Intel近年的发展路径可谓一波三折,产品路线图屡次遭遇主动或被动延期。随着消费级DRAM市场的持续低迷,原定于今年年底发布的Nova Lake系列CPU也被迫推迟至2027年的CES大会,今年我们恐怕只能通过官方资料来解解馋了。
关于Nova Lake的架构细节我已经讨论过多次,而本文我想聚焦于Nova Lake的“反击”潜力。客观地说,Intel的Arrow Lake堪称一系列失误的集合体:完全依赖台积电代工、频率不升反降、Bug缠身的Lion Cove核心、游戏性能倒退、缺乏对位AMD X3D的产品、以及AVX-512指令集的持续缺失。到了Nova Lake这一代,局面终于有望扭转,可谓是 “该有的都有了”。
那么,Nova Lake究竟具备了哪些足以挑战AMD的关键特性呢?
1. AVX 512 强势回归!
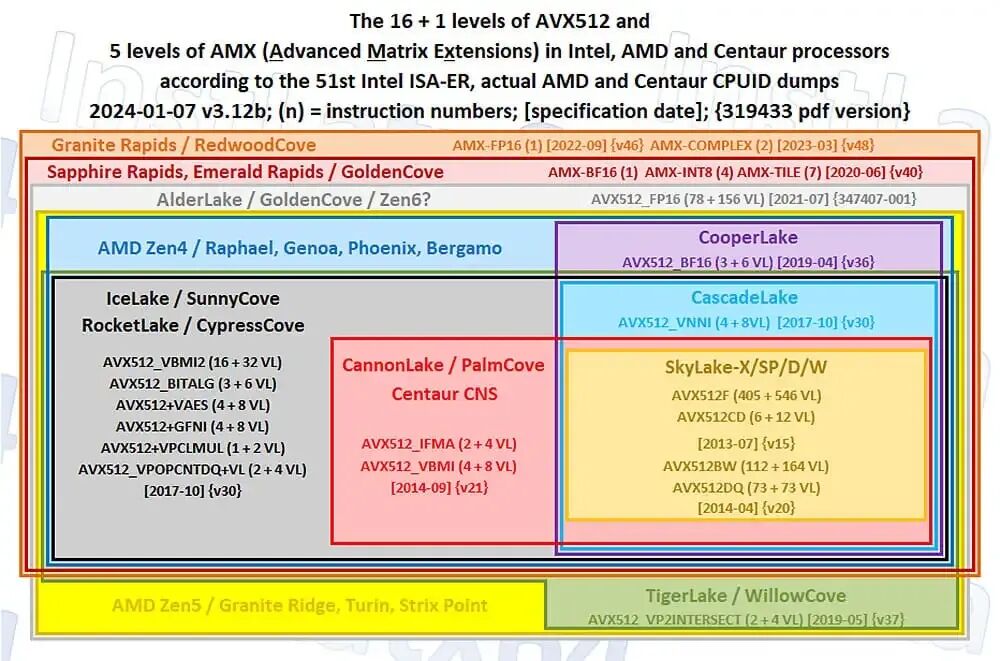
Intel一直是CPU高性能计算领域的首要推动者,从AVX到AMX(高级矩阵扩展)无不倾注了大量心血。当初Intel甚至在陈旧的14nm工艺节点上就实现了全宽度的AVX-512,而AMD直到Zen 5架构才勉强跟上。为了推广AVX-512,Intel也承受了不少争议。但颇具戏剧性的是,就在AVX-512即将步入成熟稳定期时,Intel却在第12代Alder Lake处理器上放弃了对它的支持,将亲手培育的优势拱手让给了对手,着实令人扼腕。

Alder Lake放弃AVX-512的原因简单粗暴:其能效核(E-core)在硬件上不支持AVX-512。为了保证大小核架构下的指令集一致性,Alder Lake只得整体屏蔽掉性能核(P-core)的AVX-512能力。这里需要澄清一点:尽管Intel的大小核是异构微架构,但在指令集层面,它们始终保持同构。

