“并发编程不难,难的是并发中的细节。”
对于很多Java开发者来说,简历上写着“精通并发编程”并不少见。但一到面试追问细节,很多人就露怯了:知道synchronized但说不清底层原理、会用线程池但不知如何调参、了解volatile却讲不清它和synchronized的核心区别。
会用的最多叫熟悉API,懂原理的才算是合格的工程师。
本文将系统性地梳理Java并发编程的核心知识点,尤其是那些在面试求职中高频出现的考点。从基础概念到实用工具,帮你把知识串联起来,不再惧怕追问。
一、线程基础:先搞清楚这些概念
1.1 进程和线程的区别

| 对比项 |
进程 |
线程 |
| 定义 |
正在运行的程序 |
进程内的执行单元 |
| 资源 |
独立内存空间 |
共享进程资源 |
| 开销 |
大(创建/切换慢) |
小(创建/切换快) |
| 通信 |
复杂(管道/消息队列) |
简单(共享内存) |
| 独立性 |
独立 |
依赖进程 |
通俗理解:进程是工厂,线程是工厂里的工人。工人共享工厂的资源(设备、原料),但各自干各自的活。
1.2 线程的创建方式
Java 中创建线程主要有四种方式:
// 方式一:继承 Thread 类
class MyThread extends Thread {
@Override
public void run() {
System.out.println("Thread running");
}
}
new MyThread().start();
// 方式二:实现 Runnable 接口
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("Runnable running");
}
}
new Thread(new MyRunnable()).start();
// 方式三:实现 Callable 接口(带返回值)
class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
return "Result";
}
}
FutureTask<String> task = new FutureTask<>(new MyCallable());
new Thread(task).start();
String result = task.get();
// 方式四:线程池(推荐)
ExecutorService executor = Executors.newFixedThreadPool(10);
executor.submit(() -> System.out.println("Pool running"));
executor.shutdown();
四种方式对比:
| 方式 |
优点 |
缺点 |
适用场景 |
| Thread |
简单 |
Java单继承受限 |
简单任务 |
| Runnable |
灵活 |
无返回值 |
通用场景 |
| Callable |
有返回值 |
稍复杂 |
异步计算 |
| 线程池 |
线程复用、便于管控 |
