👔 面试官:你说你做过 RAG 项目,那 RAG 主要用来解决什么问题?
🙋♂️ 我:RAG 就是让大模型变得更聪明,回答质量更高。
👔 面试官:哪个大模型不够聪明?你这不是在说废话吗?我问的是 RAG 解决的 具体问题 是什么,你连问题都没说清楚怎么谈方案?
🙋♂️ 我:哦,就是大模型有时候会编答案,RAG 可以让它不编。
👔 面试官:幻觉只是其中之一。知识时效性呢?私有知识覆盖呢?这两个你都没提到。而且你以为 RAG 是专门解决幻觉的?幻觉只是知识缺失的副产品,根源是模型的知识冻住了,你得从根源上讲。
🙋♂️ 我:呃,知识冻住了是指训练数据过期了吧,那私有数据呢?
👔 面试官:你连问题都说不全,怎么做的 RAG?回去想清楚再来吧。
好吧,这道题看似简单,但真被问到的时候很多人只记得“幻觉”两个字。实际上,RAG 旨在系统性地解决大语言模型落地应用时的一系列根本性瓶颈。下面我们来彻底梳理清楚。
💡 简要回答
RAG 主要解决三个环环相扣的核心问题:
- 知识时效性问题:LLM 的知识被“冻”在了训练截止的那一刻,之后发生的事情它一无所知。
- 私有/领域知识覆盖问题:企业内部文档、专有数据从未进入过公开训练集,LLM 对这部分内容是完全空白的。
- 幻觉问题:当模型缺少相关知识依据时,会基于“预测下一个词”的机制,生成听起来合理但实际错误的答案。
这三个问题的根源是一致的:知识被固化编码在了模型的参数权重里。RAG 的解决思路是把知识从参数里“搬”出来,存储在外部的知识库中,使用时实时检索并注入上下文,从而彻底绕开模型参数的固有知识限制。
📝 详细解析
LLM 的“知识冻结”问题
要理解 RAG,首先要明白 LLM 的知识来源与局限。模型在预训练阶段,通过阅读海量文本,将其中蕴含的知识“编码”到数以亿计的模型参数中。这个过程可以想象成编撰一本厚重的百科全书。

这本“百科全书”一旦印刷完成(模型训练结束),内容就固定了。它有一个明确的“截止出版日期”——即训练数据收集的截止时间。在此之后,无论现实世界如何变化,模型的参数都不会自动更新,这就是“知识冻结”。
