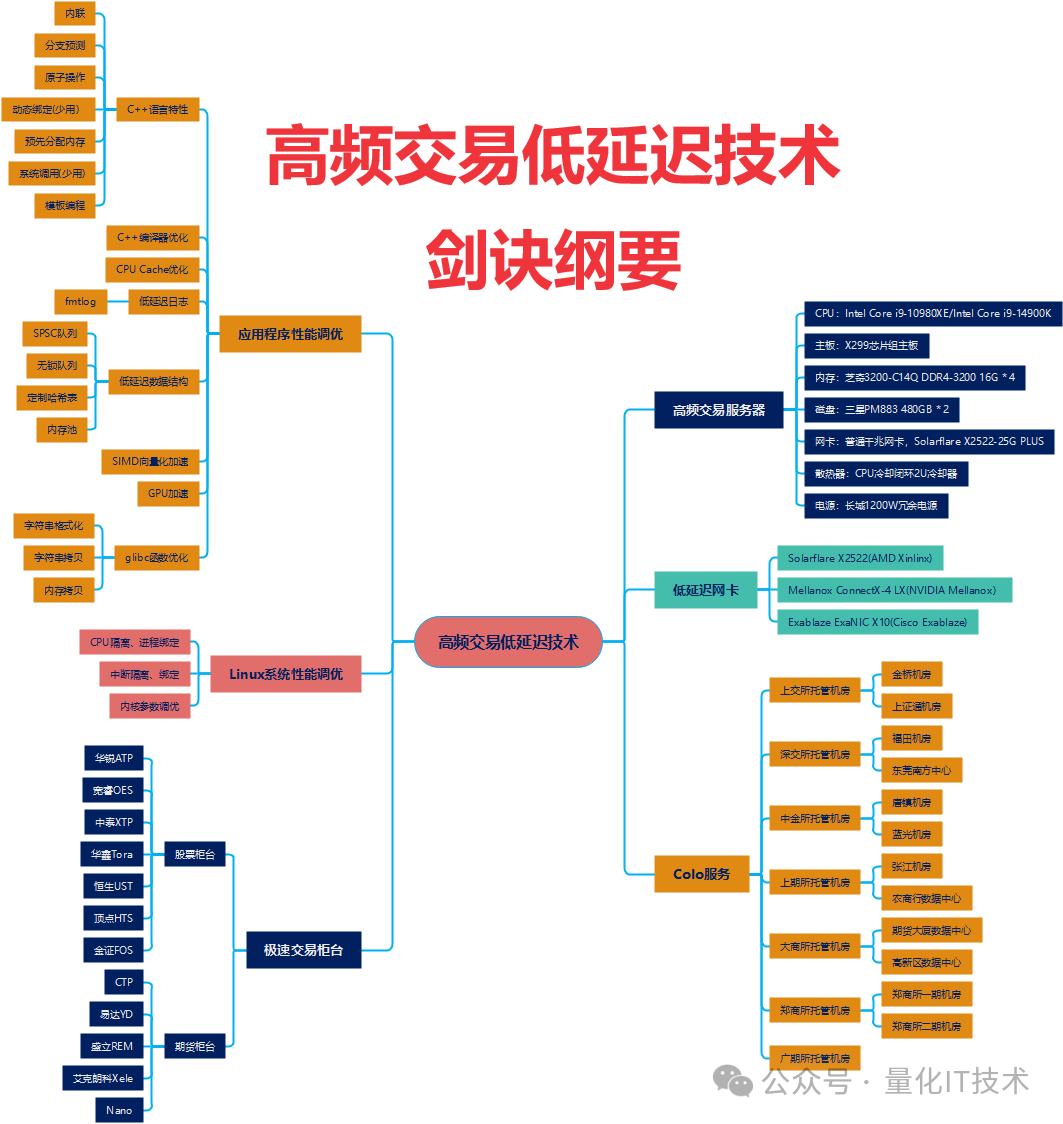
高频交易(High Frequency Trading, HFT)的核心在于速度,其目标是从市场微观结构的瞬时变化中捕捉利润,例如证券买卖报价之间的微小价差,或同一资产在不同交易所间的短暂定价偏差。为了实现纳秒级的优势,整个技术栈——从应用程序、操作系统、硬件到网络部署——都必须进行极致的优化。本文将深入解析构成高频交易低延迟体系的关键技术组件。
一、低延迟网卡与网络加速
在追求极限延迟的战场上,网卡和网络协议栈是首要突破口。专用低延迟网卡及其配套的 Kernel Bypass 技术能大幅削减数据包在操作系统内核中的处理开销。
金融行业常见的低延迟网卡主要有以下几类:
- Solarflare X2522/X3522:原属于Solarflare,现为AMD旗下Xilinx的低延迟网卡产品线。
- Mellanox ConnectX-4 LX:NVIDIA旗下Mellanox品牌的低延迟网卡。
- Exablaze ExaNIC X10:Cisco旗下Exablaze公司推出的低延迟网卡。
以Solarflare网卡及其Onload套件为例,它提供了三种不同层次的低延迟使用模式:
1. Onload
这是一种透明的Kernel Bypass方案。它提供了完全兼容标准Socket的编程接口,用户无需修改已有网络代码,只需通过LD_PRELOAD预加载libonload.so库,程序即可自动享受内核旁路带来的低延迟优势,对代码侵入性为零。
2. TCPDirect
它在更底层的ef_vi接口之上实现了TCP/UDP协议栈,提供了名为zocket的类Socket API。tcpdirect继承了ef_vi的零拷贝(Zero-Copy)特性,但要求使用大页(Huge Pages)内存。性能比Onload更高,但需要用户适配新的API。
3. ef_vi
这是最底层的Level 2 API,允许直接收发原始以太网帧,不提供任何上层协议(如IP、TCP)支持。其最大特点是零拷贝:用户需要预先分配一系列接收缓冲区并提交给ef_vi驱动。网卡收到数据包后,会直接DMA到用户指定的缓冲区,应用程序通过轮询事件队列获取已填充数据的缓冲区ID即可开始处理,处理完毕后再将缓冲区归还驱动循环使用。这种方式延迟最低,但需要用户自己处理所有网络协议。
以下是一份关于Solarflare X2522网卡在不同加速模式下的延迟测试数据(32字节消息的半程往返延迟),可以直观看出不同技术层次的性能差异:

二、高频交易服务器硬件配置
高频交易服务器为了榨取最高主频,常采用可超频的高端桌面级CPU,并围绕其构建极致优化的硬件环境。常见的CPU选择包括Intel Core i9-10980XE、i9-12900KS、i9-13900KS等。
一套典型的高频交易服务器配置可能如下:
- CPU:Intel Core i9-10980XE (18核心,24.75MB L3缓存)
- 主板:X299芯片组主板
- 内存:芝奇 3200-C14Q DDR4-3200 16G * 4(追求低延迟时序)
- 硬盘:三星 PM883 480GB * 2(用于系统和日志)
- 网卡:板载千兆管理网卡 + Solarflare X2522-25G PLUS低延迟网卡
- 散热器:CPU闭环液冷2U散热器
- 电源:长城1200W冗余电源
三、托管服务