需合理配置参数 |
生产环境 |
1.3 线程的状态
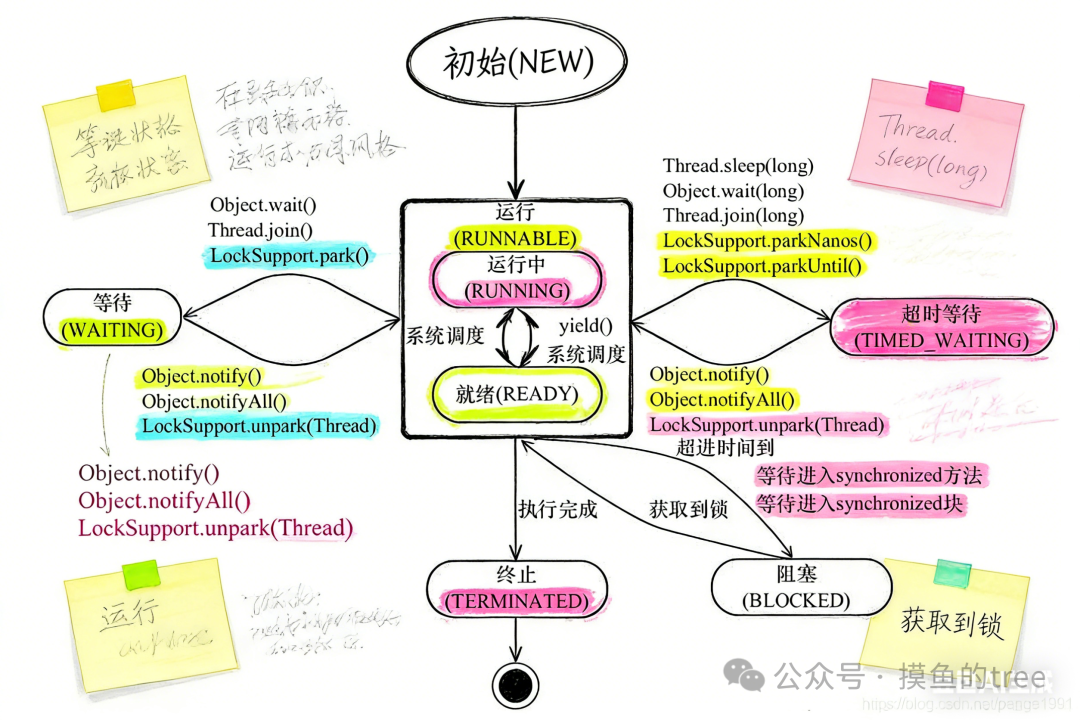
六种状态详解:
| 状态 |
说明 |
触发方式 |
| NEW |
创建,未启动 |
new Thread() |
| RUNNABLE |
可运行 |
start() |
| BLOCKED |
阻塞,等待锁 |
synchronized 争用 |
| WAITING |
无限期等待 |
wait() / join() / LockSupport.park() |
| TIMED_WAITING |
超时等待 |
sleep() / wait(timeout) / join(timeout) |
| TERMINATED |
已终止 |
执行完成 |
1.4 线程操作方法
// 线程等待
thread.join(); // 等待线程执行完成
Thread.sleep(1000); // 休眠(不释放锁)
// 线程停止(不推荐用 stop())
thread.interrupt(); // 中断线程
thread.isInterrupted(); // 检查中断状态
Thread.interrupted(); // 静态方法,检查并清除中断状态
// 线程让步
Thread.yield(); // 让出 CPU 时间片(提示调度器)
// 线程守护
thread.setDaemon(true); // 设置为守护线程
二、synchronized:最熟悉的陌生人
2.1 synchronized 底层原理
synchronized 是 Java 中最常用的同步关键字,很多人知道用,却对底层原理一知半解。
从字节码层面看:
// 编译后会产生 monitorenter 和 monitorexit 指令
public synchronized void method() {
// ...
}
// 字节码:
// monitorenter
// ... 方法内容 ...
// monitorexit
对象头结构(Mark Word):
| 锁状态 |
25位 |
31位 |
1位 |
4位 |
1位 |
2位 |
| 无锁 |
对象哈希码 |
|
|
分代年龄 |
偏向锁位 |
01 |
| 偏向锁 |
线程ID |
Epoch |
|
分代年龄 |
偏向锁位 |
01 |
| 轻量级锁 |
指向栈中锁记录的指针 |
|
|
|
|
00 |
| 重量级锁 |
指向 monitor 的指针 |
|
|
|
|
10 |
| GC标记 |
空 |
|
|
|
|
11 |
2.2 synchronized 锁升级过程
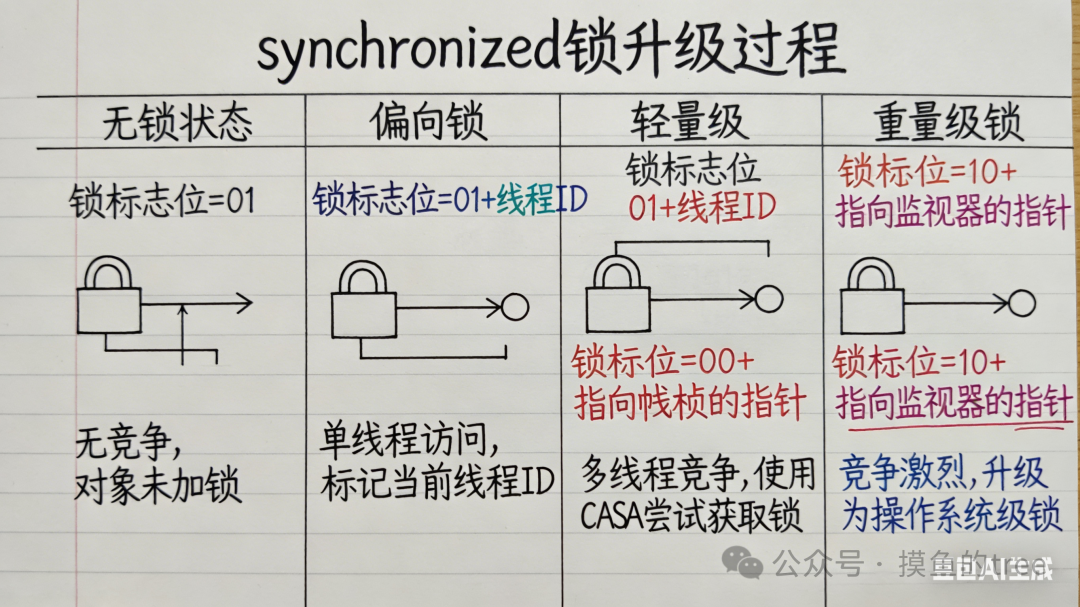
锁升级过程:
- 偏向锁:第一个线程获取锁,Mark Word 记录线程 ID。
- 轻量级锁:多个线程发生竞争,采用自旋方式等待。
- 重量级锁:自旋等待超过一定阈值,升级为操作系统级的重量级锁。
面试必问:为什么 synchronized 要设计成可升级的?
