
近年来,机器学习在系统领域的应用正不断“下沉”。它不再局限于推荐、内容分类或搜索排序,而是开始直接参与底层的系统决策,例如基于模型的调度算法、缓存算法与负载均衡算法等。
与此同时,ML for Systems 相关的研讨会也频繁出现在各大顶级学术会议上。然而,对于工程实践者而言,这种结合常常令人既期待又担忧:ML模型预测准确时,算法性能可能接近最优;但一旦预测失准,算法性能可能急剧下降,甚至将系统“带进沟里”。
那么,有没有一种方法,既能充分利用机器学习模型的预测能力作为“加速器”,又能为系统系上一条可靠的“安全带”呢?针对这一问题,学术界在近几年逐步形成了一个新兴的交叉方向:学习增强算法。
这个方向致力于将“算法 + ML 预测”作为一个整体来设计和分析。其核心目标是:在预测准确时,算法性能尽量接近最优;在预测不准时,算法性能也必须有一个可靠的最坏情况边界。这让“用 ML 模型增强系统”变得更具可控性,对工业界落地至关重要。

论文标题:Robustifying Learning-Augmented Caching Efficiently without Compromising 1-Consistency
论文链接:https://arxiv.org/pdf/2507.16242

以缓存问题为例
缓存(或称换页)是一个经典的系统问题。场景是:给定一个容量为 k 的缓存,需要在线地响应页面(page)请求。如果被请求的页面已在缓存中,则命中(hit);否则未命中(miss),需要从外部加载该页面。若加载时缓存已满,则必须先剔除(evict)一个现有页面。
Belady 于1966年提出了最优算法,其策略总是剔除缓存中未来访问时间最远的页面。传统的启发式算法(如 LRU、LFU)本质是利用过去的历史信息来估计未来。而学习增强缓存则利用机器学习模型直接预测未来,例如页面的下次访问时间,从而有机会“模仿”Belady算法:遵从预测,总是剔除预测的未来访问时间最远的页面。
但问题恰恰出在这里:一旦模型预测出现误差,盲目遵从预测的算法性能可能急剧恶化,甚至不如传统的LRU算法。
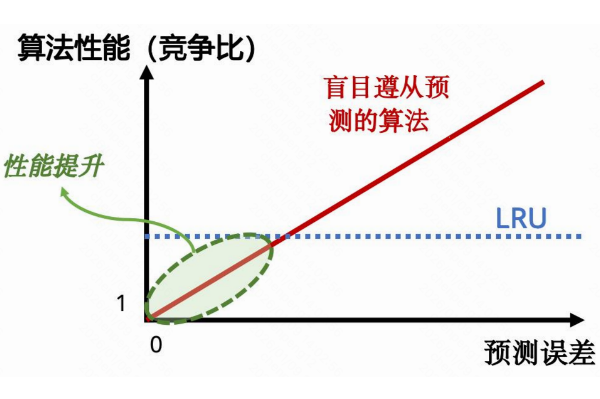
本质上,我们期望的算法应具备三个特性:在预测误差小时接近最优解(一致性,consistency);在预测误差极大时与传统算法性能相当(鲁棒性,robustness);同时,算法的性能最好能随着预测误差的增大而平滑降级(平滑性,smoothness)。
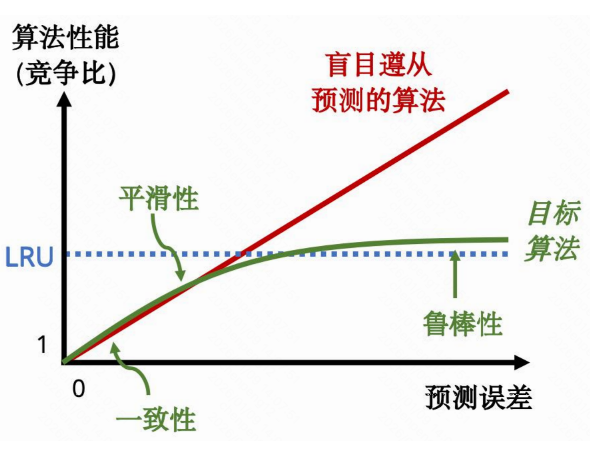

学习增强缓存的鲁棒性挑战
目前,大多数利用机器学习增强缓存的工作并未充分考虑算法鲁棒性,这成为了其在实际工业场景中落地的核心障碍。虽然已有一些研究开始关注“鲁棒化”学习增强缓存算法,但现有方法普遍存在两个核心问题:
- 引入了过高的时间复杂度,例如一些切换(switching)方法需要在线反复重新计算最优方案,难以落地。
- 损害了一致性,导致算法过于保守,无法充分利用误差较小的准确预测。
GUARD 框架的提出,正是为了解决这一核心矛盾:在不损害一致性的前提下,提供强鲁棒性保证,且每请求仅引入 O(1) 的额外计算开销。

