在使用Nacos作为服务注册中心时,你是否也思考过以下几个问题:
- 临时实例和永久实例究竟是什么?它们之间有何区别?
- 服务实例是如何成功注册到服务端的?
- 服务实例和服务端之间如何维持连接并确认存活?
- 服务的订阅与发现机制是如何实现的?
- 在集群模式下,数据如何在节点间同步?它遵循CP原则还是AP原则?
- Nacos内部的数据模型是怎样的?
本文将通过深入探讨这些问题,来揭示Nacos服务注册中心的核心底层实现原理。为了照顾不同用户,本文将同时涵盖Nacos 1.x和2.x版本的关键实现细节。
临时实例和永久实例
理解临时实例与永久实例是掌握Nacos内部机制的基础,因为两者在底层的实现逻辑上存在着根本性的差异。
临时实例
临时实例在注册到Nacos服务端后,其信息仅保存在内存中的服务注册表里,不会被持久化到磁盘。当该实例异常下线或主动注销时,Nacos会将其从服务注册表中直接移除。
永久实例
永久实例的信息不仅会存入内存的服务注册表,同时也会被持久化到磁盘文件中。即使实例发生异常或下线,Nacos也不会立即删除其记录,而只是将其健康状态标记为“不健康”。因此,你仍然可以在注册中心查看到该实例的信息,只是其状态为异常。
核心区别总结:临时实例的生命周期与服务进程强绑定,下线即消失;永久实例的信息则会被持久化,下线后信息仍保留但状态变更。
当然,除了这一基本区别,两者在心跳、健康检查等机制上也完全不同,后文会详细展开。
你可能会问:为何Nacos要区分这两种实例类型?
这主要是为了适应不同的应用场景:
- 临时实例:适用于常见的业务微服务。服务下线后,我们通常不希望再在注册中心看到它,从而保持服务列表的简洁与实时性。
- 永久实例:适用于需要运维人员长期关注的底层基础设施服务,如数据库、缓存等。即使这些服务出现异常,我们也需要能在注册中心看到其状态,以便监控和排查问题。
MySQL、Redis等服务实例可以通过Nacos SDK或控制台手动注册。
在Spring Cloud微服务体系下,默认注册的都是临时实例。如果需要将某个服务注册为永久实例,可以通过以下配置实现:
spring:
cloud:
nacos:
discovery:
# ephemeral意为“临时的”,设为false即表示注册为永久实例
ephemeral: false
版本差异提醒:
- 在Nacos 1.x版本中,实例级别决定临时或永久属性。即同一个服务下,可以同时存在临时实例和永久实例。
- 在Nacos 2.x版本中,服务级别决定临时或永久属性。同一个服务下的所有实例,要么全是临时的,要么全是永久的。因此,2.x中更准确的说法是“临时服务”和“永久服务”。
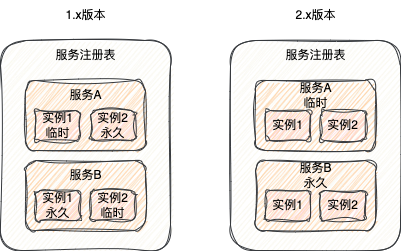
思考:为什么2.x要将该属性从实例级别提升到服务级别?
