“RAG里的文档是怎么存进向量库的?你说说Chunking怎么做。”
如果你在面试中被问到这个问题,只回答“切成小块”是远远不够的。一个扎实的回答需要深入理解为什么不能整篇存储、有哪些切割策略、以及如何根据文档类型进行选型。下面,我们就来系统地梳理RAG中的文档切割(Chunking)艺术。
为什么不能把整篇文档直接存进向量库?
首先,必须明确一个核心前提:原始文档不能直接存进向量库,必须先切成小块(Chunk)再存。原因主要有两点:
- 输入长度限制:主流的Embedding模型(如
text-embedding-ada-002)通常有输入token数量的限制(例如8191个token)。一篇数千甚至上万字的文档很容易超出这个限制。
- 信息模糊化:即使模型支持超长输入,将整篇文章压缩成一个向量,会导致细节信息被“平均掉”。当你检索“退款政策”时,向量中混杂的“配送时效”、“积分规则”等内容会稀释核心语义,导致检索结果笼统而不精确。
因此,文档入库的标准流程是:原始文档 → 切割成多个Chunk → 每个Chunk分别向量化 → 存储到向量数据库。一篇5000字的文档,切成500字一个Chunk,就会生成10条独立的向量记录。
向量库中的一条记录里有什么?
向量数据库中的每一条记录(对应一个Chunk)通常包含三个核心部分,它们各司其职,缺一不可:


可以用一个简单的类比来理解:
- 向量(Vector)是索引卡:它记录了这段内容在语义空间中的坐标,用于快速进行相似度检索,负责“找到”。
- 原文(Content)是书页:检索命中后,这部分原始文本会被原封不动地填入LLM的Prompt中,是LLM真正“阅读”的内容,负责“理解”。
- 元数据(Metadata)是书签:它记录了Chunk的来源信息,如文件名、页码、章节标题等,用于后期过滤(例如“只搜索产品手册”)和答案溯源。
在查询时,流程清晰明了:
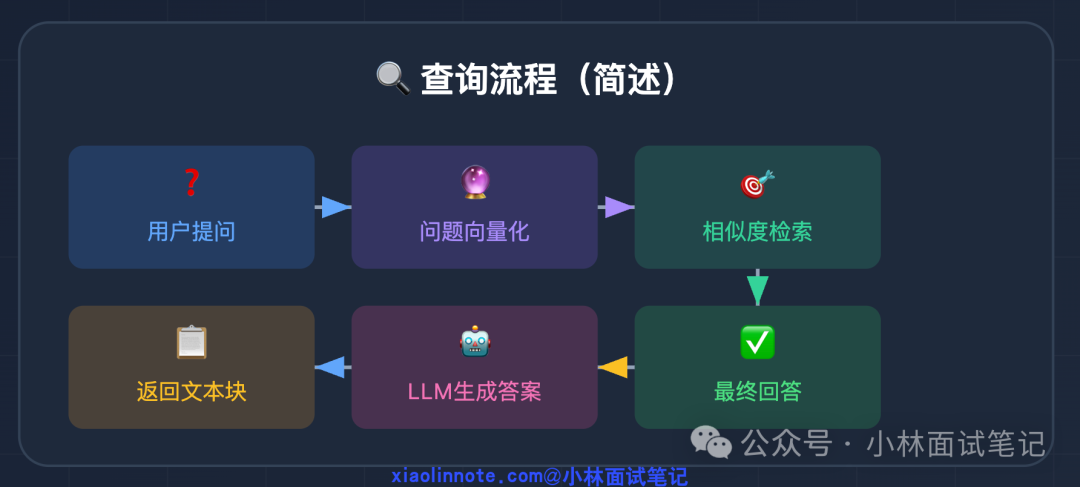
用户问题被向量化后,在向量库中寻找最相似的Chunk向量,然后取出该向量对应的原始文本,最后将其作为上下文交给LLM生成最终答案。
核心问题:Chunk应该切多大?
