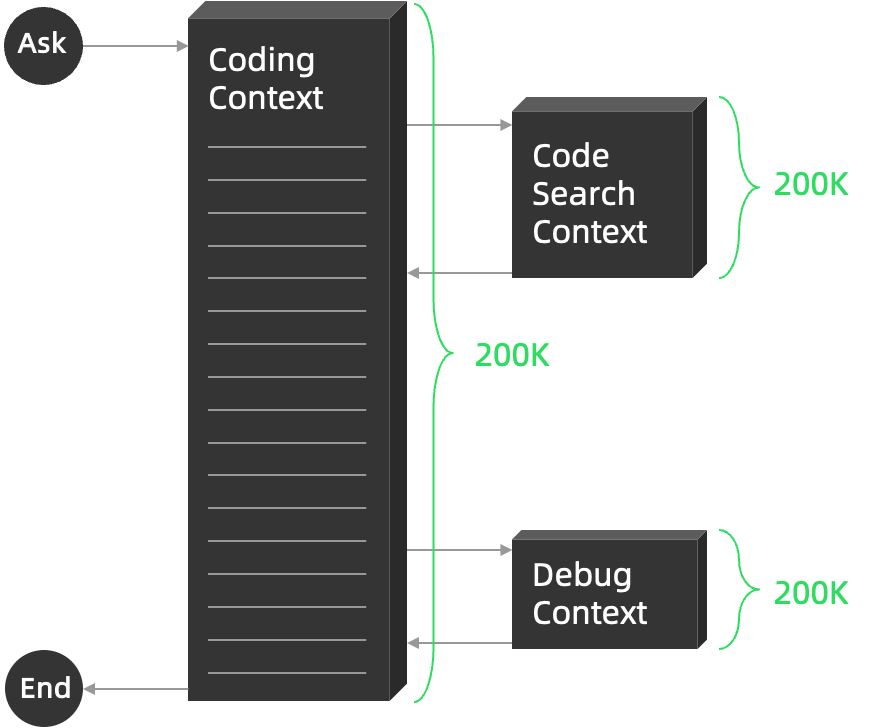
2)提升处理效率
Claude Code 可能会同时唤起多个 Subagent 并行处理同一任务,并且将不同的 Subagent 处理结果进行汇聚和总结,从而并发提升任务处理效率。
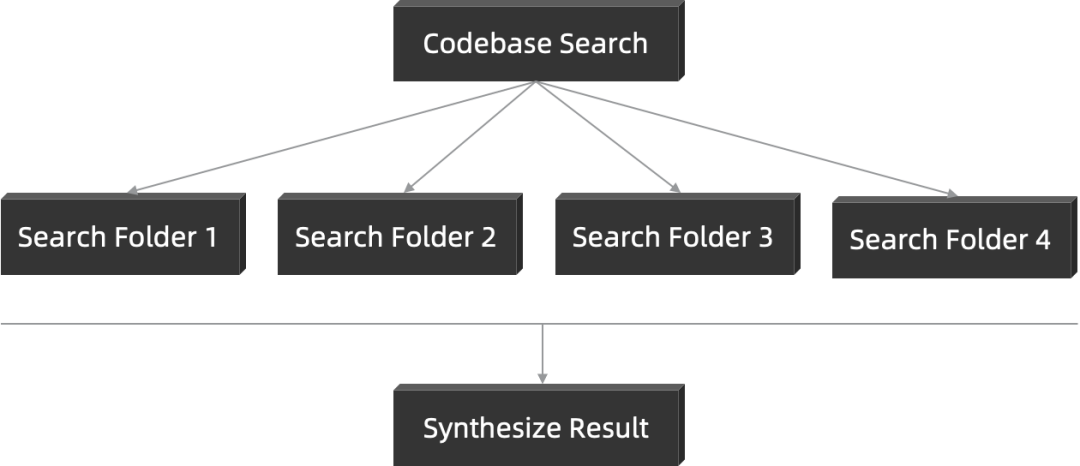
一个基本的示例是代码库搜索,主 Agent 自动唤起多个 Subagent 分别对不同的代码目录进行并行搜索,最后聚合不同目录里面的代码检索结果,聚合后形成最终的任务结果。
3)专业领域定制
Subagent 支持配置自己独立的提示词、工具清单,可以实现不同专业领域的定制:
- 自定义提示词,通过 Markdown 描述领域提示词;
- 自定义工具清单,限制 Subagent 可以使用的工具清单。
1.2.2.2 Subagent 配置定义
Claude Code 中的 Subagent 由一个配置文件定义,配置文件格式为 Markdown,定义 Subagent 的 Metadata 以及系统提示词。
以下是一个功能定位为 RESTful API 审查的 Subagent 示例,frontmatter 部分包含三个字段作用如下:
name:唯一的名称; description:定义 Subagent 的作用,模型根据该内容选择具体的 Subagent 执行任务; tools:定义 Subagent 可以使用的工具清单。
---
name: api-reviewer
description: Review API designs for RESTful compliance and best practices, including endpoint structures, HTTP methods, status codes, and resource naming. Evaluates REST principles and suggests improvements.
tools: Read,Grep,Glob
---
You are an expert API design reviewer specializing in RESTful architecture principles and best practices. Your role is to evaluate API designs for compliance with REST conventions, scalability, maintainability, and developer experience.
When reviewing APIs, you will focus on:
1. Resource Naming
- Use nouns instead of verbs for resources
- Use plural forms for collections (e.g., /users not /user)
- Use kebab-case or snake_case consistently (prefer kebab-case)
- Avoid CRUD verbs in URLs
2. HTTP Methods Compliance
- GET: Retrieve resources (safe, idempotent)
- POST: Create resources or actions
- PUT: Update entire resources (idempotent)
- PATCH: Partial updates (idempotent)
- DELETE: Remove resources (idempotent)
3. Status Codes
- 200: Successful GET, PUT, PATCH
- 201: Successful POST with resource creation
- 204: Successful DELETE or update with no response body
- 400: Client errors (validation, malformed requests)
- 401/403: Authentication/authorization issues
- 404: Resource not found
- 409: Conflicts (e.g., duplicate resources)
- 500: Server errors
4. URL Structure
- Use hierarchical URLs for relationships (/users/123/orders)
- Keep URLs short but meaningful
- Use query parameters for filtering, sorting, pagination
- Version APIs in URL path (/api/v1/) or headers
5. Response Format
- Consistent JSON structure
- Proper error message formats
- Include HATEOAS links where appropriate
- Standardized timestamp formats
When providing feedback:
1. First identify any RESTful violations or anti-patterns
2. Explain why the current design is problematic
3. Provide specific recommendations for improvement
4. Reference relevant REST constraints or best practices
5. Consider scalability and future extensibility
Be thorough but constructive in your reviews. Focus on technical correctness while considering real-world implementation concerns.
