在当下的智能体开发体系中,“为LLM外挂技能”已成为行业标准做法。我们常常困惑:Agent表现不佳,到底是底层模型的能力瓶颈,还是提供的“技能”质量不行?从日常的各类CLI工具到最近的Openclaw,其能力跃升都极大依赖这些特定领域的技能。

然而,整个工程界似乎陷入了一种“知其然不知其所以然”的盲目状态。开发者们在一个缺乏精确度量的黑盒里,不断堆砌Markdown文件、代码模板和标准流程,却没有可靠方法来量化这些外部知识到底带来了多少真实的性能提升。
这种系统性的盲目,被一项名为《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》的研究终结了。该研究首次将“技能”本身定义为可量化测试的独立工件,而非模型原生能力的附庸。

这项研究的团队阵容强大,由BenchFlow领衔,汇聚了来自亚马逊、字节跳动、富士康等工业界,以及斯坦福、卡内基梅隆、伯克利、牛津等顶尖学术机构的研究人员。他们通过7,308次执行轨迹的严格测试,旨在回答三个核心问题:
- 有效性检验:技能真的能提升表现吗?提升的幅度(Δ)具体是多少?会不会有负面干扰?
- 人类智慧 vs. 模型自生:吸收了海量数据的大模型,能否在执行任务前“自己给自己写一份有用的技能指南”?
- 设计原则摸底:什么样的技能才是好技能?是事无巨细的“教科书”,还是精炼的“速查表”?
本文基于该论文的实证数据,从底层架构、增益量化、成本分析以及5,171次真实失败日志,为您系统解读这些问题的答案。
隔离变量:构建确定性测试环境与技能定义
在深入测试前,必须厘清我们向大语言模型(LLM)上下文里注入的到底是什么。许多开发者容易将系统提示词、检索增强生成和工具调用与技能混淆。研究者给出了明确的技术边界划分:
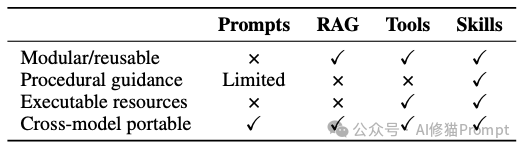
- RAG 提供“事实性知识”,具备模块化特征,但缺乏程序性指导和可执行资源。
- Tools(工具调用) 提供“能力描述”,告诉模型API能做什么,同样缺乏针对复杂业务的程序性指导和跨模型可移植性。
- Skills(智能体技能) 是唯一同时兼具 “模块化复用”、“程序性指导”、“携带可执行资源”以及“跨模型可移植” 四种特性的范式。
研究者从GitHub、社区及企业库中扫描并去重,提取了47,150个真实技能。这些文件非常轻量,中位数大小仅2.3 KB(约1500 Tokens),主要为Markdown格式,这为测试设定8K上下文窗口提供了现实依据。
构建100%确定性的基准沙盒
为了确保任务成功归因于技能而非评测偏见,研究者彻底摒弃了主观的“LLM-as-a-judge”评估,构建了基于容器、完全客观的沙盒环境。