这更符合实际场景。例如,一个MySQL服务集群,它的所有实例都应该是永久存在的,不会出现一部分永久、一部分临时的情况。由服务本身来决定这一属性,逻辑上更为合理。
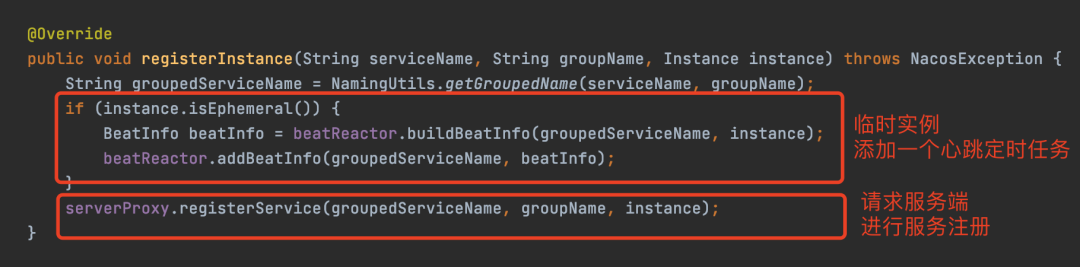
服务注册
服务注册是注册中心最核心的功能之一,即客户端将自身的元数据(如IP、端口、权重等)上报给服务端,服务端将其存入服务注册表。
1、Nacos 1.x版本的实现
在1.x版本中,服务注册通过标准的HTTP接口完成。
客户端核心注册方法代码示例如下:
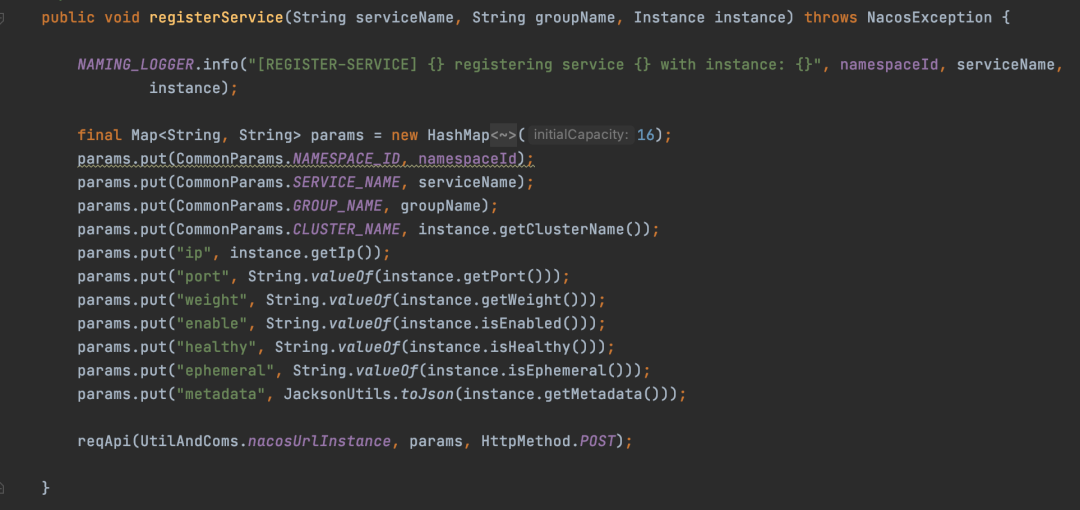
整个过程较为直观,因为Nacos服务端基于Spring Boot构建,注册请求最终由一个Controller接口处理。
2、Nacos 2.x版本的实现
2.1、通信协议的变革
2.x版本最重要的升级之一是通信协议从HTTP切换为gRPC。
gRPC是一个由Google开发的高性能、开源、通用的RPC框架,其Java实现底层基于Netty。
变更的主要原因在于HTTP请求每次通信都可能涉及连接的创建与销毁,在高频交互场景下存在资源浪费。采用基于长连接的gRPC可以显著提升性能。根据官方数据,整体注册性能提升至少2倍。
兼容性说明:2.x版本的服务端仍然保留了HTTP注册接口,因此使用1.x版本客户端的服务依然可以注册到2.x的服务端。
2.2、具体实现流程
Nacos 2.x客户端在启动时,会与服务端建立一个gRPC长连接。

后续所有的通信都基于此长连接进行。当客户端发起注册请求时,通过这个连接将实例信息发送给服务端,服务端同样将其存入服务注册表。
新增的“Redo”机制:当注册的是临时实例时,2.x客户端还会将该实例信息存储在一个本地缓存中,用于“Redo”操作。
Redo本质是一个补偿机制,默认为每3秒执行一次的定时任务。它的主要作用是:当客户端因网络异常与服务器断开连接并重连后,自动将之前注册过的服务实例、订阅过的服务等关键操作重新执行一遍,确保状态同步。
Redo机制不仅用于服务注册,也用于服务订阅等操作,是2.x版本保证连接恢复后状态一致性的重要设计。
小结
- 1.x:通过HTTP协议进行服务注册。
