这三天发生了什么
3月2日晚上7点49分(北京时间),Claude 开始出现故障。
一开始,许多人以为这只是普通的服务波动,工程师们排查的重点都放在登录和登出路径上。然而没过多久,API 服务也开始出现问题,“Claude宕机”这个词条瞬间刷屏。
紧接着,Claude Opus 4.6 核心模型在晚上10点35分大面积报错,团队被迫进行紧急修复。一直折腾到晚上11点55分,似乎稳住了局面。但仅仅一分钟后,Haiku 4.5 模型又接着出问题。
这场故障最终持续到了第二天凌晨5点16分,才彻底结束。
从晚上7点49分到次日凌晨5点16分,整整近10个小时。
在此期间,Claude.ai 网页端、开发者控制台、Claude Code 全线受到影响,无一幸免。
为什么宕机这么久?AWS中东机房起火了
路透社随后爆出了一个关键细节:就在 Claude 开始大面积报错的40多分钟后(约晚上8点半),亚马逊 AWS 位于阿联酋的数据中心(可用区 mec1-az2),被一个“不明物体”击中,引发了火花和火情,消防部门直接拉闸断电以控制局面。
AWS 官方发布的公告措辞非常谨慎,既没有说明是什么物体,也没有确认具体的影响范围。但从时间线上看,完全吻合——Anthropic 的算力深度依赖 AWS,其中东节点受损,影响迅速传导至 Claude 的全球服务,从而引发了接下来长达10小时的连锁崩溃。
这件事带有一种黑色幽默的色彩:平时在赛博空间里看似无所不能的大模型,在物理世界里,其脆弱性与普通服务器并无二致。一个机房的物理故障,就能让全球用户的服务瞬间“断粮”。
不只是 Claude,包括 Gemini 在内的多个基于该区域云服务的应用都受到了波及。
更大的风暴:美国政府宣布全面停用Claude
宕机问题还未完全恢复,另一颗炸弹被引爆了。
美国财政部长 Scott Bessent 正式宣布,将全面关停 Anthropic 旗下所有 AI 工具的使用。紧随其后,联邦住房金融局、房利美、房地美等机构也相继宣布停用 Claude。
这背后的背景是,上周 Anthropic 拒绝了五角大楼提出的一项合同变更要求,随后被定性为“供应链风险”,并因此被列入联邦政府的黑名单。
“供应链风险”这个定性的杀伤力极大。如果严格执行,像英伟达这样既向美军供货、又向 Anthropic 提供 AI 芯片的公司,这层商业关系就可能被要求切断。这直接威胁到了 Anthropic 正在进行的巨额融资——据 Axios 报道,总额超过 600 亿美元,其中 300 亿是上个月刚刚宣布的——现在这笔融资的前景悬而未决。
另一边,OpenAI 在 Anthropic 被打压的同时,火速与军方签订了合作协议。这种鲜明的对比,让硅谷的许多科技从业者感到不安。
硅谷的反应:600多人联名,要求撤回定性
面对政府的决定,科技界迅速做出了反应。OpenAI、Slack、IBM、Cursor、Salesforce Ventures……等59家公司的 CEO 和知名人士联名签署公开信,要求国防部撤回对 Anthropic “供应链风险”的定性。
信里有一句话,我觉得说到了点子上:
仅仅因为一家美国公司拒绝接受合同变更就对其进行惩罚,这向全美的科技公司传递了一个明确信号:要么对政府的要求言听计从,要么就等着被报复。