答:核心是为了性能优化。偏向锁在无竞争时开销最小;轻量级锁在少量竞争时,自旋等待比直接线程阻塞更高效;只有在大量、激烈竞争时,才使用开销较大但保证公平性的重量级锁。
2.3 synchronized 的四种用法
// 1. 修饰代码块(指定锁对象)
synchronized(this) {
// 临界区
}
// 2. 修饰实例方法(锁当前对象实例)
public synchronized void method() {
// 临界区
}
// 3. 修饰静态方法(锁类的 Class 对象)
public synchronized static void method() {
// 临界区
}
// 4. 修饰类(指定锁类)
synchronized(MyClass.class) {
// 临界区
}
2.4 synchronized 和 ReentrantLock 的区别
| 对比项 |
synchronized |
ReentrantLock |
| 锁类型 |
隐式锁,JVM 内置 |
显式锁,需要手动管理 |
| 获取/释放 |
自动(进入/退出代码块) |
手动 (lock() / unlock()) |
| 公平锁 |
不支持 |
支持(构造时可指定) |
| 响应中断 |
不支持 |
支持 (lockInterruptibly()) |
| 尝试非阻塞获取 |
不支持 |
支持 (tryLock()) |
| 条件变量 |
无 |
支持多个 Condition |
| 底层实现 |
Monitor(管程) |
AQS(AbstractQueuedSynchronizer) |
// ReentrantLock 示例
ReentrantLock lock = new ReentrantLock();
// tryLock() 尝试获取(非阻塞)
if (lock.tryLock()) {
try {
// 临界区
} finally {
lock.unlock(); // 务必在 finally 中释放
}
}
// 公平锁
ReentrantLock fairLock = new ReentrantLock(true);
// 条件变量
Condition condition = lock.newCondition();
condition.await(); // 等待
condition.signal(); // 通知
三、volatile:最轻量的同步
3.1 volatile 的作用
volatile 是 Java 中最轻量级的同步机制,它保证两个核心特性:
// volatile 保证:
volatile boolean flag = false;
// 1. 可见性:一个线程修改后,新值对其他线程立即可见
// 2. 有序性:禁止指令重排序
可见性演示:
public class VolatileDemo {
// 不带 volatile,程序可能因可见性问题永远不停止
// 带 volatile,保证修改对所有线程可见,程序能正确停止
volatile boolean running = true;
public void stop() {
running = false;
}
public void run() {
while (running) {
// 业务逻辑
}
}
}
3.2 有序性:指令重排
// 指令重排示例
int a = 1; // 1
int b = 2; // 2
int c = a + b; // 3
// 编译器或处理器可能为了优化,将顺序重排为:
int b = 2; // 2
int a = 1; // 1
int c = a + b; // 3
// volatile 变量可以禁止其前后的指令进行重排序
volatile int x = 1;
int y = 2;
// x 的读/写操作不会被重排序到 y 的操作之前或之后
3.3 volatile 和 synchronized 的区别
| 对比项 |
volatile |
synchronized |
| 作用域 |
修饰变量 |
修饰代码块或方法 |
| 原子性 |
不保证(如 i++) |
保证 |
| 可见性 |
保证 |
保证 |
| 有序性 |
保证(禁止重排) |
保证 |
| 性能开销 |
很低(读接近普通变量) |
较高(涉及锁升级) |
面试必问:volatile 为什么不保证原子性?