- 2.x:通过gRPC长连接进行服务注册。
- 2.x特有:引入了Redo机制,确保在网络闪断重连后能自动恢复注册、订阅等状态。
延伸思考:既然2.x有Redo机制来保证重连后的状态恢复,那么1.x是否有类似的保障机制呢?答案是肯定的,这便引出了下一部分——心跳机制。
心跳机制
心跳机制,也称为保活机制,是服务实例向注册中心定期发送信号以证明自己“存活”的机制。
在正常关闭流程中,服务会主动发送下线请求,服务端据此移除实例。但在网络异常等非正常场景下,实例可能已不可用却无法通知服务端。心跳机制正是为了解决这一问题,Nacos、Eureka等注册中心都采用了类似设计。
重要前提:在Nacos中,心跳机制仅针对临时实例。永久实例的健康状态通过其他方式判断(见下文健康检查)。
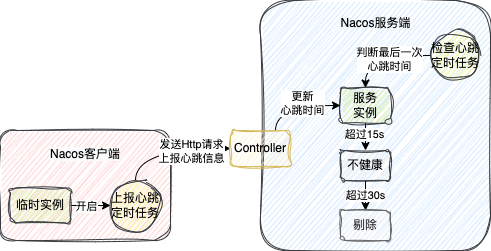
1、Nacos 1.x心跳实现
1.x版本的心跳由客户端和服务端两个定时任务协同完成。
当注册临时实例时,客户端会启动一个默认5秒执行一次的定时任务。
该任务会构建一个携带实例信息的HTTP请求发送给服务端。

服务端同样有一个定时任务(默认5秒一次),用于检查各实例的最后心跳时间:
- 若最后一次心跳时间超过15秒但未超过30秒,则将实例标记为不健康。
- 若超过30秒,则直接将该实例从服务注册表中剔除。
此外,1.x的心跳机制也隐含了“重注册”的效用:如果服务端在处理心跳请求时,发现该实例不在注册表中,则会将其加入。这与2.x的Redo机制有异曲同工之妙。
2、Nacos 2.x心跳实现
2.x版本由于采用了gRPC长连接,其保活机制主要依赖连接本身。
- 连接层心跳:一旦gRPC长连接断开,服务端会立即认为该连接对应的所有临时实例不可用,并将其剔除。
- 服务端主动探测:Nacos服务端还会启动一个定时任务(默认3秒一次),检查超过20秒未发送任何数据的连接。它会主动向这些“沉默”连接的客户端发送探活请求,若失败则断开连接并剔除相关实例。
小结
- 1.x:基于HTTP定时上报。客户端定时发送心跳,服务端定时检查并更新状态(15秒不健康,30秒剔除)。心跳也兼具故障恢复后的“重注册”功能。
- 2.x:基于gRPC连接状态。依赖连接自身的心跳保活和服务端的主动探活,连接异常则立即剔除实例,响应更迅速。
