最近,一篇关于大语言模型(LLM)幻觉的理论工作在 arxiv 上发布。这篇文章提供了一个有趣的视角:即便忽略数据脏、训练不足等工程因素,为了节省记忆空间,语言模型也会自然地产生幻觉。
本文将尝试直观地解释三件事:
- 为什么像电话号码、法律判例这类看似随机的知识,模型最容易瞎编;
- 为什么“让模型学会说不知道”往往会带来过度拒绝(over-refusal);
- 为什么为了消除幻觉,RAG 不仅是工程技巧,更是一条自然的出路。
文章链接:Hallucination is a Consequence of Space-Optimality: A Rate-Distortion Theorem for Membership Testing
幻觉:语言模型为什么喜欢“瞎编”?
目前的大语言模型在处理修改语法这类有规律的任务上已经表现不错。然而,在面对一些随机事实时,即使是最好的模型也容易“翻车”。最著名的例子莫过于律师使用 GPT 准备案件材料时,模型直接杜撰了不存在的判例。
科研工作者们也可能有类似体验:如果不允许上网搜索,直接询问 LLM 具体的论文标题和作者,得到的答案多半是似是而非的“虚假论文”。

鉴于幻觉问题的重要性,研究界对其产生机制进行了诸多探讨,大致可分为以下几类:
- 工程问题:数据质量差、训练不充分,或是自回归生成机制本身容易“说错后继续延伸”。
- 可计算性理论:某些输出在计算上不可判定,因此 LLM 不可能完全学会。
- 统计学习理论:对于没有内在规律的“死知识”,如果 LLM 在训练中没见过,被问到时只能猜测。
- 模型容量/有损压缩:模型再大,也比不上世界的信息量。训练集中的知识必然有它记不住的部分。
我们暂时搁置工程问题——我们想探究的是:在理想条件下(数据干净、训练充分、模型不会顺着错误往下编),幻觉还会出现吗? 可计算性问题通常不涉及此类事实性错误,也暂且不论。
我们先梳理后两种思路,并从它们尚未完全覆盖的角度,引出本文的新视角。
1. 相关工作:统计学习视角
这个思路的核心是泛化。我们特别关注“随机事实”:
随机事实:指那些看起来随机、没有内在规律、也独立于其他知识的信息。LLM 若要正确回答此类问题,必须在训练中见过它们。
例如:你朋友的电话号码(无法从张三的号码推导李四的)、某本冷门教材的 ISBN 码。再扩展一些,具体论文的标题作者、过往法律判例、某个软件曾出现的具体 Bug,也都具有极强的随机性。
统计学习中的经典“没有免费午餐”定理表明,若要对这类无规律的事实进行真/假判别,除非在训练中见过绝大多数,否则不可能全对。这几乎不可能:训练集无法包罗万象,更何况有些问题(如“下一任美国总统是谁”)在训练时根本没有答案。
因此,一个看似直接的解决方案是:让 LLM 在遇到没见过、无法推断的问题时,直接拒绝回答(Abstain)。这也被 OpenAI 的相关论文指出:许多训练和评估并不鼓励模型如实承认“不知道”,这是当下幻觉产生的主因之一。
然而,新的问题随之而来:完美地区分“见过的事实”和“没见过(但可能为真)的非事实”本身也极其困难。例如,让模型变得“更保守”似乎总会导致过度拒绝(over-refusal),即连本该正确回答的问题也答不上来。
那么,自然的问题便是:对于语言模型,“知道”与“不知道”的界限为何如此模糊? 这就引向了第二个视角。
2. 相关工作:有损压缩视角
《纽约客》2023年有篇文章将 GPT 比作“整个互联网的一个模糊 JPEG”,指的就是有损压缩。如同 JPEG 会丢弃高频细节只保留大体轮廓,由于 LLM 所包含的信息量不足以完整描述整个训练集,细节信息必然会丢失。
近期也有研究论证,在参数有限的情况下,如果需要记忆的知识是无穷的,那么那些长尾的、不常见的知识自然会被优先舍弃。
但是,现有理论尚不足以完全解释为何 LLM 难以完成“区分事实与非事实”这项任务。具体来说:
- 模型不匹配:现有工作要么泛泛而谈“有损压缩必有损”,要么需要假设有无穷多事实才能体现参数量的不足。
- 无法区分错误类型:单纯的“有损”能解释遗忘(存不下就丢),却解释不了为何模型会“理直气壮地瞎编”。
于是,我们面临两个谜团:
- 事实集合是有限的,为什么模型还是记不住?
