很多人过去对 AI 写代码还有个心理安慰:它最多也就写写脚手架、补补页面,真到了核心算法和业务逻辑,终究还得靠人来把控。
但现在,这道看似稳固的“最后防线”,也开始动摇了。谷歌 DeepMind 最近做了一件更激进的事:他们直接让 LLM 驱动的智能体去改写和进化算法代码本身——注意,不是调参数,而是修改底层的算法逻辑。
改写后的代码会被直接投入真实的博弈环境中反复运行,由系统自动评估性能、优胜劣汰,进行一轮又一轮的进化。结果如何呢?这个名为 AlphaEvolve 的智能体,真的创造出了 全新的多智能体学习算法,在多项测试中性能超越了人类专家手工打磨的现有版本。
更重要的是,它所发现的机制往往并不直观,属于人类专家很难通过经验和穷举找到的解决方案。整个过程形成了一个从生成、测试到筛选的全自动闭环,人类只负责定义算法框架和评估标准,无需手动调参或反复试错。

AlphaEvolve 延续了 DeepMind 一贯的“Alpha”命名传统(如 AlphaGo、AlphaFold),“Evolve”意为“进化”,精准地概括了其核心机制:通过类似生物进化的方式不断改写和筛选代码。虽然 AlphaEvolve 本身并非全新概念,但这是它首次被应用于自动发现和优化学习算法。
该系统将 Gemini 系列大语言模型与进化搜索相结合,实现了代码的持续生成、测试、筛选与再进化。

DeepMind 将这项研究整理成了一篇长达 37 页的论文,题为《Discovering Multiagent Learning Algorithms with Large Language Models》(基于大语言模型的多智能体学习算法自动发现),一经发布便在技术圈引发了广泛讨论。

有网友在社交媒体上表达了自己的震撼,认为这可能是 DeepMind 乃至谷歌的一张“王牌”。也有人形象地比喻道:“这就像教一个孩子读书,然后看着它自己编写教科书。” 更有人开始思考更长远的问题:既然 AI 已经能设计出更好的学习算法,那么或许它也应该被赋予优先设计一套完善的“伦理引擎”的任务,以确保在迈向更高级人工智能之前,对齐问题已得到妥善解决。
