
Anthropic 为 Claude 的 skill-creator 工具带来了一个关键更新:一套完整的测试框架。现在,你可以为你的 Agent Skill 编写 evals(评估测试)、运行基准测试,甚至进行 A/B 版本对比,整个过程无需编写代码。这为非工程师背景的领域专家提供了一个可靠的工具,用以验证他们的 AI 助手技能是否真的按预期工作。
开发者面临的普遍困境
设想这样一个场景:你花费了几个小时精心编写了一个 Agent Skill,初步测试感觉不错。然而,当底层模型更新后,你开始不确定这个 Skill 是否还能正常运行。或者,当你修改了某个细节时,你无从判断改动带来了提升还是倒退。又或者,新增的 Skill 是否会与现有技能产生冲突、发生误触发?这些问题,几乎是每位 Skill 开发者的日常困扰。
Anthropic 团队也意识到了这一痛点:许多 Skill 的创建者是熟悉业务流程的领域专家,他们并非专业开发者。他们深知自己的需求,但缺乏有效的工具来客观验证这些 AI 技能的可靠性。这正是本次功能更新的核心驱动力。

明确你的Skill类型:两种设计思路
在深入探讨测试方法之前,Anthropic 提出了一个实用的分类框架,帮助我们理解不同 Skill 的本质。
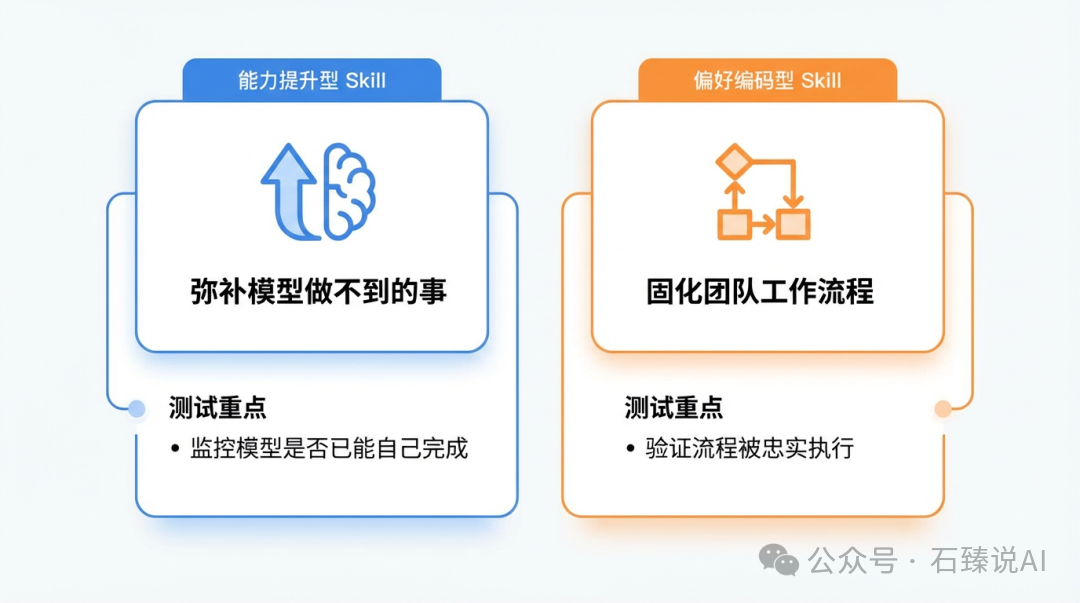
- 能力提升型 Skill:这类技能旨在弥补模型自身能力的不足,将特定技巧或模式固化下来,以实现模型原本无法稳定完成的任务。例如,处理一个没有预设可填字段的 PDF 表单,模型需要在没有任何界面引导的情况下,精确地将文字定位到指定坐标。这就是一个典型的、需要特定技巧加持的任务。
- 偏好编码型 Skill:这类技能并非因为模型能力不够,而是为了将团队或组织的工作流程固化下来。例如,按照公司特定标准逐条审查 NDA 合同,或者按照固定模板格式生成周报。核心目标是确保 AI 严格遵循既定流程,而非自由发挥。
为什么这个分类至关重要?因为它直接决定了测试的侧重点。
| 类型 |
测试重点 |
| 能力提升型 |
监控基线模型是否已能自己完成任务(Skill 可能已“过时”) |
| 偏好编码型 |
验证流程是否被忠实执行(防止模型偏离既定工作流) |
这个框架本身就是一个有价值的思维工具,它能帮你厘清:你正在构建的技能,究竟是在弥补模型的短板,还是在编码团队的最佳实践。
核心新功能:为AI技能引入“单元测试”
Evals:技能的“质量检验员”
本次更新最核心的功能便是对 evals 的支持。你可以将其理解为 AI 技能的“单元测试”。
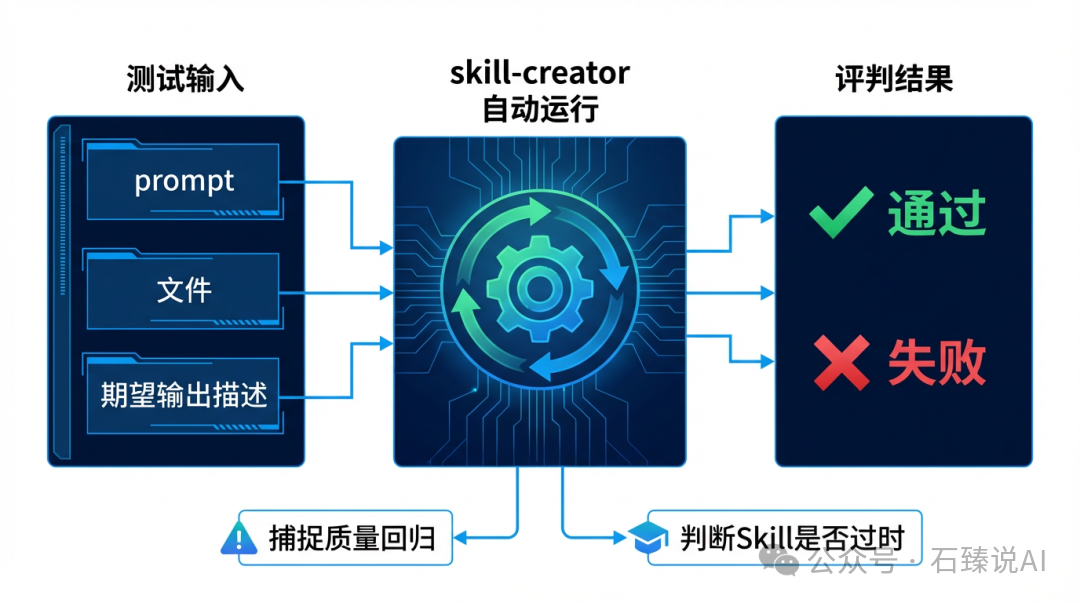
使用方法直观明了:提供一组测试用的 prompt(以及必要的输入文件),并清晰描述“一个合格的输出应该是什么样的”。随后,skill-creator 便会自动运行你的 Skill,并根据你设定的标准来评判输出是否达标。
