
OpenAI 现已正式发布 GPT-5.4 及其性能更强的 GPT-5.4 Pro 版本。此次更新专注于专业生产力场景,旨在一次性地全面提升模型在复杂推理、代码生成与多步智能体(Agent)工作流中的表现。
本次迭代最关键的技术重构,在于赋予了模型原生且达到 SOTA 级别的计算机操作能力。这是 OpenAI 推出的首个具备此项能力的通用大模型。在专门评估桌面环境导航能力的 OSWorld-Verified 基准测试中,GPT-5.4 一举取得了 75.0% 的成功率。
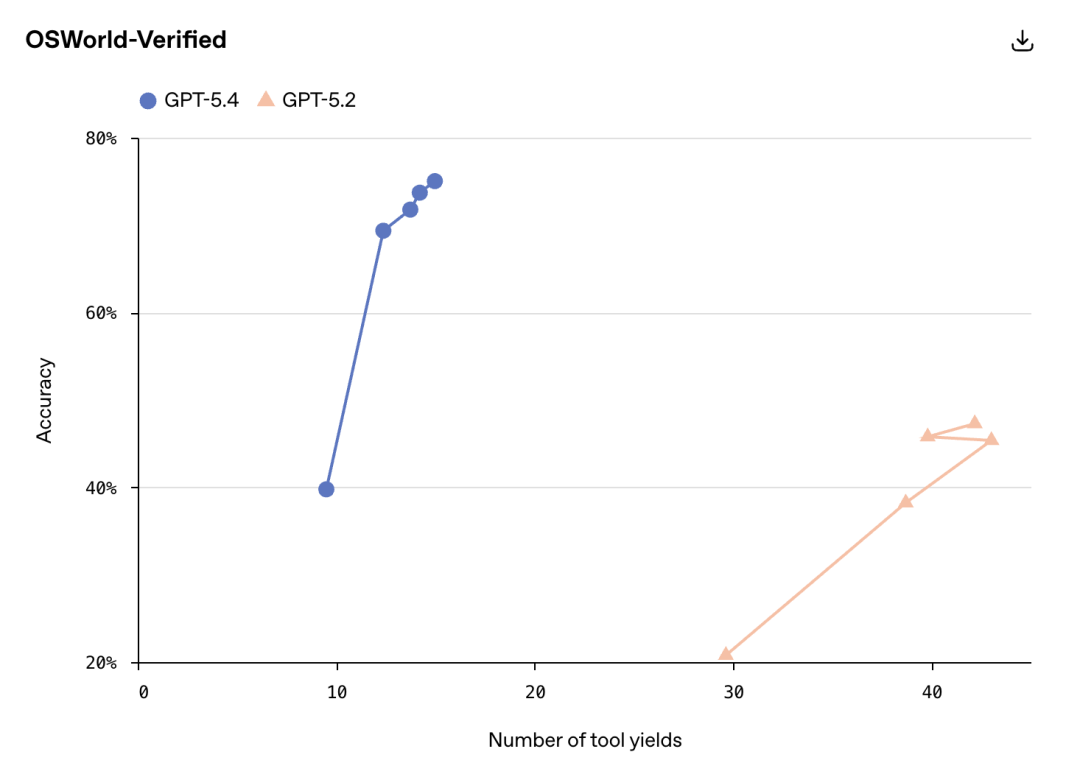
这个成绩不仅显著超越了前代模型,更是全面超过了 72.4% 的人类基准线。模型现在可以直接编写代码调用诸如 Playwright 这样的自动化工具,甚至能够根据屏幕截图直接输出键盘和鼠标的操作指令。
与此同时,模型的视觉感知底层能力也迎来了重大升级。它新增了原生图像输入细节级别,最高支持 1024万 总像素的无损感知。在文档解析测试 OmniDocBench 中,其平均误差已降至 0.109。
在职场专业任务方面,其表现实现了彻底翻盘。在面向44个职业的知识工作评估基准 GDPval 中,GPT-5.4 的胜率达到了 83.0%。针对投行级别的电子表格建模任务,其得分更是直接飙升至 87.3%。而在 PPT 生成及排版审美的盲测中,它也获得了 68.0% 的胜出率。
模型的“幻觉”问题得到了进一步压制,单个事实错误率下降了 33%。其代码能力直接继承了 GPT-5.3-Codex 的行业顶级水平。
在 Codex 和 API 端,模型开放了最高 100万 Token 的上下文窗口。开启 /fast 模式后,Token 的生成速度最高可提升 1.5倍,并支持边构建边测试的交互式可视化调试。
工具调用机制引入了全新的 Tool search 搜索架构,彻底抛弃了过去将所有工具定义硬塞入提示词的低效做法。现在,模型可以通过轻量级目录检索并按需挂载工具。在挂载 36个MCP服务器 时,Token 消耗量出现了断崖式下跌,降幅高达 47%。在深层网页检索测试 BrowseComp 中,GPT-5.4 Pro 将最高准确率拉升至 89.3%。
此外,模型的交互逻辑也变得更加“跟手”。对于长思考任务,它会预先输出思维大纲,并支持用户中途强行打断以修正思考方向。
目前,新模型已在 ChatGPT、API 和 Codex 平台全量上线。ChatGPT Plus 及以上订阅用户即日起即可使用 GPT-5.4 Thinking 替代旧版模型。
API 调用定价有所上调:GPT-5.4 的输入价格为 2.50 美元 / 百万 Token,输出价格为 15 美元 / 百万 Token;GPT-5.4 Pro 的输入价格为 30 美元 / 百万 Token,输出价格为 180 美元 / 百万 Token。
| API model |
Input price |
Cached input price |
Output price |
| gpt-5.2 |
$1.75 / M tokens |
$0.175 / M tokens |
$14 / M tokens |
| gpt-5.4 |
$2.50 / M tokens |
$0.25 / M tokens |
$15 / M tokens |
| gpt-5.2-pro |
$21 / M tokens |
- |
$168 / M tokens |
| gpt-5.4-pro |
$30 / M tokens |
- |
$180 / M tokens |
这次底层架构的统一,标志着大模型正从一个对话工具,彻底转变为支撑长线、复杂作业的系统级基础设施。不得不说,当前全球顶尖 人工智能 模型的迭代速度越来越快,希望国内的研发也能迎头赶上。关于大模型的最新动态和技术解析,欢迎来 云栈社区 的 开发者广场 与大家一起交流探讨。 |  发表于 2026-3-7 16:36:14
|
查看: 278|
回复: 0
发表于 2026-3-7 16:36:14
|
查看: 278|
回复: 0