答:volatile 只保证单次读/写操作的原子性和可见性、有序性。但像 i++ 这样的复合操作(读取、加1、写入),在多线程下,可能发生线程 A 读取后,线程 B 也读取了旧值,然后各自加1写回,导致最终结果只增加了1。要保证原子性,需要使用 synchronized 或 AtomicInteger。
四、ThreadLocal:线程本地变量
4.1 ThreadLocal 是什么
ThreadLocal 为每个线程提供独立的变量副本,实现了线程间的数据隔离。
// ThreadLocal 示例
public class ThreadLocalDemo {
private static ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
public static void main(String[] args) {
// 线程1
new Thread(() -> {
threadLocal.set(1);
System.out.println(Thread.currentThread().getName() + ": " + threadLocal.get());
}, "T1").start();
// 线程2
new Thread(() -> {
threadLocal.set(2);
System.out.println(Thread.currentThread().getName() + ": " + threadLocal.get());
}, "T2").start();
}
}
// 输出:
// T1: 1
// T2: 2
4.2 ThreadLocal 原理
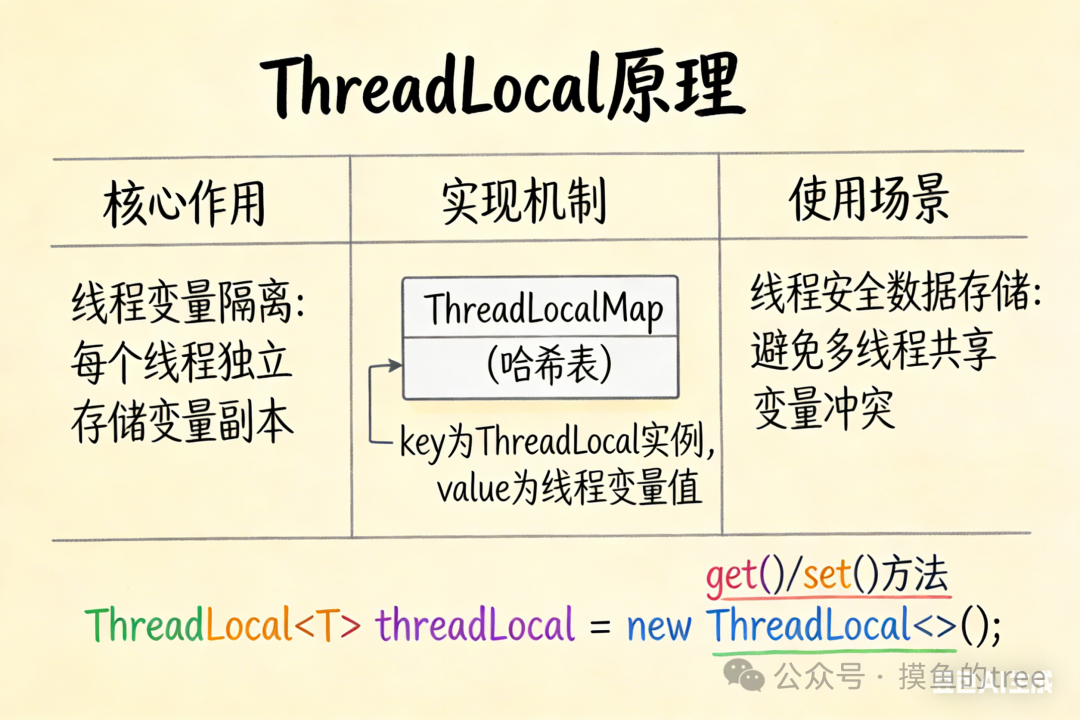
4.3 内存泄漏问题
// ThreadLocal 内存泄漏原因:
// ThreadLocalMap 的 Entry 继承自 WeakReference<ThreadLocal<?>>
// key(ThreadLocal 实例)是弱引用,value(存储的值)是强引用
// 解决方案:使用完毕后手动 remove
try {
threadLocal.set(value);
// 执行业务逻辑
} finally {
threadLocal.remove(); // 非常重要!
}
面试加分项:为什么 Entry 的 key 要设计成弱引用?
答:如果 key 使用强引用,那么即使外部不再持有 ThreadLocal 对象的引用(threadLocal = null),由于 ThreadLocalMap 的 Entry 仍持有强引用,ThreadLocal 对象也无法被回收,导致内存泄漏。设计成弱引用后,在 GC 时,ThreadLocal 对象可以被回收,key 会变为 null。但 value 仍然是强引用,如果线程长期运行(如线程池场景),value 无法被访问也无法回收,依然会造成内存泄漏。因此,最佳实践是必须手动调用 remove()。
五、线程池:并发编程的核心
5.1 为什么要用线程池
| 对比项 |
传统方式(每次 new Thread) |
线程池 |
| 创建开销 |
大(约 1-2 MB) |
小(线程复用) |
| 响应速度 |
慢(需创建线程) |
快(有现成线程) |
| 资源管理 |
无,容易 OOM |
可控制最大并发数 |
| 线程数量 |
不可控 |
可控,避免资源耗尽 |
5.2 线程池的七大参数
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 空闲线程存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 阻塞队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
) {
// ...
