看着铺天盖地的AI新闻,你是否感觉一头雾水?神经网络、大语言模型、RAG、幻觉……这些术语听起来高深莫测,让人望而却步。别担心,本文旨在用最通俗的语言,为你拆解人工智能领域的20个核心概念。每个术语都包含“术语解释”和“大白话”比喻两部分,力求让零基础的朋友也能轻松入门,理解AI究竟在做什么。
一、基础概念类
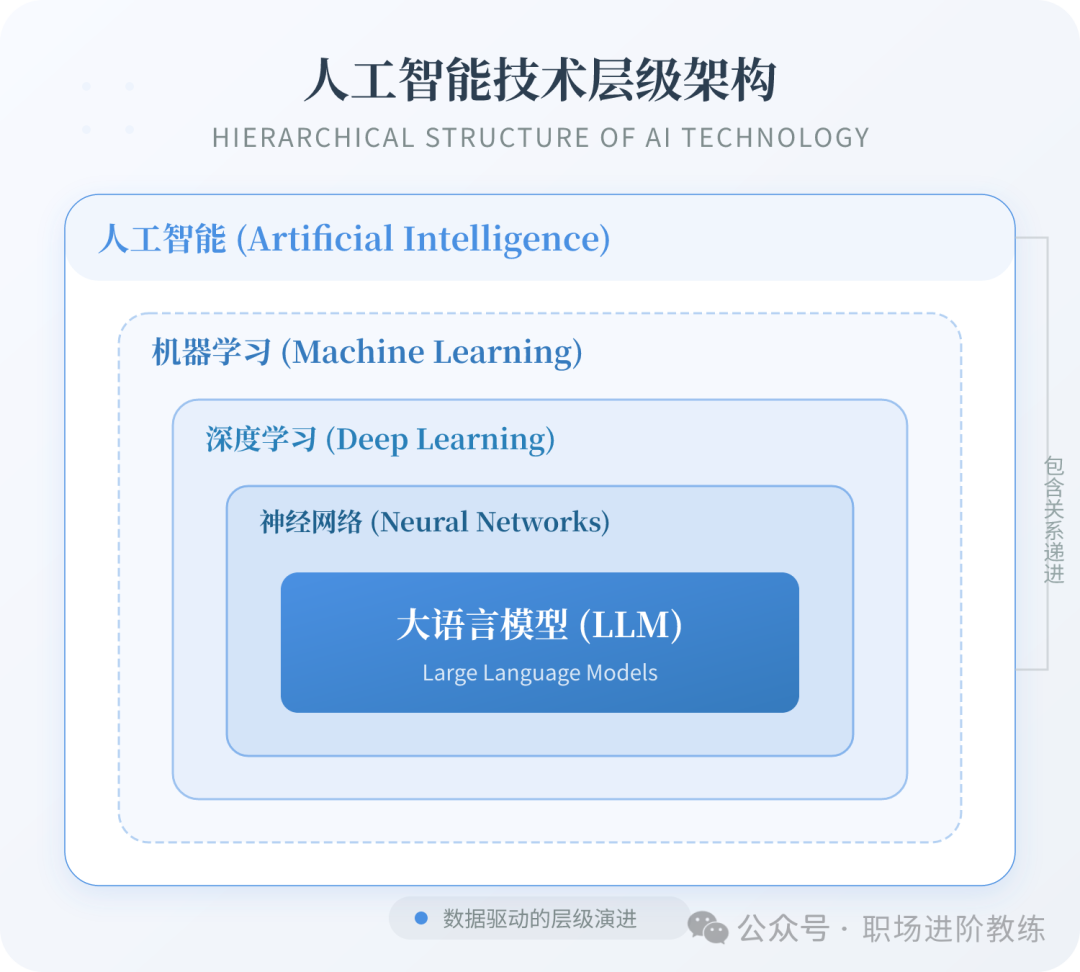
人工智能 (AI)
- 术语解释:让机器模拟人类智能的理论、方法和技术。
- 大白话:“让机器像人一样思考”。就像给电脑装上一个“大脑”,让它能看、能听、能说话、能决策,而不是只会按固定步骤算算术。它是所有相关技术的顶层概念。
机器学习 (ML)
- 术语解释:让计算机不用明确编程就能学习的方法,通过数据训练来提升性能。
- 大白话:“教电脑自己找规律”。不像传统编程那样一步步告诉电脑怎么做,而是给它一堆例子(数据),让它自己总结规律。就像教小孩认识猫,不用描述猫的特征,给他看100张猫图,他就学会了。这是实现人工智能的一种核心路径。
深度学习
- 术语解释:基于多层神经网络(模拟人脑神经元)的机器学习方法。
- 大白话:“模仿人脑的深度思考”。就像人脑有无数神经元层层连接,深度学习也搭建了很多层“人工神经元”,一层层提取特征。比如认脸:第一层认轮廓,第二层认眼睛,第三层认整张脸,层层递进。它是当前最强大的机器学习技术之一。
神经网络
- 术语解释:由大量人工神经元相互连接组成的计算模型,模仿人脑结构。
- 大白话:“用电脑搭的简易人脑网”。就像一张大网,每个节点(神经元)收到信号后处理一下,再传给下一个。通过调整节点间的连接强度(权重),让网络学会处理信息。它是深度学习的基石。
大语言模型 (LLM)
- 术语解释:在海量文本数据上训练的超大神经网络,能理解和生成自然语言。