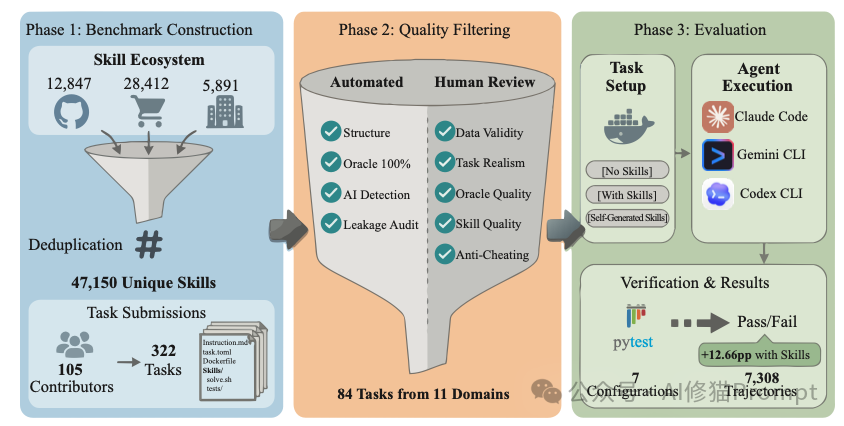
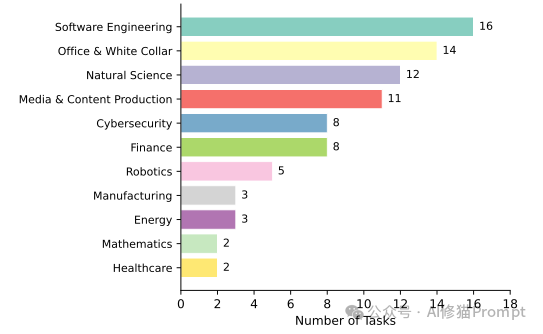
在SkillsBench中,每个任务都是一个自包含的目录,覆盖11个专业领域,并严格包含以下组件:
- 资源强隔离:通过
task.toml 声明CPU、内存限制及严格的超时预算(如600-1200秒)。
- 基准参考实现:每个任务包含一个
solve.sh 脚本,必须在Ubuntu 24.04容器中实现100%测试通过率,作为“完美答案”对照。
- 确定性断言:测试由
pytest 执行,输出CTRF格式的JSON报告。任务结果只有通过(1)或失败(0),没有模糊的部分得分。
- 反泄漏审查:使用GPTZero和人工审查,确保任务指令
instruction.md 非AI生成,且技能文件中不包含测试答案的硬编码。
在此环境下,同一“智能体+模型”组合在 “无技能”、“有人工策划技能” 和 “自生成技能” 三种条件下执行任务,其通过率差值即为技能的真实价值。
拷问一:技能真的有用吗?量化增益与负溢出效应
实验涵盖了Claude Code、Gemini CLI和Codex CLI三种框架,搭配GPT-5.2、Claude 3家族、Gemini 3家族等共7种模型。
1. 绝对增益的量化数据
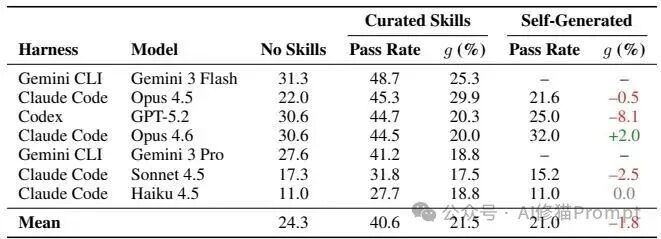
数据证实,人工策划的技能带来了明确收益。在7种配置下,外挂技能使平均绝对通过率提升了 +16.2个百分点(从24.3%升至40.6%)。
- 最大提升:Claude Code + Opus 4.5组合增益最大,通过率增加 +23.3个百分点。
- 最高上限:Gemini CLI + Gemini 3 Flash在技能加持下,取得了 48.7% 的最高绝对通过率。
研究者还引入了物理学中的规范化增益公式来排除“天花板效应”:
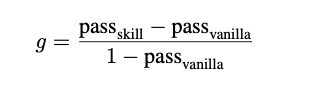
其中Opus 4.5的规范化增益达到了29.9%。
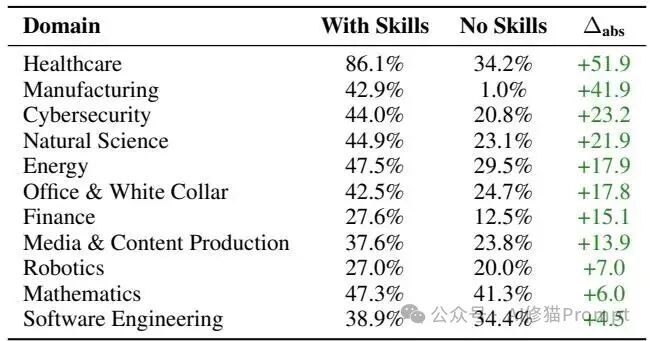
2. 领域差异的下钻分析
增益分布极不均衡,呈现显著的领域异质性。
- 高增益领域:在需要生僻工作流规范的领域,技能统治力极强。医疗保健领域获得了 +51.9个百分点 的惊人提升,制造业以 +41.9个百分点 紧随其后。
- 低增益领域:在模型预训练语料丰富的领域,如软件工程和数学,技能提升仅分别为 +4.5 和 +6.0个百分点。
3. 反常识剖析:技能为何有时导致崩溃?