人只定义框架,AI实现全自动闭环进化
那么,这个实验具体是如何设计的呢?首先,研究团队并没有让模型“从零开始”编写算法,而是选定了两个成熟且理论扎实的多智能体强化学习框架作为进化起点:
- CFR:反事实后悔最小化算法族,其核心在于通过递归方式累积后悔值并构建平均策略。
- PSRO:策略空间响应预言算法,通过迭代计算最优响应并求解元策略,来不断扩展策略种群。
长期以来,在不完全信息博弈(如扑克)的求解中,尽管 CFR 和 PSRO 等经典算法理论基础坚实,但其最高效的“变体”往往依赖于人类专家的经验,通过手动调参、修改规则和大量试错来获得。
在这项工作中,研究人员将算法的核心逻辑拆解为几个可供改写的 Python 函数模块,例如:后悔值累积规则、当前策略生成方式、平均策略更新规则以及 PSRO 的元策略求解器逻辑。这意味着,他们只向大语言模型开放了“关键决策逻辑”的修改权限,而整体算法框架保持固定。这一步至关重要,相当于为进化过程定义了明确的“基因”搜索空间。
随后,真正的“进化”环节启动。AlphaEvolve 将当前版本的算法代码视为一个“个体”,由大语言模型生成多个在语义上有意义的改写版本。这些改写并非随机变动,而是针对具体逻辑、控制流或更新规则进行修改。每一个新生成的算法变体都会被自动编译、运行,并投入一组预设的博弈环境(如 Kuhn Poker、Leduc Poker 等)中进行实战测试,使用“可剥削性”等指标进行量化评分。表现优异的版本被保留,作为下一轮搜索的“父代”;表现不佳的则被淘汰。
整个过程形成了一个完整的自动化闭环:生成 → 运行 → 评估 → 筛选 → 再生成,循环推进。人类研究者不参与中间的参数调整或版本筛选,仅负责设定初始规则和最终的评价标准。