你可能会想,那就重新训练一遍?对于 GPT 级别的模型,单次训练成本高达千万美元,不可能频繁进行。微调虽能注入少量新知识,但成本也不低,且注入的知识难以溯源,出了问题无法定位原因。
因此,“知识冻结”是 LLM 架构的固有特性,直接导致了后续的三个衍生问题。
问题一:知识时效性 —— 训练数据有截止日期
这是最直观的问题。当你询问 LLM “今年新发布的某产品有什么功能?”时,如果其训练数据截止在产品发布日期之前,它并不知道答案。但LLM不会说“我不知道”,而是会依据历史规律,“推测”出一个听起来合理但很可能错误的答案,并且说得极为自信。
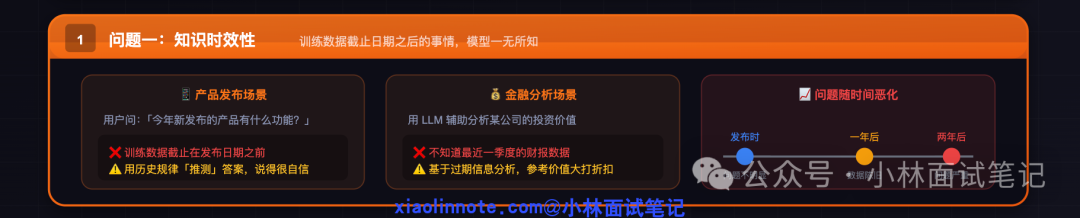
在金融分析等对数据实时性要求高的场景中,这个问题尤为致命。如果模型不知道某公司最近一季度的财报,其分析建议就建立在过时信息之上,参考价值大打折扣。随着时间的推移,训练数据会越来越陈旧,这个问题只会愈发严重。
问题二:私有知识覆盖 —— 内部数据从未进过训练集
如果说时效性是“知识旧了”,那么这个问题是“知识压根没有”。公开的互联网知识,LLM或多或少见过;但每家公司的内部文档(产品手册、客服知识库、合同、行业规范等)根本不会出现在公开训练数据中。

例如,让 LLM 扮演客服回答“我们产品的退款政策是什么?”,它不可能知道公司特定的规定。如果它强行回答了,那一定是在编造。这是企业将 AI 落地时最普遍的痛点:海量私有知识需要被AI理解和运用,但通过重训练或微调来注入,成本高、周期长,且无法应对知识的日常更新。
问题三:幻觉 —— 知识缺失的副产品
前两个问题(知识过期和知识缺失)的共同表现,就是“幻觉”。很多人误以为幻觉是LLM的一个独立缺陷,实则不然。幻觉是模型在缺乏可靠知识依据时的“应急策略”。
LLM的核心机制是“预测下一个词”,它没有内置“我不确定就停下来”的开关。当参数里的知识不够用时,它只能硬着头皮生成,将相关或不相关的记忆碎片拼凑成一个看似连贯的答案。
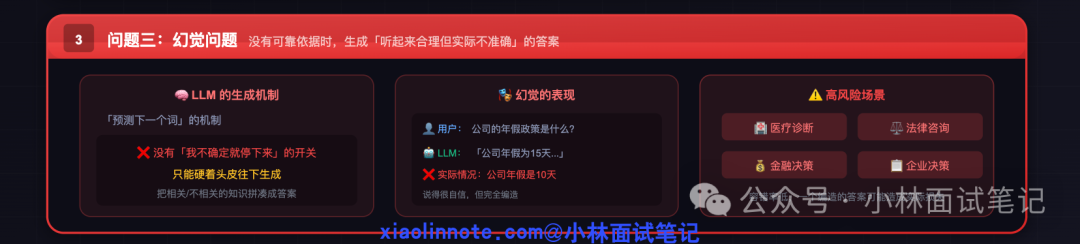
因此,幻觉的根源是知识不够。解决幻觉的关键不是“教模型不乱说”,而是为它提供准确、可靠的知识依据。在医疗、法律、金融等容错率极低的领域,一个编造的答案可能带来实际损失,治理幻觉是构建可信AI应用的核心。
