对我而言,过去这40天是神奇的。我连续写出了三篇阅读量超过10万的文章,以及超过10篇阅读量破万的内容。



随之而来的,是读者关注数从6700多,一路增长到超过4万8,净增超过4.2万。
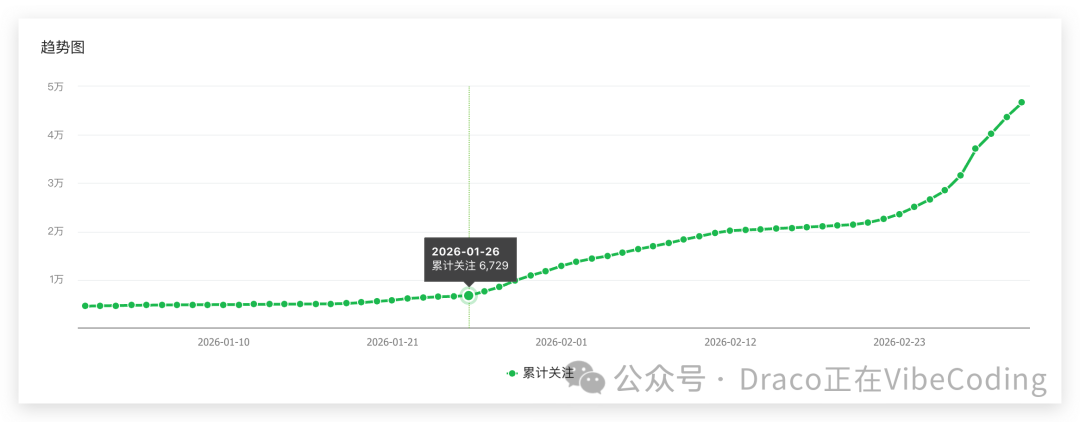
第一篇“10万+”或许有运气的成分,但后续能持续产出大小爆款,我认为其中有一些关键的方法值得复盘和记录。这些经验对于任何想在技术内容创作领域有所建树的朋友,或许都有参考价值。
1. 利他:从“自嗨”到服务读者
你是否也曾写过“自嗨式”的技术文章?回顾过去,我不少内容就偏向于此——本质上是“利己”,不顾读者诉求,单方面吧唧吧唧自说自话。今天回头看,除了自我感觉良好,几乎没帮到谁。

观念转变后,我的选题流程变成了这样:
- 先问自己:我对这个话题是否真的感兴趣?
- 再拷问自己:大概会有多少读者也对它感兴趣?
如果第二个问题的答案是“没多少”,那么无论我个人多喜欢这个选题,也没必要把它写成公开的技术文章。写作的起点,应该是读者的需求,而非作者的表达欲。
其次,是“不藏私”。这其实也是 “learn in public, build in public” 精神的内核。阳光下没有新鲜事,技术领域尤其如此,很少存在“我想到了别人没想到”的独家秘籍。因此,完全可以放心大胆地把所知所想分享出来。当你真心帮助到读者时,他们会用积极的反馈来回馈你。
最后,是积极互动。这40天里,我在公域和私域回复了可能有好几百条读者的提问。当然,前提是“知之为知之,不知为不知”,绝不能不懂装懂,这是对读者的基本尊重。
2. 指向行动:降低读者的执行门槛
福格行为公式 (Fogg Behavior Model) 指出:B (Behavior) = M (Motivation) · A (Ability) · P (Prompt)。翻译过来就是:行动 = 意愿 × 能力 × 提示。
这意味着,M(动机)、A(能力)、P(提示)三者缺一不可,行动就无法发生。对于很多有价值的技术实践,读者往往不缺意愿(M),也不缺看到文章这个提示(P),他们真正卡住的地方,是“能力”(A)——即“我不知道具体怎么做”。
所以,高价值技术文章的核心作用之一,就是补全这个“A”。我阅读量最高的一篇,正是用近2万字的篇幅,手把手带领新手读者完成 openclaw 部署的几乎每一个步骤,配以几十张截图和命令行代码,尽力做到事无巨细。
当你把“能力”这个门槛降到足够低,文章就自然具备了传播和收藏的价值。
3. 势大力沉:用深度建立信任
最近我写了不少“2万字保姆级教程”、“万字长文解析”,即便有AI辅助,这个过程也确实非常耗费精力。但是,这种投入会形成一种“内容势能”,读者是能够清晰感知到的。
这种“势大力沉”的深度内容,即使读者无法立即读完,也有很高的概率被收藏或转发,因为它明确地传递了一个信号:“这份资料足够全面,值得留存以备不时之需”。“保姆教程”和“势大力沉”本就是一体两面。
当然,深度不等于堆砌无效信息。它必须建立在“利他”和“指向行动”的基础上,否则就只是无意义的“信息屎山”。
4. 勤奋与信息嗅觉:保持输入与敏锐度
持续的输入是高质量输出的前提。 这40天,我基本保持了日更的节奏。为了维持选题的新鲜度,我在多个平台进行了海量的信息摄入。
就我个人体验而言,获取一手、高质量技术信息和趋势,最好的平台依然是 Twitter,特别是 Twitter 上的长文(Twitter Article)。那里的内容往往更新、更快、质量也更佳。
