还记得我们在上文探讨的分布式调用链追踪系统吗?有读者反馈对其中的实现原理还想了解更多细节,本篇我们就来一次透彻的拆解,聊聊在微服务架构下,如何构建一个“看得见”的追踪系统。本文力求通俗易懂,感谢「码农翻身」刘欣老师的思路启发!
微服务架构下的痛点
在微服务架构中,一次用户请求的背后,往往是多个服务模块、多种中间件、多台服务器协同工作的结果。这些调用关系可能是串行的,也可能是并行的。这就带来了一个核心问题:当请求完成时,我们如何清晰地知道它到底调用了哪些服务?调用顺序是怎样的?每个环节的性能表现如何?一旦出现性能瓶颈,又该如何快速定位?
来看一个稍微复杂的架构示例:
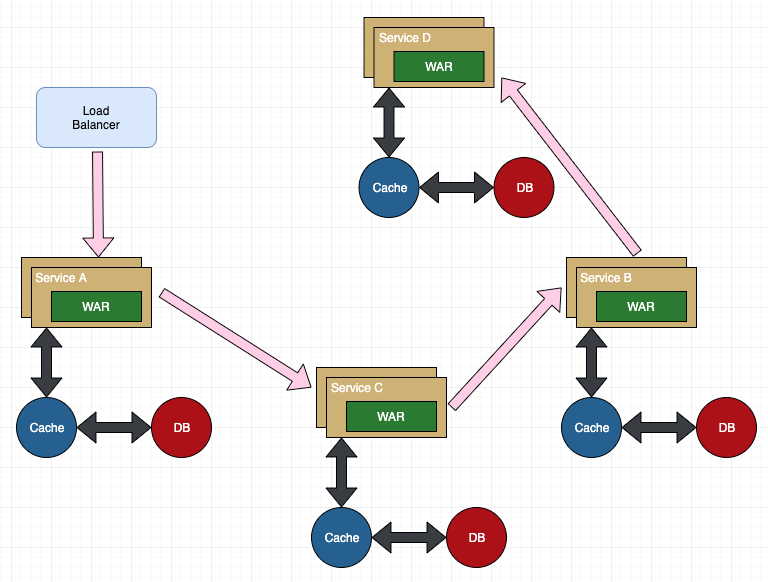
假设用户反馈某个页面响应很慢,而我们只知道该页面的请求链路是 A -> C -> B -> D。在缺乏有效监控的情况下,我们很难判断到底是 A、C、B、D 中的哪一个服务拖慢了整体速度。
问题还没完。在真实的分布式系统中,每个服务(如 Service A、B、C、D)通常都会部署在多台机器上以实现高可用和负载均衡。
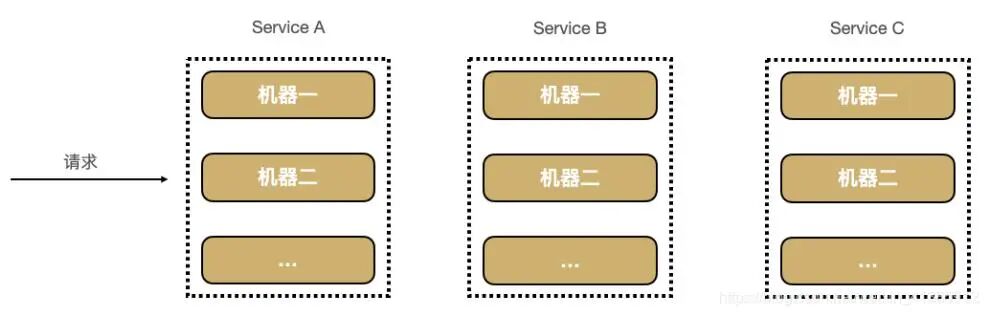
这时,我们甚至连“请求具体落在了哪台机器上”都无从得知。这种“看不见”的状态,直接导致了微服务运维中的三大痛点:
- 问题排查难度大、周期长:犹如大海捞针,需要人工逐层翻查日志。
- 特定场景难以复现:无法精准记录和复现问题发生时的完整调用上下文。
- 系统性能瓶颈分析困难:无法量化每个服务的处理耗时,难以定位性能短板。
那么,有没有一种方法可以自动、准确地记录下完整的调用链条,并用直观的方式展示出来呢?答案就是构建一个分布式调用链追踪系统。
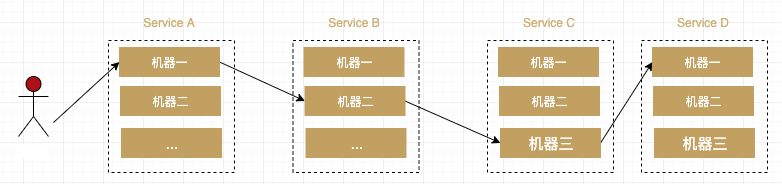
如何设计一个追踪系统?