如果说Alder Lake和Raptor Lake因为初代能效核硬件先天不足而屏蔽AVX-512尚可理解,那么到了Arrow Lake这一第二代产品,AVX-512的持续缺席就非常说不过去了。事实上,Skymont/Darkmont这一代的能效核,其硬件已经配备了4个128位的SIMD单元,其吞吐能力足以满足半吞吐AVX-512(类似AMD Zen 4或Zen 5 APU的水平)的要求。在这样的硬件基础上,Intel不考虑增加AVX-512支持实在难以服众。尽管在这样的宽度下,支持AVX-512还是AVX-2并不影响SIMD的理论峰值吞吐,但AVX-512指令集包含了太多先进特性,最终结果就是即便在相同硬件宽度下,AVX-512也能大幅领先于AVX-2。
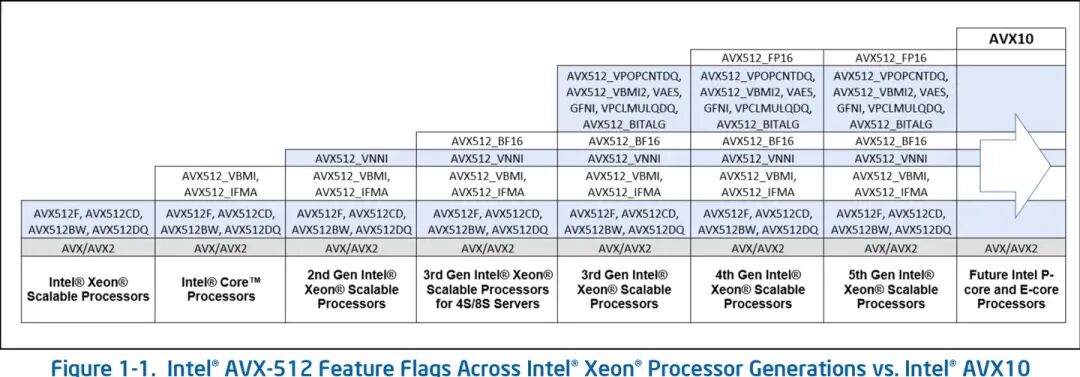
回到Nova Lake,目前已经确认它将支持AVX-512的迭代版本——AVX10.2指令集。这意味着,无论Nova Lake是否能直接运行为AVX-512优化的旧代码,它都为快速适配最新的向量计算标准铺平了道路。AVX10.2与AVX-512具有相同的宽度和压力模型,开发者只需更改编译器标志,就能将现有的优化成果直接迁移过来。支持AVX10.2的Nova Lake不仅能弥补向量计算这条“瘸腿”,更可能让搭载双bLLC计算模块的Nova Lake 16P+32E配置成为桌面AI工作站的利器。
2. 大缓存,王者归来!
