一、研究背景与问题定位
大模型在复杂智能体任务中面临“性能-效率”失衡的核心难题:单一大模型要么因能力不足无法解决高难度任务(如HLE),要么因过度依赖强模型导致计算成本与延迟激增,且难以适配用户个性化工具使用偏好。
当前主流工具调用范式存在显著局限:基于现成模型提示的编排策略存在系统性偏见,或过度依赖同体系模型变体,或盲目调用最强工具忽视成本;同时现有方法未兼顾任务正确性、资源效率与用户偏好的多目标优化。
我们提出ToolOrchestra框架,通过训练8B参数量的轻量编排模型(Orchestrator),以强化学习实现多工具(含专业/通用大模型)的动态协同,同时构建ToolScale合成数据集保障训练,实现性能与效率的平衡及用户偏好对齐。
论文:ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration

二、方法创新
1. 模型结构

Orchestrator的核心是多轮推理-工具调用-反馈的闭环迭代架构,其形式化表示为马尔可夫决策过程(MDP),各组件定义如下:
- 输入空间:包含用户指令与工具偏好;
- 状态空间:刻画环境与交互历史的综合状态;
- 动作空间:所有可调用工具(基础工具、专业LLM、通用LLM)的集合;
- 观测空间:工具调用后的反馈结果;
- 转移函数:描述动作触发的状态变迁;
- 观测函数:定义状态对应的观测输出;
- 奖励函数:衡量轨迹的任务完成度、效率与偏好匹配度;
- 初始状态分布:指令对应的初始状态采样规则;
- 折扣因子:平衡即时与长期奖励。
其闭环迭代流程可表示为如下方程组:
其中,为第步的交互历史,为编排模型的策略网络,为轨迹的综合奖励。该框架通过“推理规划→工具调用→反馈接收→状态更新”的循环,实现复杂任务的逐步拆解与求解,形成完整的闭环决策链路。
2. 针对多目标优化问题的强化学习算法
主流大模型工具调用的核心瓶颈在于单目标导向的优化缺陷:仅追求任务正确率会导致算力浪费,仅关注效率则牺牲性能,且忽视用户工具使用偏好。为此,我们设计了融合“结果正确性、资源效率、用户偏好”的多目标算法优化框架,基于Group Relative Policy Optimization(GRPO)实现策略迭代,解决多目标权重平衡与训练稳定性问题。
步骤1:多维度奖励定义
首先,针对轨迹定义三类基础奖励:
- 结果奖励:衡量任务完成正确性,为二元取值:完成任务否则该奖励由GPT-5作为裁判,对比输出答案与真值的一致性。
- 效率奖励:包含计算成本与时间延迟惩罚:其中为轨迹的总调用成本(按第三方API定价折算),为耗时,负号表示成本/延迟越高,奖励越低。
- 偏好奖励:基于用户工具偏好向量计算,先构建轨迹特征向量(为工具的调用次数),再对做批次归一化:其中和为批次内第维特征的最值,归一化后消除量纲差异。
步骤2:综合奖励计算
将归一化后的特征与偏好向量加权,得到轨迹的最终奖励:
其中为工具数量,为第维的偏好权重(),例如表示优先使用工具,表示优先保证正确率。
步骤3:GRPO策略更新
在GRPO框架下,首先计算轨迹的优势值(组内奖励归一化):
其中为组内轨迹集合,衡量轨迹相对组内平均水平的优劣。
随后,通过以下目标函数优化策略,实现策略的平稳迭代:
其中为策略似然比,为裁剪系数(控制策略更新幅度),为KL散度惩罚系数(保障策略平滑性)。该公式通过“裁剪优势项+KL惩罚”解决强化学习训练中的过拟合与不稳定问题。