如果我们自己来设计这样一个系统,该怎么思考?
第一步:给每次完整的请求一个“身份证”
首先,我们必须能区分不同的请求链路。我们给每一次完整的请求分配一个全局唯一的 ID,称为 TraceID。在这次请求涉及的所有服务调用中,都必须携带这个 TraceID。这样一来,所有相关的子调用就能被关联到同一个“案件”下了。
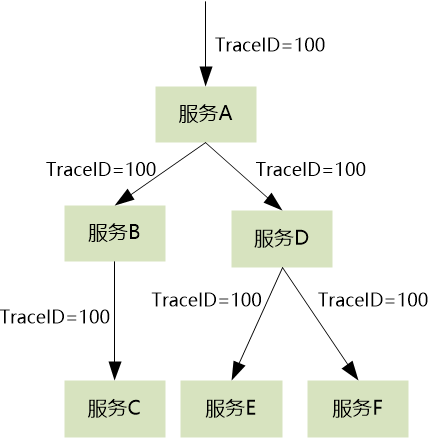
第二步:理清调用间的“父子关系”
仅有 TraceID 还不够。假设我们有如下调用链,如果只孤立地记录了:
A -> B
B -> C
A -> D
D -> E
D -> F
即便知道它们拥有相同的 TraceID,我们也无法还原出正确的调用拓扑图。因此,必须记录调用之间的先后次序和父子关系。
我们需要为每一次调用(例如 A->B 这次 RPC)分配一个 ID,称为 SpanID。同时,子调用需要知道是谁调用了它,这个 ID 就是 ParentSpanID。通过这种父子关系,我们就能构建出完整的调用树。
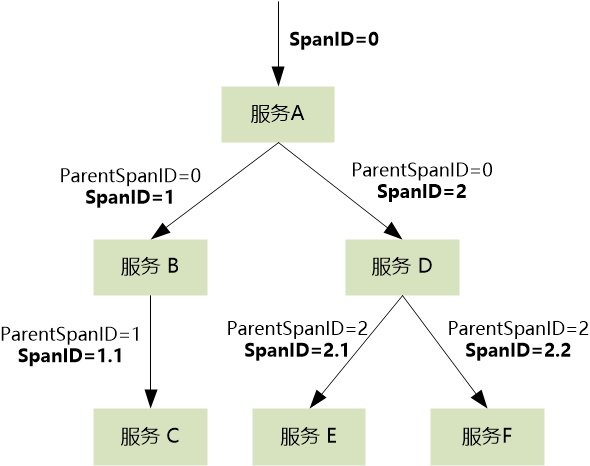
用表格来记录,信息就非常清晰了:
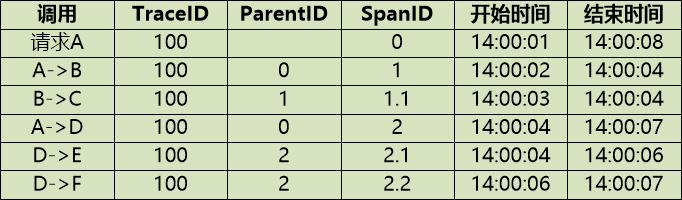
有了这些结构化的数据,生成可视化的调用链视图就水到渠成了。
施展魔法的“Agent”
理论很清晰,但在分布式环境中,如何让各个服务自动、正确地生成并传递 TraceID、ParentSpanID、SpanID 呢?让业务服务自己来处理这些追踪逻辑显然不行,侵入性太强,会增加复杂度。
这就需要引入一个独立的组件——Agent。它的角色就像一个“魔法师”,部署在每个服务所在的机器上,悄无声息地完成监控和数据注入的工作。
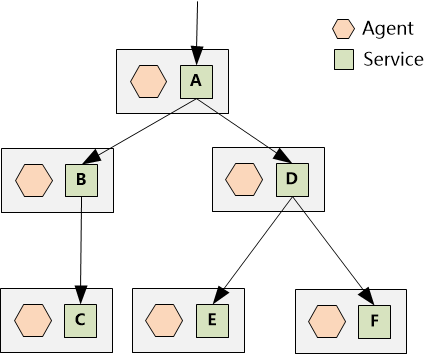