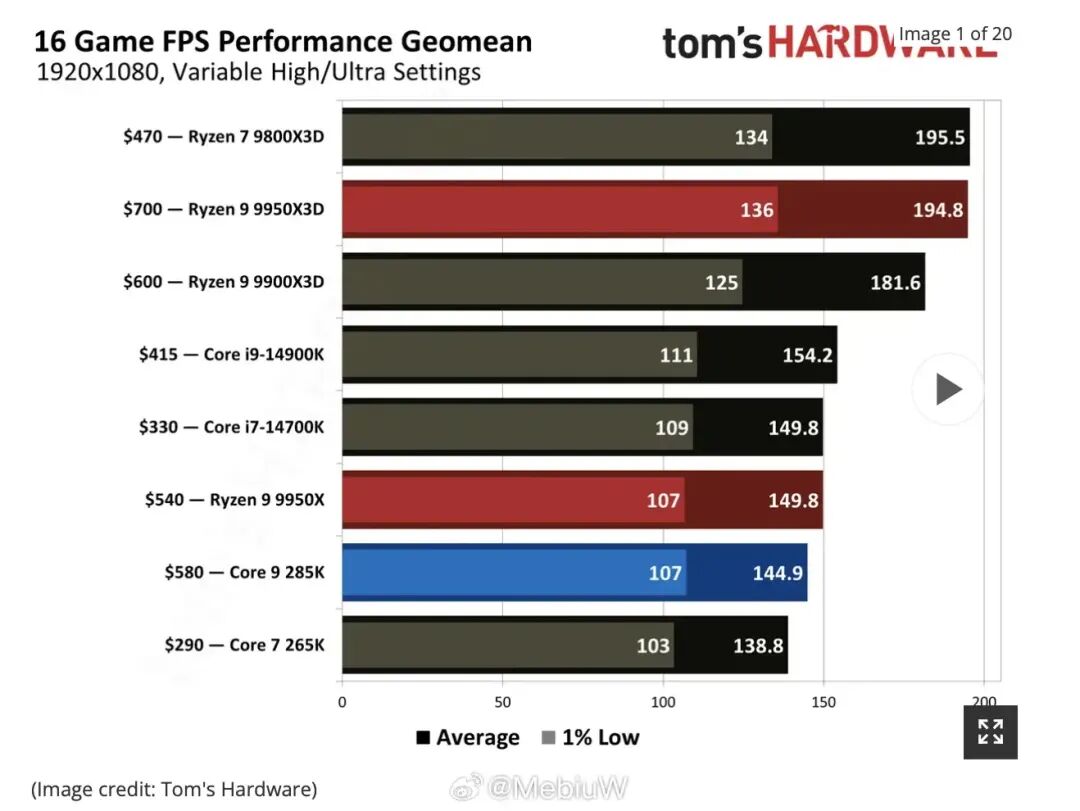
自酷睿时代开启以来,Intel CPU的游戏性能长期领先于AMD。即便是问题频出的Arrow Lake S,其在游戏表现上也基本与AMD Zen 5打平。AMD真正在游戏领域反超Intel,靠的是其跳出常规设计思路的大缓存X3D技术。
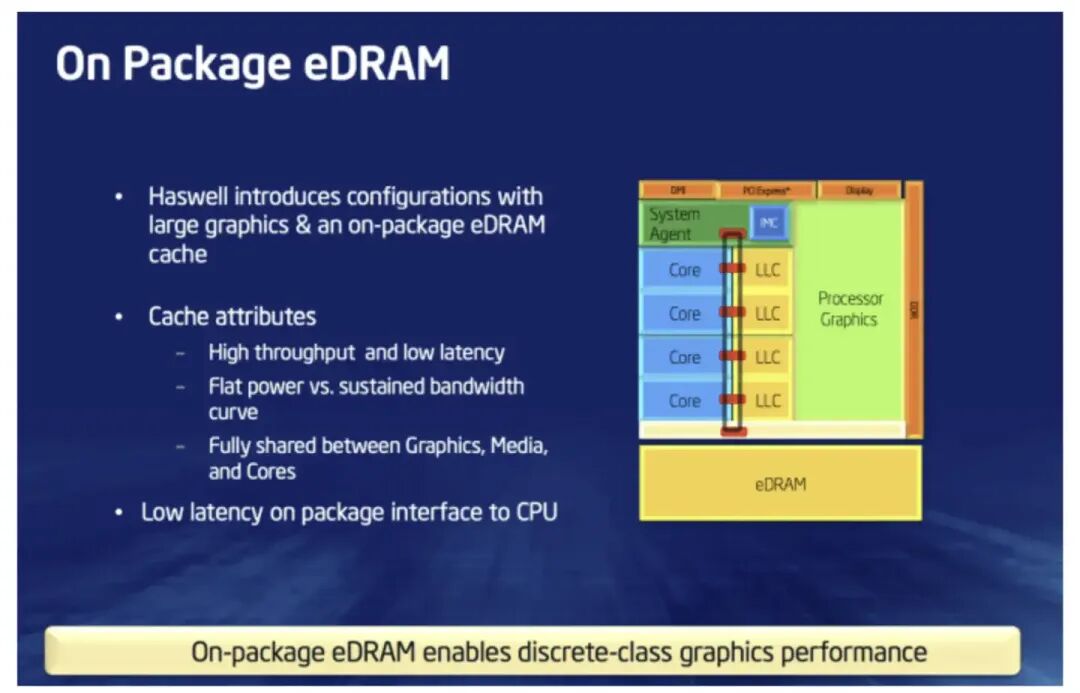
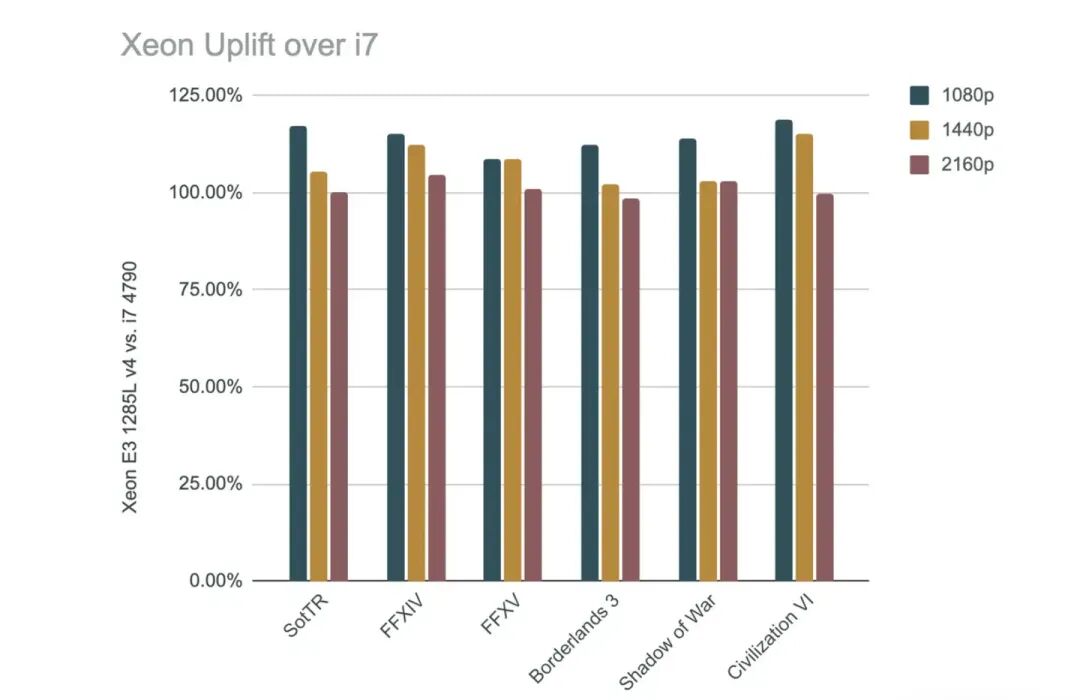
另一方面,我始终认为AMD的3D V-Cache虽然在3D堆叠缓存技术上独树一帜,但“给处理器外挂大缓存以提升游戏性能”这个思路并非AMD首创,其“鼻祖”恰恰是如今被X3D打得焦头烂额的Intel。早在Broadwell时期,Intel就推出过搭载eDRAM大缓存的桌面CPU。测试显示,即便使用比Haswell Refresh更低的频率,该处理器在1080p游戏中也获得了接近20%的性能提升。所以,在Intel本身深知大缓存功效且拥有自家技术方案的前提下,当看到AMD初代5800X3D取得巨大成功后,是否应该在7800X3D时代就及时跟进,至少不该错过9800X3D这一代?然而,没有如果,Intel直到Arrow Lake依然选择不上大缓存,随后又撞上了Lion Cove的核心Bug。

不过,转机出现在Nova Lake上。Intel终于为Nova Lake加上了bLLC(带宽优化末级缓存)大缓存。而且,与AMD采用落后工艺制造SRAM再进行堆叠的方案不同,Nova Lake的bLLC是实打实的原生L3缓存,在集成度和性能上理应显著优于外挂方案。采用N2工艺的SRAM与采用N6工艺的SRAM,谁能做出更高性能,答案不言而喻。