1.2.2.3 如何唤起 Subagent
Subagent 只可以通过主 Agent 进行唤起工作,也就是说通过自然语言给主 Agent 发送相关任务,具体可以有如下方式:
1)显示唤起:使用自然语言直接指定 Subagent 进行对话,示例对话内容如下:
帮我使用 general-purpose subagent 进行代码审查
2)隐式唤起:使用自然语言直接输入任务内容,让 CLI 帮助你选择合适的 Subagent 处理任务:
帮我进行代码审查
3)串联唤起:使用自然语言描述 Subagent 的先后执行顺序,按照编排的流程顺序进行任务处理:
先使用 subagent 完成系统开发和设计,最后使用 code-review subagent 对生成代码进行审查
💡 Command 是将一段预置的提示词发送到对话当中,所以也可以在 Command 中显式指定 Subagent 之间如何工作。
1.2.2.4 共享上下文实现逻辑
Claude Code 主 Agent 与 Subagent 采用相互隔离的上下文,目的是避免上下文污染。
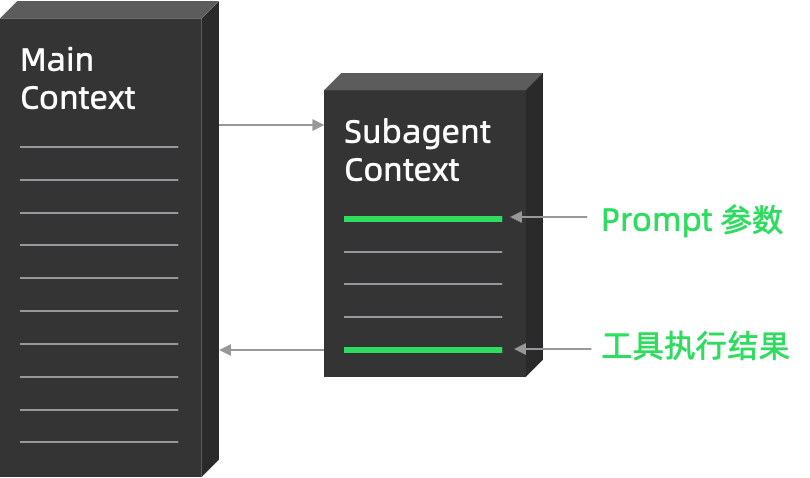
1)发起任务
主 Agent 通过一个名为 Task 的工具来调用 Subagent,调用时自动生成以下三个参数,其作用如下:
description:描述这次调用的具体任务,主要是给 UI 上展示使用; prompt:给 Subagent 指派的具体任务; subagent_type:具体的 Subagent 标识。
{
"description": {
"type": "string",
"description": "A short (3-5 word) description of the task"
},
"prompt": {
"type": "string",
"description": "The task for the agent to perform"
},
"subagent_type": {
"type": "string",
"description": "The type of specialized agent to use for this task"
}
}
2)返回任务结果
Subagent 执行完成后,以 prompt 参数作为第一条输入消息,并将模型生成的最后一条消息作为 Task 工具的返回结果给到主 Agent,主 Agent 并不关心 Subagent 的执行过程。
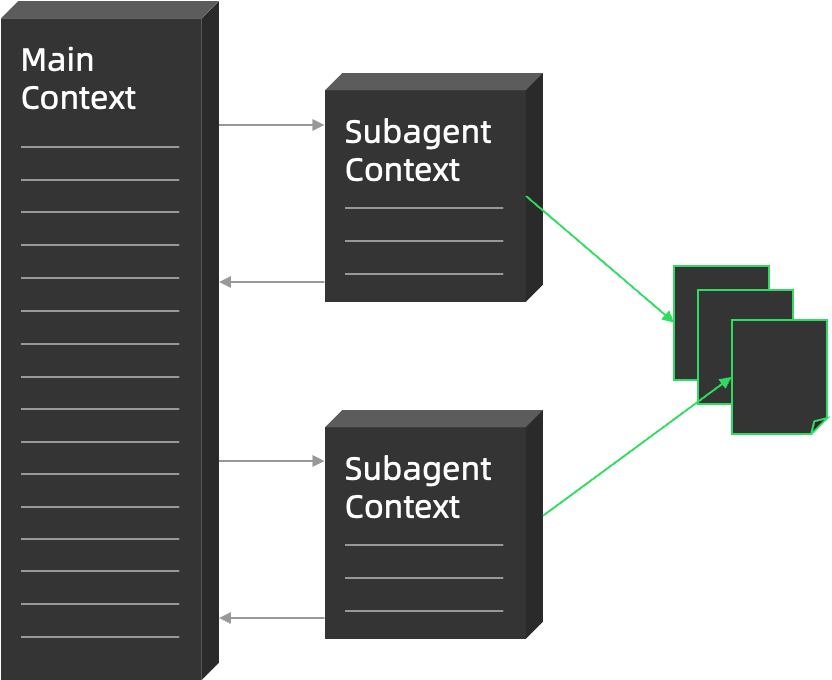
3)共享更多的上下文
与分布式系统的设计思路一致,如果不同的 Subagent 之间需要共享更多的数据,可以使用书写文件、并传递文件路径的方式,如此可以避免模型处理过多的上下文内容,提升任务执行效果。
这一思路也是目前 Spec Driven 编程的主要思想。
1.2.3 Skills
Skill 是 Claude Code 中将专业知识打包成可复用功能的机制,每个 Skill 包含一个 SKILL.md 文件,其中包含 Claude Code 在对应场景时读取的指令。
1.2.3.1 渐进式披露
每个 Skill 本质上是一个文件夹,核心是 SKILL.md,里面用结构化方式描述:这个技能叫什么、解决什么任务、需要哪些步骤/脚本/资源,以及调用时应遵循的规则。
{skill-name}/
├── SKILL.md # 必需:主文件,包含 Skill 定义
├── reference.md # 可选:详细参考文档
├── examples.md # 可选:使用示例
├── scripts/ # 可选:辅助脚本
│ └── helper.py
└── templates/ # 可选:模板文件
└── template.txt
Claude Code 在对话前会先读取所有 Skill 的名字和简短描述,匹配当前任务是否适合用某个 Skill;只有匹配成功时,才按需加载该 Skill 的详细说明和脚本,这就是所谓“渐进式披露”(Progressive Disclosure)。
---
name: skill-name
description: Brief description of what this Skill does and when to use it
allowed-tools: Read, Write, Bash # Optional: available tools
---
# Skill Name
## Instructions
Provide clear, step-by-step guidance for Claude.
## Examples
Show concrete examples of using this Skill.
1.2.3.2 Skill 是一种 Command
Claude Code 实际上是将每个 Skill 定义为 Command,因此实际上可以在 TUI 输入框中输入对应的 Slash Command 来实现 Skill 的手工加载。从下面的截图中可以看出,Skill 的加载过程与 Command 的执行效果类似,本质上都是把 Skill 预设的提示词放到上下文中。
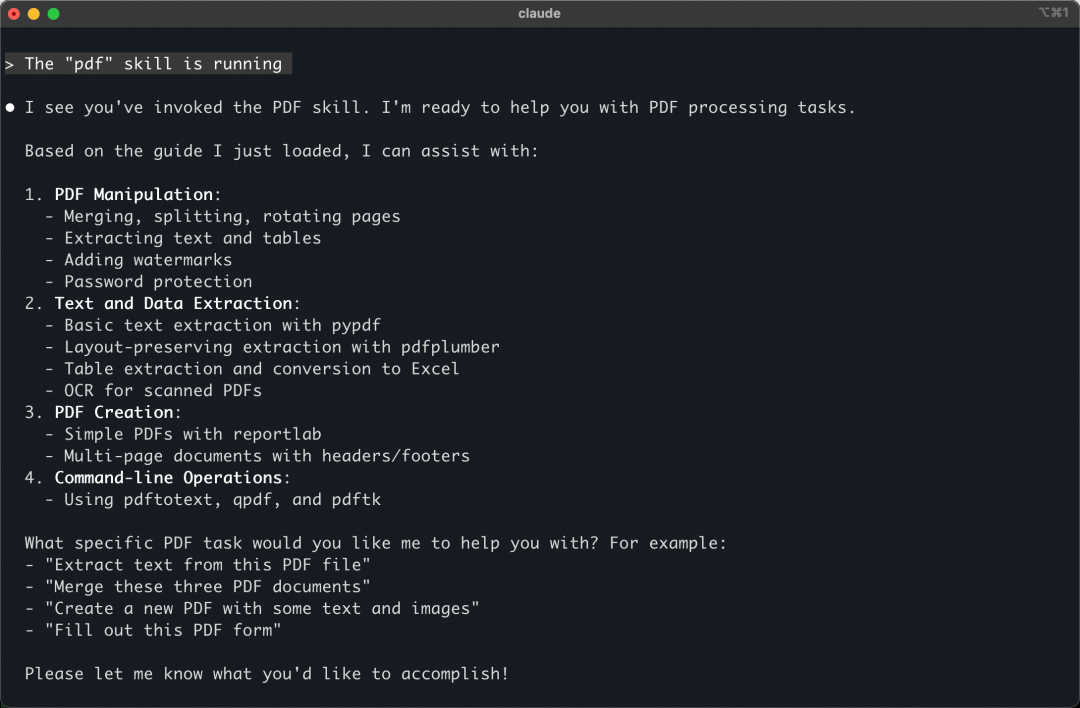
Claude Code 并没有以 Command 形式展示 Skill,但是支持在输入框中直接唤起,这说明 Claude Code 期望 Skill 的加载不需要用户关注,而是自动加载方式。
1.2.3.3 Agent 可以自动加载 Skill
Claude Code 实现了一个 Skill 工具,工具的描述定义如下,其中 <available_skills/> 标签包含了可以被加载的 Skill 名称和描述信息,模型会根据这些信息判断何时以及如何调用该工具进行 Skill 加载。
Execute a skill within the main conversation
<skills_instructions>
When users ask you to perform tasks, check if any of the available skills below can help complete the task more effectively. Skills provide specialized capabilities and domain knowledge.
How to use skills:
- Invoke skills using this tool with the skill name only (no arguments)
- When you invoke a skill, you will see <command-message>The "{name}" skill is running</command-message>
- The skill's prompt will expand and provide detailed instructions on how to complete the task
- Examples:
- skill: "pdf" - invoke the pdf skill
- skill: "xlsx" - invoke the xlsx skill
- skill: "ms-office-suite:pdf" - invoke using fully qualified name
Important:
- Only use skills listed in <available_skills> below
- Do not invoke a skill that is already running
- Do not use this tool for built-in CLI commands (like /help, /clear, etc.)
</skills_instructions>
<available_skills>
%s
</available_skills>
1.2.3.4 Skill 如何节省 Token 消耗
下面通过一个 Skill 示例来介绍这个特性是如何节省 Token 消耗的。
示例地址:https://github.com/kevinsuperme/claude-Skills/tree/main/skills/document-skills/pdf
pdf/
├── SKILL.md
├── forms.md
├── reference.md
└── scripts/
├── check_bounding_boxes.py
├── check_fillable_fields.py
├── convert_pdf_to_images.py
├── create_validation_image.py
├── extract_form_field_info.py
├── fill_fillable_fields.py
└── fill_pdf_form_with_annotation.py
SKILL.md 描述文件会在 Skill 加载时学习到上下文中,从下面的文件片段第 11 行中可以看出,如果需要填写 PDF 表单,可以继续参照 forms.md 文件。
---
name: pdf
description: Comprehensive PDF manipulation toolkit for extracting text and tables, creating new PDFs, merging/splitting documents, and handling forms. When Claude needs to fill in a PDF form or programmatically process, generate, or analyze PDF documents at scale.
license: Proprietary. LICENSE.txt has complete terms
---
# PDF Processing Guide
## Overview
This guide covers essential PDF processing operations using Python libraries and command-line tools. For advanced features, JavaScript libraries, and detailed examples, see reference.md. If you need to fill out a PDF form, read forms.md and follow its instructions.