切割粒度(Chunk Size)的选择是在“检索精度”和“上下文完整性”之间做权衡。
- Chunk太大:向量包含的语义过于笼统,检索时容易召回不相关的内容,也更容易触发模型长度限制。
- Chunk太小:单个Chunk语义不完整,LLM缺乏足够上下文来理解,同时检索噪音会增多。
通常,500到1000个token是一个合理的起点。但更关键的是,要根据文档的具体内容结构和应用场景,选择合适的切割策略。
四大文档切割策略详解
策略一:固定大小切割(Fixed Size Chunking)
这是最简单、最基础的策略。顾名思义,按照固定的字符数或Token数进行切割,不关心语义边界在哪里。
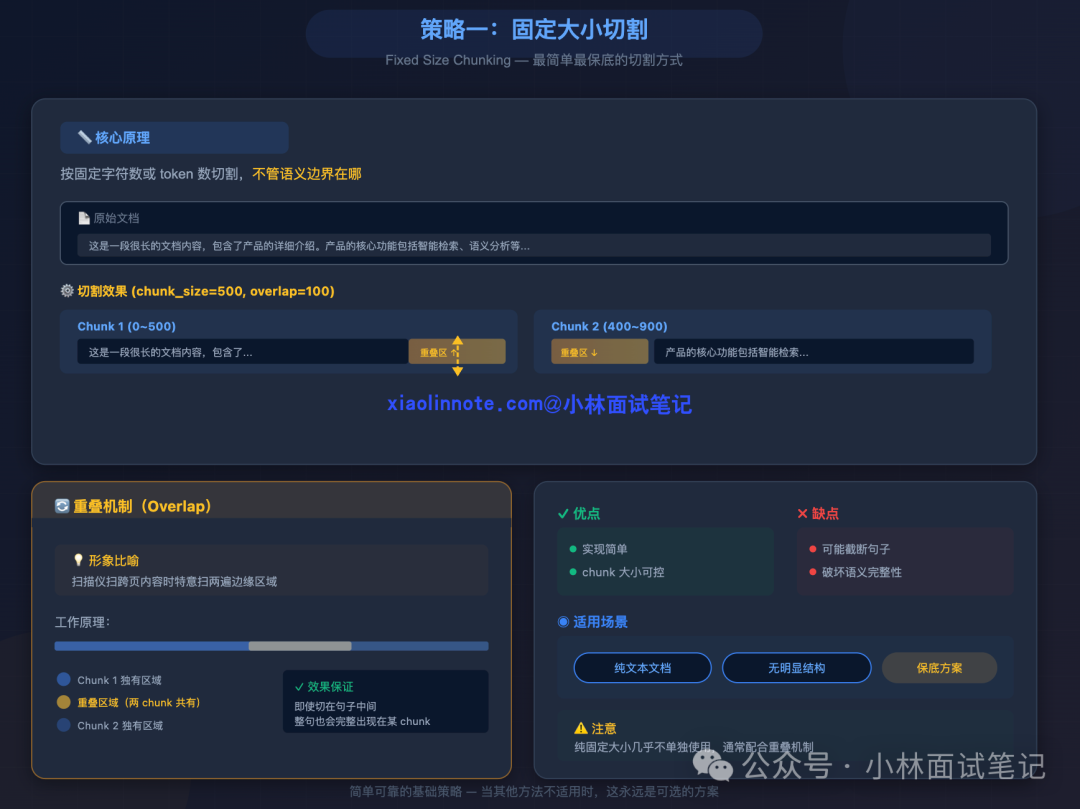
其优点是实现简单,Chunk大小完全可控。但致命缺点是可能从句子或段落中间截断,破坏语义的完整性。
因此,实践中几乎总会配合重叠机制(Overlap)使用。例如,设置chunk_size=500,overlap=100。这意味着第二个Chunk的前100个字符与第一个Chunk的后100个字符是重复的。这确保了即使切割点落在了一句完整的话中间,这句话也必然会完整地出现在其中一个Chunk里,就像扫描仪扫描跨页内容时会重复扫描边缘区域一样。
适用场景:无结构的纯文本文档,或作为其他策略失效时的保底方案。
策略二:语义边界切割(Semantic/Structure Based Chunking)
为了解决固定切割可能切断语义的问题,更优的策略是沿着文本天然的“断点”进行切割,例如段落、句子或标题层级。
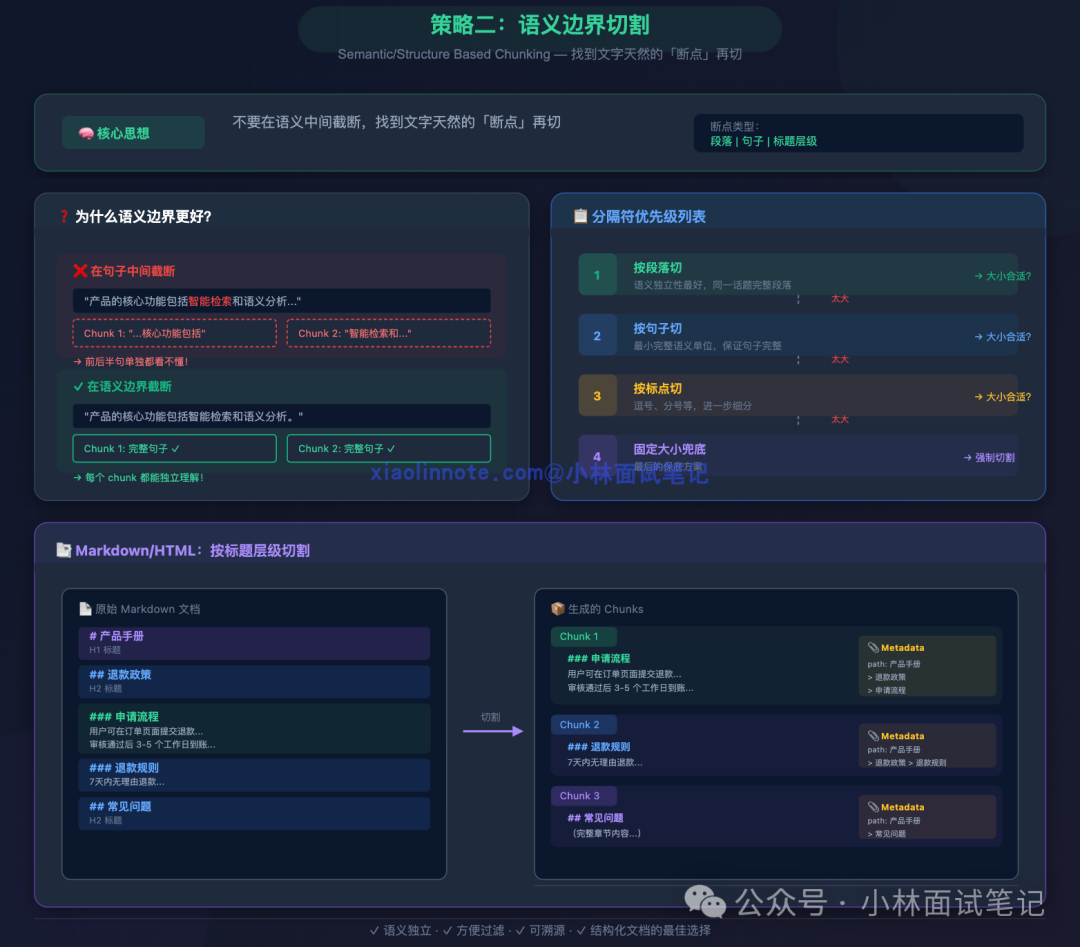
为什么这样更好? 因为一个完整的句子或段落是语义表达的最小(或较优)单位。在句子中间切断,前后半句都可能难以理解;而按完整段落切割,则能保证每个Chunk都围绕一个独立话题展开。