- 记不住就算了,为什么非要“瞎编”?
为了探究这些更具体的现象,我们需要一个新的理论工具——成员查询(Membership Testing)。
新视角:将LLM视为随机事实的“成员查询器”
为了对“死知识”的记忆进行建模,我们可以将 LLM(的其中一项功能)视为一个进行成员查询的数据结构。当然,LLM 的功能远复杂于此,但对于“某个判例是否存在”这类事实性问题,成员查询抓住了核心。
什么是成员查询?
想象所有可能的“事实”构成一个巨大的全集 U(例如所有看起来像那么回事的法律判例)。模型已知的事实,我们称为“关键集” K,它是 U 中一个稀疏的子集(即真实存在的判例)。我们假设所有不在 K 中的元素,一律视为“非事实”。这个假设也称为封闭世界假设。
那么,LLM 记忆知识,就相当于构建了一个数据结构,其任务是:对于用户查询的一个元素 i ∈ U,输出一个介于 [0, 1] 之间的“置信度”分数 x̂_i,来表示它有多大把握认为 i 属于已知事实集 K。
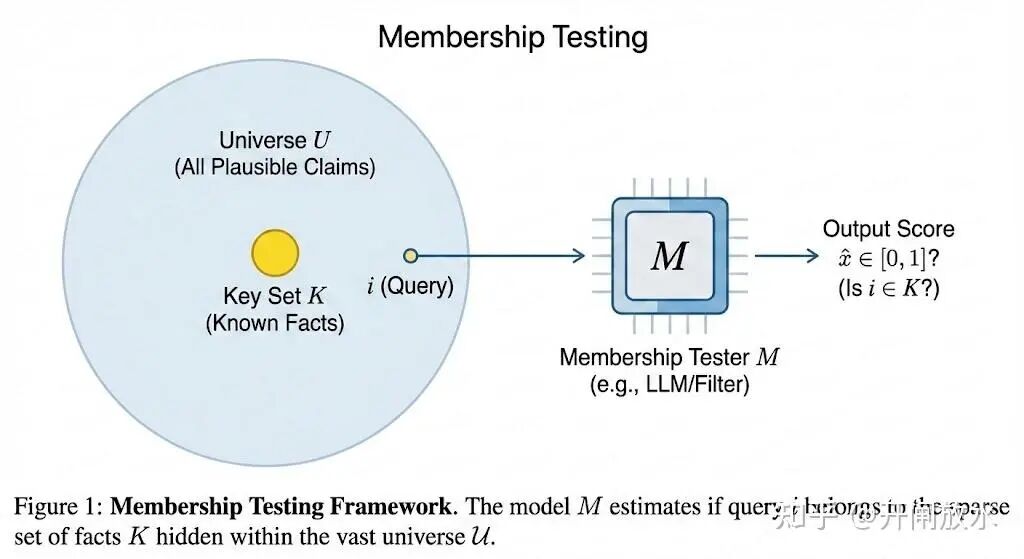
熟悉数据结构的读者可能发现,这很像布隆过滤器——这确实是我们的灵感来源之一。布隆过滤器是一种节省空间的数据结构,用于存储一个集合 K,并回答“i 是否属于 K”的问题。
其关键特性是允许一个假阳性率:如果 i ∈ K,过滤器永远输出1(无错误);如果 i ∉ K,过滤器有至多 ε 的概率错误地输出1(假阳性)。这种假阳性,本质上就是一种“幻觉”——过滤器“以为”一些从未见过的元素是自己见过的。
我们定义的成员查询器是对这一概念的推广:我们不仅允许非零的假阳性率,还允许非零的假阴性率,并且输出可以是 [0,1] 区间内的任意实数,而不仅仅是二元 0/1。