延迟的另一个关键因素是物理距离。为了将网络传输延迟降至最低,高频交易公司普遍采用托管服务,即将自家交易服务器直接放置在交易所撮合引擎所在的数据中心内。
交易所托管机房会确保所有托管机柜到核心交易系统的光纤长度严格相等,从而保证所有客户享有相同的、最低的网络延迟。由于场地和电力限制,这些机柜资源通常非常紧俏。
在国内,个人和机构投资者无法直接连接交易所,必须通过证券公司或期货公司的席位进行交易。因此,量化团队需要向券商或期货公司申请托管机柜和网络资源,将自购或指定的交易服务器放入券商在交易所租用的机柜中,从而实现与交易所撮合主机的物理距离最小化。
四、极速交易柜台
根据监管要求,交易指令必须通过经纪公司的柜台系统转发至交易所。因此,柜台的性能直接决定了订单进入交易所前的最后一段延迟。
1. 股票极速交易柜台
这是为程序化交易提供的专用快速通道,功能精简,追求极致性能。主流极速柜台通常将现货交易和信用交易分离。核心功能包括委托申报、回执、成交回报和撤单。国内主要的股票极速柜台有:
- 华锐ATP
- 恒生UFT/UST
- 顶点HTS
- 金证FGS
- 宽睿OES
- 华宝证券LTS
- 中泰证券XTP
2. 期货极速交易柜台
期货交易同样需要通过期货公司的柜台系统。国内主流的期货极速交易柜台包括:
- CTP(综合交易平台)
- 易达YD
- 盛立REM
- 艾克朗科Xele
五、Linux系统性能调优
在操作系统层面,细致的调优能有效减少不确定性和干扰,这对于系统设计的稳定性至关重要。
- CPU隔离与绑定:将关键交易进程绑定到特定的物理CPU核心,并隔离这些核心,避免其他进程或操作系统任务调度造成的干扰。
- 中断隔离与绑定:将网卡产生的中断请求绑定到指定的、非交易核心的CPU上,防止中断处理打断交易线程的执行。
- 内核参数调优:调整网络缓冲区大小、禁用省电模式、优化时钟源等,以匹配低延迟工作负载的需求。
六、应用程序性能调优
这是开发人员最能发挥作用的领域,涉及从语言特性到计算机基础原理的深度优化。
1. C++语言层面优化
- 大量使用内联函数减少调用开销。
- 谨慎使用原子操作,确保必要的数据同步。
- 利用
likely/unlikely宏辅助分支预测。
- 避免或减少使用虚函数(动态绑定)带来的间接调用。
- 内存池化,预先分配好所需内存,避免运行时动态分配。
- 最小化系统调用次数。
2. 数据结构与算法优化
- 实现定制化的低延迟数据结构(如无锁队列、SPSC队列、定制哈希表)。
- 开发零分配或低开销的日志库。
- 精心选择数据结构以减少缓存未命中(Cache Miss)。
- 确保关键数据结构缓存行对齐,避免伪共享。
3. 编译与指令优化
- 利用编译器的向量化优化(如SIMD指令集)。
- 探索使用ICC等编译器进行针对性优化。
- 理解并优化指令重排(编译时、运行时、CPU流水线级)。
4. 其他高级优化
- 在适用场景下采用无锁编程模型。
- 探索SIMD进行数据并行计算加速。
- 针对特定计算密集型任务考虑GPU加速。
构建一套完整的高频交易低延迟系统,是一项跨越硬件、网络、系统软件和应用层的复杂系统工程。每一纳秒的提升,都来自于对上述各个环节深入骨髓的理解和精益求精的优化。希望这篇概述能为有志于进入该领域的技术人员提供一张清晰的“寻宝图”。如果你想深入探讨其中任何一点,欢迎来我们云栈社区交流。
 发表于 2026-4-15 02:14:27
|
查看: 145|
回复: 0
发表于 2026-4-15 02:14:27
|
查看: 145|
回复: 0