3. 针对训练数据稀缺问题的数据合成与算法优化
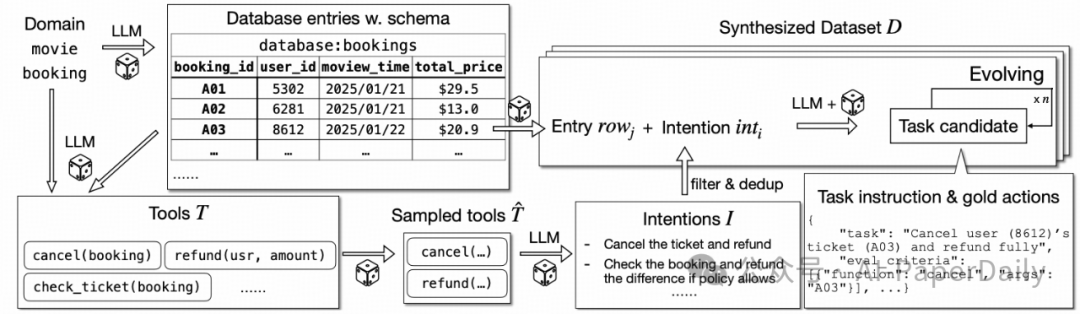
大模型编排器训练的关键瓶颈是高质量多轮工具调用数据稀缺,为此我们设计了“环境生成→任务合成→难度增强→质量过滤”的自动化数据合成管线:
- 环境生成:针对10个领域(金融、医疗、电商等),生成领域专属数据库(含表结构与条目)与工具API,例如电影领域生成cancel_booking、refund_ticket等工具;
- 任务合成:基于领域意图库,将抽象意图转化为具体任务,生成包含“指令-黄金工具调用序列-验证标准”的三元组;
- 难度增强:通过添加约束、扩展实体等方式提升任务复杂度;
- 质量过滤:剔除“工具调用报错、模型无法求解、无需工具可完成”的无效任务。
最终生成的ToolScale数据集包含超4000个多轮工具调用任务,覆盖复杂环境与多样工具组合,为强化学习提供充足的监督信号。
创新点2:训练稳定性优化算法
为解决多目标强化学习中的训练震荡问题,我们引入三项优化策略,对应如下公式约束:
- 同质性过滤:当批次内奖励标准差时,过滤该批次(信号过弱无训练价值):
- 格式一致性过滤:过滤工具调用格式错误的轨迹,保证输入输出对齐:格式不匹配预设模板
- 无偏KL估计:修正传统KL估计的系统性偏差,引入策略重要性权重:该估计消除了低概率轨迹的梯度爆炸问题,保障策略更新的平稳性。
创新点3:工具调用泛化性优化
为提升编排器对未知工具的适配能力,我们在训练中引入动态工具配置:
- 工具子集随机采样:每个训练实例仅采样工具集的子集,模拟用户工具访问的异质性;
- 定价策略随机化:在不同训练批次中调整工具调用成本,让模型学习成本敏感的决策逻辑。
对应的数学表示为,对工具集,每个批次随机生成子集,并为内工具分配随机定价,其中为均匀分布,使模型学习到“工具可用性-成本-能力”的全局权衡。
三、实验验证
我们在HLE、FRAMES、-Bench三大基准上验证Orchestrator的性能,关键量化结果如下:
- 性能领先:Orchestrator-8B在HLE上得分37.1%,超越GPT-5(35.1%);在FRAMES上达76.3%,在-Bench上达80.2%,均为所有对比模型最优;
- 效率优势:其平均单任务成本仅9.2美分、延迟8.2分钟,相比GPT-5(成本30.2美分、延迟19.8分钟),效率提升2.5倍以上,仅为Claude Opus 4.1成本的12%;
- 泛化能力:面对训练未见过的工具集(如Codestral-22B、DeepSeekMath-7B),仍能保持22.0%的HLE得分,远超同参数量基线;
- 偏好对齐:在偏好感知测试集上,Orchestrator的偏好匹配得分达46.7%(HLE)、68.4%(FRAMES),显著高于GPT-5的34.6%与37.9%。
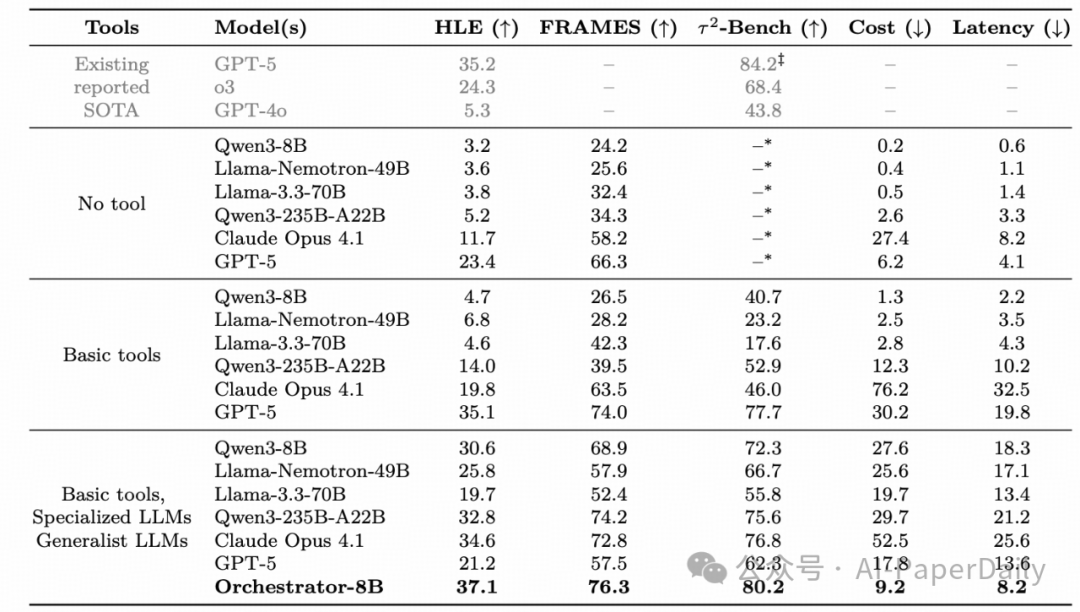
实验数据显示,在高难度复杂推理场景下,Orchestrator-8B实现了比GPT-5更高的任务准确率,同时将计算成本降低至30%左右,充分验证了算法在“高性能-高效率-高适配”多目标下的有效性与稳定性。
 发表于 2025-12-7 19:53:19
|
查看: 164|
回复: 0
发表于 2025-12-7 19:53:19
|
查看: 164|
回复: 0