两种错误衡量标准:对数损失 vs FPR/FNR
这种推广可以建模 LLM 处理随机事实的两种模式:概率估计和真假判断。
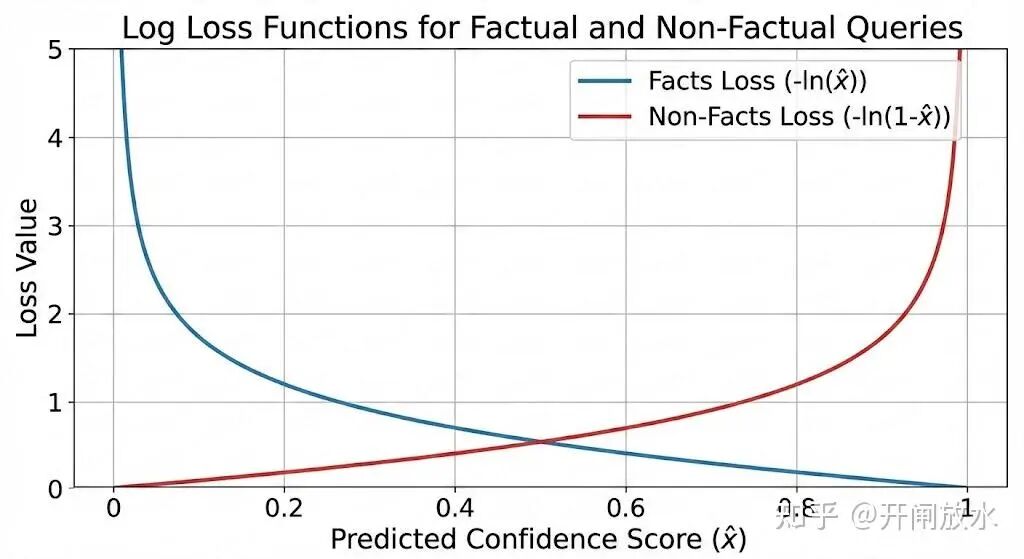
概率估计。LLM 本质上是一个概率模型,其机制鼓励输出一个概率 x̂_i ∈ (0,1),来预测 i ∈ K 为真的可能性。衡量这种预测好坏的标准通常是交叉熵或对数损失:
- 如果
i ∈ K(是事实),那么输出 x̂_i 带来的“惩罚”是 -ln(x̂_i)。
- 如果
i ∉ K(是非事实),那么惩罚是 -ln(1 - x̂_i)。
这种惩罚函数的特点是,当模型对错误答案过于自信时(例如事实却给出极低概率),惩罚会急剧增大。
真假判断。假设我们通过后处理(如设定阈值)将 LLM 的置信度输出转化为二元决策,从而筛选出一个它认为的“事实”子集。此时,我们的目标就与过滤器类似——我们希望控制假阴性率和假阳性率。对应的线性损失函数为:
- 如果
i ∈ K,错误为 1 - x̂_i。
- 如果
i ∉ K,错误为 x̂_i。
这种损失对极端错误的惩罚不那么严厉。
核心结论:幻觉是空间最优的必然结果
我们的主要定理(一个率失真定理)表明:给定一个目标错误率,为了达到这个错误水平,任何成员查询器(包括 LLM)所必需的存储信息量,由一个关键的 KL散度项决定。
定理直观理解
想象宇宙 U 中包含一百万个“看起来像判例”的陈述,但只有一千个是真的。对于查询器来说,默认状态下每个元素都极有可能是非事实,因为真事实太稀疏了。