实现时,可以设定一个分隔符优先级列表(例如:换行符/段落 > 句号 > 分号 > 逗号),优先尝试按高级别边界切割,如果得到的Chunk仍然过大,再按下一级边界进一步分割。
对于Markdown、HTML这类有明确层级的结构化文档,最佳实践是按标题层级切割。每个Chunk对应一个完整的章节(如“## 退款政策”下的所有内容),并在元数据中记录其路径(如产品手册 > 退款政策 > 申请流程)。这样切割出的Chunk语义高度独立,且极其便于过滤和溯源。
策略三:特殊内容专项处理
通用文本切割策略在面对代码和表格时会“失灵”,必须专项处理。

- 代码文件:应以函数或类为最小单位进行切割。一个函数是完成特定逻辑的完整单元。从函数中间截断,会导致参数、逻辑和返回值分离,使得单个Chunk无法被理解。可以使用语法解析工具(如Python的AST、Tree-sitter)来准确识别代码结构边界。
- 表格:必须整块保留,通常转换为Markdown表格格式存储,绝不能按行截断。表格中的每一行数据都严重依赖于表头来定义其含义。单独看“2小时”毫无意义,但结合“响应时间”这一列名就清晰了。保留整表才能维持数据的上下文关系。
策略四:父子切割(Parent-Child Chunking)
当对检索质量和答案生成质量都有较高要求时,父子切割是一种非常有效的进阶策略。其核心思想是:用小Chunk实现精准检索,用关联的大Chunk提供完整上下文。

- 存储阶段:同一段内容存两份。
- 子Chunk(Child):较小(如200token),语义聚焦,用于向量检索,保证检索精度。
- 父Chunk(Parent):较大(如1000token),包含子Chunk及其周围的上下文,通过ID与子Chunk关联。
- 检索阶段:
- 用户查询被向量化后,首先在子Chunk中做相似度检索,找到最精准的匹配点。
- 根据命中子Chunk的关联ID,找到对应的父Chunk。
