XGBoost 在解决结构化数据问题,比如表格数据预测方面表现尤为出色。它的全称是“eXtreme Gradient Boosting”,即“极限梯度提升”。这个听起来有些复杂的概念,其实可以理解为一种让模型通过逐步学习并修正错误,从而变得越来越“聪明”的算法框架。
下面,我们将深入其核心思想,并结合一个完整的房价预测案例,在云栈社区的极客氛围中,一起拆解这个强大的算法。
什么是「梯度提升」?
我们可以用一个简单的例子来理解。假设我们要训练一个模型来预测房价。最初,我们可能只用一个非常简单的模型(比如总是预测平均房价),这个预测显然误差很大。接下来,我们训练第二个模型,它的任务不是直接预测房价,而是专门去学习和预测第一个模型产生的误差。然后,第三个模型再学习前两个模型组合后的残差……如此迭代,每一步都在“纠正”前序模型的错误,让整体预测能力不断“提升”。这种通过不断添加新模型来拟合残差,从而逐步逼近目标的过程,就是梯度提升的核心思想。
XGBoost:梯度提升的“强化版”
XGBoost 并非新算法,而是对经典梯度提升决策树(GBDT)在工程实现和算法细节上的深度优化。它通过引入二阶泰勒展开来更精确地逼近损失函数,并采用并行计算、加权分位数草图、缓存访问模式优化等技术,使其训练速度更快、内存效率更高,且通常能获得更好的泛化性能。
实战案例:用 XGBoost 预测房价
让我们通过一个具体的案例,直观感受 XGBoost 的工作流程。假设我们拥有某个城市的房产数据,包括房屋面积、房间数、建造年份和位置评分等特征,目标是预测房屋价格。
基本步骤:
- 初始化模型:从一个简单的初始预测开始(例如所有样本的均价)。
- 计算残差:计算当前模型预测值与真实价格之间的差异。
- 构建决策树拟合残差:训练一棵决策树,它的学习目标不是原始房价,而是上一步计算出的残差。这棵树会尝试找到特征与残差之间的关系。
- 迭代更新:将新树的预测结果(乘以一个较小的学习率)加到现有模型上,从而更新预测值。然后重复步骤2-4,不断添加新的树来修正剩余误差。
通过多次迭代,这个由许多“小树”组成的团队协作模型,最终能给出非常精准的房价预测。
XGBoost 的核心优势
- 效率与性能:得益于并行化与算法优化,它在处理大数据集时速度极快,且预测精度往往在各类竞赛中名列前茅。
- 防止过拟合:内置了正则化项(L1和L2)、子采样、最大深度限制、学习率等机制,有效控制模型复杂度,提升泛化能力。
- 灵活可解释:既能处理回归/分类任务,也支持自定义损失函数。同时,它可以输出特征重要性,帮助我们理解哪些特征对预测影响最大。
公式推导:理解XGBoost的数学本质
1. 树模型与损失函数
假设我们有数据集 $\mathcal{D} = \{(x_i, y_i)\}$,其中 $x_i$ 是特征,$y_i$ 是目标值。XGBoost 模型包含 $K$ 棵树,预测值是所有树输出的加权和:
$$\hat{y}_i = \phi(x_i) = \sum_{k=1}^{K} f_k(x_i), \quad f_k \in \mathcal{F}$$
其中,$f_k$ 代表第 $k$ 棵树,$\mathcal{F}$ 是所有可能的树结构空间。每棵树 $f_k$ 将样本映射到一个叶子节点,并为该节点赋予一个得分 $w$。
我们的目标是找到一组树,最小化以下正则化目标函数:
$$\mathcal{L}(\phi) = \sum_{i} l(y_i, \hat{y}_i) + \sum_{k} \Omega(f_k)$$
这里,$l$ 是可微的损失函数(如均方误差),$\Omega(f_k)$ 是正则化项,用于惩罚模型的复杂度,定义为 $\Omega(f) = \gamma T + \frac{1}{2}\lambda \|w\|^2$,其中 $T$ 是树叶子的数量。