那么,要想让查询器在面对真事实时输出高置信度,它就必须为每一个真事实额外存储一些信息,将其从默认的“非事实海洋”中标记出来。这个“标记”所需的信息量,恰好等于事实上的置信度分布与非事实上的置信度分布之间的 KL 散度。KL 散度越大,区分越明显,但也越耗费存储空间。
1. 对数损失视角:高置信幻觉是“最自然”的错误
在这个视角下,求解最小化 KL 散度(即最省空间)的置信度分布,是一个凸优化问题。最优解呈现出一种非常有趣的模式:
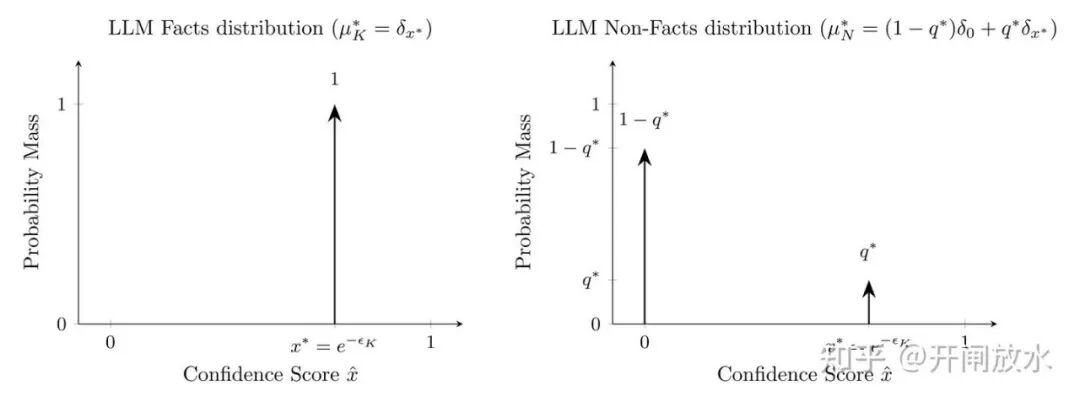
用通俗的话说:
- 模型会以一个高置信度 x* 来“记住”所有事实。
- 但对于非事实,模型会坚定地拒绝大部分(给出 0 置信度),但同时会“记住”一小部分非事实,并给它们分配与真事实完全相同的高置信度 x*。这一小部分就是幻觉。
这里的荒诞之处在于:在模型眼中,幻觉内容和真事实一模一样,不是“模糊地觉得可能”,而是“以完全相同的、高置信度认定为真”。这意味着,任何试图通过设定置信度阈值来过滤幻觉的方案,在这个最优模型上都会失效——你会把真事实和幻觉一起接受或一起拒绝。
我们在小型 Transformer 模型上进行了合成实验,结果与理论预测高度吻合。
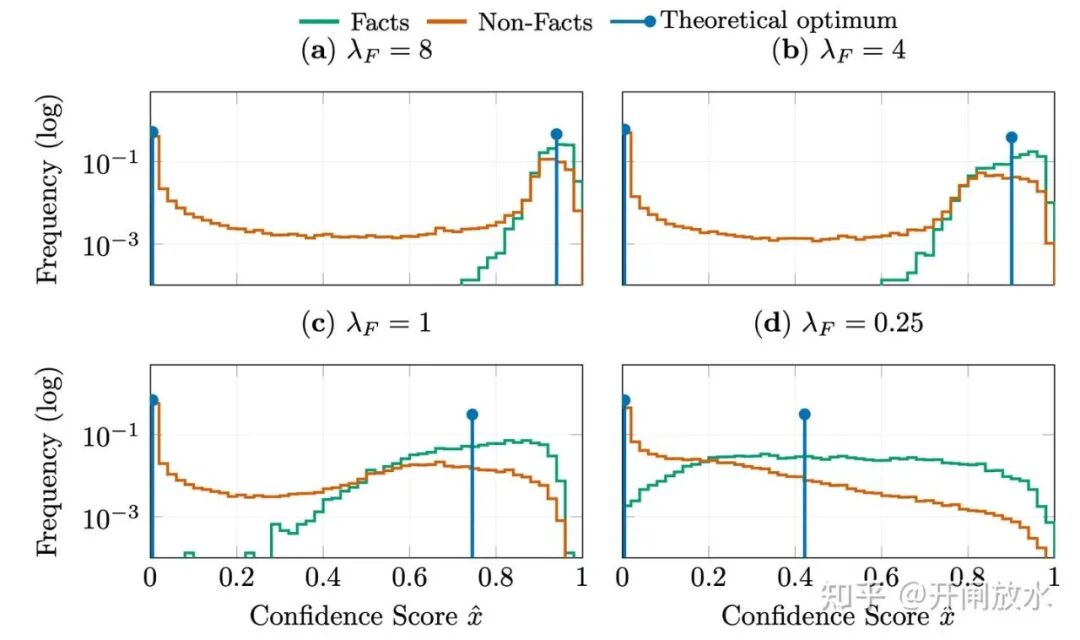
观察上图(红色为非事实分布),可以看到在高置信度区域,红色曲线出现了明显的“鼓包”,这正是被模型“高置信度幻觉”的那部分非事实。实验模型的实际分布与理论下界非常接近,只多用了约 12% 的信息量。
另一个发现是,过分强调降低事实错误(提高召回率),反而会导致更多非事实被拖入高置信区,不仅幻觉率飙升,整体错误率也可能上升。这为训练提供了一个实用洞见:一味追求高召回可能并不划算,适当强调“拒绝非事实”或许是更优策略。
2. 二元判断视角:为什么无法彻底消除幻觉?
