在系统架构设计中,消息队列、缓存和分库分表常被视为应对高并发挑战的三大核心组件。结合我个人的项目经历,曾深度使用过 ActiveMQ、RabbitMQ、Kafka 以及 RocketMQ 等多种主流消息中间件。本文将基于这些实战经验,为你系统梳理消息队列的七种经典应用场景,希望能为你的架构设计提供一些切实可行的思路。
1 异步与解耦
我曾负责某电商平台的用户服务,其核心功能包括用户注册、信息查询与修改等。在最初的架构中,用户注册成功后,发送注册成功短信的逻辑被直接内嵌在用户中心服务里。

这种设计带来的问题显而易见:
- 性能瓶颈:如果短信服务商接口不稳定或响应超时,会直接拖慢整个用户注册接口,严重影响前端用户体验。
- 耦合过紧:短信发送属于非核心的辅助功能,但其代码变更却会迫使核心的用户中心服务频繁发布上线,增加了核心系统的维护风险和复杂度。
为了解决上述问题,我们引入了消息队列进行架构重构。

- 异步化:用户中心服务在成功保存用户信息后,只需向消息队列发送一条消息,随后即可立即响应用户,注册流程的总耗时大大缩短。
- 解耦:独立的“任务服务”消费队列中的消息,并调用短信服务。这样就将核心的用户服务与易变、非核心的短信功能彻底分离,系统间的耦合度显著降低。
2 流量削峰
在高并发场景下,突如其来的流量洪峰极易冲垮系统。例如,大量请求直接访问数据库,可能导致连接池耗尽、CPU飙升等严重后果。
在服务于神州专车订单团队时,我们遇到了类似挑战。在订单的生命周期内,任何状态变更都需要持久化到数据库。如果所有写操作都直接落库,高峰期的数据库压力将不堪重负。我们的解决方案是引入“订单落盘服务”作为消费者。

具体流程为:订单系统(生产者)在处理完前端请求并更新缓存后,将变更信息以消息形式发送到 MetaQ(消息队列)。订单落盘服务消费这些消息,进行必要的业务校验(如防止乱序),然后将数据异步写入数据库。
这样做的好处是,无论前端流量如何波动,后端的数据库写入压力都被消息队列平滑掉了。消费者的处理能力是可控且匀速的,从而保障了数据库的稳定性,也让直面用户的订单系统变得更加健壮。
3 消息总线
“总线”的概念源于硬件,指各个组件通过一个标准化的通道进行数据和指令的交换。在软件架构中,我们也可以构建一个消息总线,让各个系统通过消息队列进行通信,而非直接调用。
在某彩票公司的订单系统中,一个订单的生命周期涉及创建、拆单、出票、算奖等多个环节,分别由不同的子系统处理。如果每个系统都直接去读写核心的订单主表,势必造成混乱和难以维护的依赖网。
因此,架构师设计了“调度中心”服务。它维护着最权威的订单状态,但并不直接与其他子系统通信。所有状态的变更和指令的下达,都通过消息队列这个“总线”来完成。
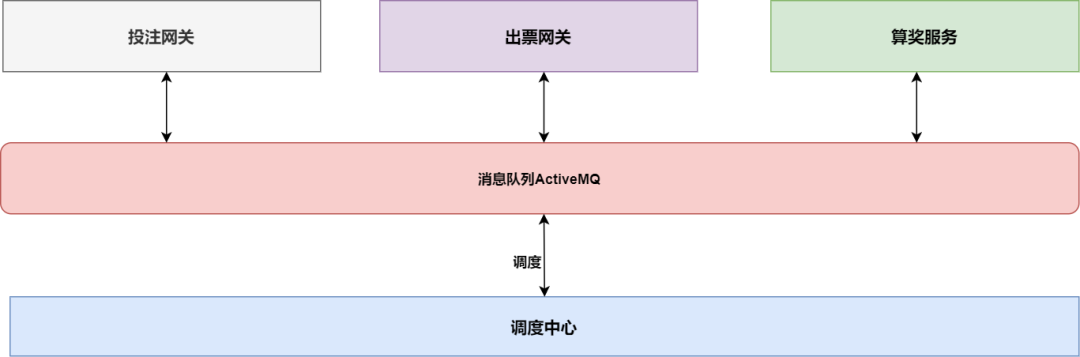
例如,出票网关完成出票后,向总线发送“出票成功”消息;调度中心消费该消息,更新订单状态,并可能触发向算奖服务发送“开始算奖”的消息。这种架构极大地降低了系统间的耦合度,让每个模块可以独立演化、各司其职。
4 延时任务
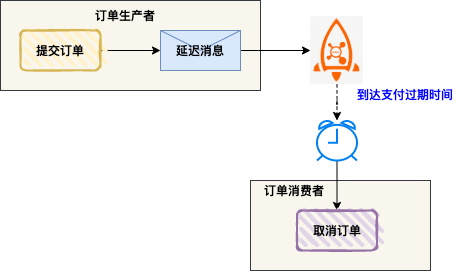
一个常见的业务场景是:用户下单后若未在规定时间内支付,订单需要自动关闭。实现这种“延时任务”,消息队列的延迟消息特性是一种非常优雅的方式。
其原理是:订单服务在创建订单后,向消息队列发送一条延迟消息(例如延迟30分钟)。消息队列会在指定时间点后将消息投递给消费者。消费者收到消息后,检查订单支付状态,若未支付则执行关单逻辑。
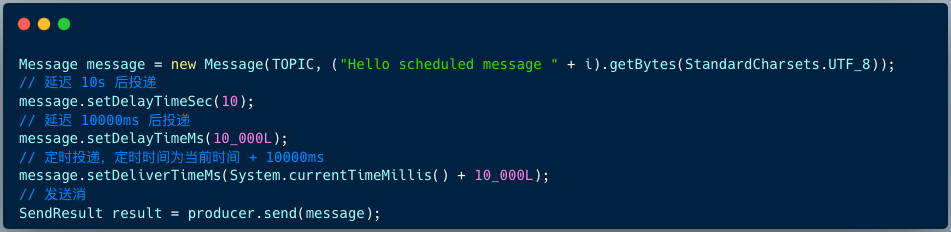
以 RocketMQ 为例,在 4.x 版本中,发送延迟消息的代码如下:
Message msg = new Message();
msg.setTopic("TopicA");
msg.setTags("Tag");
msg.setBody("this is a delay message".getBytes());
// 设置延迟level为5,对应延迟1分钟
msg.setDelayTimeLevel(5);
producer.send(msg);
RocketMQ 4.x 的延迟级别在 Broker 端通过 messageDelayLevel 参数配置。