2. 二阶泰勒展开与增量训练
XGBoost 采用加法训练策略。假设在第 $t$ 次迭代时,模型当前的预测为 $\hat{y}_i^{(t-1)}$,我们想要添加一棵新树 $f_t$ 来最小化目标函数。我们对损失函数进行二阶泰勒展开:
$$\mathcal{L}^{(t)} \approx \sum_{i=1}^{n} [l(y_i, \hat{y}_i^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)] + \Omega(f_t)$$
其中,$g_i = \partial_{\hat{y}^{(t-1)}} l(y_i, \hat{y}_i^{(t-1)})$ 和 $h_i = \partial_{\hat{y}^{(t-1)}}^2 l(y_i, \hat{y}_i^{(t-1)})$ 分别是损失函数的一阶和二阶梯度。移除常数项 $l(y_i, \hat{y}_i^{(t-1)})$,我们得到第 $t$ 轮的简化目标:
$$\tilde{\mathcal{L}}^{(t)} = \sum_{i=1}^{n} [g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)] + \Omega(f_t)$$
3. 叶子节点最优权重的求解
定义 $I_j = \{ i | q(x_i) = j \}$ 为被分配到叶子 $j$ 的样本集合,$q(x)$ 表示样本 $x$ 被分配到的叶子索引。将树结构 $f_t$ 的定义和正则项 $\Omega$ 代入上述目标,并对其关于叶子权重 $w_j$ 求导,可得叶子 $j$ 的最优权重为:
$$w_j^* = -\frac{\sum_{i \in I_j} g_i}{\sum_{i \in I_j} h_i + \lambda}$$
相应的,当树结构固定时,该结构带来的最小损失值为:
$$\tilde{\mathcal{L}}^{(t)}(q) = -\frac{1}{2} \sum_{j=1}^{T} \frac{(\sum_{i \in I_j} g_i)^2}{\sum_{i \in I_j} h_i + \lambda} + \gamma T$$
这个分数被用作评估树结构好坏的标准,类似于决策树中的“不纯度”度量,XGBoost 在构建树时就是通过贪心算法来最大化这个分数的增益。
完整案例:从数据生成到模型评估
我们将通过代码完整演示以下步骤:
- 生成虚拟数据:模拟包含面积、房间数、房龄、位置评分的房价数据集。
- 训练 XGBoost 模型:使用 Python 的
xgboost 库构建回归模型。
- 可视化分析:绘制数据分布、训练过程监控、特征重要性及预测效果图。
代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from xgboost import XGBRegressor, plot_importance
import xgboost as xgb
# 生成虚拟数据集
np.random.seed(42)
n_samples = 5000
area = np.random.normal(1500, 500, n_samples) # 房屋面积
rooms = np.random.randint(2, 7, n_samples) # 房间数量
age = np.random.randint(1, 30, n_samples) # 建造年份
location_score = np.random.uniform(1, 10, n_samples) # 位置评分