因此,只要Intel和AMD都按照正常的技术节奏发展,AMD不突然拿出“黑科技”或Intel不再出现重大失误,那么Intel Nova Lake在修复Lion Cove Bug、获得代际性能提升以及bLLC缓存加持的三重作用下,其游戏性能将非常值得期待。我目前的预测是,它将强于未来的Zen 6X3D。
3. 多计算模块时代降临!

在过去分析Intel和AMD的芯粒(Chiplet)策略时,我反复提及一个观点:Intel的策略(尤其是至强系列)是“物理上胶水,逻辑上统一”;而AMD则是“彻头彻尾的胶水”。直白地说,两者的核心区别在于,Intel的核心互联设计通常只有一级总线(网状或环形总线),导致其无法在物理上灵活配置核心(环形总线限制),或者扩展代价极大、上限较低(网状总线)。相比之下,AMD的芯粒设计虽然牺牲了部分互联效率,却可以灵活复用芯片,动态配置核心数量。因此,Intel在消费级市场要堆砌更多核心,往往只能重新流片全新的芯片。这种方式虽然能带来更好的性能,但其高昂的成本在激烈的市场竞争中并不占优。

转机出现在Lunar Lake和Panther Lake所采用的SoC总线上。在经历了Meteor Lake/Arrow Lake初期的双集群尝试后,Lunar Lake / Panther Lake的SoC总线已经能够挂载多个不同的CPU集群,并实现正常的调用与通信,其模式类似于AMD将多个CCD(核心复合芯片)连接在一起。
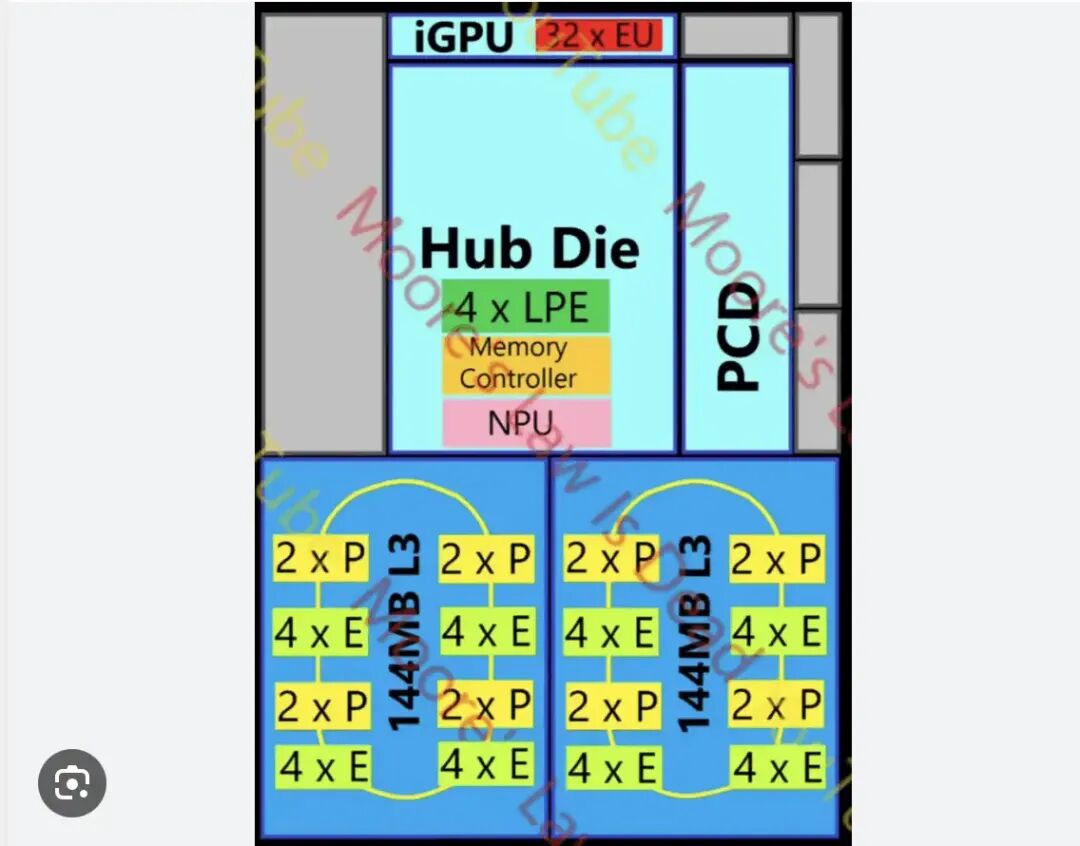