RAG 如何系统性地解决这三个问题?
既然问题的根源是“知识冻在参数里”,那么最直接的思路就是:不把知识放在参数里。
RAG (检索增强生成) 正是采用了这一思路:将知识存储在外部向量数据库中,当用户提问时,实时检索最相关的知识片段,并将其与问题一同组装成提示词(Prompt)交给LLM。这样,LLM就相当于在“开卷考试”——基于提供的“参考资料”作答,而非仅凭“记忆”发挥。
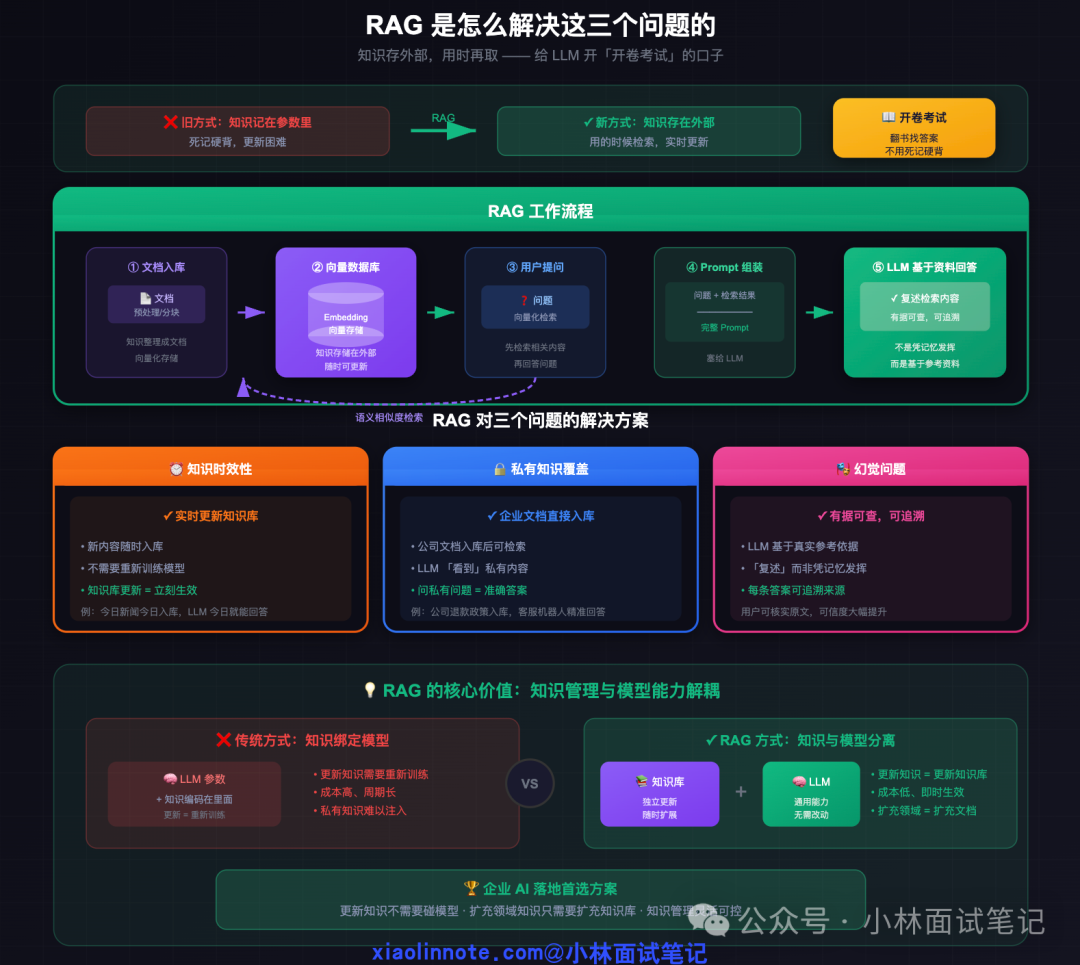
这一机制对上述三个问题实现了“一揽子”解决:
- 针对知识时效性:新知识(如今日新闻、最新财报)可以随时导入知识库,无需重新训练模型,更新即时生效。
- 针对私有知识覆盖:企业内部文档导入知识库后,LLM便能检索并利用这些内容来回答特定问题,实现精准回复。
- 针对幻觉问题:LLM的答案有了真实的文本依据,是在“复述”或“总结”检索结果,而非凭空编造,幻觉率显著降低。同时,答案可以追溯到源头文档,极大提升了可信度。
RAG的核心价值在于将“知识管理”与“模型推理能力”解耦。更新知识只需更新知识库,成本低、速度快;扩充领域知识只需导入新文档,灵活高效。这正是它成为企业AI落地首选架构的根本原因。
🎯 面试总结
回到开头的场景,面对“面试官”的提问,一个合格的回答需要体现系统性思考:
- 清晰指出三个具体问题:知识时效性、私有知识缺失、幻觉。
- 点明共同根源:这三个问题均源于“知识被冻结在模型参数中”这一LLM固有特性。
- 阐述RAG的解决思路:将知识外置,通过“检索-增强”的方式,在推理时动态提供相关知识,从而绕过模型参数的知识限制。
- 澄清常见误区:明确指出幻觉是知识缺失的“果”而非“因”,RAG是通过解决知识缺失这个“因”来根治幻觉。
掌握这个逻辑链条,你不仅能回答“RAG解决什么问题”,更能展现出你对LLM局限性及优化方案的深层理解。
 发表于 2026-4-13 02:26:24
|
查看: 184|
回复: 0
发表于 2026-4-13 02:26:24
|
查看: 184|
回复: 0