# 假设真实的房价与这些特征的线性关系,再加入噪声
price = 5000 + 0.3 * area + 10000 * rooms - 150 * age + 5000 * location_score + np.random.normal(0, 10000, n_samples)
# 创建 DataFrame
data = pd.DataFrame({
'Area': area,
'Rooms': rooms,
'Age': age,
'Location_Score': location_score,
'Price': price
})
# 数据分为训练集和测试集
X = data[['Area', 'Rooms', 'Age', 'Location_Score']]
y = data['Price']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义和训练 XGBoost 回归模型,添加 eval_set 参数
eval_set = [(X_train, y_train), (X_test, y_test)]
model = XGBRegressor(objective='reg:squarederror', max_depth=4, learning_rate=0.1, n_estimators=100, random_state=42)
model.fit(X_train, y_train, eval_set=eval_set, eval_metric="rmse", verbose=False)
# 预测结果
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
# Data Distribution
plt.figure(figsize=(10, 6))
sns.scatterplot(x='Area', y='Price', hue='Rooms', size='Location_Score', sizes=(20, 200), data=data, palette="viridis")
plt.title("Relationship between Area and Price (by Room Count and Location Score)")
plt.xlabel("Area (Square Feet)")
plt.ylabel("Price")
plt.legend(title="Room Count & Location Score", loc="upper left", bbox_to_anchor=(1, 1))
plt.show()
# Loss Change during Training
results = model.evals_result()
epochs = len(results['validation_0']['rmse'])
x_axis = range(0, epochs)
plt.figure(figsize=(10, 6))
plt.plot(x_axis, results['validation_0']['rmse'], label='Train')
plt.plot(x_axis, results['validation_1']['rmse'], label='Test')
plt.title("RMSE during XGBoost Training")
plt.xlabel("Epoch")
plt.ylabel("RMSE")
plt.legend()
plt.show()