用户也在用脚投票。Sensor Tower 的数据显示,在 OpenAI 和军方签约后,ChatGPT 在美国的日卸载量暴涨了 295%(平时约为 9%)。App Store 中的一星差评当天激增 775%。与此同时,Claude 的日下载量首次超过了 ChatGPT,并在全球六个国家的 App Store 领先。倡导用户离开 ChatGPT 的 “QuitGPT” 运动参与者也从 70 万人飙升至 150 万人。
这波流量是真实的,但我不认为这对 Anthropic 来说仅仅是好事。顶着被政府定性为“风险”的巨大压力进行融资和运营,其压力与挑战是空前的。
回到我们自己:平台这两天怎么处理的
从前天晚上开始,我们自己的 AI 编程巴士所使用的 Claude 服务就明显感觉到了异常——延迟高、响应慢,状态时好时坏。昨天上午到下午是最难受的阶段,官方一直没有发布修复公告。
我进行了一轮紧急排查,加了几次容错,最终确认问题与我们自己的系统无关,纯粹是上游服务本身不稳定导致的。在国内,许多依赖 Claude API 的平台昨天几乎都处于不可用状态。我们这边因为做了一些冗余和备用通道的处理,情况稍好,但依然受到了明显影响。对于昨天刚购买订阅的用户反馈,我立即安排了临时的方案,提供了一小部分余额,让他们可以临时切换codex使用,作为应急措施。当然,这种紧急模式切换中间也出过小问题,用户体验并不完美,这一点我很清楚。
昨晚我思考了很久如何处理这次事件带来的影响。
我计算了一下,如果给所有订阅用户延长一天有效期,成本高达数千美元。这确实让我犹豫过。但转念一想,前几天我们做推广活动,花了上千美元,最终也只有极少数人转化为付费用户。而那些愿意付费、信任我们服务的用户,才是真正支撑这个产品走下去的核心。如果对免费用户大方,对付费用户反而斤斤计较,这种逻辑无论如何也说不通。
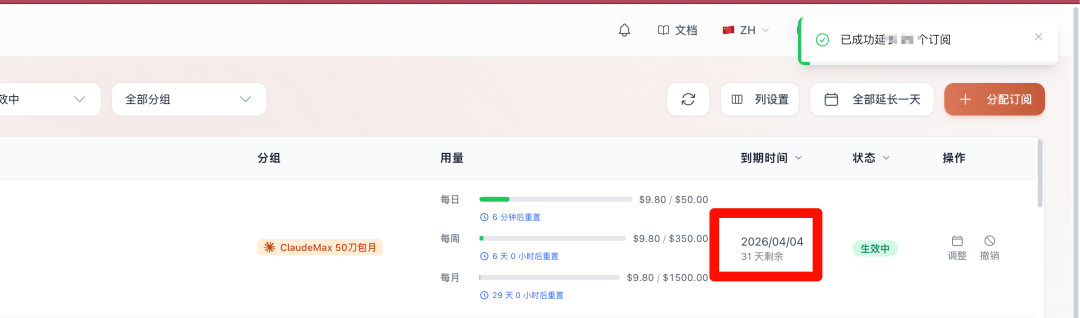
所以,我们最终的决定是:不只是昨天明显受影响的用户,凡是订阅了套餐的用户,全部自动延长一天有效期。昨天新订阅的用户也包括在内。这不是补偿,只是觉得应该这样做。
这个过程也给我上了一课,在复杂的云服务生态下,提前做好备用方案、保持服务冗余,应该是每个服务提供者持续投入的关键方向。在 云栈社区 的 运维 & 测试 板块,也有不少关于提升服务稳定性的讨论和心得。
说一下我对这件事的判断
Claude 宕机、美国政府封禁、硅谷强力反弹——这三件事叠加在一起,看起来纷繁复杂,但底层的逻辑其实比较清晰:
AI 工具的最终稳定性,依赖于物理基础设施和宏观政治环境,而这两点都不在任何单一 AI 公司的完全控制之内。
AWS 中东机房起火事件,是一个绝佳的提醒。我们使用的所有云服务,其底层都是实实在在的硬件、电力、网络设施,它们会因为各种物理或意外原因出现问题。认识到这一点并非悲观,而是面对现实。
在政治层面,Anthropic 当前选择的道路——拒绝某些特定的军事应用——虽然带来了短期的阵痛和巨大的商业压力,但也为自己赢得了一部分特定用户群体的信任,比如那些因价值观从 ChatGPT 迁移过来的人。这个选择是否正确,现在下结论为时过早,但 Anthropic 显然是经过了深思熟虑才做出决定的。
对我们这些服务的构建者和使用者而言,这次宕机事件再次强调了构建弹性和高可用架构的重要性。无论是技术层面的运维策略,还是面对突发事件的沟通与补偿机制,都需要我们在实践中不断学习和完善。如果你也在探索如何构建更可靠的系统,或许可以看看 云栈社区 里关于 DevOps 和 SRE 的实践分享。
 发表于 2026-3-7 09:30:42
|
查看: 196|
回复: 0
发表于 2026-3-7 09:30:42
|
查看: 196|
回复: 0