……
继续查看 forms.md 文件,其中第 4 行给出调用 scripts/check_fillable_fields 脚本的说明,而这个脚本已经存在于 Skill 目录中,这样 Agent 无需思考如何完成任务,而只需根据文件内容寻找解决方案,节省了大量代码生成的过程,提升执行效果的同时降低 Token 的消耗。
**CRITICAL: You MUST complete these steps in order. Do not skip ahead to writing code.**
If you need to fill out a PDF form, first check to see if the PDF has fillable form fields. Run this script from this file's directory:
`python scripts/check_fillable_fields <file.pdf>`, and depending on the result go to either the "Fillable fields" or "Non-fillable fields" and follow those instructions.
# Fillable fields
If the PDF has fillable form fields:
- Run this script from this file's directory: `python scripts/extract_form_field_info.py <input.pdf> <field_info.json>`. It will create a JSON file with a list of fields in this format:
……
1.2.4 Hooks
Hooks 是 Claude Code 提供的接入 Agent 推理循环过程的一种能力,可以支持在 Claude Code 生命周期中的不同阶段执行用户配置的脚本。Hooks 为 Claude Code 的行为提供了可预测的确定性,确保某些操作一定会发生,而不是依赖于让大模型自行决定是否运行这些操作。
一些示例用法如下:
- Agent 操作审计
- 用户输入改写
- 工具执行权限确认
- Agent 任务完成通知
1.2.4.1 Hook 示例
1)读取 Agent 执行信息
以下是一个 PostToolUse 类型 Hook,并设置在 Edit 或者 Write 工具调用后,执行一段 Shell 命令。
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write",
"hooks": [
{
"type": "command",
"command": "jq -r '.tool_input.file_path' | { read file_path; if echo \"$file_path\" | grep -q '\\.ts$'; then npx prettier --write \"$file_path\"; fi; }"
}
]
}
]
}
}
Shell 命令从标准输入中获取信息,并利用 jq 命令完成工具调用参数 filePath 的读取。Claude Code 会将对标准输入中发送一个 JSON 字符串,如下是一个示例的 Hook 输入信息。
{
"session_id": "abc123",
"transcript_path": "/Users/.../.claude/projects/.../00893aaf-19fa-41d2-8238-13269b9b3ca0.jsonl",
"cwd": "/Users/...",
"permission_mode": "default",
"hook_event_name": "PostToolUse",
"tool_name": "Write",
"tool_input": {
"file_path": "/path/to/file.txt",
"content": "file content"
},
"tool_response": {
"filePath": "/path/to/file.txt",
"success": true
},
"tool_use_id": "toolu_01ABC123..."
}
2)干预 Agent 执行结果
以上示例并没有对 Agent 执行过程产生影响,而实际上可以通过 Hook 干预 Agent 执行过程,只需要在标准输出中打印一个结果字符串即可,如下是一个改写用户输入内容 Hook 结果。
decision 字段 block、undefined 表示拒绝本次用户请求 reason:用于 TUI 展示 hookSpecificOutput:设置输出,不同的 Hook 不一样
{
"decision": "block" | undefined,
"reason": "Explanation for decision",
"hookSpecificOutput": {
"hookEventName": "UserPromptSubmit",
"additionalContext": "My additional context here"
}
}
1.2.4.2 内置 Hook 清单
Claude Code 为多个“生命周期事件”提供 Hook 入口,用户可以在这些事件上添加脚本调用设置。核心是围绕「用户输入 → 工具调用 → Claude 输出与结束」这条链路提供若干标准事件点,目前主要包括如下 8 个关键 Hook 事件点。
| 事件名 |
触发阶段 |
能力重点 |
常见用途示例 |
| UserPromptSubmit |
用户输入 → Claude 接收之前 |
过滤/增强用户提示 |
注入上下文、屏蔽敏感 prompt、打日志 |
| SessionStart |
新会话/agent 创建时 |
会话级初始化,追加上下文 |
初始化环境、加载配置、为会话追加说明性 context |
| PreToolUse |
工具执行之前 |
能阻止工具执行、控制权限 |
安全闸门、参数校验、预备环境 |
| PostToolUse |
工具执行之后 |
评估结果、向 Claude 反馈 |
自动格式化/测试、对坏结果打回 |
| Notification |
发送系统通知时 |
改写/转发通知 |
推送到 Slack/邮件/系统通知 |
| PreCompact |
会话历史即将被 compact 之前 |
影响 compact 策略、追加 compact 指令 |
手动 /compact 或自动 compact 前,告诉 Claude 要优先保留哪些内容 |
| Stop |
Claude 准备结束本轮工作时 |
可阻止停止、要求继续 |
检查任务是否完成,智能“别急着停” |
| SubagentStop |
子代理准备结束时 |
精细控制单个 subagent 的停止 |
多代理协作中的子任务验收 |
| SessionEnd |
整个会话结束、进程退出前(在 Stop 之后) |
无法阻止结束,但可做清理和收尾 |
持久化会话统计、写审计日志、清理临时资源 |