以服务 A 上的 Agent 为例,它的工作规则非常简单:
- 识别新请求:当 Agent 监控到对服务 A 的调用请求中没有 ParentSpanID,它就判定这是一次全新的请求,于是生成一个全局唯一的 TraceID。
- 传递调用关系:当服务 A 调用服务 B 时,Agent 会为这次调用生成一个 SpanID(例如
1),并将其作为 ParentSpanID 塞入发给服务 B 的请求中。这样,服务 B 的 Agent 在处理后续调用(如 B->C)时,就能基于这个 ParentSpanID (1) 生成子调用的 SpanID (1.1)。
- 处理并行调用:当服务 A 又调用服务 D 时,Agent 会生成另一个 SpanID (
2),并将其作为新的 ParentSpanID 传递给服务 D,以此类推。
你可能会问:微服务之间是跨进程调用的,这些追踪 ID 怎么可能在服务间“悄无声息”地传递呢?这正是 Agent “魔法”的关键——它需要理解服务间的通信协议。
以常见的 HTTP 协议为例,一个请求分为 Header 和 Body。Header 通常用于存放协议元数据(如内容长度、认证令牌),而 Body 存放业务数据。Agent 就可以巧妙地将 TraceID、ParentSpanID 等追踪信息“夹带”在 HTTP Header 中传递。这样既完全不影响业务逻辑(Body),又实现了追踪数据的透传。
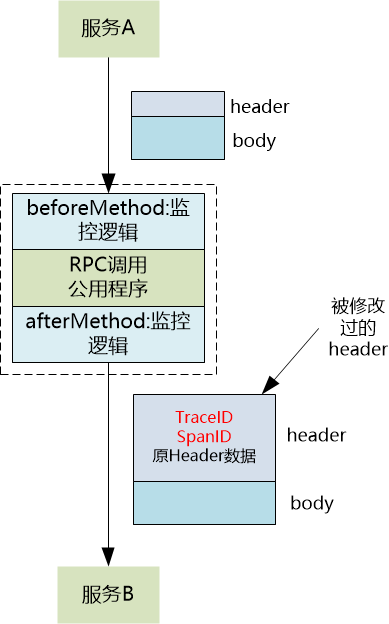
那么,Agent 是如何做到这一点的呢?它的实现原理通常是字节码增强。Agent 会定位到微服务框架中负责 RPC 调用的公共入口(例如 Dubbo 的 Filter 链),然后在运行时,动态地修改这个入口方法的字节码,在其前后植入监控逻辑。
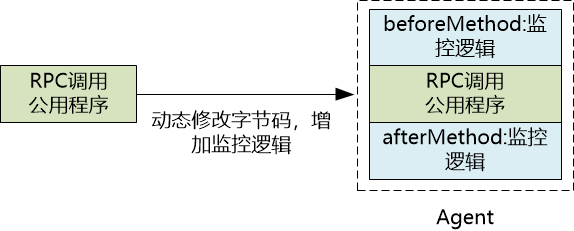