GUARD:为学习增强缓存算法装上“轻量安全带”
GUARD 被设计为一个算法鲁棒化框架,用于提升已有学习增强算法的鲁棒性。其核心思想是:在必要时介入原有算法流程,对缓存中的某些页面进行“保护”,防止其在一定时间内被误剔除。
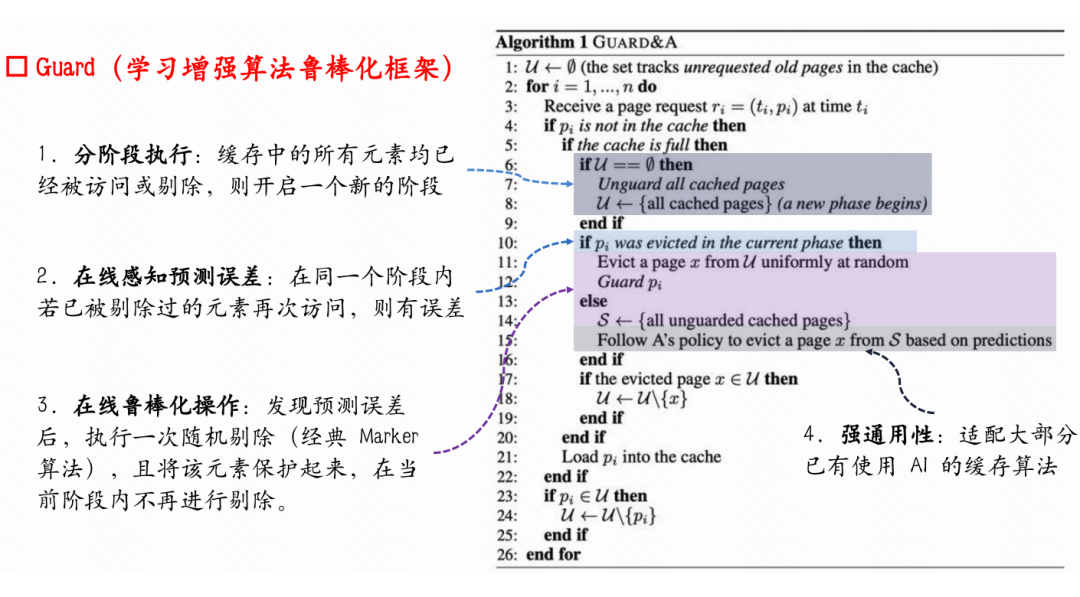
上图展示了 GUARD 与某个基于预测的基线算法 A 结合后的流程。它采用分阶段执行,并仅在在线感知到预测误差时,才执行一次鲁棒化操作(例如一次随机剔除)。这样既保证了在预测准确时不干预原有算法 A(维护了一致性),又在预测不准时能纠正原有算法 A 可能做出的错误决策(提供了鲁棒性保证)。
直观上,可以将 GUARD 类比为汽车的“车道保持系统”:
- 原有的基于 ML 模型的算法 A 仍然负责正常“驾驶”,充分利用预测信息。
- GUARD 只在检测到车辆“开始偏离安全车道”(即预测出现误差)时才介入干预,将系统拉回安全状态。
在理论层面,GUARD 系列算法取得了先进的(state-of-the-art)一致性、鲁棒性边界,并展现出优越的平滑性与时间复杂度。
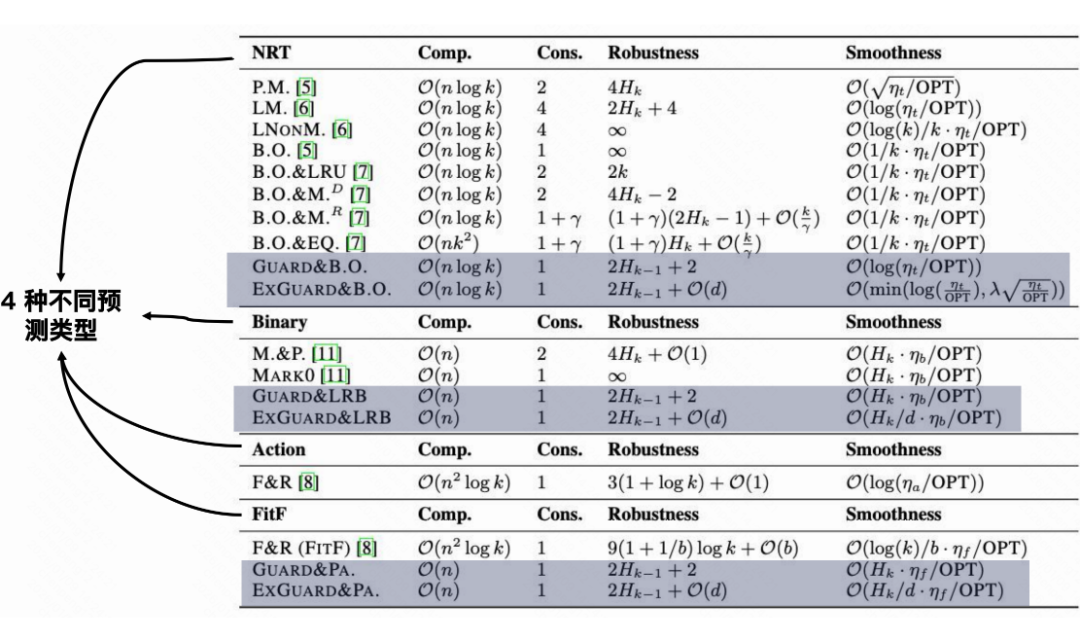