如果我们退一步,只要求 LLM 像二元分类器一样工作(知道就说知道,不知道就拒绝),情况又如何?这正是前面提到的 Abstention 思路。
我们的理论在此视角下,给出了传统布隆过滤器空间下界的自然推广:
如果一个过滤器同时拥有假阳性率 FPR 和假阴性率 FNR,那么存储每个元素所需的最小空间约为 KL(Bern(1-FNR) || Bern(FPR)) 比特。
KL 散度的不对称性在这里起到了关键作用。当 FNR=0(即不允许遗漏任何真事实)时,所需空间约为 log(1/FPR),这是传统结论。然而,如果 FPR=0(即不允许任何幻觉),除非 FNR + FPR = 1(这等于随机猜测),否则所需的 KL 散度将是无穷大。
这意味着:不存在一个“只会遗忘、不会瞎编”的数据结构。特别地,不存在没有假阳性只有假阴性的“反向布隆过滤器”。
回到 LLM 的语境:如果用于记忆随机事实的“有效容量”有限,那么单纯让模型“拒绝回答”无法根除幻觉。这只会让我们在“幻觉”和“遗忘”这条权衡曲线上移动位置。完全消除幻觉,在潜在事实无穷多时,在信息论上是不可可能的。
为什么LLM的“记忆量”如此有限?
看到这里,从事大模型训练的读者可能会质疑:现在的模型动辄千亿参数,记点死知识怎么会容量不足?
这里的关键在于,我们所说的“记忆量”,并非指参数量,而是指模型权重 W 中所蕴含的、关于这批随机事实 K 的有效信息比特数,用互信息 I(W; K) 来衡量。我们认为,在现实的训练动态中,这个“事实脑容量”其实非常小,原因有二:
- 训练过程天然排斥死记硬背:无论是 Dropout、权重衰减等显式正则化,还是 SGD 带来的隐式偏好,从理论视角看,训练本身就在极力压缩模型与训练数据间的互信息。高熵、无规律的随机事实,如同噪声一样容易被“过滤”掉。
- 结构化知识挤占了空间:世界知识中不仅有死记的随机事实,还有语法、逻辑等规律性强、出现频率高、对降低损失贡献大的结构化知识。模型在训练早期就会优先将“记忆预算”分配给这些更“划算”的知识。
因此,即便模型总参数量巨大,真正分配给“背电话号码”这类随机事实的有效比特数也捉襟见肘。在这个严苛的预算限制下,为了最小化整体损失,模型只能遵循信息论的最优解,选择“以高置信度幻觉一部分非事实”这种最节省空间的妥协方案。
那么,如何增加有效记忆量?
- 通过大量针对性训练,强制模型在特定随机事实上达到极低错误率(但可能有其他代价)。
- 使用 RAG。这实际上是绕过参数记忆瓶颈的巧妙方法。RAG 允许模型从外部知识源实时检索,无需将所有事实硬编码进权重,从而回归其更擅长的理解、推理和信息整合角色。
总结
让我们回到开头提出的三个问题,用本文的视角给出回答:
-
为什么随机知识(如号码、判例)最易产生幻觉?
因为这些知识缺乏内在规律,模型必须逐条死记,每条都消耗宝贵的“记忆容量”。我们的定理表明,容量有限时,产生高置信度的幻觉是数学上最优的错误方式。知识越随机、越需死记,就越容易触发此机制。
-
为什么“让模型说不知道”会导致过度拒绝?
因为在最优解中,被幻觉的非事实和真事实共享完全相同的置信度。任何想通过阈值剔除幻觉的尝试,都会无差别地拒绝掉一部分真事实。在有限记忆下,降低幻觉与避免过度拒绝是不可兼得的。
-
为什么RAG是自然的出路?
我们的理论下界针对的是参数化记忆(事实存储在模型权重中)。RAG 通过外挂数据库,直接绕开了这一瓶颈,使模型不必充当一个“有限的随机事实过滤器”,而是能专注于其更本质的优势。因此,RAG 并非简单的工程技巧,而是信息论指引下的一个根本性解决方案。
对于希望深入探讨人工智能理论基础,或对算法与信息论在AI中的应用感兴趣的开发者,欢迎在云栈社区继续交流。
参考文献
- Why Language Models Hallucinate
- Can AI Assistants Know What They Don't Know?
- Understanding LLM Behaviors via Compression: Data Generation, Knowledge Acquisition and Scaling Laws
 发表于 2026-3-7 09:23:27
|
查看: 157|
回复: 0
发表于 2026-3-7 09:23:27
|
查看: 157|
回复: 0