健康检查
心跳机制是临时实例的“主动汇报”,而对于无法主动汇报的永久实例(如MySQL、Redis),Nacos采用健康检查机制,即服务端主动发起探测来判断实例健康状态。
健康检查机制在1.x和2.x版本中实现原理相同。服务端会创建一个健康检查任务,其执行间隔在2000~7000毫秒之间动态调整。
目前支持三种检查方式:
- TCP检查:尝试与实例的IP和端口建立Socket连接,成功则认为健康。
- HTTP检查:向实例的指定路径(需配置)发送HTTP请求,根据响应状态判断健康。
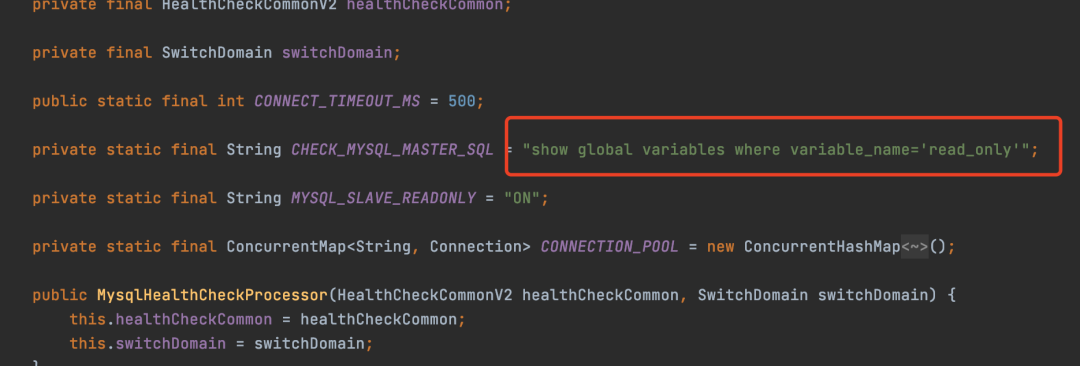
- MySQL检查:一种特殊检查,用于判断数据库实例是否为主库。它会执行特定的SQL查询。
// 用于MySQL健康检查的SQL
private static final String CHECK_MYSQL_MASTER_SQL = "show global variables where variable_name='read_only';";
默认情况下,Nacos使用TCP检查方式。
服务发现
服务发现是指已注册的服务实例能够被其他服务消费方发现。Nacos提供了两种模式:
- 主动查询(Pull):客户端主动向服务端拉取指定服务的实例列表。
- 服务订阅(Push):客户端向服务端订阅某个服务,当该服务的实例列表发生变化时,服务端会主动将最新列表推送给客户端。
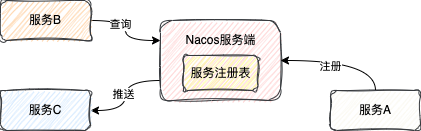
在实际微服务架构中,通常推荐使用订阅模式,以便实时感知变化。Spring Cloud Alibaba集成Nacos时默认即采用订阅模式。
两种发现方式在1.x和2.x的实现差异主要体现在通信协议上(HTTP vs gRPC),但订阅模式的底层机制更为复杂。无论是哪个版本,客户端都通过NamingService.subscribe(String serviceName, EventListener listener)方法发起订阅,实例变化时会回调EventListener。
1、Nacos 1.x服务订阅实现
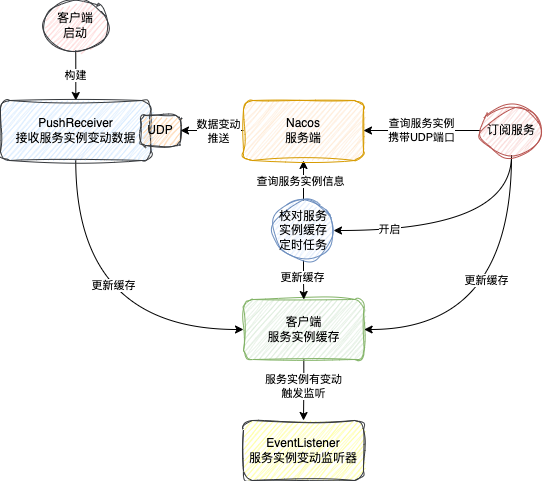