更详细的配置可以参考官方文档:https://code.claude.com/docs/en/hooks-guide
1.2.4.3 外部集成场景实例
Hooks 的外部集成价值,核心在于“把 Claude Code 变成你现有工程体系的一等公民”,是 Claude Code 从单机走向分布式的关键,让 AI 编码不再是一个孤立的聊天工具,而是可以被监控、审计、触发和编排的自动化节点。
-
接入现有工程流水线
- 在工具执行后自动跑格式化、lint、测试,把本地“工程规范”变成 Claude 必须遵守的步骤。
- 在阶段结束时触发 CI、生成变更报告、记录审计日志,让 Claude 的修改直接进入团队已有流程。
-
打通外部服务与协作平台
- 将 Claude 的关键事件(通知、任务完成等)推送到 Slack、飞书、邮件或告警系统。
- 在 Issue/PR 系统中自动创建或更新任务,把 AI 输出直接串入代码评审和项目管理体系。
-
统一安全与合规控制层
- 在执行命令或访问外部服务前集中做安全/权限校验,阻止高危操作、控制数据流向。
- 对即将流出到日志、监控、业务系统的数据做脱敏和过滤,把 Claude 纳入既有安全与合规框架,而不是旁路系统。
在实际工程团队里,Claude Code 很少是“单机玩具”,而是需要嵌入到已有的开发流程、协作平台和安全体系中运转,Hooks 正是承担这个“粘合层”的关键机制:通过在关键生命周期节点自动调用外部脚本或服务,把 AI 的每一步行为暴露给你的 CI/CD、通知系统、安全网关和度量平台,从而让 AI 编码既能被自动驱动,也能被严格约束和观测,而不是游离在工程体系之外。
1.3 技术对比与选型决策
Hooks 能力相对容易理解,对于外部系统集成是第一选择。
但是,很多人在使用 Command、Subagent、Skills 这些新特性存在使用困惑,比如:
- 代码提交功能既可以用
git-commter Subagent,也可以定义 git-commit Command
- 节省上下文占用 Subagent 和 Skills 都能达到效果
- ……
因为都是对上下文中的提示词进行管理,所以容易产生技术决策问题。
1.3.1 通俗理解
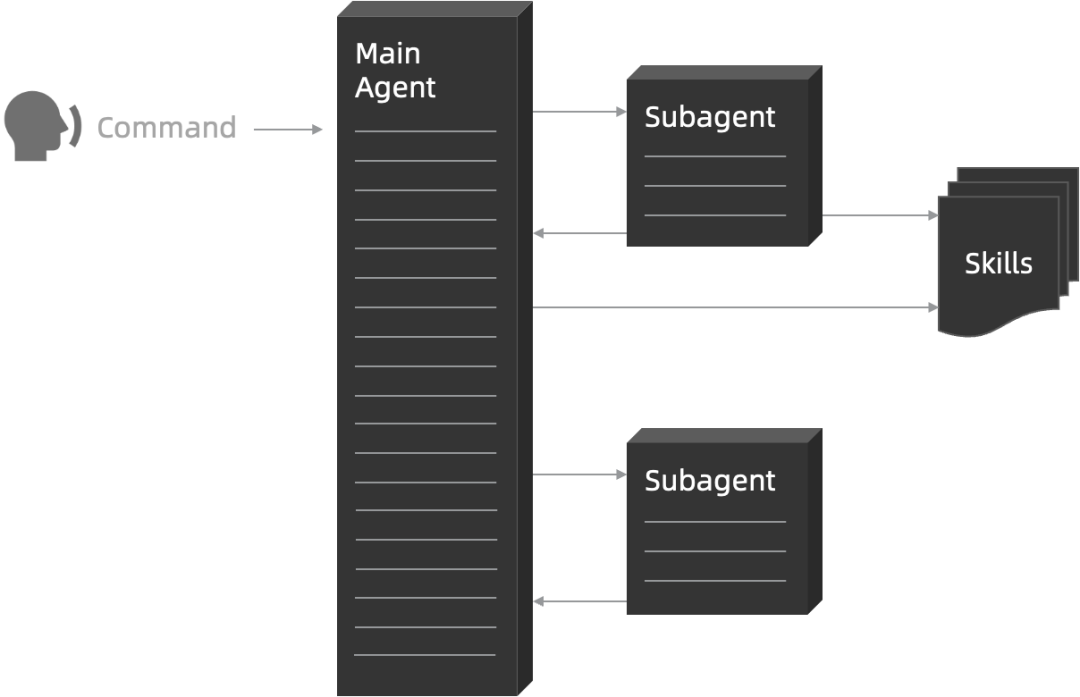
-
Command:
- 是 “人” 给 Agent 下达指令
- 指令通常是 “任务描述” 和 “任务要求”
-
Subagent:
- 主 Agent 通过 Task 工具唤起 Subagent “工具人” 工作
- Subagent 提示词配置的是 “人设描述”、“价值观”
-
Skills:
-
CLAUDE.md(AGENTS.md):
一些 Story 来辅助理解相互之间的关系:
- 用户通过 Command 让 Subagent 加载 Skill 完成某个任务
- Subagent 自动判断一个任务需要加载特定 Skill 来完成
- 多个 Subagent 都可以加载 Skill,如果 Skill 不够通用可以直接设置给 Subagent
- 常用的 Agent 执行准则可以放到 AGENTS.md 当中
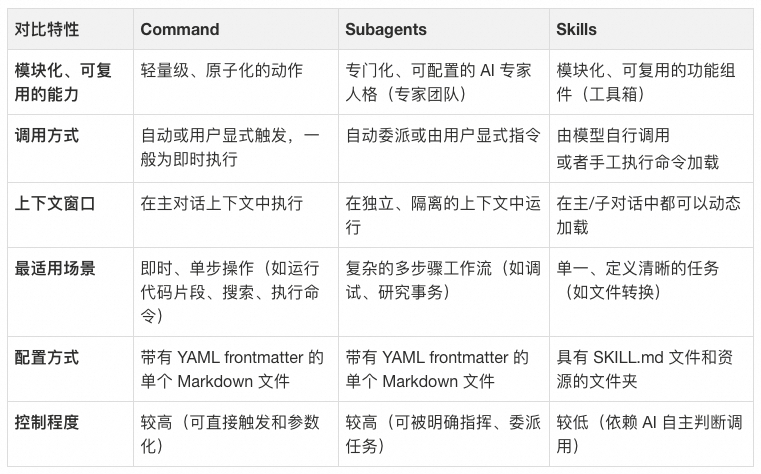
1.3.2 特性对比
1.4 对比 Cursor Rules
Cursor 提供了 Command、Subagent 相关能力,这部分能力类似。
Cursor 还提供了 Rules 配置能力,并且支持设置 Rule 的 4 种使用方法,4 种方法分别对应不同的加载方式。从功能上来看与 Claude Code 有所差异,但本质上只是概念设计上的差异。
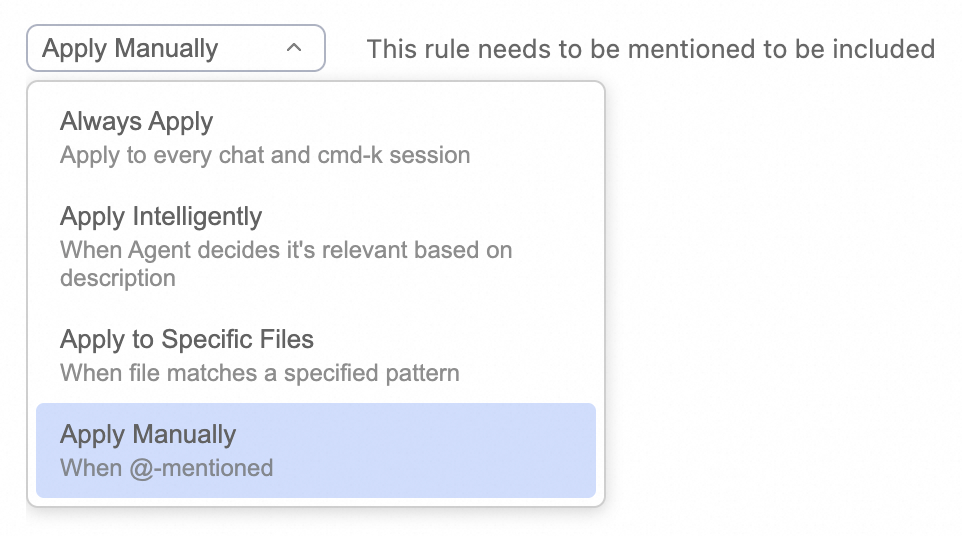
Always Apply:CLAUDE.md 记忆文件 Apply to Specific Files:CLAUDE.md 记忆文件 Apply Intelligently:模型动态加载,Skills 能力 Apply Manually:@文件引用
从这个设计来看,Claude Code 相比 Cursor 的设计概念上更加清晰,更容易被理解。
1.5 高度可扩展的产品架构
Claude Code 通过定义各种抽象资源,并定义其形态为配置文件,通过三级配置设计,实现一个高度可扩展、可管控的产品架构:
- 行为说明:用
CLAUDE.md 之类的文档定义项目级、用户级规则和上下文,相当于给模型一个统一的「说明书接口」。
- 配置层级:支持用户级、项目级等配置层次,让不同作用域的配置文件叠加生效,有点像「点文件 + 项目配置」的组合。
- 命令与工具:甚至 Slash 命令、工具行为等也可以通过文件/文档约定,而不是硬编码在 UI 里。
这种做法的本质是:尽量让「如何工作」都体现在可读、可编辑的文本/配置中,用文档作为统一的契约与控制面。

二、Claude 前沿工具调用技术
Anthropic 公司在 11.24 发布了一篇博文,一口气发布了三个 beta 特性,重点介绍更高效的工具调用方法。
https://www.anthropic.com/engineering/advanced-tool-use
三个特性分别是:
- Tool Search Tool
- Programatic Tool Calling
- Tool use Examples
2.1 技术背景介绍
大模型上下文窗口大小有限,即使是超大的窗口也很难满足日益增长的工具调用诉求,数十个 MCP 工具即有可能把常见的 200K 上下文占满,同时带来其他各方面的技术问题。
- 用户可用上下文减少,对话轮次骤减
- 工具过多,模型识别工具调用的准确性降低了,参数出错概率高
- 上下文占用过大,对话效果降低
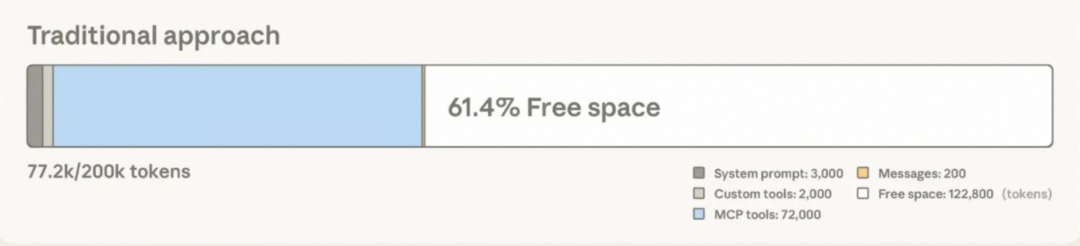
导致上下文快速膨胀的两种原因:
因此,Anthropic 针对这两种情况对工具调用逻辑进行优化,提出了三种特性能力:
- Tool Search Tool
- Programatic Tool Calling
- Tool Use Examples
传统模型调用时,需要传递所有的工具清单,直接占用大量的上下文空间,Tool Search Tool 和 Skill Tool 动态加载 Skill 的逻辑类似,工具也可以使用该工具按需动态加载。
Tool Search Tool, which allows Claude to use search tools to access thousands of tools without consuming its context window
{
"tools": [
// Include a tool search tool (regex, BM25, or custom)
{"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"},
// Mark tools for on-demand discovery
{
"name": "github.createPullRequest",
"description": "Create a pull request",
"input_schema": {...},
"defer_loading": true