实验效果:在真实数据集与多种预测器上表现“稳且强”
论文在合成噪声与真实预测器下均对 GUARD 进行了性能评估。其中,成本比率(cost ratio)代表算法产生的缓存未命中次数与最优解未命中次数的比值,cost ratio = 1 代表性能达到最优。
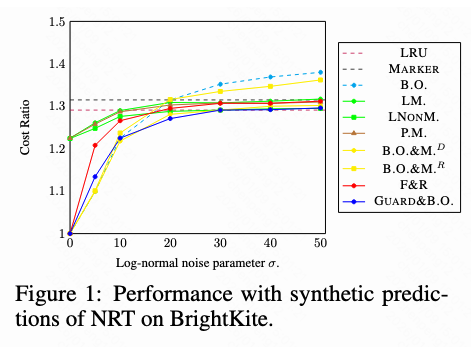
1) 合成噪声测试:从“预测很准”到“预测很烂”,曲线依旧平稳
在 BrightKite 数据集上,通过给真实的未来访问时间添加噪声来模拟有误差的 ML 预测。实验显示,GUARD&B.O. 等算法的表现与理论分析吻合:
- 1-一致性:当预测误差为0时,性能与最优解一致。
- 强鲁棒性:当预测误差极大时,性能与传统的 LRU 算法相当。
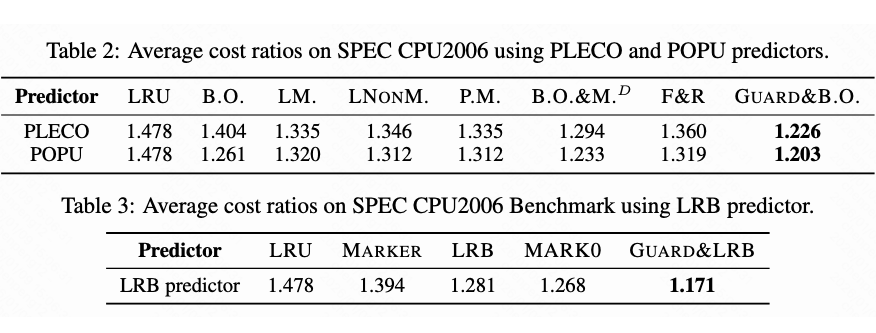
2) 真实轨迹测试:在 SPEC CPU2006 基准测试上平均成本比率最优
- 使用 PLECO / POPU 等真实预测器时,GUARD&B.O. 在平均成本比率上优于多种强基线算法。
- 使用 LRB 预测器时,GUARD&LRB 同样给出了最优的平均成本比率。
此外,研究团队开源了一个功能强大的缓存算法测试基准平台,支持多种启发式算法和几乎现有的所有学习增强算法。源码链接:https://github.com/OptiSys-ZJU/Cache-Coliseum

系统算法与机器学习的巧妙结合:未来展望
通过缓存这个具体例子,我们可以看到在利用机器学习模型增强系统算法的过程中,存在着广阔的算法设计空间。事实上,不仅仅是本文提到的离散算法设计思路,我们同样可以借鉴在线学习的理念,动态调整对 ML 模型预测的信赖程度,从而实现系统算法的鲁棒化。
学习增强算法领域仍在蓬勃发展。它提供了一套将“收益”(预测准确时的性能提升)和“风险”(预测错误时的性能损失)一同量化的方法论,使得新一代基于模型的系统算法更可控、更具落地价值。这也为“ML for Systems”领域提供了一个全新的、充满潜力的研究视角。对这类交叉领域感兴趣的朋友,可以到 云栈社区 的智能与数据板块交流讨论。
参考文献
[1] Thodoris Lykouris and Sergei Vassilvtiskii. Competitive caching with machine learned advice. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 3296–3305. PMLR, 10–15 Jul 2018.
[2] https://algorithms-with-predictions.github.io/
 发表于 2026-3-7 09:28:41
|
查看: 162|
回复: 0
发表于 2026-3-7 09:28:41
|
查看: 162|
回复: 0