}
5.3 线程池的执行流程

5.4 四种常见线程池
| 线程池 |
特点 |
适用场景 |
| FixedThreadPool |
固定线程数,无界队列 |
任务量稳定、可控 |
| CachedThreadPool |
线程数弹性,使用 SynchronousQueue |
短时、异步、小任务 |
| SingleThreadExecutor |
单线程,任务队列 |
任务需串行执行 |
| ScheduledThreadPool |
定时/周期性执行 |
延迟任务、定期任务 |
// 阿里巴巴开发规范:禁止使用 Executors 快捷创建线程池
// 应使用 ThreadPoolExecutor 明确参数,避免资源耗尽风险
// 正确写法
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, // corePoolSize
10, // maximumPoolSize
60L, // keepAliveTime
TimeUnit.SECONDS, // unit
new LinkedBlockingQueue<>(100), // workQueue
new ThreadPoolExecutor.CallerRunsPolicy() // handler
);
5.5 线程数设置
// CPU 密集型(计算任务多):线程数 ≈ CPU 核心数 + 1
int cpuCores = Runtime.getRuntime().availableProcessors();
int poolSize = cpuCores + 1;
// IO 密集型(数据库、网络操作多):线程数 ≈ CPU 核心数 * 2
// 更精确公式:线程数 = CPU核心数 * (1 + (IO耗时 / CPU耗时))
六、并发容器:安全的数据结构
6.1 ConcurrentHashMap
// JDK 8 之前:分段锁(Segment)
// JDK 8 之后:数组 + 链表/红黑树 + CAS + synchronized(锁粒度更细)
// 常用操作
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
map.put("key", 1); // 原子 put
map.get("key"); // 高效 get(无锁)
map.computeIfAbsent("key", k -> 1); // 原子计算,不存在则添加
map.putIfAbsent("key", 1); // 原子插入(不存在才放)
6.2 常用并发容器
| 容器 |
特点 |
适用场景 |
| ConcurrentHashMap |
高并发哈希表 |
缓存、计数器 |
| ConcurrentLinkedQueue |
非阻塞无界队列 |
高性能生产者-消费者 |
| CopyOnWriteArrayList |
写时复制,读快写慢 |
读多写少(监听器列表、配置) |
| BlockingQueue |
阻塞队列 |
经典生产者-消费者模型 |
| ConcurrentSkipListMap |
并发有序映射 |
需要排序的缓存 |
// BlockingQueue 示例(生产者-消费者)
BlockingQueue<String> queue = new LinkedBlockingQueue<>(10);
// 生产者
for (int i = 0; i < 20; i++) {
final int taskId = i;
new Thread(() -> {
try {
queue.put("task-" + taskId); // 队列满则阻塞
System.out.println("生产: task-" + taskId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}).start();
}
// 消费者
for (int i = 0; i < 5; i++) {
new Thread(() -> {
try {
String task = queue.take(); // 队列空则阻塞
System.out.println("消费: " + task);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}).start();
}
七、JUC(java.util.concurrent)工具类
7.1 CountDownLatch
// 倒数计数器:等待多个线程完成
CountDownLatch latch = new CountDownLatch(3);
// 3 个工作线程
for (int i = 0; i < 3; i++) {
final int id = i;
new Thread(() -> {
try {
Thread.sleep(1000 * (id + 1));
System.out.println("线程" + id + "完成");
latch.countDown(); // 计数减1
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}).start();
}
// 主线程等待所有工作线程完成
latch.await(); // 阻塞,直到计数变为 0
System.out.println("所有线程完成,主线程继续");
7.2 CyclicBarrier
// 循环栅栏:让多个线程在某个点相互等待,再一起继续
CyclicBarrier barrier = new CyclicBarrier(3, () -> {
System.out.println("所有线程到达栅栏,执行回调"); // 全部到达后执行
});
// 3 个线程
for (int i = 0; i < 3; i++) {
final int id = i;
new Thread(() -> {
try {
System.out.println("线程" + id + "到达栅栏1");
barrier.await(); // 等待其他线程
System.out.println("线程" + id + "继续执行");
barrier.await(); // 可以复用,进行下一轮等待
} catch (InterruptedException | BrokenBarrierException e) {
Thread.currentThread().interrupt();
}
}).start();
}
7.3 Semaphore
// 信号量:控制并发访问的线程数量(限流)
Semaphore semaphore = new Semaphore(3); // 最多允许 3 个线程并发
// 10 个任务
for (int i = 0; i < 10; i++) {
final int id = i;
new Thread(() -> {
try {
semaphore.acquire(); // 获取许可,没有则阻塞
System.out.println("线程" + id + "获得许可,开始执行");
Thread.sleep(1000);
System.out.println("线程" + id + "执行完成,释放许可");
semaphore.release(); // 释放许可
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}).start();
}
八、面试高频问题汇总
Q1:synchronized 和 ReentrantLock 的区别?