}
// ... hundreds more deferred tools with defer_loading: true
]
}
上下文窗口占用情况示例:
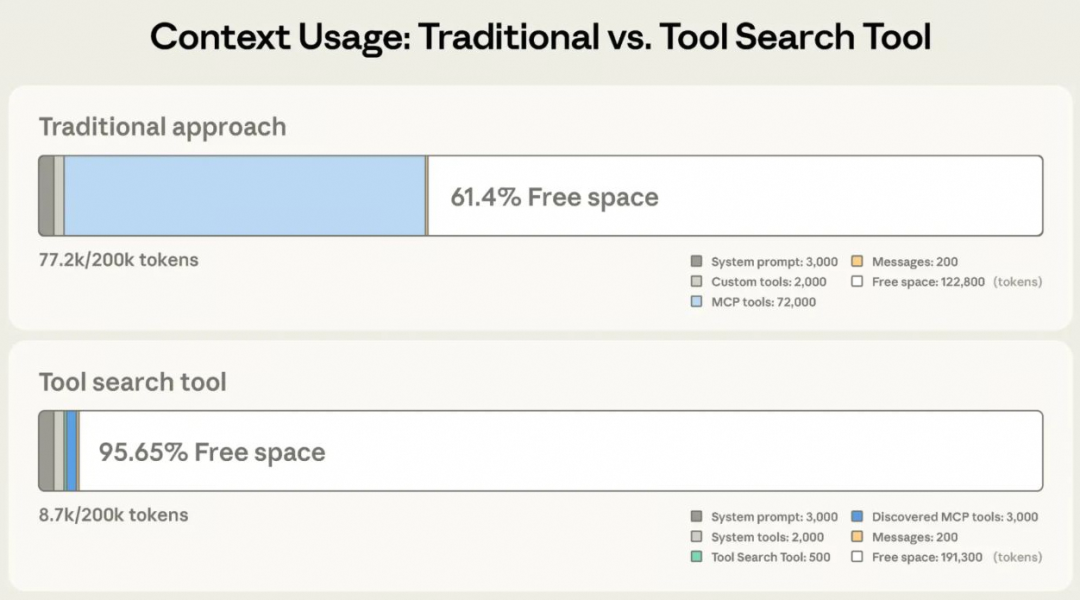
工具调用,尤其是用户自行接入的 MCP 工具,可能会返回大量的工具结果数据,造成上下文被快速填充,导致后续对话无法进行。实际上很多工具的输出结果最好进行清洗后再给模型,比如:
- 网页爬取工具返回的网页内容,大量 CSS 等无用代码需要去除
- 统计数据时,先进行全量数据查询,然后需要对内容进行聚合计算给出结果
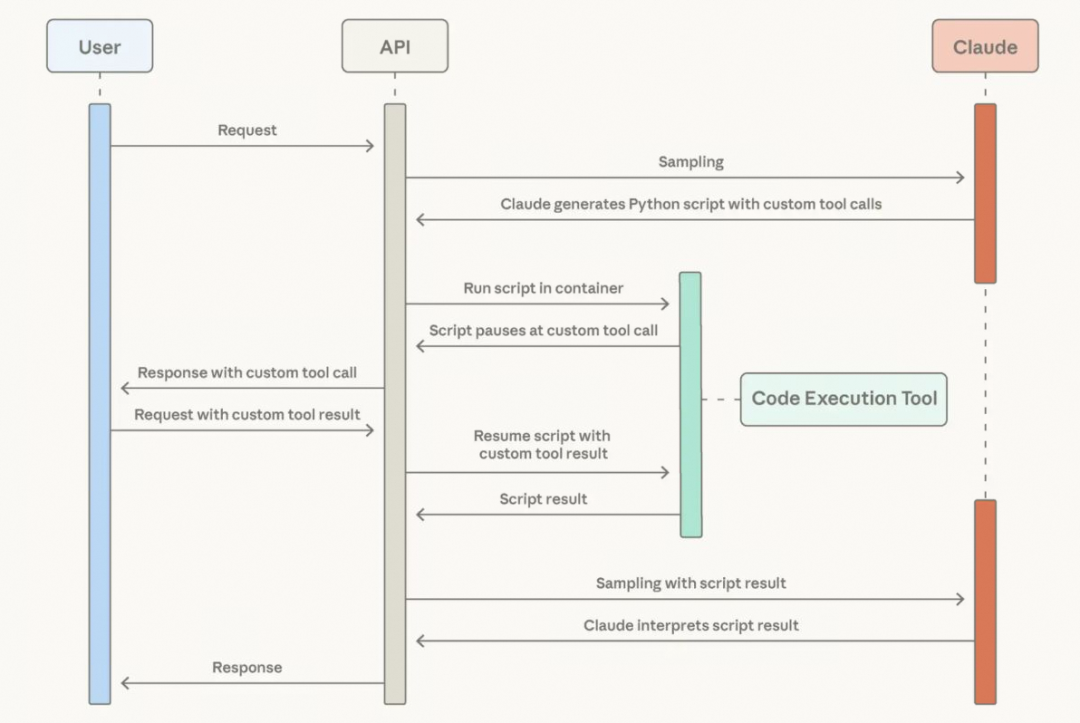
用户侧初始化的工具清单包含 code_execution 工具(注意这是一个服务端工具),以及设定 get_team_members 工具可以被 code_execution 工具调用。
{
"tools": [
{
"type": "code_execution_20250825",
"name": "code_execution"
},
{
"name": "get_team_members",
"description": "Get all members of a department...",
"input_schema": {...},
"allowed_callers": ["code_execution_20250825"] // opt-in to programmatic tool calling
},
{
"name": "get_expenses",
...
},
{
"name": "get_budget_by_level",
...
}
]
}
第一次模型请求时,模型结合“用户需求”+“工具清单”,生成一段调用工具、处理工具结果的代码,这段代码执行的结果可以直接满足原始“用户需求”。这里需要注意的是,get_team_members 工具的调用是在 python 代码当中,它会要求用户侧发起工具调用、返回工具执行结果。第二次给到模型的数据已经是代码处理过后的数据了,如此避免了模型直接处理 get_team_members 工具返回的巨大结果。
{
"type": "server_tool_use",
"id": "srvtoolu_abc",
"name": "code_execution",
"input": {
"code": "team = get_team_members('engineering')\n..."
}
}
目前工具调用时,需要传递输入参数的 schema 信息,用来让模型了解每个参数的具体类型,保证模型生成的准确性。然而只提供这些信息还不足以更精确地指导模型生成调用参数,比如一个字符串可能有具体的格式要求、一个数字有数值区间要求等。
{
"name": "create_ticket",
"input_schema": {
"properties": {
"title": {"type": "string"},
"priority": {"enum": ["low", "medium", "high", "critical"]},
"labels": {"type": "array", "items": {"type": "string"}},
"reporter": {
"type": "object",
"properties": {
"id": {"type": "string"},
"name": {"type": "string"},
"contact": {
"type": "object",
"properties": {
"email": {"type": "string"},
"phone": {"type": "string"}
}
}
}
},
"due_date": {"type": "string"},
"escalation": {
"type": "object",
"properties": {
"level": {"type": "integer"},
"notify_manager": {"type": "boolean"},
"sla_hours": {"type": "integer"}
}
}
},
"required": ["title"]
}
}
Anthropic 的思路是在工具描述中添加 input_examples 字段,用来向模型提供调用参数示例,从而指导模型给出正确的输入参数信息。
{
"name": "create_ticket",
"input_schema": { /* same schema as above */ },
"input_examples": [
{
"title": "Login page returns 500 error",
"priority": "critical",
"labels": ["bug", "authentication", "production"],
"reporter": {
"id": "USR-12345",
"name": "Jane Smith",
"contact": {
"email": "jane@acme.com",
"phone": "+1-555-0123"
}
},
"due_date": "2024-11-06",
"escalation": {
"level": 2,
"notify_manager": true,
"sla_hours": 4
}
},
{
"title": "Add dark mode support",
"labels": ["feature-request", "ui"],
"reporter": {
"id": "USR-67890",
"name": "Alex Chen"
}
},
{
"title": "Update API documentation"
}
]
}
三、一场关于“效率”提升的深度思考
Claude Code 的出现不仅仅是新产品、新技术的诞生,而是一场关于“效率”提升的深度思考,它将大家的视野从眼花缭乱的 AI 新产品拉回到 AI 应用的核心,重新思考 Agent 实现的本质是什么。
3.1 回归 Agent 本质
如何才能像传统 IT 基础设施一样,让 AI 应用也能够进行分层设计、通过复用让上层应用只关注业务实现,因此需要回归 Agent 本质,从 Agent 最核心的能力出发,从而能够辐射更多的 AI 应用场景。
3.1.1 Agent 的本质是什么
一句话概括 Agent 是什么:
“能感知环境、根据目标自己做决策并采取行动的智能实体。”
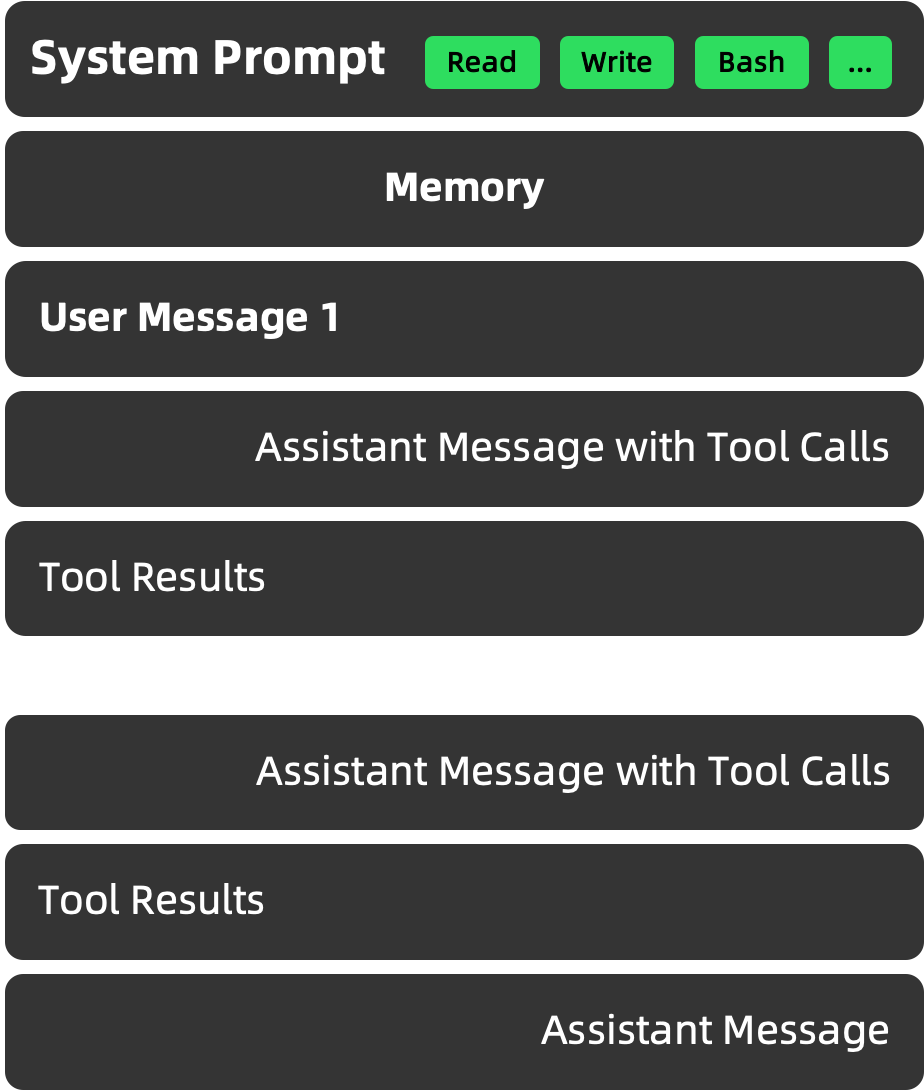
近年来市面上 AI 产品花样很多,但底层 Agent 技术的“配方”这两年变化不算颠覆,而是在同一套核心框架里不断打磨和工程化。绝大多数所谓 Agent,本质都是在大模型外面包一层相似的架构:
- 核心是大模型(LLM/多模态模型),负责理解、推理和生成。
- 再加上三件“标配”:规划(Planning)、记忆(Memory)、工具调用(Tool Use)。
- 外面再接一个编排框架/工作流(如各种 Agentic Workflow),把单次调用变成多轮闭环执行。