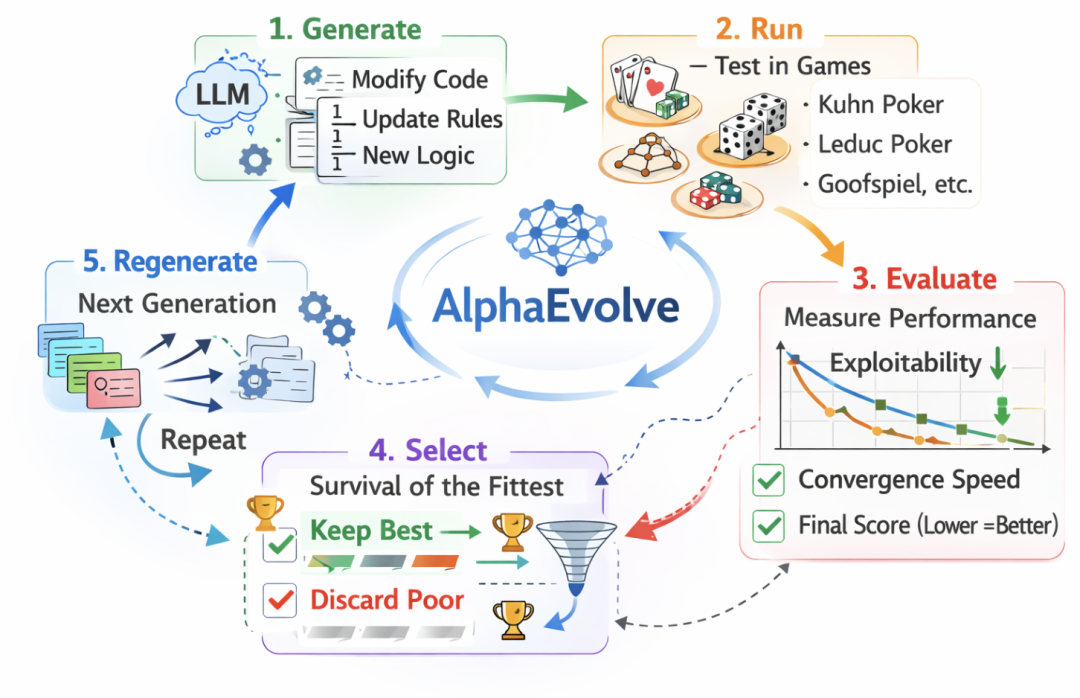
(图示:AlphaEvolve 自动化进化工作流程,此图亦由 AI 生成)
最终,通过这套进化流程,AI 创造出了两个全新的算法。
成果一:VAD-CFR —— 更高效的反事实后悔最小化算法
在 CFR 方向上,AlphaEvolve 进化出了名为 VAD-CFR 的新算法。它没有停留在调整表面参数,而是直接改动了“后悔值如何累积、如何折现、何时开始计算平均策略”等核心逻辑。
例如,它引入了“波动敏感性折现”(根据历史表现的波动性动态调整折现因子)、“一致性增强的乐观策略”以及“硬性预热启动策略累积计划”等非直观的机制。尽管这些机制听起来有些抽象,但其效果显著:在多个不完全信息博弈测试中,VAD-CFR 的表现超越了目前由人类专家精心打磨的最佳基线算法。
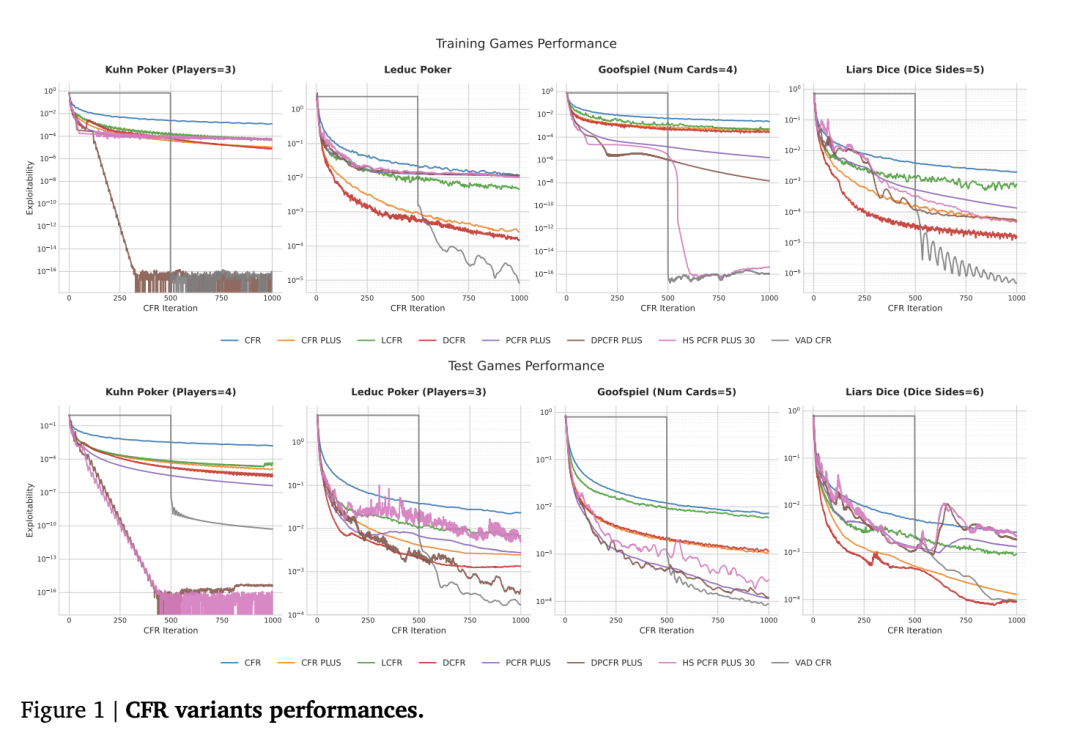
上图直观展示了多种 CFR 变体在不同博弈环境中的收敛表现。上半部分为训练阶段使用的游戏,下半部分为规模更大、更复杂的测试游戏。横轴代表迭代次数,纵轴为“可剥削性”(数值越低,表明算法越接近纳什均衡,性能越好)。
图中灰色的曲线代表 VAD-CFR。可以观察到,在大多数游戏中,它的曲线下降速度更快,且最终达到的均衡点更低,明显优于 CFR+、DCFR、PCFR+ 这些经过人类多轮优化的版本。在某些游戏中,大约在 500 次迭代后,VAD-CFR 的曲线下降速度明显加快——这正是其设计的“硬性预热启动”机制结束,开始全力冲刺的时刻。这种“前期蓄力,后期发力”的模式,并非人类设计者的常规思路。
更重要的是,在规模更大、难度更高的测试游戏中,VAD-CFR 的优势依然得以保持,并未出现“过拟合”训练环境的情况。这证明,它所发现的是一种在算法结构层面更为高效的更新方式,而非针对特定游戏的小技巧。