(答案详见上文 2.4 表格)
Q2:volatile 和 synchronized 的区别?
(答案详见上文 3.3 表格)
Q3:线程池的执行流程?
- 提交任务。
- 判断核心线程池是否已满?未满 → 创建核心线程执行任务。
- 核心线程池已满 → 任务进入阻塞队列等待。
- 队列已满 → 判断最大线程池(非核心线程)是否已满?未满 → 创建临时线程执行任务。
- 最大线程池也已满 → 执行拒绝策略。
Q4:CountDownLatch 和 CyclicBarrier 的区别?
| 对比项 |
CountDownLatch |
CyclicBarrier |
| 主要用途 |
等待一个或多个事件完成 |
等待多个线程到达集合点 |
| 计数 |
单向减少(countDown()),不可重置 |
可循环使用(await()后重置) |
| 线程关系 |
发射后不管,不关心谁完成 |
线程之间相互等待 |
| 结束方式 |
由外部线程调用 countDown() |
由参与线程自身调用 await() |
Q5:ThreadLocal 内存泄漏原因及如何解决?
原因:ThreadLocalMap 的 Entry 中,key(ThreadLocal 对象)是弱引用,value(存储的值)是强引用。当 ThreadLocal 外部引用被置 null 后,GC 会回收 key,但 value 由于仍被 Entry 强引用而无法回收,且 key=null 的 Entry 无法被访问,导致内存泄漏。
解决:务必在使用完毕后调用 threadLocal.remove()。
Q6:如何保证线程安全?
这是一道综合性问题,可以分层回答:
- 互斥同步:
synchronized(JVM 级别)、ReentrantLock(JDK 级别)。
- 非阻塞同步:
Atomic 原子类(CAS 操作)。
- 线程本地存储:
ThreadLocal,避免共享。
- 使用线程安全容器:
ConcurrentHashMap、CopyOnWriteArrayList 等。
- 不可变对象:使用
final 修饰字段,创建后状态不可变。
Q7:线程池参数(核心线程数)怎么设置?
- CPU 密集型:
核心线程数 ≈ CPU 核心数 + 1。
- IO 密集型:
核心线程数 ≈ CPU 核心数 * 2。更精确的公式是:核心线程数 = CPU核心数 * (1 + (IO耗时 / CPU耗时))。
- 在实际高并发系统中,这只是一个起点,必须配合压力测试来最终确定。
Q8:简述 synchronized 锁升级过程?
无锁 → 偏向锁 → 轻量级锁 → 重量级锁
- 偏向锁:假设只有一个线程访问,Mark Word 记录线程 ID,降低无竞争时的开销。
- 轻量级锁:发生轻度竞争,线程通过 CAS 自旋尝试获取锁,避免直接阻塞。
- 重量级锁:竞争激烈或自旋超时,升级为操作系统互斥量(mutex),线程进入阻塞队列。
九、总结
并发编程的核心可以归结为三点:同步、线程安全、性能。
- 同步:解决竞态条件,核心是
synchronized、Lock 和 volatile。
- 线程安全:保证数据一致性,手段包括原子类、并发容器和
ThreadLocal。
- 性能:合理利用资源,核心是线程池和各类
JUC 工具类。
希望通过本文的梳理,能帮助你构建起Java并发编程的知识体系。从理解原理到应对面试,再到实际应用,每个环节都至关重要。扎实的基础是解决复杂高并发问题的前提。
如果你想与更多同行交流这些技术细节,或者获取更多实战案例,欢迎来到 云栈社区 ,这里聚集了众多乐于分享和讨论的开发者。
 发表于 2026-3-8 02:10:53
|
查看: 133|
回复: 0
发表于 2026-3-8 02:10:53
|
查看: 133|
回复: 0