换句话说,现在大部分 Agent 只是在“意图理解 → 拆解任务 → 选工具 → 执行 → 再判断要不要继续”这个套路里做不同包装和场景定制,并没有跳出这个范式,这也就是所谓的 Agent Loop。
3.1.1.1 主子 Agent 架构(规划)
通过主子 Agent 架构,将模型的推理过程具象化到具体的上下文空间,构建了现实世界分析任务、拆解任务以及实现任务的核心框架。
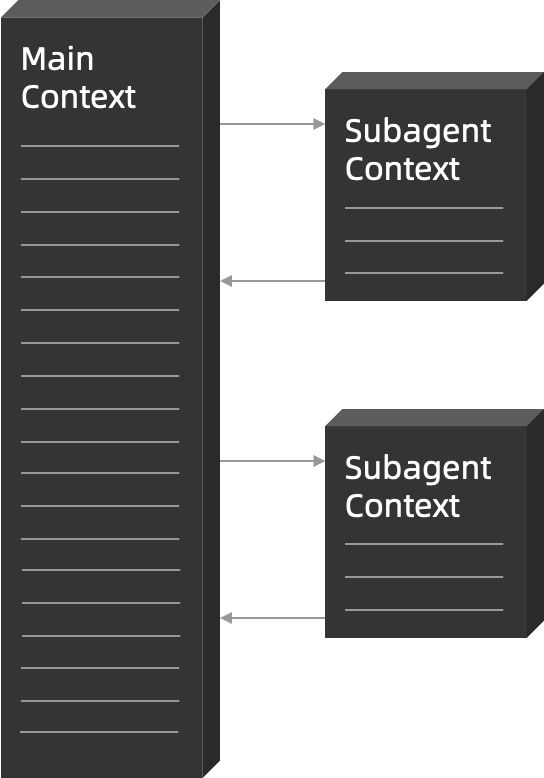
当前的 Subagent 更多是工程上的权宜之计,以人工梳理 Subagent 为主;从更长远的视角看,智能系统大概率会从“人工设计 Subagent”,演化到“AI 自主按需生成 Subagent”,再进一步收敛为对外只有一个统一的通用 Agent、对内却是自组织的多子系统结构。
3.1.1.2 上下文管理(记忆)
Claude Code 提供多种上下文管理的机制和手段。
CLAUDE.md:通过 Markdown 文件进行记忆设置,用于指导 AI 编码代理如何与项目交互。本质上是参考 README.md,不过 README.md 文件是为人类准备的,而 CLAUDE.md 是给 AI 看的。 /compact:上下文压缩指令,内部通过多种压缩机制来精简超长的上下文,从而避免对话无法继续。 System-reminder:Claude Code 内部隐形提醒机制,避免长期对话产生的记忆遗忘等问题。
3.1.1.3 持续的工具优化(工具调用)
Claude Code 内置的工具一直在持续演进,包括新增的 Skill 等工具来提供全新的 Agent 能力,也有被下架的 LS 等内置工具,工具是 AI 连接外部世界的桥梁,合理的工具设计、完善的工具监测体系,是 Agent 能力提升的必要条件。
3.1.2 一切旁路皆 Hook
从 Claude Code 研发方的视角看,Hooks 其实更像是“把内部旁路能力产品化”的机制,而不仅仅是为了对外集成好用。在真实的服务端实现里,很多绕不开的需求本来就需要旁路逻辑:
- 各种 Workaround:针对模型 Bug、特定命令的危险边界、少数用户环境的兼容补丁,都不适合直接硬写进主流程逻辑,而是挂在某些关键点“拦一手”再决定怎么修。
- 监控与审计:细粒度记录“模型调用了什么工具、改了哪些文件、执行结果怎样”,以及在异常路径(工具失败、长时间无响应)时打点、告警,这些也天然是旁路链路,不应该污染主业务代码。
- 针对特定租户/场景的行为调整:例如某些大客户需要额外的安全检查、额外的日志字段或特定的 stop 策略,这类客制逻辑如果直接写在内核里,会让主代码极其复杂,而通过 hook 则可以“外挂”进去。
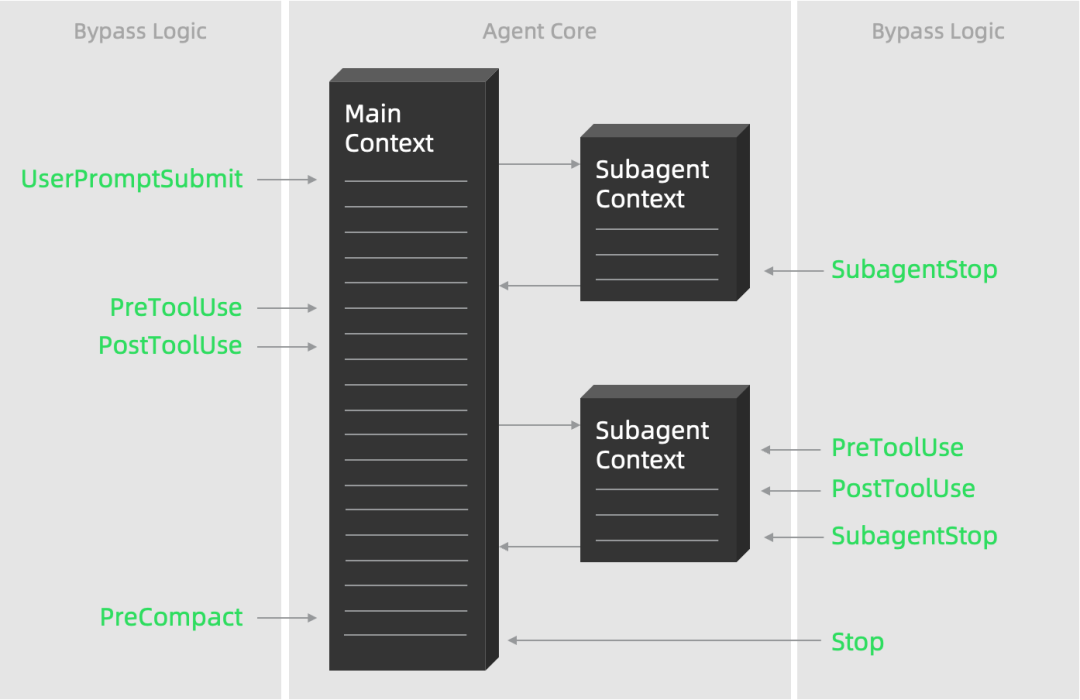
1)内部实现依赖
随着模型能力的不断提升,很多以前因为模型能力不足而添加的 Workaround 逻辑都会随之而消失,保证主链路的清晰才能紧跟模型迭代的步伐,Agent 在未来的发展中更具竞争力。
2)AI 演进的牺牲品
现在 Hardcode 的代码未来都可能被 AI 替代掉,它们都是固定的 SOP,只要 AI 能够生成代码,即可完成能力的自我实现。
3.2 加速迭代效率
Claude Code 这一产品形态的诞生,加速了 AI Agent 类产品的开发效率,包括它自身。
3.2.1 更容易被集成
除了 TUI 的交互式使用模式,Claude Code 还提供了 Headless Mode、Agent SDK 两种集成方式,个人或者企业能够基于其进行二次开发,同时享受最先进的 Agent 能力演进。
1)Headless Mode
claude --output-format=stream-json -p 'your_task_description'
Headless Mode 是一种无界面、非交互式的运行模式,适用于自动化脚本、持续集成/持续部署(CI/CD)流水线或后台批处理任务等场景。用户可以通过命令行参数、配置文件或环境变量传入输入内容,如代码片段或问题描述,系统会直接返回处理结果,无需人工干预,从而便于集成到开发流程中实现高效、自动化的代码辅助。
2)Agent SDK
Agent SDK 则为开发者提供了更深层次的集成能力。通过提供多种编程语言的软件开发工具包,Claude Code 的核心功能可以被嵌入到自定义应用、IDE 插件、企业内部工具或智能体(Agent)系统中。该 SDK 支持上下文管理、多轮对话、自定义提示模板以及对输出结果的进一步处理,使开发者能够根据具体业务需求灵活调用和扩展其能力。这三种使用模式——TUI、Headless Mode 和 Agent SDK——共同构成了从终端交互到自动化执行再到深度系统集成的完整能力矩阵,满足不同用户和场景下的多样化需求。
3.2.2 更容易做评估
Headless Mode 也方便了 Claude Code 自身的评估工作,避免因为复杂的 GUI 交互,导致评估工作量的增加。
1)避免 GUI 的复杂性
首先,Headless Mode 极大简化了 Claude Code 自身的评估流程。通过摒弃图形或交互式终端界面,评估脚本能够以程序化方式直接调用模型,输入结构化测试数据并获取可解析的输出结果。这不仅避免了因 GUI 交互引入的操作复杂性和不确定性,还显著降低了人工干预成本,使得大规模、高频率的自动化测试成为可能。该模式支持在持续集成(CI/CD)环境中无缝运行,确保评估结果具备高度的可重复性与可靠性,从而加速模型迭代与功能验证。
2)Headless 模式催生生态建设
其次,Terminal Bench 作为专为终端形态 AI 工具设计的测评系统,进一步完善了这一评估生态。它提供标准化的输入输出协议、隔离且可复现的测试环境,以及涵盖任务完成率、代码正确性、响应时间等维度的结构化指标体系。这种基础设施天然适配 Headless Mode,使开发者无需人工介入即可完成端到端的基准测试。Terminal Bench 不仅降低了评估门槛,还实现了不同模型版本或竞品之间的公平比较,真正构建起“开发—集成—评估”一体化的自动化闭环。
3.2.3 重新定义生产关系
Claude Code 以平均每周 5 个版本的计划在持续迭代中。
1)技术选型简单
Claude Code 采用「命令行 + TUI」的技术选型,避免了现代 IT 企业里多种岗位之间的复杂生产关系,让 Agent 在一个简单的命令行中充分演进,这能明显提升个人与团队的产出效率。
TUI 基于文本实现,界面由字符、符号、菜单等文本元素组成,不依赖图形,极大地降低开发难度,也避免了因为 GUI 带来的各种技术实现成本,让开发的核心更加聚焦在 Agent 能力上。
2)利用 AI 迭代 AI
Anthropic 的 Claude Code 团队用 Claude Code 开发 Claude Code,本质上是一种非常激进、系统化的「dogfooding」(自己吃自己的狗粮),目的是在真实高强度场景下打磨这个代理式编码工具的能力与可靠性,同时建立了 AI、人以及系统之间的全新生产关系,加速产品开发的过程。
四、Qoder CLI 的最佳实践
Qoder CLI 是 Qoder 产品家族中的一员,与 IDE 类产品相同,它使用全球顶级模型,基础模型免费使用!