最具技术洞见的发现是:在84个任务中,有16个任务在引入人工技能后,模型表现反而变差(负增益)。
- 例如在
taxonomy-tree-merge 任务中,通过率暴跌了39.3个百分点。
- 在
energy-ac-optimal-power-flow 任务中,通过率下降了14.3个百分点。
日志分析揭示了机理:当基础模型对某类任务已有强大先验知识时,强行注入的外部程序性知识若不完全对齐其内部逻辑,就会引入“冲突的指导”。同时,额外规范会消耗有限的上下文预算,可能导致模型在处理原本简单问题时产生“过度设计”或认知过载。
框架底层调度差异
技能的效用也受外壳框架调度实现的影响:
- 隐式扫描 vs. 显式调用:Claude Code和Codex将技能文件放在隐藏目录(如
/root/.claude/skills),供模型隐式发现;而Gemini CLI则暴露一个 activate_skill 工具,要求模型必须主动显式调用。
- 模型的“执行傲慢”:测试中观察到,Codex CLI + GPT-5.2组合常出现一种行为:智能体在对话中知晓技能存在,但在实际编码时却忽略提供的SOP,执意自行实现解决方案。
拷问二:模型能“自我拔高”吗?自生成技能的幻想破灭
既然大模型学习了海量公开代码和工作流,能否通过系统提示,让它先为自己生成SOP再执行?研究者设置了“自生成技能”条件来验证。
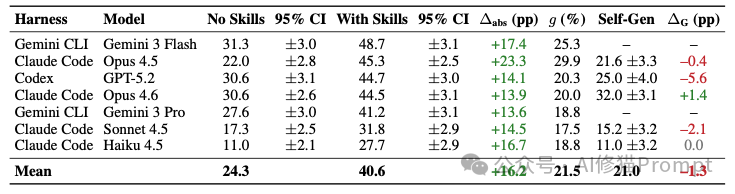
实证数据击碎了这一幻想。在支持此测试的5种配置中,自生成技能导致的平均表现,比“什么都不给”的基线还要低 1.3个百分点。
- 仅Opus 4.6获得了微弱的 +1.4个百分点 提升。
- Codex + GPT-5.2的表现遭受重创,通过率急剧下降 5.6个百分点。
轨迹分析表明,模型在尝试输出自身所需的程序性知识时,会陷入两种困境:
- 不精确的过程提取:模型能意识到任务领域(如用pandas),但生成的文档停留在概念层面,缺少关键的API调用模式和参数规则。
- 未知的未知盲区:对于专业密集的任务(如制造业排期),模型无法识别自身需要补充特定技能,转而用通用逻辑硬解,导致崩溃。
- 时间预算消耗:生成和阅读有缺陷的自创文档,严重挤占了解决问题的时间,导致超时。
结论明确:有效的技能必须来源于人类策划的领域专长,模型目前无法可靠地为自己编写受益的程序性知识。
拷问三:好技能的设计原则与Token经济学
如果必须由人编写技能,应遵循什么规范?量化分析打破了“越全越好”的直觉。
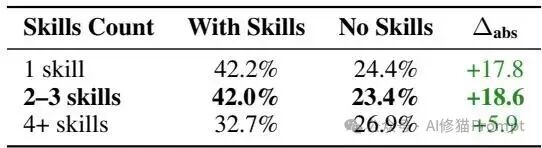
1. 数量控制与复杂度边界
- 数量阈值:针对单个任务,当挂载 2到3个 技能模块时,增益达到最优峰值(+18.6个百分点)。当技能数达到 4个或更多 时,收益断崖式下跌至 +5.9个百分点。冗余技能会形成噪音并诱发幻觉。
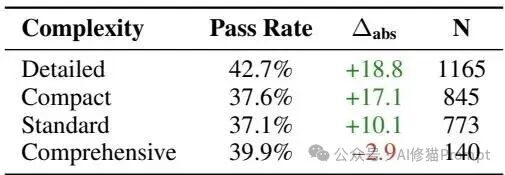
- 复杂度倒挂:被评定为“详细”和“紧凑”的技能包,分别提供了 +18.8 和 +17.1个百分点 的最强增益。而试图涵盖所有边缘情况的“全面”型文档,实际上损害了表现,导致通过率下降 2.9个百分点。过度阐释占用上下文预算,却无法提供简明引导。
2. Token经济学与算力代偿
技能注入会改变模型的推理成本结构,这在工业部署中至关重要。
- 跨级超越:挂载技能的 Claude Haiku 4.5(通过率27.7%)可击败无技能状态的旗舰模型 Claude Opus 4.5(22.0%)。
- Token体积换取智能:在Gemini产品线中,挂载技能后,Gemini 3 Flash 单次任务消耗高达 1.08 M(百万) 输入Token,是 Gemini 3 Pro(0.47 M)的2.3倍。小模型需更多迭代和重试来弥补推理深度不足。
- 反向剪枝效应:高级模型 Gemini 3 Pro 接入技能后,输入Token消耗量反而下降6%。结构化的程序性知识阻断了其无效探索路径。