1.x版本的服务订阅主要包含以下三步:
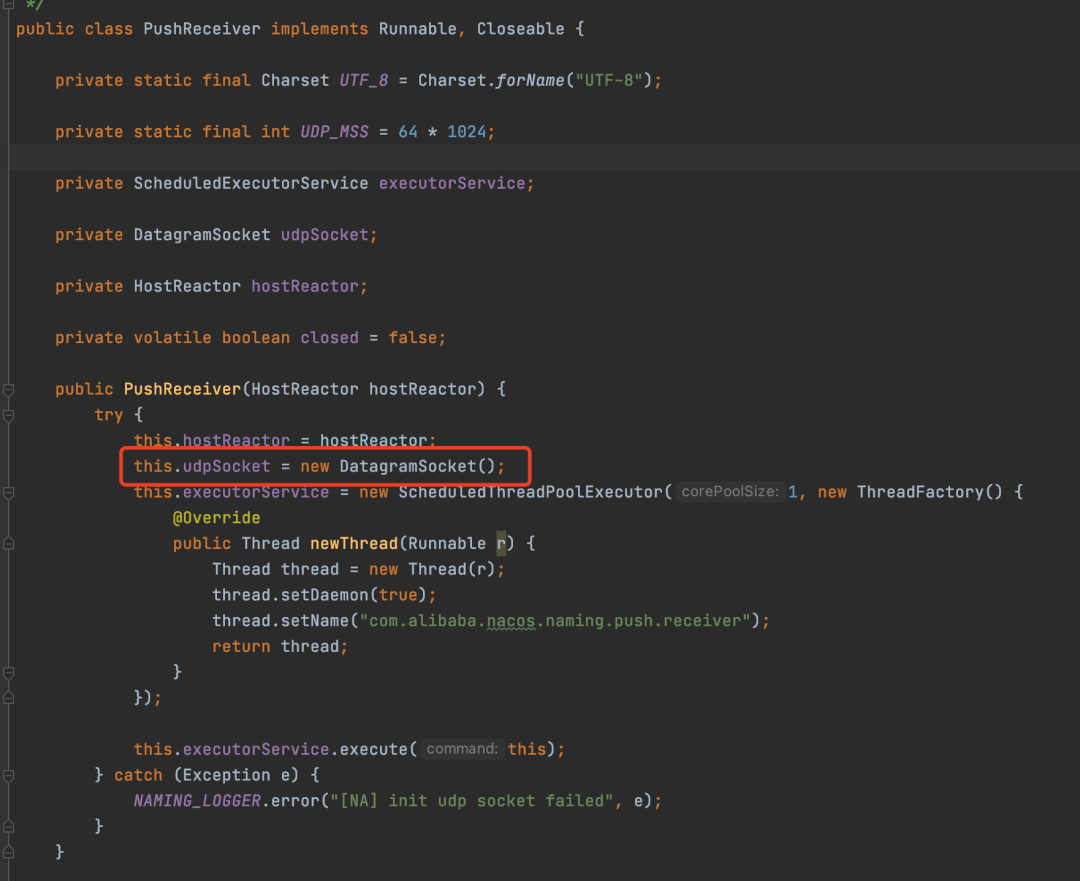
- 构建UDP接收器:客户端启动时,会构建一个
PushReceiver类,它内部创建一个随机的UDP Socket端口,专门用于接收服务端的推送数据。
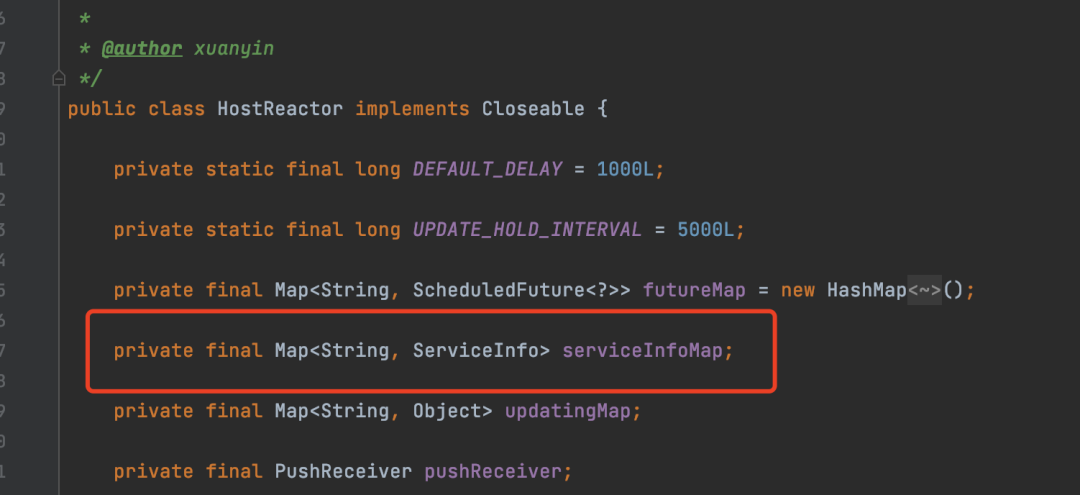
- 首次查询与UDP端口上报:调用
subscribe方法时,首先会从服务端查询全量实例信息,并存入客户端本地缓存(一个ServiceInfo Map)。同时,会将上一步创建的UDP端口号作为参数传给服务端,以便后续推送。
- 启动定时校对任务:开启一个延迟任务(正常间隔约10s,异常时延长,最多60s),定期从服务端拉取实例信息来更新本地缓存,作为UDP推送可能丢失的兜底方案。
为何有了Push还要Pull? 因为UDP协议本身是无连接、不可靠的,存在丢包可能。定时拉取机制确保了即使推送丢失,客户端最终也能通过拉取同步到正确数据。
2、Nacos 2.x服务订阅的实现
2.x版本由于有了可靠的gRPC长连接,直接通过该连接进行服务变动的推送,摒弃了UDP方式。客户端收到推送后的处理逻辑(更新本地缓存、触发监听器)与1.x一致。
同时,2.x也保留了客户端本地缓存和定时校对机制,但定时校对默认是关闭的。因为长连接相对稳定,且当连接异常断开又恢复后,Redo机制会重新完成订阅,足以保证数据同步。
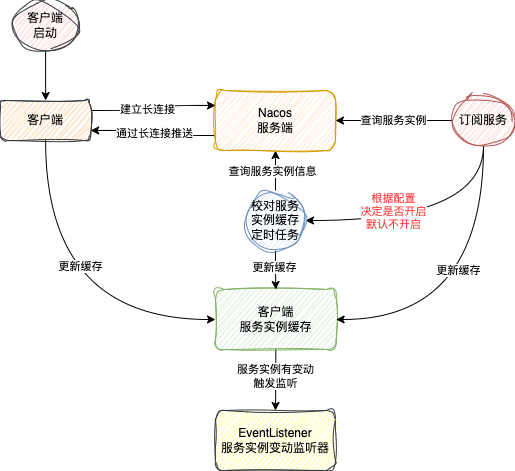
一个重要区别:在2.x版本中,仅临时服务支持订阅模式,永久服务不再支持订阅。
小结
- 服务查询:1.x通过HTTP,2.x通过gRPC。
- 服务订阅:1.x基于UDP推送 + 定时拉取兜底;2.x基于gRPC长连接推送 + (可选的)定时拉取。
- 本地缓存:两者均有,用于快速读取和对比。
- 订阅范围:1.x所有服务可订阅;2.x仅临时服务可订阅。
数据一致性
在Nacos集群模式下,数据一致性是一个核心问题。在深入讨论前,需要理解“服务实例的责任机制”。
1、服务实例的责任机制