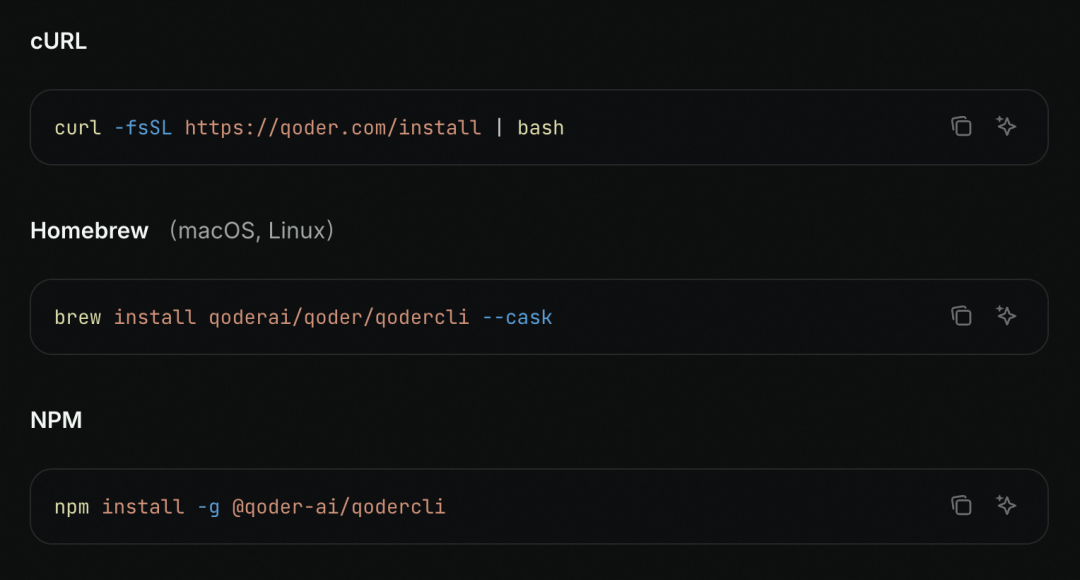
如何安装,一条命令即可!
Qoder CLI 从发布到现在,积累了众多实践场景,下面概要地进行介绍。
4.1 Vibe Coding
Qoder CLI 在快速原型开发场景中展现独特优势,通过特定的代码开发框架、标准 MCP,我们可以将 AI Coding 扩展到各类办公场景。
qodercli mcp add chrome-devtools -- npx chrome-devtools-mcp@latest
通过配置如下的 Chrome MCP 工具,让 CLI 能够自动生成代码、启动并测试应用,用户无需关注代码,即可实时关注产品的开发过程。
4.2 Quest Mode — Spec Coding
开发者通过自然语言描述意图,CLI 理解用户意图并生成 Spec 结构化地拆解任务,然后通过 Spec 将任务委派至 CLI 进行执行。
- 充分澄清设计:Specification 对于开发者来说是最熟悉的意图表达方式,让设计文档成为人与 AI 之间的沟通媒介;
- 异步委派任务:开发者的工作变成明确任务意图、写作生成设计文档,工作模式从实时伴随进化到异步委派。
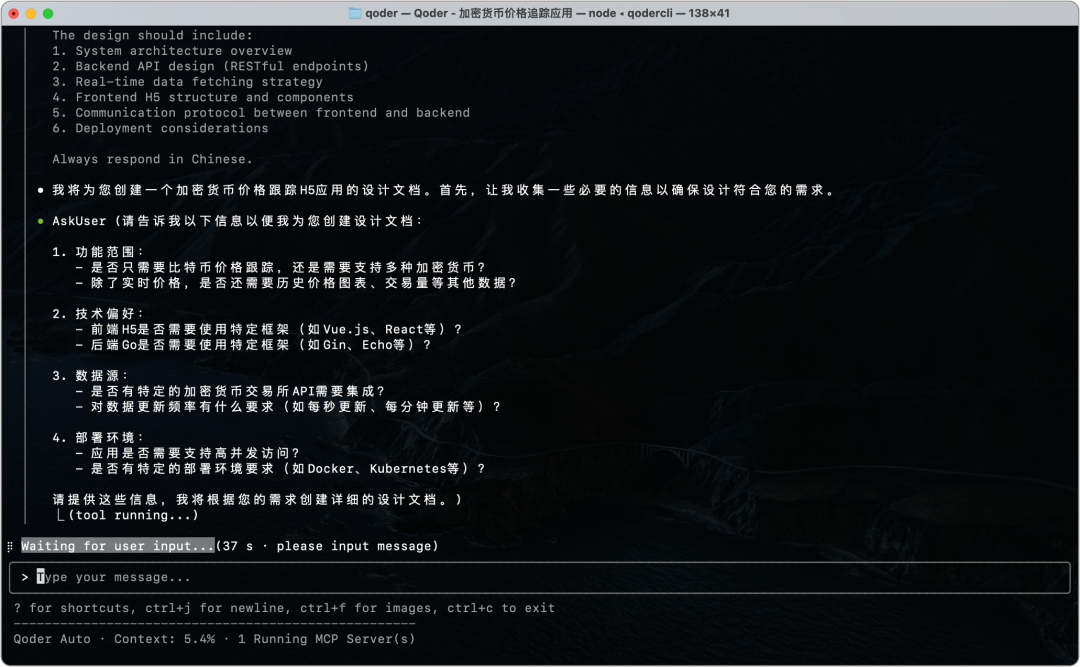
Qoder CLI 已支持 OpenSpec、spec-kit 开源实现
Qoder IDE 中的 Quest Mode 即将迎来全新版本升级!