- 成本核算:尽管Flash消耗更多Token,但按假设定价(Flash $0.50/M,Pro$2.00/M),Flash单任务成本仅 $0.57,比Pro的 $1.06 便宜47%,同时还取得了最高胜率。
系统尸检:5,171次真实崩溃的溯源分析
为了探究“在有技能指导下,智能体为何依然失败”,研究者对5,171次非基础设施错误的崩溃轨迹进行了分类学分析。
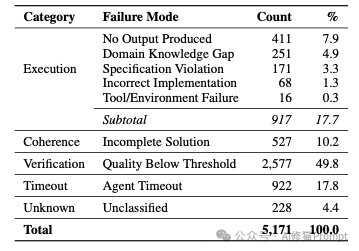
1. 验证阈值失败 | 占比 49.8%
最主要的死因。模型遵循指示完成了逻辑闭环,但产出存在超容差偏差。
案例:earthquake-plate-calculation任务中,模型正确提取了地震数据并应用了Haversine公式,但代入了一个错误的板块边界坐标,导致计算距离误差达8.2%,击穿了 ±0.01 km 的极窄容差。这表明在垂直领域,数据细节理解仍是LLM的硬伤。
2. 执行超时 | 占比 17.8%
在严格时限内未能输出结果。一个反直觉的发现是:挂载技能后,总体失败率降低,但超时占比不降反升。这是因为技能帮助模型绕过了早期简单崩溃,得以进入任务深水区,却在更深层的复杂计算中耗尽时间预算。
案例:gravitational-wave-detection任务需要构建带通滤波和信噪比计算管线,多数模型直接耗尽计算窗口被终止。
3. 相干性断裂 | 占比 10.2%
模型过早宣告完成,提交了结构正确但内容残缺的产物。
案例:shock-analysis-supply任务中,模型构建了Excel基础结构,但遗漏了加载特定数据库、运行优化求解器等三个计算负荷最大的核心步骤。
4. 早期流产 | 占比 7.9%
要求输出的文件完全不存在。
案例:gh-repo-analytics任务需与本地Git服务器交互,智能体在最基础的凭证或环境配置上失败,导致整个工作流卡死在第一步。
5. 规范违规 | 占比 3.3%
模型忽视硬性的输出格式要求。
案例:latex-formula-extraction任务要求逐行输出$$包裹的纯净公式,但模型“画蛇添足”加入了Markdown标题,导致基于正则的测试脚本直接判零。
成功的反例证明
成功的案例则清晰展现了技能的杠杆效应。在 sales-pivot-analysis 任务中,无技能时所有模型通过率为0%,它们试图手写透视表逻辑导致数组越界。一旦挂载了关于openpyxl透视表创建API的技能文档,模型平均通过率跃升至85.7%,实现了从0到1的突破。
AI的绝对算力边界:“零分俱乐部”
在所有84个任务中,有16个任务(19%) 即使在挂载完美技能、使用顶级模型的情况下,依然保持0% 的全局通过率。这揭示了当前智能体体系无法跨越的物理断层:
- 计算不可行:如引力波信号匹配滤波探测 (
gravitational-wave-detection),彻底超出迭代时间预算。
- 脆弱的多步流水线:如异构企业信息交叉检索,链条过长,任何一步的微小幻觉都会阻断全局。
- 极度严苛的规范死穴:输出格式几乎无冗余容错空间的自动化脚本调试任务。

结论与工程启示
SkillsBench的实证结果向智能体工程师传递了明确信号:
- 摒弃零样本神话:在专业工作流中,不要指望大模型能自发组合出完美的API调用。它需要结构化的领域知识指导,且无法可靠地自生成。
- 约束输入冗余:将垂直领域Agent的技能库维持在最小可用状态。每个任务挂载的技能模块应严格限制在2-3个以内。
- 精简为王:技能文档拒绝写成详尽教科书。应提供短小精悍、强约束力的分步指南和一个高信息密度的可执行用例。
向智能体注入SOP规范,本质是一种低成本、即插即用的“软”微调。在这个确定性的测试场中,数据证明:精准的、由人类专家提炼的工艺手册,依然是驾驭庞大深度学习算力的最佳缰绳。对于希望深入探索Agent技术边界、获取更多前沿数据科学与工程实践案例的开发者,欢迎持续关注云栈社区的后续分享与讨论。
 发表于 2026-2-25 04:16:16
|
查看: 131|
回复: 0
发表于 2026-2-25 04:16:16
|
查看: 131|
回复: 0