在单节点下,该节点负责所有实例的心跳检查、健康检查等。但在集群中,为了负载均衡,Nacos通过特定规则让每个节点只“负责”管理一部分服务实例(尽管每个节点都拥有全量的服务注册表)。
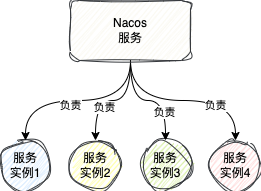

这个“负责”机制体现在源码的responsible标识上,决定了由哪个节点来执行对特定实例的心跳超时判断或健康检查探活。
2、CAP定理与BASE理论简述
在分布式系统中,CAP定理指出一致性(C)、可用性(A)、分区容错性(P)三者不可兼得。由于网络分区不可避免,实际通常在CP(强一致)和AP(高可用)之间权衡。
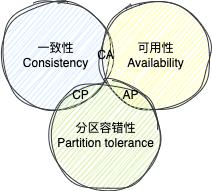
BASE理论是对AP策略的延伸,强调基本可用(Basically Available)、软状态(Soft State)和最终一致性(Eventually Consistent),是互联网系统常见的实践。
3、Nacos中的AP与CP实现
Nacos根据不同的数据类别,混合使用了AP和CP模型。并非通过一个配置全局切换。
- 对于临时实例:Nacos优先保证可用性(AP),采用自研的Distro协议。
- 对于永久实例:Nacos优先保证强一致性(CP),采用Raft协议。
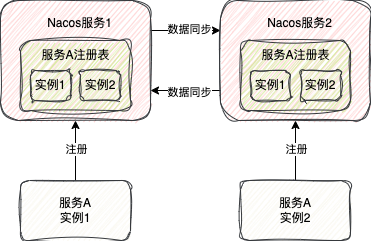
3.1、Nacos的AP实现 (Distro协议)
Distro是一个类Gossip的AP协议。每个节点地位平等,都拥有全量数据,均可处理读写请求。
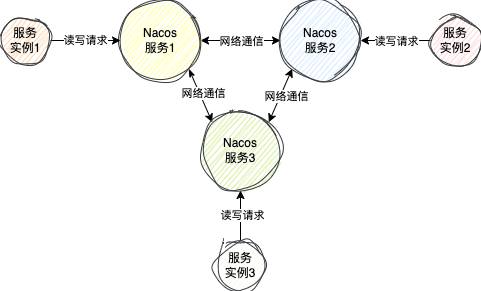
- 新节点加入:会从其他节点拉取全量数据。
- 数据写入:当某个节点收到临时实例的注册请求,除了更新自身,还会异步将数据同步给其他所有节点。
- 最终一致性保障:
- 失败重试:同步失败会定期重试。
- 定时对比:节点间定期对比各自“负责”的数据的版本号,若不一致则同步增量数据。
3.2、Nacos的CP实现 (Raft协议)
Nacos使用Raft算法来保证永久实例数据的强一致性。
- 1.x早期:自己实现Raft。
- 2.x版本:集成蚂蚁开源的JRaft框架。
在Raft集群中,存在Leader、Follower、Candidate三种角色。只有Leader能处理写请求,Follower复制Leader的数据。