官方分享了一个真实案例:一个处理 PDF 的 Skill 原本无法正确应对没有可填字段的表单。通过 evals,团队精准定位了这一失败场景。基于此反馈,他们将定位逻辑从“依赖表单字段”修改为“锚定已提取的文字坐标”,从而成功解决了问题。
这个例子生动地说明了测试的价值:没有系统性的测试,Skill 只是“看上去能用”;有了 evals,你才能“确知它确实能用”。
有两个实际应用场景尤其值得关注:
- 捕捉质量回退:AI 模型和底层基础设施在不断迭代。上个月运行良好的 Skill,本月可能会因为某些更新而行为异常。Evals 能作为早期预警系统,在问题影响实际工作流之前发出信号。
- 判断 Skill 是否“过时”:这主要针对能力提升型 Skill。如果基线模型(即不加载任何自定义 Skill 的原始模型)能够直接通过你的 evals,那就意味着这个 Skill 所包含的技巧已经被模型内化吸收了。此时,Skill 并非“失效”,而是成功“毕业”了。
Benchmark 模式:构建可追踪的性能仪表盘
如果说单次 evals 是一次快照,那么 Benchmark 模式就是将快照连接成时间线的工具。
该模式会批量运行同一组 evals,并输出三个核心指标:通过率、执行时间和 Token 消耗。你可以在每次模型更新后运行它,也可以在修改 Skill 的前后分别运行,以清晰追踪性能的变化趋势。这些结果可以本地存储、接入数据仪表盘,甚至直接集成到 CI/CD 流水线中——这相当于将 AI 技能的质量保障纳入了标准的软件开发持续集成体系。
多Agent并行与盲测比较
顺序运行测试存在两个问题:速度慢,且前一个测试的上下文可能会“污染”后一个测试。新版本通过多 Agent 并行运行解决了这个问题——每个 eval 都在独立、干净的上下文中执行,拥有独立的 Token 计数和计时,彼此互不干扰。
此外,比较 Agent 功能也值得一提。它的工作原理是:同时运行两个版本的 Skill(例如 A/B 测试,或“有Skill” vs “无Skill”),然后让一个不知情的第三方 Agent 来评判两个输出的质量。这种盲测方式有效消除了开发者的主观偏差,让你能客观判断改动是真实提升了效果,还是仅仅“感觉”变好了。
智能调优触发描述
随着 Skill 库的不断扩大,触发描述的精确性变得愈发关键。描述过于宽泛会导致误触发,过于精确则可能导致漏触发。
新版 skill-creator 新增了智能分析功能。它会分析你当前的触发描述,对比历史上的实际触发样本,然后为你建议更精准的措辞,旨在同时降低误触发和漏触发的概率。Anthropic 使用自己的6个公开文档创建技能来测试此功能,结果显示其中5个的触发准确率得到了显著提升。
一个值得思考的未来方向
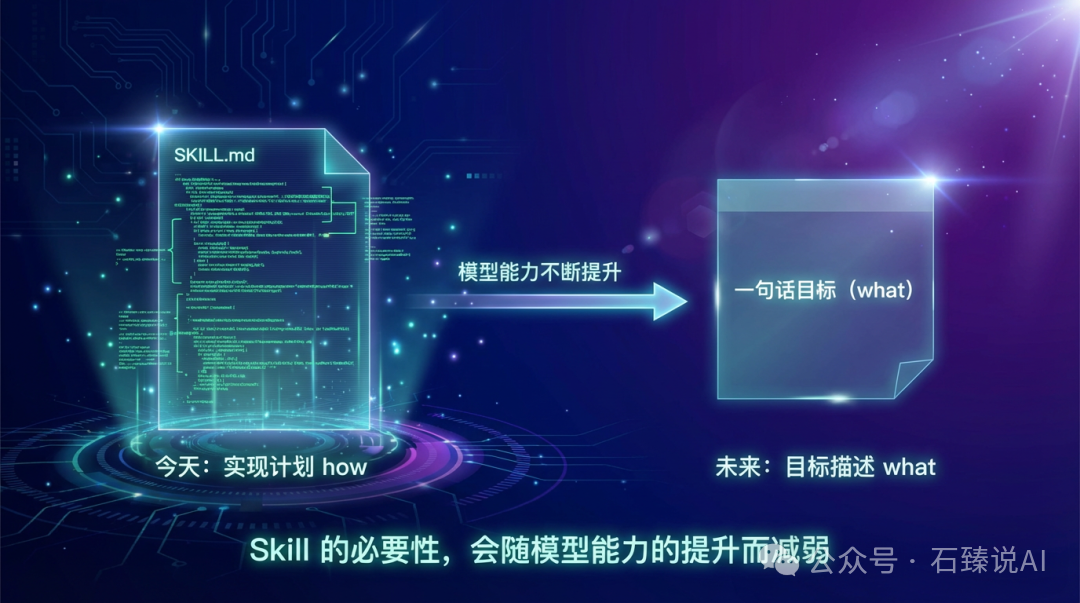
Anthropic 在其博客末尾提出了一个前瞻性的观点:目前 SKILL.md 文件本质上是一份“实现计划”,它告诉模型“如何”做某件事。但随着模型能力持续增强,未来我们或许只需要提供“目标描述”,即告诉模型“要做什么”,模型便能自行推导出实现路径。