- 大白话:“读过全网书的超级学霸”。比如ChatGPT,它把互联网上的海量文字(书籍、网页、论文)都“读”了一遍,学会了人类语言的规律,所以能跟你聊天、写文章、编代码。它是目前最耀眼的AI应用之一。
二、模型与训练类
模型
- 术语解释:算法在数据上训练后得到的、能对新数据做出预测的“知识库”。
- 大白话:“训练好的大脑”。就像学生经过多年学习形成的知识体系。AI模型就是经过大量数据训练后,形成的那个能用来识别猫、翻译语言或写文章的“知识包”。
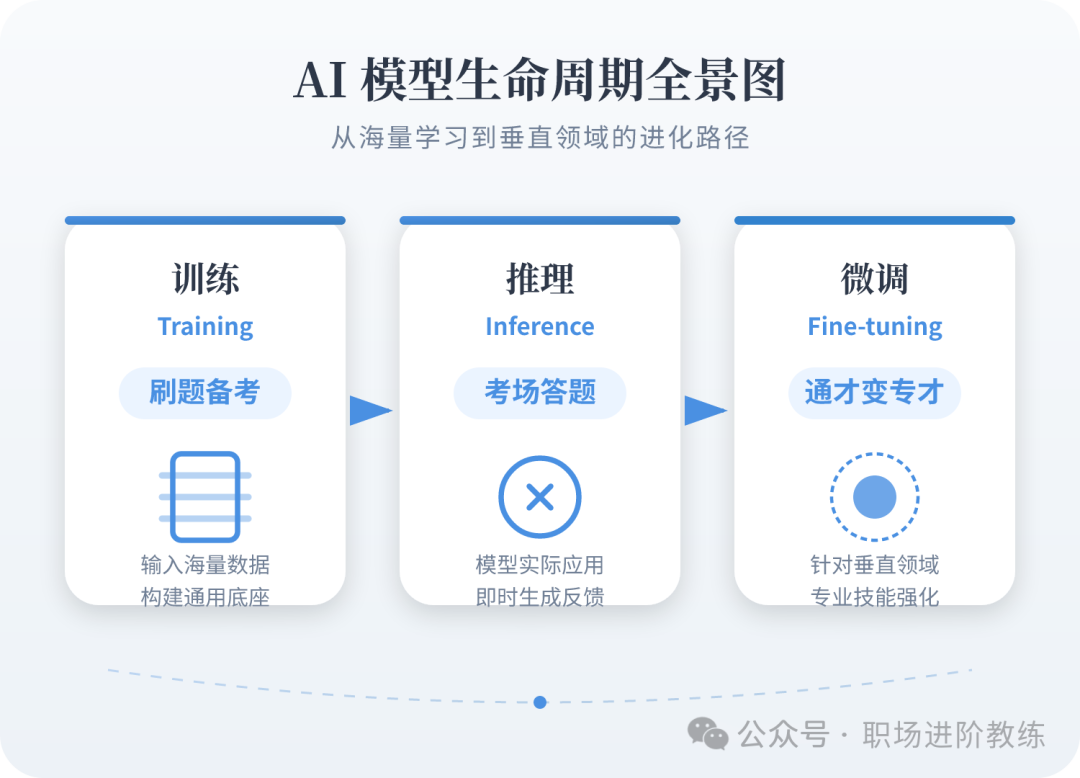
训练
- 术语解释:用数据让模型学习的过程,不断调整参数使预测更准。
- 大白话:“刷题备考”。就像学生做习题集(训练数据),做完对答案,错了就改正(调整参数),反复练习直到考试能考高分(预测准确)。
推理
- 术语解释:用训练好的模型对新数据做预测的过程。
- 大白话:“上考场答题”。模型已经训练好了(学成了),现在给模型一张没见过的猫图,它根据学过的知识判断“这是猫”,这就是推理。
微调
- 术语解释:在预训练模型(如通用大模型)的基础上,用少量特定领域数据继续训练,使其适应特定任务。
- 大白话:“通才变专才”。一个模型本来啥都会一点(通才),你想让它变成法律专家,就给它看点法律案例(少量专业数据),它就能更懂法律术语和逻辑了。省钱省力,不用从头学起。
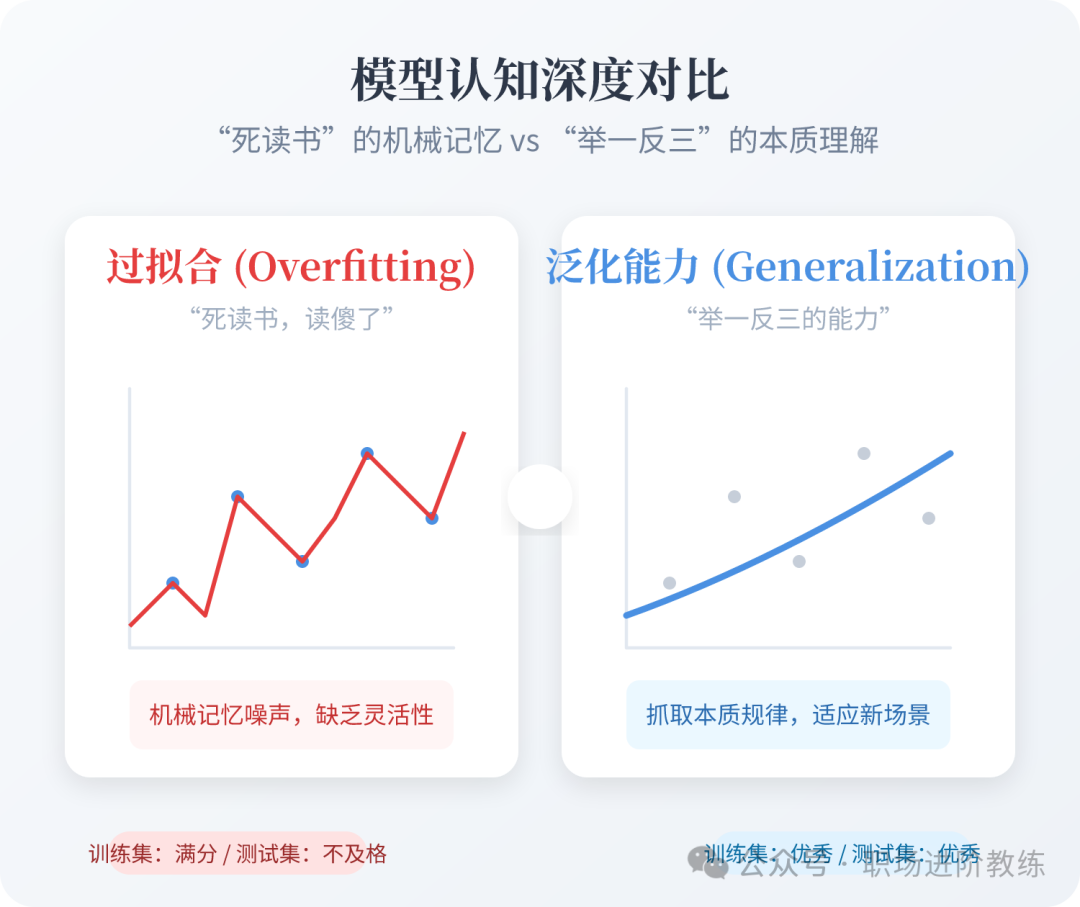
过拟合
- 术语解释:模型在训练数据上表现太好,但在新数据上表现差,即“死记硬背”没理解规律。
- 大白话:“死读书读傻了”。学生把习题答案全背下来了,考试遇到一模一样的题得满分,但题目稍微变一下(新数据)就不会了,因为他没真正理解原理。
泛化能力
- 术语解释:模型对未见过的数据的适应能力和预测准确性。