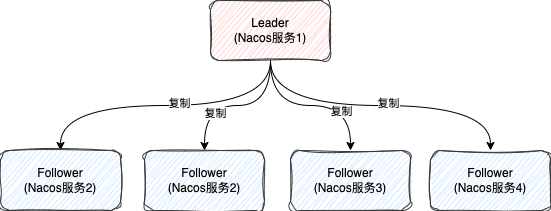
写流程遵循“多数派”原则:Leader先将写请求转发给所有Follower,收到超过半数的成功确认后,才提交数据并返回客户端成功。否则,写请求失败。这保证了数据的强一致性(CP)。
注意一个细节:对于服务实例的读请求(如查询实例列表),Nacos并未强制走Leader节点,而是允许从任意Follower节点读取其本地数据。这在极端情况下可能导致读取到旧数据(即“脏读”),与经典Raft的读一致性保证略有不同。Nacos在其他一些元数据操作上则严格遵守了Raft的读一致性。
数据模型
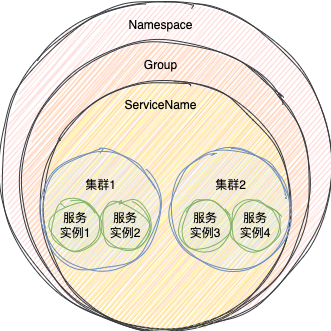
在Nacos中,一个服务的全局唯一标识由三个维度确定,构成一种层级结构:
- 命名空间 (Namespace):用于租户隔离,默认是
public。
- 分组 (Group):可用于环境隔离(如dev, test),默认是
DEFAULT_GROUP。
- 服务名 (ServiceName):服务的具体名称。
此外,在服务之下还有一个集群(Cluster)的概念。服务实例在注册时可以指定所属集群,默认集群为DEFAULT。在Spring Cloud中可通过以下配置指定:
spring:
cloud:
nacos:
discovery:
cluster-name: myCluster
服务消费者在订阅时,可以选择只订阅特定集群的实例,以实现地域优先调用等场景。
总结
本文深入剖析了Nacos作为服务注册中心的核心运行机制,涵盖了从实例类型、注册、发现到集群数据一致性等关键环节,并对1.x与2.x版本的重大差异进行了对比。理解这些底层原理,将有助于你在实际开发和运维中更准确地定位问题、优化架构,并充分利用Nacos提供的强大能力。
希望这篇深度解析能对你有所帮助。如果你想继续深入研究分布式系统或微服务领域的其他核心技术,欢迎在云栈社区与更多开发者交流探讨。
 发表于 2026-3-7 05:05:39
|
查看: 168|
回复: 0
发表于 2026-3-7 05:05:39
|
查看: 168|
回复: 0