基于这一新的总线设计,虽然Lunar Lake和Panther Lake只是挂载了一个低功耗能效核集群,但这项技术的出现释放了一个重要信号:未来Intel也可以像AMD一样,直接叠加多个计算模块。因此,我们在Nova Lake上终于看到了这样的设计——它可以挂载两个计算模块,实现核心数量翻倍,从而在多线程跑分上“师夷长技以制夷”。不仅如此,大家应该意识到,Intel未来可能全面转向这项技术,推出更多核心堆叠密度更高的产品。顺便提一下,服务器端的Clearwater Forest虽然用了复杂的互联,但其本质仍然是“物理胶水,逻辑统一”。
小结:迟到的“完全体”
除了上文重点剖析的三大特性,Nova Lake还具备许多其他亮点,感兴趣的朋友可以翻阅我之前的文章或关注后续更新。总的来说,除了P核心本身仍然基于Cove架构的“历史包袱”,Nova Lake在CPU设计上几乎集齐了目前x86平台所有能拿出的好东西。仅从纸面参数来看,我对Nova Lake的期待值非常高。如果Nova Lake再次失利,那么唯一能指望的恐怕就只有未来的“统一核心”(Unified Core)架构了。
最后,可能有人会问,Nova Lake又将内存控制器放在了SoC(枢纽芯片)一侧,这是否是个问题?我想说,首先,AMD也是如此设计,这绝非Arrow Lake翻车的根本原因。其次,既然要走向真正的模块化设计,内存控制器就不可能继续放在CPU计算模块一侧。对于这类前沿的芯片设计与性能分析,云栈社区 将持续关注并分享深度解读。
 发表于 2026-3-1 16:08:10
|
查看: 183|
回复: 0
发表于 2026-3-1 16:08:10
|
查看: 183|
回复: 0