如图所示,在调用实际发生前(beforeMethod),Agent 会生成或获取追踪信息;在调用发生后(afterMethod),Agent 会记录耗时等信息。整个过程中,业务代码完全无感知。
数据的收集与展示
单个 Agent 只能看到它所在服务的“一亩三分地”。为了获得全局视角,我们需要一个收集器(Collector) 来汇聚所有 Agent 上报的数据。
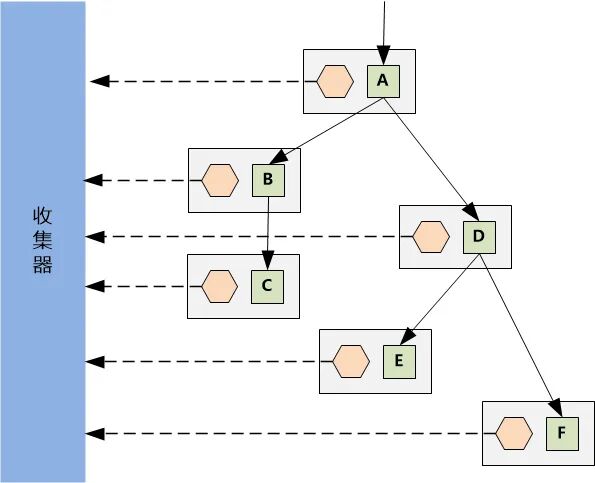
收集器拿到全局数据后,就能进行聚合、分析,并绘制出直观的调用链拓扑图和时间序列图。例如,它可以生成类似下图的火焰图或时间线图,清晰展示每次调用的耗时与层级关系,这对于性能监控和瓶颈定位极具价值。
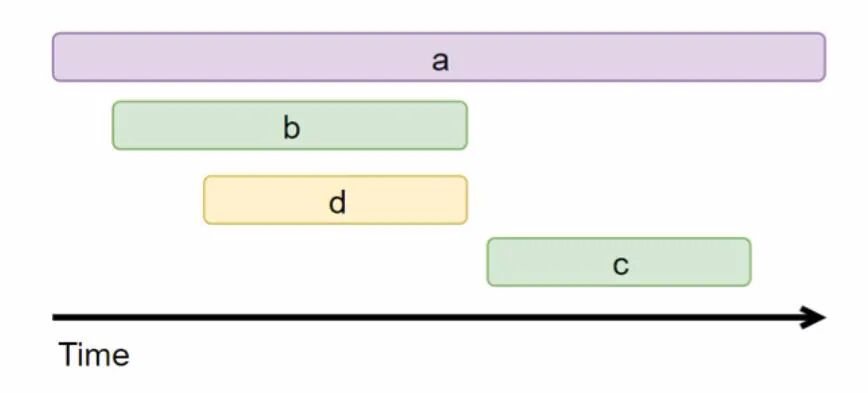
小结
至此,一个分布式调用链追踪系统的核心设计思路就清晰了:通过 TraceID 关联整个请求,通过 SpanID 和 ParentSpanID 描绘调用树,借助无侵入的 Agent 自动埋点和透传数据,最终由 收集器 汇聚信息并可视化展示。
当然,一个成熟的系统还需要考虑很多工程细节,比如采样率(是否需要记录所有请求)、全局 ID 生成算法的高效与唯一性、海量数据的存储与查询、友好的 UI 界面等。目前业界已有不少优秀的开源实现,如 SkyWalking、Zipkin、Jaeger 等,它们都是基于类似原理构建的,为我们在微服务实践中进行运维和问题排查提供了强大工具。
希望这篇解析能帮助你更透彻地理解分布式追踪系统是如何工作的。如果你对更多技术实现的细节感兴趣,欢迎在技术社区深入交流,例如在云栈社区的架构与运维板块,常有许多相关的深度讨论和实践分享。
 发表于 2026-3-7 12:43:46
|
查看: 137|
回复: 0
发表于 2026-3-7 12:43:46
|
查看: 137|
回复: 0