- 大白话:“举一反三的能力”。真正的好学生,不光会做练习册上的题,考试时题目变个花样也能做对。泛化能力强就是模型能适应新情况,而不是只会背答案。
三、数据与评估类
训练集 / 验证集 / 测试集
- 术语解释:数据被分成的三部分,分别用于训练、调参和最终评估。
- 大白话:“教材/模拟考/高考”。
- 训练集(教材):学生学习用的课本知识。
- 验证集(模拟考):平时小测验,用来调整学习方法(调参数)。
- 测试集(高考):最终考试,之前完全没见过,用来评判真实水平。

标注数据
- 术语解释:已经人工打上标签(正确答案)的数据,用于监督学习。
- 大白话:“带答案的例题”。比如教AI认猫,你先给一张图,然后在旁边写上“猫”。这张带标签的图就是标注数据。标注越准,AI学得越好。
特征
- 术语解释:数据中用于模型学习的可测量属性或特性。
- 大白话:“事物的特征点”。比如判断一个水果是不是苹果,特征包括:颜色(红/绿)、形状(圆的)、大小、有没有把儿。这些特征就是AI做判断的依据。
准确率 / 召回率
- 术语解释:评估模型性能的指标。准确率是预测对的占总预测的比例;召回率是实际为正例的被找出来的比例。
- 大白话:“准不准”和“全不全”。比如从100个视频里找出所有猫的视频。
- 准确率:找出来的视频里,真的是猫的有多少?(别找太多狗冒充猫)
- 召回率:真正的猫视频里,被你找出来多少?(别漏掉太多猫)
四、算法与架构类
监督学习 / 无监督学习 / 强化学习
- 术语解释:三种主要的学习范式。
- 大白话:
- 监督学习:“有标准答案的题海战术”。给AI一堆“题目+答案”(标注数据),让它学会做题。
- 无监督学习:“自己找规律分类”。不给答案,只给一堆照片,AI自己发现有些是猫,有些是狗,自动分成两类。
- 强化学习:“训狗/玩游戏”。做对了给奖励(肉干),做错了给惩罚(不睬它),AI为了拿到最多奖励,自己摸索出最佳策略。