成果二:SHOR-PSRO —— 更灵活的元策略求解器
在 PSRO 方向上,AI 进化出了 SHOR-PSRO 算法。它的创新之处在于重新设计了“元策略求解器”。
传统的元求解器往往在“探索策略多样性”和“逼近博弈均衡”之间采取固定的权衡策略。而 SHOR-PSRO 直接设计了一种混合型元求解器,将多种更新机制(如乐观后悔匹配与平滑分布)线性结合,并且随着训练进程动态调整混合系数,使得整个训练过程能够自动地从早期的“多样性探索”平滑过渡到后期的“均衡逼近”。
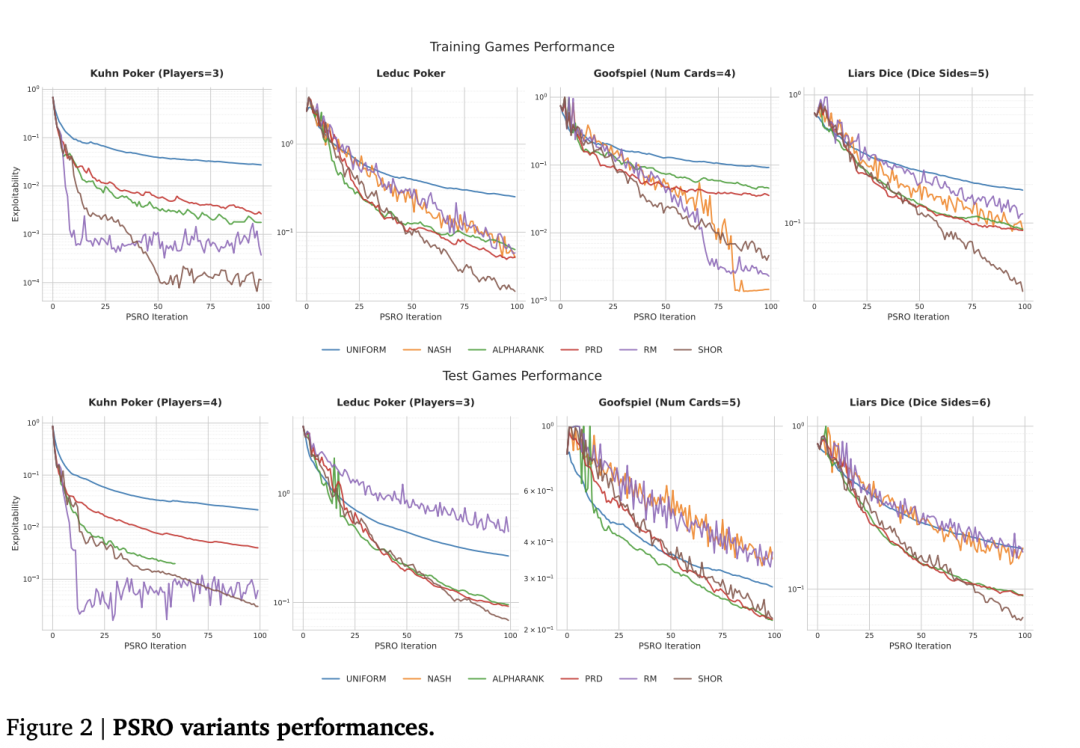
上图对比了 SHOR-PSRO 与 Uniform、Nash、AlphaRank、PRD、RM 等经典元求解器的性能。图表同样分为训练游戏和测试游戏上下两部分。横轴为 PSRO 迭代次数,纵轴为可剥削性。
可以看到,在大多数游戏中,代表 SHOR 的棕色曲线下降更快,并且在 100 次迭代时达到的可剥削性数值更低。即使在更复杂的测试游戏(如 4 人库恩扑克、6 面骰子的 liar‘s dice)中,SHOR 的优势依然明显。简而言之,SHOR-PSRO 在“何时侧重探索、何时专注收敛”的动态调度逻辑上,表现得比传统固定方法更灵活、更智能。
它的胜利不是依靠参数微调,而是通过改变调度逻辑本身实现的。
这项研究展示了利用大语言模型结合进化搜索来自动探索广阔算法设计空间的巨大潜力。对于从事算法研究和 强化学习 的开发者而言,这或许预示着一个新范式的开端:人类更多地扮演框架定义者和目标制定者的角色,而将具体的、甚至是非直觉的优化路径探索,交给具备强大代码生成与推理能力的 AI 智能体。想了解更多前沿 AI 与算法技术的探讨,欢迎访问 云栈社区 与同行交流。
相关资源:
 发表于 2026-3-3 03:51:24
|
查看: 107|
回复: 0
发表于 2026-3-3 03:51:24
|
查看: 107|
回复: 0
