最近我在开发基于 MQTT 的固件升级功能时,遇到了一个棘手的问题:设备无法一次性成功下载完整的固件文件。为了提升传输效率,我尝试增大了 lwip 协议栈的 TCP_WND(接收窗口)大小,没想到这个改动却引发了更大的 Bug。
我发现应用层读取到的 TCP 数据竟然不是按顺序的。

这很奇怪,我们都知道,TCP 协议的一大核心特性就是保证数据的顺序交付。即便底层网络包(比如在 Wi-Fi 环境下)可能是乱序到达网卡的,协议栈也应该在内部处理好重组和排序工作,最终将有序的数据流提交给应用层。
为了定位问题,我一边用 Wireshark 抓包观察网络流量,一边在 lwip 最底层的网络包接收函数里添加了调试代码,直接统计和分析收到的每一个数据包。
uint32_t g_low_level_input_cnt = 0;
uint32_t g_tcp_port_8080_cnt = 0;
uint32_t g_tcp_seq_numbers[256] = {0};
uint16_t g_tcp_seq_index = 0;
uint32_t g_custom_pbuf_error;
uint32_t g_rx_buf_alloc = 0;
// 解析 8080 端口包
static void count_tcp_port_8080(const uint8_t *frame, uint32_t framelength)
{
if (frame == NULL)
{
return;
}
if (framelength < (SIZEOF_ETH_HDR + 20U))
{
return;
}
const struct eth_hdr *eth = (const struct eth_hdr *)frame;
if (lwip_ntohs(eth->type) != ETHTYPE_IP)
{
return;
}
const uint8_t *ip = frame + SIZEOF_ETH_HDR;
const uint16_t ip_header_len = (uint16_t)((ip[0] & 0x0FU) * 4U);
if (ip_header_len < 20U)
{
return;
}
if (ip[9] != 6U)
{
return;
}
if (framelength < (SIZEOF_ETH_HDR + ip_header_len + 20U))
{
return;
}
const uint8_t *tcp = frame + SIZEOF_ETH_HDR + ip_header_len;
const uint32_t seq = ((uint32_t)tcp[4] << 24) | ((uint32_t)tcp[5] << 16) |
((uint32_t)tcp[6] << 8) | (uint32_t)tcp[7];
const uint16_t src_port = (uint16_t)((tcp[0] << 8) | tcp[1]);
const uint16_t dst_port = (uint16_t)((tcp[2] << 8) | tcp[3]);
if (src_port == 8080 || dst_port == 8080)
{
g_tcp_port_8080_cnt++;
g_tcp_seq_numbers[g_tcp_seq_index] = seq;
g_tcp_seq_index = (uint16_t)((g_tcp_seq_index + 1U) % (sizeof(g_tcp_seq_numbers) / sizeof(g_tcp_seq_numbers[0])));
}
}
调试结果确认,底层函数确实已经收到了所有的数据包。但诡异的事情发生了:上层的 lwip_read 函数获取到的数据,并不是第一个数据包(Seq=1),而是后面的某个包。
而且这个问题总是发生在服务器发送 【TCP Window Full】 提示的附近。更奇怪的是,STM32 的底层驱动函数明明只处理了开头的几个数据包,可应用层的 lwip_read 却已经读到了更新的、序列号更大的数据...
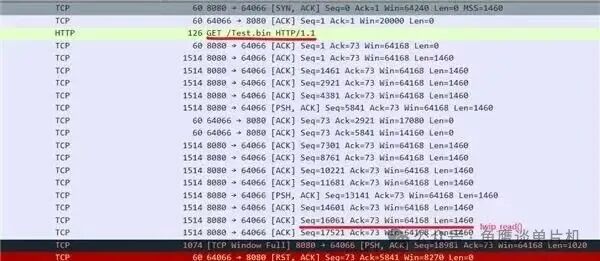
等等,“读到了更新的数据”?灵光一闪,我瞬间明白了。
只有一种情况能解释这种“时空错乱”的现象:DMA(直接内存访问)。只有它,可以在不经过 CPU 干预的情况下,直接操作硬件并修改内存缓冲区。
回头仔细查看 lwip 和 STM32 ETH 驱动的源码,果然如此。驱动为了追求极致性能,使用了 零拷贝 技术。DMA 直接将网络数据包写入应用层可能正在使用的缓冲区,而当接收描述符环(RX Descriptor Ring)复用或管理不当时,DMA 有可能覆盖掉尚未被应用层读取的旧数据包缓冲区。这就导致 read 函数读取的数据看起来是乱序的,实际上是旧数据被新数据覆盖了。
找到原因后,我立刻将驱动从零拷贝模式改为拷贝模式(即 DMA 先将数据放到专用缓存,再由 CPU 复制到 pbuf)。改动之后,数据果然能够顺序接收了!问题似乎解决了。
但好景不长,新的问题接踵而至:接收速度变得非常慢,而且偶尔仍然会出现非顺序接收的情况。
这又是怎么回事?隐约记得几年前好像处理过类似的问题。于是我翻遍了代码仓库的提交记录,终于找到了。原来在另一个项目里,我真的掉进过同一个坑,而且这个坑在项目代码完全不同的情况下依然存在。
LWIP_MEMPOOL_DECLARE(RX_POOL, ETH_RX_DESC_CNT, sizeof(struct pbuf_custom), "Zero-copy RX PBUF pool");
我赶紧按照历史经验处理了缓冲区管理的问题,并将接收窗口等配置恢复原状。至此,TCP 数据顺序交付的问题才算是真正搞定,设备可以完整下载固件了。不过,网络仍然存在一些丢包,这应该是 STM32 驱动和 lwip 协议栈的其他配置(如缓冲区大小、中断处理等)还需要进一步调优,但至少核心的乱序问题解决了。
这次调试经历让我深刻体会到,在嵌入式网络开发中,数据流涉及多个环节:ETH 硬件 -> DMA -> 描述符列表 -> 内存池 -> 应用程序。任何一环配置不当,都会导致难以排查的问题。尤其让人疑惑的是,lwip 的 TCP_WND 参数似乎可以随意设置,但在理想情况下,它应该与 STM32 底层驱动的接收缓冲池大小、DMA 描述符数量等硬件限制紧密关联才对。在 云栈社区 与同行交流时也发现,这类底层协议栈与硬件驱动配合的“坑”,往往是嵌入式网络开发中的共性挑战。
 发表于 2026-3-5 05:33:16
|
查看: 167|
回复: 0
发表于 2026-3-5 05:33:16
|
查看: 167|
回复: 0
