
2011年,一项关于“第六感”的研究在心理学界掀起波澜,似乎为超感官知觉提供了统计证据。然而,当其他研究者试图复现实验时,却纷纷宣告失败。这个故事并非个例,它直指当代科研领域一个令人不安的核心问题:为何许多看似严谨、具备统计显著性的科学结论,最终却被证明难以重复,甚至可能是错误的?
本文将探讨统计数据从产生到抵达公众视野的全链条中,错误是如何被引入、放大并最终被接受的。我们不仅需要警惕明目张胆的数据造假,更要关注那些看似合规、实则扭曲统计意义的“可疑学术行为”。在信息爆炸的时代,掌握正确的统计学思维,是识破数字幻象、做出理性判断的关键。
第六感真的存在吗?
美国社会心理学家达里尔·贝姆在2011年发表了一项引起轰动的实验。实验中,学生需要猜测电脑屏幕上两块“窗帘”的哪一块后面藏有图像,而图像出现的位置是完全随机的。零假设是“不存在第六感”,所以猜对的预期概率是50%。
令人惊讶的是,当窗帘后的图像是色情内容时,受试者的正确率达到了53%,其P值为0.01。该论文还汇总了另外8项类似研究,总计超过1000名受试者,其中8项都取得了统计显著的结果。
难道第六感真的存在?我们稍后再来拆解这个案例。它提醒我们,现实中的统计研究远非总是理想和完美的。现在,让我们先看看当统计学被滥用时,会发生什么。
可重复性危机
早在2005年,学者约翰·约安尼季斯就提出了一个惊世骇俗的观点:大多数已发表的研究结论都是错的。这种现象最初在医学和生物学领域凸显,后来蔓延到心理学及其他社会科学,被称为“可重复性危机”。
一个名为“可重复性计划”的大型合作项目,尝试用更大样本复现了100项心理学研究。结果发现,虽然有97%的原始研究取得了统计显著结果,但其中只有36%能在重复实验中得到复现。
媒体常将此解读为63%的显著结论为假,但这本身又陷入了“唯P值是瞻”的陷阱。统计学家安德鲁·格尔曼指出,更准确地说,只有23%的原始实验与重复实验之间的差异本身具有统计显著性。
与其执着于“是否显著”,不如关注效应大小。可重复性计划发现,重复实验得到的效应方向虽然与原始实验一致,但其大小平均只有原始实验的一半。这暴露了科学出版中的一个系统性偏差:效应越大(哪怕部分源于偶然运气)的研究,越容易登上顶级期刊。这类似于“均值回归”,可称为“零假设回归”——被夸大的初始效应会向零值回落。
可重复性危机的根源复杂,与研究者必须发表“显著成果”的生存压力密切相关。即使实验设计完美,统计学原理也决定了会有一部分显著结果是假阳性。问题在于,现实中的大多数研究远非完美。
从问题到结论:处处是陷阱
一个完整的统计研究周期(PPDAC:提出问题、规划、数据收集、分析、结论)的每个环节都可能出错。
- 提出问题:可能设定了无法用现有数据回答的问题,例如“为何过去十年英国少女怀孕率大幅下降?”
- 做出规划:
- 选择方便样本而非代表性样本(如电话民调)。
- 使用引导性问题。
- 缺乏恰当的对照组。
- 样本量太小,检验效能不足。
- 未考虑干扰因素,未实施盲法试验。
正如统计学家费希尔的名言:“实验完成后再咨询统计学家,如同病人死后才进行尸检。我们最多只能告诉你实验是怎么死的。”
- 收集数据:低回复率、参与者中途退出、招募缓慢等都是常见问题。
- 分析数据:此阶段错误后果可能极其严重。
- 2010年,一篇影响经济紧缩政策讨论的经济学论文,因电子表格遗漏五个国家的数据而导致结论偏差。
- 一家投资公司的程序员敲错代码,导致风险模型严重低估风险,最终给客户造成2.17亿美元损失,公司被罚总计2.42亿美元。
- 即使计算无误,模型本身也可能出错,例如错误分析“整群随机试验”数据,或误将“交互作用”解释为组间差异。
- 得出结论:最明目张胆的做法是进行多次检验,只报告最显著的那次结果。这如同电视台只转播一支球队的进球,必然扭曲事实。美国制药公司InterMune的前CEO就因选择性报告药物对某患者亚组的“显著”疗效(而整体疗效不显),而被判电信诈骗罪。
蓄意欺诈与“巧克力减肥”骗局