4.3 Code Review
Qoder CLI 提供 Code Review 能力,支持在本地和远端运行,可以根据业务场景进行选择。
4.3.1 本地 Code Review
Qoder CLI 在本地提供了基于 / 命令的 Code Review 功能,只需在修改完成的代码仓库下执行 /review 命令,就会唤起 CLI 执行代码审查任务。/review 命令面向专业开发场景,使用最顶级的模型+专用 Subagent,对当前仓库未提交的代码修改进行审查。
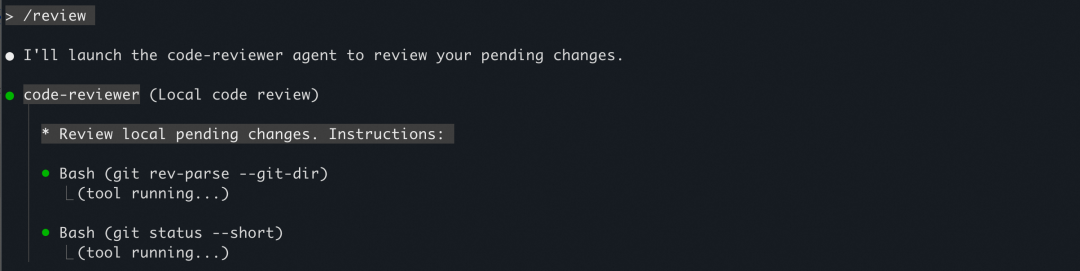
4.3.2 基于 Github、Gitlab 进行 Code Review
近期,我们发布的 Qoder CLI GitHub Action,为 Pull Request 环节引入了自动化的智能评审工作流,切实帮助开发者提升了代码质量与合并效率。与此同时,我们也收到了大量企业用户的反馈——希望在 GitLab 的工作流中也获得一致的智能评审体验,将 Qoder CLI 平稳地集成到现有的 Merge Request 流程中。
基于这些需求,我们整理并推出了一套可直接落地的官方最佳实践指南,帮助你快速在 GitLab CI 中构建自动化、深度智能的代码审查流程。
只需少量 CI 配置,你的 GitLab MR 就能具备自动触发、深度理解代码上下文并输出高质量审查意见的智能评审能力,享受 Qoder CLI 带来的智能化效率提升。
4.4 标准的 ACP 协议实现
ACP 协议是一种 CLI 与 IDE 集成的协议,详见:
Agent Client Protocol(https://agentclientprotocol.com/overview/introduction)
Qoder CLI 实现了该协议标准,通过该特性 Qoder CLI 可以被集成到任何一种实现了 ACP 协议的客户端中。
Zed IDE 适配效果:
支持 ACP 协议的一系列编辑器(https://zed.dev/acp):

4.5 环境部署、云上运维
Qoder CLI 支持三大主流操作系统,并且可以在 容器、K8s 等沙箱环境中运行。通过一行命令即可完成快速安装,即使是在远端 ECS 环境中,我们可以直接在 WebTerminal 中完成 CLI 的安装,同时利用它进行运维操作。一些实践案例:
1)ECS 运维
- 一般用户:通过 CLI 进行开源环境的搭建
参照 https://github.com/nextcloud/docker 帮我在这台机器上安装
-
开发用户:利用 CLI 在线上 ECS 上进行自然语言调试应用 BUG
帮我看下如下错误信息,分析错误原因
**错误堆栈信息**
- 运维用户:通过 CLI 进行网络抓包分析
监听8004端口的http请求,来源地址为4.4.4.4
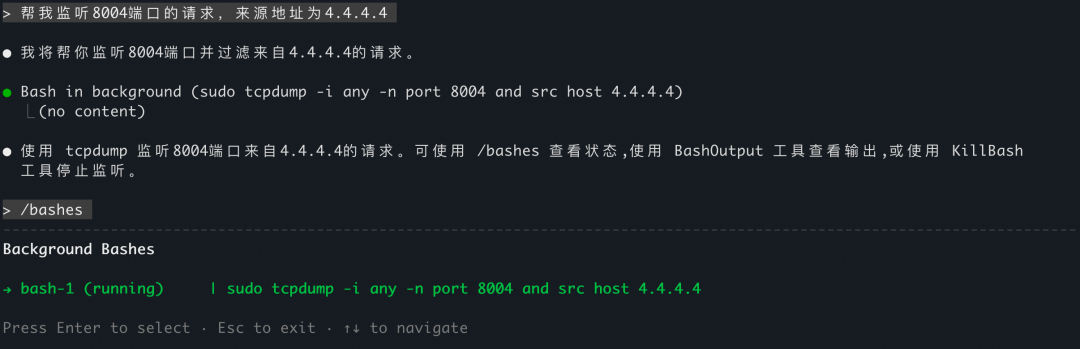
2)Kuberntes 运维(ACK)
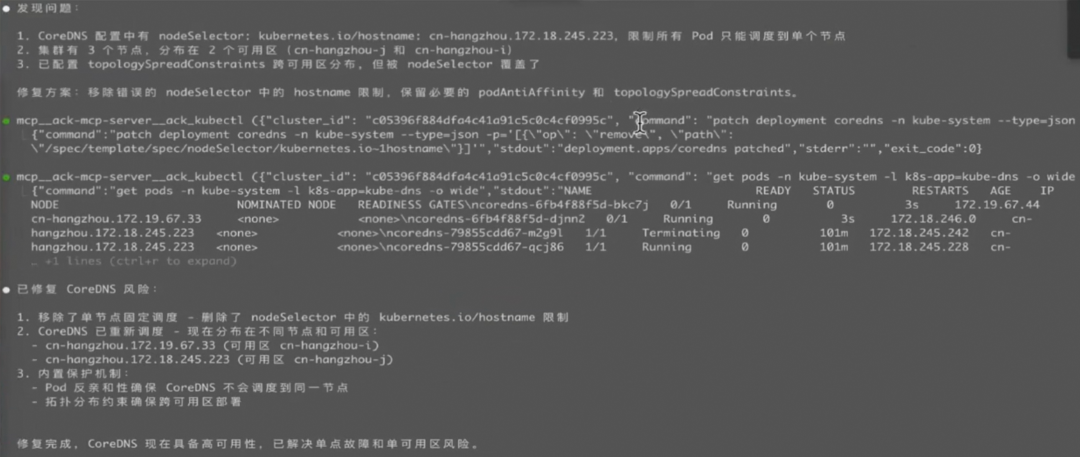
通过与 Kubernetes MCP 工具的集成,可以直接将 CLI 运行在远端 Pod 中,实现 Kubernetes 集群的连接,用户只需要通过自然语言进行需求描述,如“分析xx Pod为什么没有起来”,CLI 则会自动完成相关日志查询和分析,最后给出问题分析的结果。
-
诊断集群问题
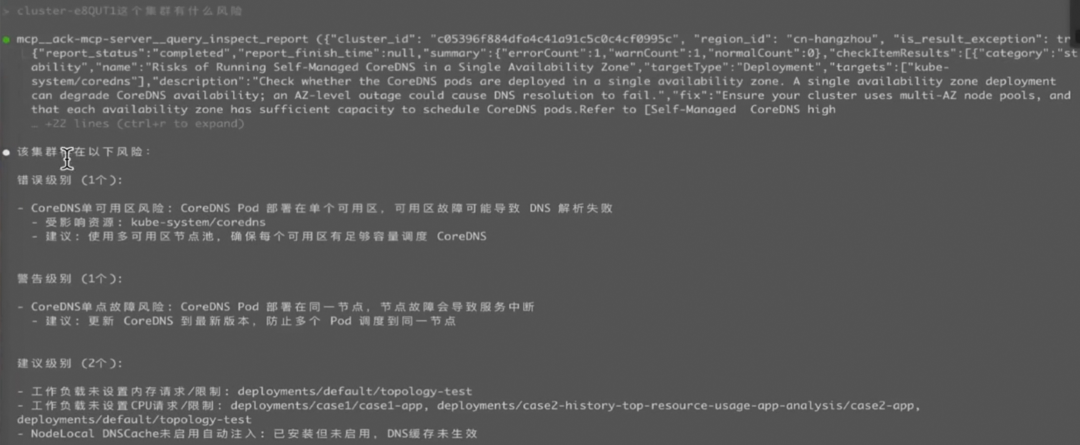
-
修复集群问题
4.6 基于 CLI 进行日志分析
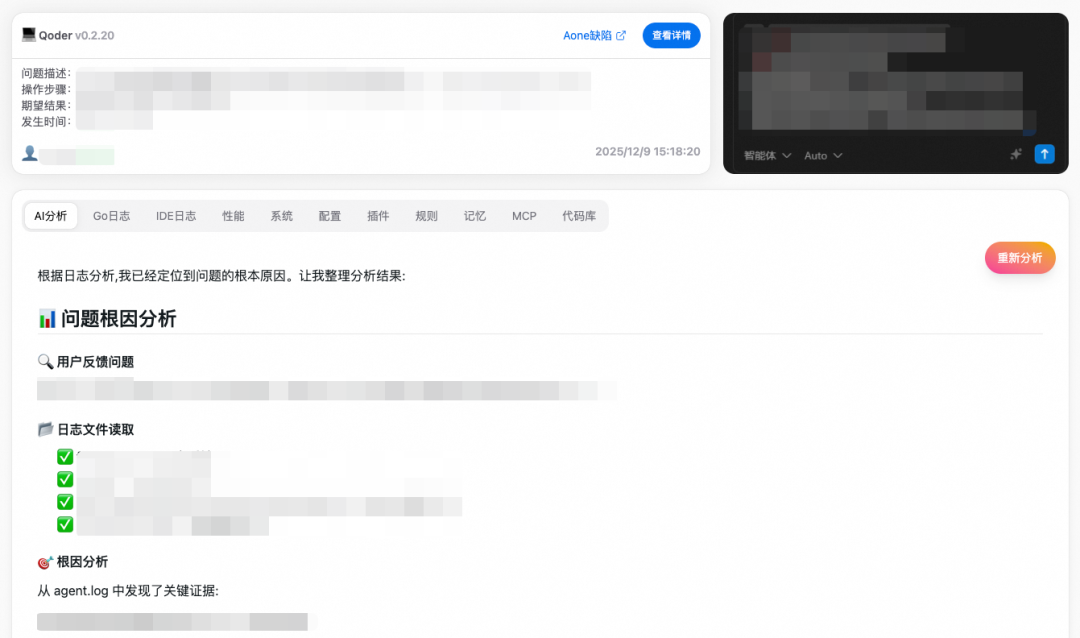
Qoder CLI 适合各类被集成场景,使用代码或者脚本都可,内部我们通过日志分析落地了一些最佳实践。
Qoder 产品的 Feedback 日志会通过 Qoder CLI 自动进行分析处理,结合用户上报的环境和配置信息,实现反馈问题的根因自动定位,极大地提升了问题处理效率。
 发表于 2026-3-1 16:16:48
|
查看: 343|
回复: 0
发表于 2026-3-1 16:16:48
|
查看: 343|
回复: 0