Transformer
- 术语解释:一种基于自注意力机制的神经网络架构,是现代大语言模型的基础。
- 大白话:“超级注意力模型”。读一句话时,它能同时关注到所有词之间的关系,而不是像以前那样一个词一个词顺着读。所以它理解上下文特别强,这也是ChatGPT能听懂你话的底层技术。

RAG(检索增强生成)
- 术语解释:结合信息检索和文本生成的技术,让模型在生成答案前先检索相关知识。
- 大白话:“开卷考试+查资料”。以前大模型是闭卷考试(全靠记忆),容易胡说八道(幻觉)。RAG让它可以先翻书(检索数据库),找到相关资料,再结合资料回答问题,答案更准、更新。
提示工程
- 术语解释:设计、优化输入给AI的提示词,以获得更好输出的技术。
- 大白话:“学会跟AI好好说话”。同样问AI,有人问“写个方案”,AI给得敷衍;有人会问“你是一位资深营销专家,请为新产品写一份针对年轻用户的推广方案,要求2000字,包含预算分配”。后者就是提示工程——问得越具体、角色越明确,答案通常越好。
幻觉
- 术语解释:AI生成的内容中,出现与事实不符或凭空捏造的部分。
- 大白话:“一本正经地胡说八道”。AI模型有时候为了回答得流畅、完整,会自己编造一些事实,比如问它某个历史事件,它可能把时间地点人物都说得有鼻子有眼,但其实是错的。因为它更在意“像人说话”的流畅性和合理性,而不是“说对的话”。
希望这份“术语翻译”能帮你拨开AI世界的第一层迷雾。理解这些基础概念是深入探索人工智能浩瀚领域的第一步。如果你对某个方向特别感兴趣,想深入了解其背后的技术细节或最新应用,欢迎到 云栈社区 的相关板块浏览和讨论,那里有更多志同道合的开发者和技术文章。 |  发表于 2026-3-8 03:50:28
|
查看: 189|
回复: 0
发表于 2026-3-8 03:50:28
|
查看: 189|
回复: 0