一个技巧是:现在的 Twitter 推荐算法非常敏感。如果你持续对优质的“技术长文”点赞、收藏,大概只需要互动10篇左右,算法就会将你信息流80%以上的内容都调整为同类型的优质长文。这个逻辑也适用于其他细分兴趣,比如你只对某个 AI 模型(如 Nano Banana Pro/2)的 Prompt 案例互动,信息流也会随之净化。
我的第一篇10万+文章,正是得益于这种信息嗅觉。我提前了大约48小时关注到 “Clawdbot” 在 Twitter 上有渐火的趋势,又比国内主流媒体的报道早了12-24小时,发布了一篇精心编译和整合的文章(其实是在阅读了几十篇相关长文和若干视频后,筛选出的一篇高质量译文)。
5. 工欲善其事必先利其器:与AI深度协奏
我之前写过关于“Vibe/Agentic Note-Taking”的文章,核心观点是:在当下,任何信息的组织与创作,都应该与 Coding Agent 进行深度互动。
例如,我在 Obsidian 里撰写这篇文章时,旁边一定会打开一个 Coding Agent(下图用的是深度集成于 Obsidian 的 Claude Code)。否则,产出的信息就容易成为“孤岛”,时间一长就会沦为“无效信息”——想想你收藏夹里那些再也想不起来、也无法被 AI 重新组织和利用的笔记吧。
一个强大的 Coding Agent 在写作中能扮演多种角色:
- 深度检索助手:
- 将整个 GitHub 项目仓库扔给它,让它理解后帮你校准文章中的技术细节。
- 联网查找并验证特定的技术参数、版本号或事件时间线。
- 头脑风暴伙伴:
- 在获取基础资料后,与 Agent 进行充分讨论,它能提供超越个人局限的思考维度和深度。
- 编写辅助引擎:
- 生成大量公众号标题选项供你选择。
- 对行文进行润色,调整语序和节奏。
- 进行风格转换,例如将技术文档改写成更活泼的社区分享帖。
- 内容审核员:
- 检查是否有潜在的内容风险。
- 快速排查错别字和语法错误。
这里引出一个值得深入讨论的话题:究竟哪些内容可以放心交给AI生成?
我的看法是:人的大脑需要通过克服认知困难来实现“熵减”,从而成长(其生物学本质是神经元连接的建立与强化)。AI的思考过程并不发生在你的大脑里,因此不存在“克服困难”这一说,大脑失去了“熵减”的机会,也就难以实现真正的认知迭代。
因此,我的建议是:
- 可以交给AI的:偏向于“事实”(Facts)和“记忆”(Memory)类的内容,比如资料搜集、背景信息整理、基础代码片段生成。
- 必须留给自己的:需要认知深度、逻辑推演、观点提炼和结构设计的部分。把这些最烧脑的环节留给自己那个“懒惰”的大脑,逼它去思考、去建立连接。AI替你想出来再告诉你,和你自己挣扎后想出来,完全是两回事。 腾讯研究院的“晓辉博士”也表达过类似的观点。
最后
以上是我对这40天技术内容创作的一些阶段性总结。肯定还有一些碎片化的想法漂浮在脑海,尚未与我的核心认知网络完全连接。未来我还会持续复盘,并在像 云栈社区 这样的开发者社区里与大家分享。希望这些经验对正在从事或对技术写作感兴趣的朋友有所启发,这也算没有违背“利他”的初衷。
共勉。
 发表于 2026-3-5 10:37:10
|
查看: 120|
回复: 0
发表于 2026-3-5 10:37:10
|
查看: 120|
回复: 0