这次发布的 evals 框架,恰恰是朝着这个方向迈进了一步——因为 evals 描述的是“应该发生什么”(结果),而不是“如何做到”(过程)。换句话说,evals 本身就在向未来更高级的 Skill 形态靠拢。
当然,这还是一个比较早期的构想,但方向值得所有关注 AI Agent 开发的从业者思考:技能作为“实现细节”的必要性,可能会随着模型通用能力的提升而逐渐减弱。
如何立即开始使用
目前,所有更新功能已在 Claude.ai 平台和 Claude for Work 中上线。
对于 Claude Code 用户,可以通过以下命令安装插件:
/plugin marketplace add anthropics/skills
或者,你也可以直接从 GitHub 仓库获取:
https://github.com/anthropics/claude-plugins-official/tree/main/plugins/skill-creator
skill-creator 的本体项目位于:
https://github.com/anthropics/skills/tree/main/skills/skill-creator
要点回顾
- 两种 Skill 类型:能力提升型(弥补模型短板)和偏好编码型(固化团队流程),它们的测试侧重点不同。
- Evals:为 Skill 编写测试用例,系统性验证其在各种输入下是否输出符合预期。
- Benchmark 模式:追踪通过率、执行时间、Token 消耗等指标,并支持接入 CI/CD 流水线,实现持续监控。
- 多Agent并行与比较Agent:通过并行执行和盲测对比,客观、高效地评估 Skill 改动效果。
- 触发描述调优:基于数据智能优化触发描述,降低误触发和漏触发风险。
- 未来演进:Evals 所描述的“应然状态”,正指引着未来 Skill 向更声明式、目标驱动的形态发展。
参考链接
- Claude 官方博客:
https://claude.com/blog/improving-skill-creator-test-measure-and-refine-agent-skills
- skill-creator GitHub:
https://github.com/anthropics/skills/tree/main/skills/skill-creator
- Claude Code 插件 GitHub:
https://github.com/anthropics/claude-plugins-official/tree/main/plugins/skill-creator
为你的 AI Agent 技能引入系统化的 单元测试,是迈向生产级可靠应用的关键一步。无论是修复潜在缺陷,还是验证模型迭代后的兼容性,这套来自官方的测试框架都提供了标准化工具。如果你想了解更多关于 skill-creator 的 开源实战 经验,欢迎在 云栈社区 与其他开发者交流探讨。
 发表于 2026-3-5 17:51:30
|
查看: 165|
回复: 0
发表于 2026-3-5 17:51:30
|
查看: 165|
回复: 0