- 将父Chunk的完整文本(而非子Chunk)送入LLM生成答案。
这就像在图书馆用目录卡(子Chunk)快速定位到具体章节,但最终阅读的是整章内容(父Chunk)。此策略的代价是存储和索引构建成本翻倍,但在追求高质量的场景下往往物有所值。
策略选型速查表
| 策略 |
适用文档类型 |
优点 |
缺点 |
| 固定大小 + 重叠 |
纯文本、无明显结构 |
实现简单、大小可控 |
可能破坏语义完整性 |
| 语义边界切割 |
段落分明的文章 |
语义完整,召回质量好 |
实现稍复杂,Chunk大小不均 |
| 标题层级切割 |
Markdown、HTML文档 |
语义独立,自带结构元数据 |
依赖文档有清晰标题结构 |
| 代码按函数切割 |
源代码文件 |
保留代码逻辑完整性 |
需语法解析,有语言限制 |
| 父子切割 |
各类文档(追求高质量) |
兼顾检索精度与上下文完整性 |
存储量翻倍,索引构建复杂 |
面试与实战总结
回到最初的面试问题,一个完整的回答框架应该是:
- 阐明必要性:由于Embedding模型有长度限制,且整文档存储会导致语义模糊,所以必须切割。
- 解析存储结构:每个Chunk在向量库中存储为一条包含向量、原文和元数据的记录。
- 展示策略库:从基础的固定大小重叠切割,到更智能的语义/结构切割,再到针对代码表格的专项处理,以及高阶的父子切割。
- 体现选型思维:粒度(500-1000token)是起点,关键是根据文档类型选择策略。实践中常采用组合策略,例如“用固定大小重叠做兜底,对结构化文档用语义边界切割,在高要求场景使用父子切割”。
深入理解文档切割不仅是应对面试的关键,更是构建高效、精准RAG系统的基石。希望这篇梳理能帮助你在未来的技术面试和项目实战中更加游刃有余。
 发表于 2026-4-13 02:30:09
|
查看: 159|
回复: 0
发表于 2026-4-13 02:30:09
|
查看: 159|
回复: 0