而在 RocketMQ 5.x 版本中,支持了更灵活的任意时间延迟,提供了多个 API 供开发者设置精确的延迟或定时投递时间。
5 广播消费
广播消费模式是指,一条消息会被推送给订阅了该主题的所有消费者实例(即使它们属于同一个消费者组),确保消息至少被每个消费者消费一次。
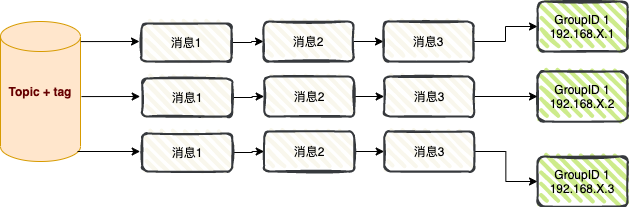
广播消费主要有两大应用场景:实时消息推送和本地缓存同步。
5.1 实时消息推送
以网约车司机端的派单推送为例。用户下单后,派单系统会通过算法将订单派给合适的司机,司机端APP需要实时收到这条派单信息。
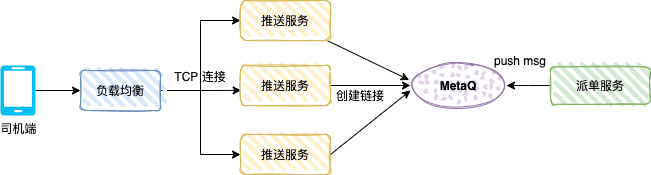
推送服务集群中的每个实例都是一个TCP长连接服务器,同时也都是消息队列的消费者,且设置为广播消费模式。当司机打开APP,会与某个推送服务建立TCP连接。派单系统(生产者)将派单消息发送到消息队列(如MetaQ)。每一个推送服务实例都会消费到这条消息。每个实例检查自己维护的连接池中是否有目标司机的TCP连接,如果有,则通过该连接将派单信息实时推送给司机端。
5.2 本地缓存同步
在高性能场景下,应用常使用本地缓存(如 Caffeine、Guava Cache)来避免频繁访问数据库或远程缓存。但当源头数据变更时,如何让所有应用节点的本地缓存保持一致?广播消费模式可以完美解决这个问题。
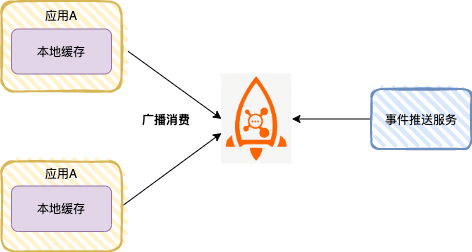
每个应用节点启动后,都作为一个广播消费者订阅“配置变更”或“字典表更新”主题。当管理后台修改了数据并发送一条更新消息后,所有节点都会消费到这条消息,并同时刷新自己内存中的本地缓存,从而保证数据的一致性。
6 分布式事务
在电商交易等复杂业务中,一个核心操作往往需要联动多个下游服务。例如,“用户支付成功”这个事件,需要触发更新订单状态、增加用户积分、通知物流发货、清空购物车等多个操作。如何保证这些操作的事务一致性?
6.1 传统XA方案:强一致,但性能差
基于XA协议的分布式事务可以保证强一致性,但需要长时间锁定多个资源,严重牺牲了系统的并发处理能力,性能往往难以接受。
6.2 普通消息方案:难以保证一致性
如果采用普通消息,先执行本地事务(更新订单),再发送消息通知下游,会面临严重的一致性问题:
- 本地事务成功,消息发送失败:下游无法感知,数据不一致。
- 消息发送成功,本地事务失败:下游错误地执行了业务,数据不一致。
- 消息发送未知(超时):无法决定是提交还是回滚本地事务。