# Feature Importance
plt.figure(figsize=(10, 6))
plot_importance(model, importance_type='weight', title='Feature Importance (Based on Frequency of Use)')
plt.show()
# Actual vs Predicted Values
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, c='red', marker='o', edgecolor='k', alpha=0.6)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2)
plt.title("Actual vs Predicted Prices")
plt.xlabel("Actual Price")
plt.ylabel("Predicted Price")
plt.show()
# Output RMSE
print(f"Test RMSE: {rmse:.2f}")
结果分析与可视化
图表1:房屋面积与价格关系散点图
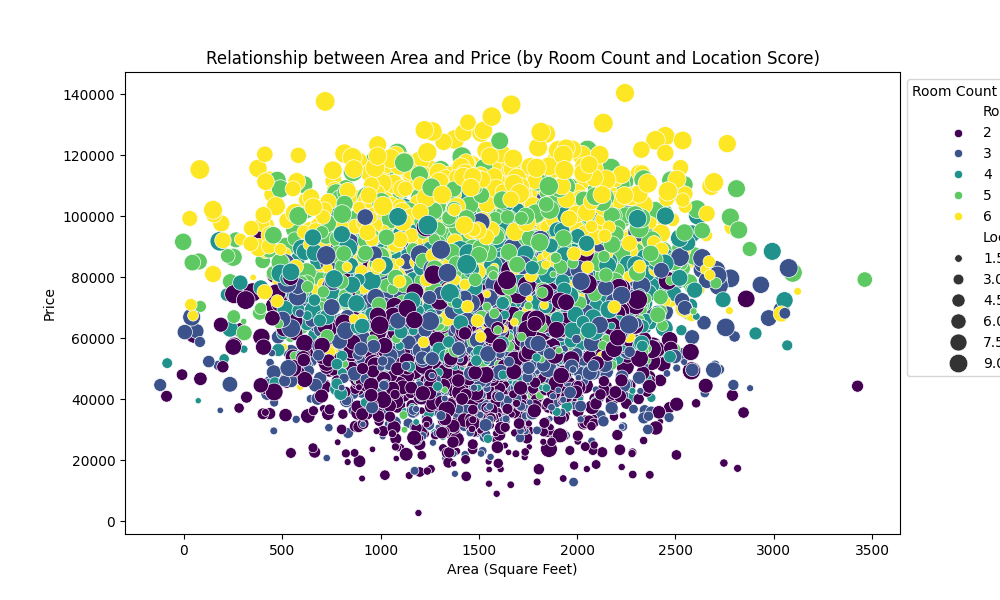
这张图展示了数据的原始分布。横轴是房屋面积,纵轴是房价。点的颜色代表房间数量,点的大小代表位置评分。可以直观看出,房价随面积和房间数增加而上升的整体趋势,同时位置评分(点的大小)也带来了分布的离散性,这正是现实数据的复杂性体现。
图表2:XGBoost 训练过程中 RMSE 的变化
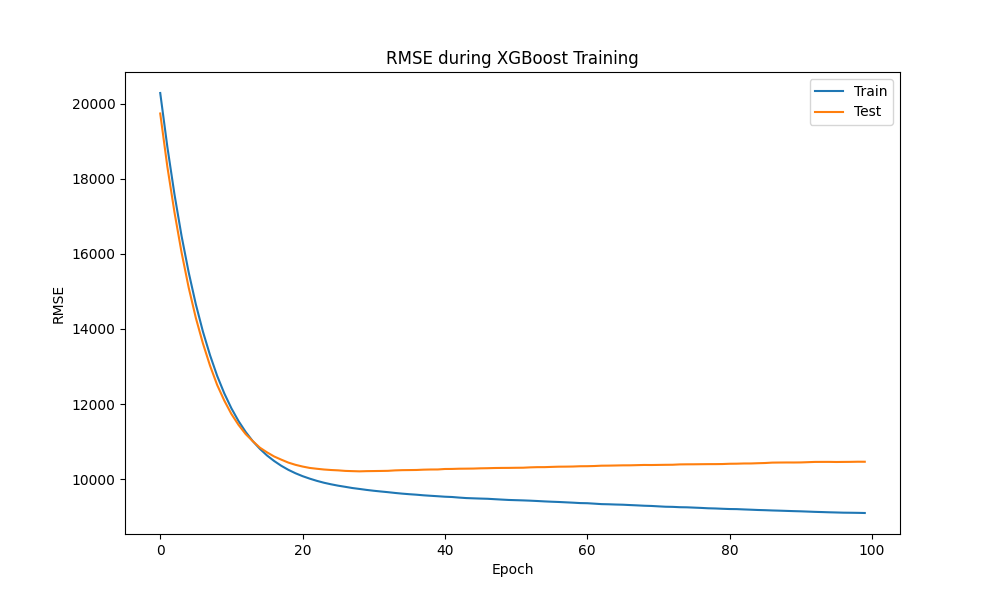
这张折线图监控了模型的训练过程。蓝色线代表训练集误差,橙色线代表测试集误差。可以看到,随着迭代(Epoch)增加,两者误差迅速下降并在约20轮后趋于稳定。测试误差未显著上升,表明模型没有严重过拟合,收敛情况良好。这种监控对于调整 n_estimators(树的数量)和 learning_rate(学习率)等关键参数至关重要。
图表3:特征重要性排名
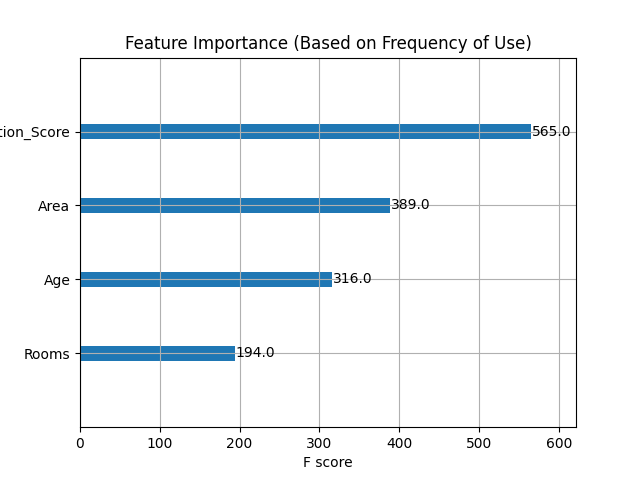
XGBoost 可以自动计算特征重要性。本图展示了基于特征在树中被用作分割点的频率(F score)排序。在本案例中,Location_Score(位置评分)和 Area(面积)是最重要的两个特征。理解特征重要性是机器学习中特征工程和模型解释的关键一步。
图表4:真实房价与预测房价对比图
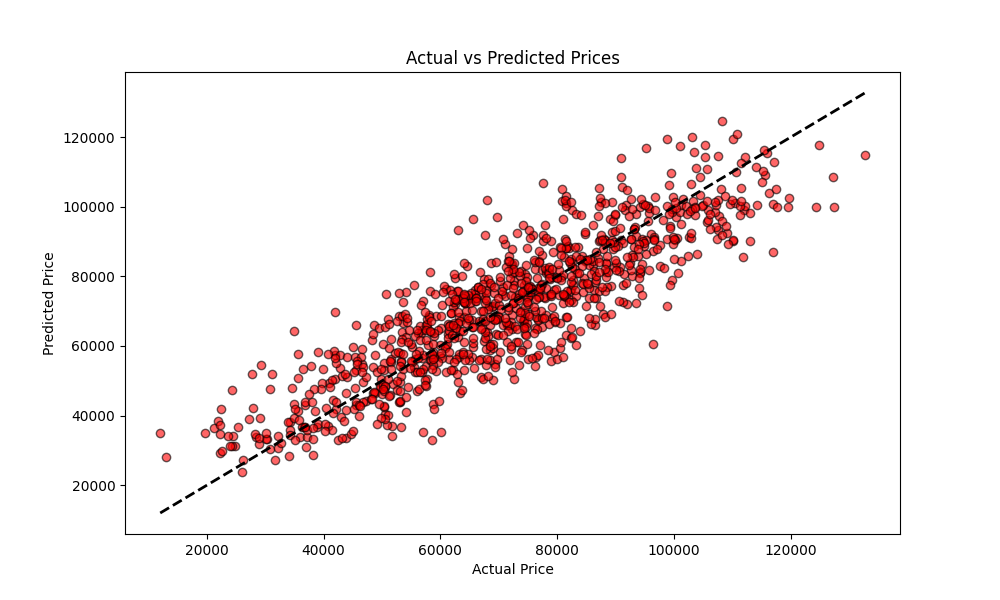
这是模型性能的最终检验。我们将测试集的真实房价(横轴)与模型预测的房价(纵轴)进行对比。理想情况下,所有点应落在黑色虚线的对角线上。从图中可见,大多数点紧密分布在对角线两侧,说明模型预测较为准确。一些偏离较远的点则代表了模型的预测误差。
最终,控制台会输出模型的量化评估指标:Test RMSE: 10196.19。这个根均方误差值为我们提供了预测误差的大致范围。
总结
通过本文,我们从直观比喻深入到数学原理,再落地到完整的代码实战,系统性地解析了 XGBoost。作为深度学习时代之前最强大的监督学习算法之一,XGBoost 凭借其优异的性能、速度和灵活性,在金融风控、销售预测、搜索排序等众多领域仍有不可替代的价值。理解其梯度提升的本质、正则化控制的思想以及高效的工程实现,将帮助你更好地在实战中驾驭这一利器。
 发表于 2026-4-12 01:52:19
|
查看: 235|
回复: 0
发表于 2026-4-12 01:52:19
|
查看: 235|
回复: 0