故意伪造数据的情况相对少见。一项调查显示,约2%的科学家承认曾伪造数据。统计学家甚至能用统计方法侦测作假,例如发现不同组的标准差数字离奇地完全一致。
但更普遍、也更棘手的问题,并非赤裸裸的造假,而是游走在灰色地带的“可疑学术行为”。
“可疑学术行为”:P值操纵与研究者自由度
即便数据真实、分析无误,如果我们不清楚研究者得出结论的具体过程,也无法正确理解结果。研究人员可能会根据数据的初步反馈,无意识或有意识地调整诸多细节:何时停止收集数据、排除哪些异常值、选择哪些变量进行分层分析等等。统计学家尤里·西蒙松称之为“研究者自由度”,安德鲁·格尔曼则诗意地称为“小径分岔的花园”。
这些调整都会增加获得“显著”P值的机会。因此,区分探索性研究(灵活探索,提出假设)和验证性研究(严格按预设方案检验假设)至关重要。在验证性研究中滥用探索性研究的灵活性,就是“P值操纵”。
一个经典案例是“听披头士能让人变年轻”的实验。研究者通过不断招募新受试者、尝试各种分析技巧(如按父亲年龄分层),直到在第34名受试者后,在《当我64岁时》和另一首歌的对比中得到了P<0.05的“显著”结果。他们随后坦白,这是 “根据结果构建假设” 的演示。
2012年一项对心理学家的调查显示,虽然仅2%的人承认伪造数据,但:
- 35%的人曾将预先想到的结果报告为“意外发现”。
- 58%的人曾边收集数据边检验,一看到显著结果就停止收集。
- 67%的人未报告全部研究结果。
- 94%的人承认至少有过一项可疑学术行为。
问题的症结在于探索性与验证性研究的边界模糊。这些行为在探索中或许可以接受,但在验证中必须禁止。
科学结论的传播链:误解与夸大
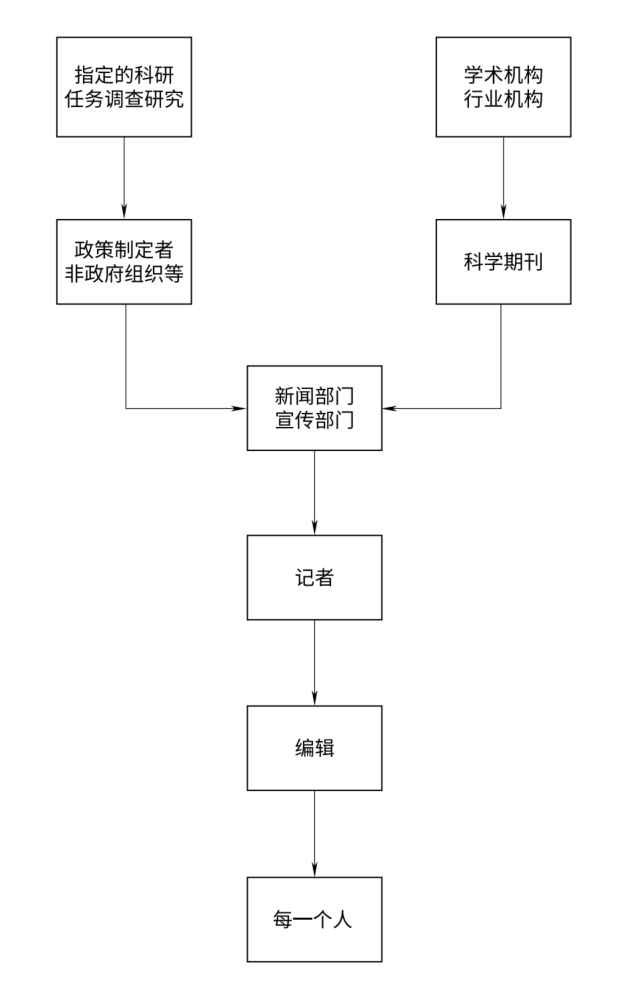
统计数据及结论从源头流向个人的流程。每一阶段都可能因各种原因导致信息被过滤或扭曲。
从论文发表到新闻头条,科学结论的可靠性在传播链的每一步都可能遭到破坏。
- 科学论文的问题:许多“阴性”或“不新奇”的研究根本无法发表(“文件抽屉问题”)。制药公司可能隐瞒不利结果。期刊偏好新奇结论,促使研究者夸大显著性。
- 新闻机构的问题:大学或机构的新闻稿本身就可能夸大因果关系或建议(一项研究发现约40%的新闻稿存在此问题),媒体在此基础上进一步加工。
- 媒体报道的问题:决定标题的通常是追求点击量的编辑,而非撰稿人。媒体最常做的不是颠倒黑白,而是对事实进行“可疑解读”和夸大。常见手段包括:
- 隐去结论的不确定性。
- 将相关性报道为因果关系。
- 夸大结果的重要性。
- 使用吸引眼球的相对风险,而非更能反映实际的绝对风险。
例如,一篇题为《沉迷电视节目会害死你》的报道称,长时间看电视患致命肺栓塞的风险是正常情况的2.5倍(相对风险)。但高危人群的绝对发病率极低,相当于要连续看12000年电视才可能遭遇此风险。这种报道方式无疑放大了公众的焦虑。
回到“第六感”
现在我们可以理解达里尔·贝姆的“第六感”结论是如何产生的了。他公开承认,如果实验不顺利,会“立即修改一些细节,然后重新开始”。他进行了9项实验,每项的分析方法都不同,并选择性地报告了有利结果(如色情图片实验的阳性结果),忽略了不利结果。
安德鲁·格尔曼尖锐地指出:贝姆的P值计算基于“假设不成立的情况下,出现当前数据的概率”,但他并未说明,假设不成立时,他是否会采用同样的分析流程。
颇具讽刺意味的是,贝姆这项有争议的研究,反而极大地推动了整个科学界对研究可重复性、算法严谨性和“研究者自由度”危害的深刻反思。他的案例成为了一个警示:在追求科学发现的道路上,统计工具既能揭示真理,也能在不当使用时,构筑海市蜃楼。
面对纷繁复杂的科学报道和数据结论,作为读者和思考者,我们需要保持审慎。理解计算机科学中的逻辑与统计学中的不确定性,培养批判性思维,是穿透信息迷雾、接近事实真相的必要素养。欢迎在云栈社区与更多开发者一起,探讨技术背后的逻辑与思想。
 发表于 2026-3-9 03:49:37
|
查看: 130|
回复: 0
发表于 2026-3-9 03:49:37
|
查看: 130|
回复: 0