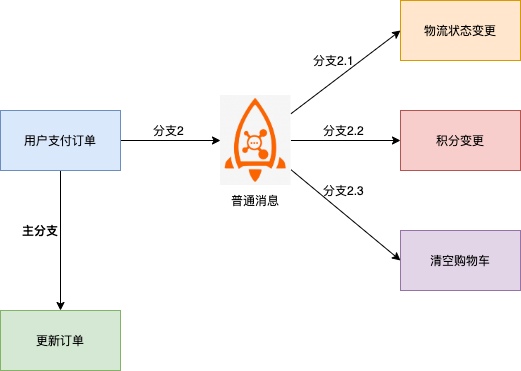
6.3 RocketMQ分布式事务消息:最终一致性
RocketMQ 提供的分布式事务消息机制,通过二阶段提交与本地事务状态回查,实现了业务的最终一致性。
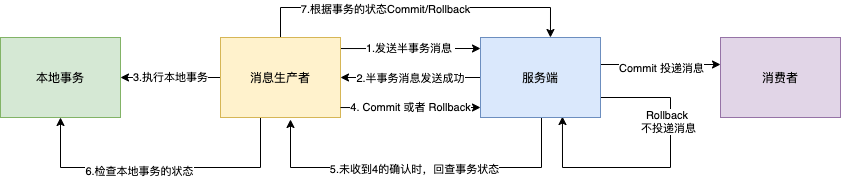
- 发送半消息:生产者向Broker发送一条“半事务消息”,此时消息对消费者不可见。
- 执行本地事务:生产者执行本地业务逻辑(如更新订单状态)。
- 提交二次确认:生产者根据本地事务结果(成功/失败),向Broker发送Commit或Rollback指令。
- Commit:Broker将半消息变为正式消息,投递给消费者。
- Rollback:Broker丢弃该半消息。
- 事务状态回查:如果Broker长时间未收到二次确认(比如生产者宕机),会主动向生产者发起回查。生产者检查本地事务状态后,再次提交确认结果。
这套机制确保了:只要本地事务成功,消息一定会被下游消费;本地事务失败,消息一定不会发出。从而在分布式系统中实现了可靠的最终一致性。
7 数据中转枢纽
在大数据领域,各种专用系统(如HBase、ElasticSearch、Spark、Hadoop)层出不穷。通常,同一份数据(如应用日志)需要被注入到多个不同的系统中进行分析处理。为每个系统单独建立一套数据采集管道成本高昂,且难以维护。
此时,消息队列(尤其是Kafka)可以扮演一个统一的数据中转枢纽的角色。

日志处理流程通常分为三部分:
- 日志采集端:部署在应用服务器上的Agent(如Filebeat)负责采集日志,并以“批量”、“异步”的方式发送到Kafka。这种方式对应用性能影响极小。
- Kafka枢纽:接收并持久化日志数据,提供高吞吐、可回溯的消息流。
- 下游处理应用:不同的消费者可以同时从Kafka中拉取数据。例如,Logstash消费日志并写入ElasticSearch供实时检索;另一个Spark流处理任务消费同样的日志进行实时计算;同时,数据还可以被导入Hadoop进行离线深度分析。
通过Kafka这个枢纽,我们实现了一份数据源的多元复用,简化了数据管道架构,提高了数据利用效率。
希望这篇对消息队列七大应用场景的梳理,能帮助你更好地理解和运用这一强大的架构工具。如果你在 分布式系统 的实践中还有其他心得或疑问,欢迎在云栈社区与更多开发者一起交流探讨。
 发表于 2026-3-7 12:46:40
|
查看: 151|
回复: 0
发表于 2026-3-7 12:46:40
|
查看: 151|
回复: 0
