你是否也曾好奇,自己的电脑配置究竟能流畅运行哪些 AI大模型?手动查询硬件要求、比对模型参数不仅繁琐,还容易出错。现在,有了 llmfit 这款开源工具,一键就能快速检测你的硬件,并从海量模型中筛选出最适合你电脑的那一个。
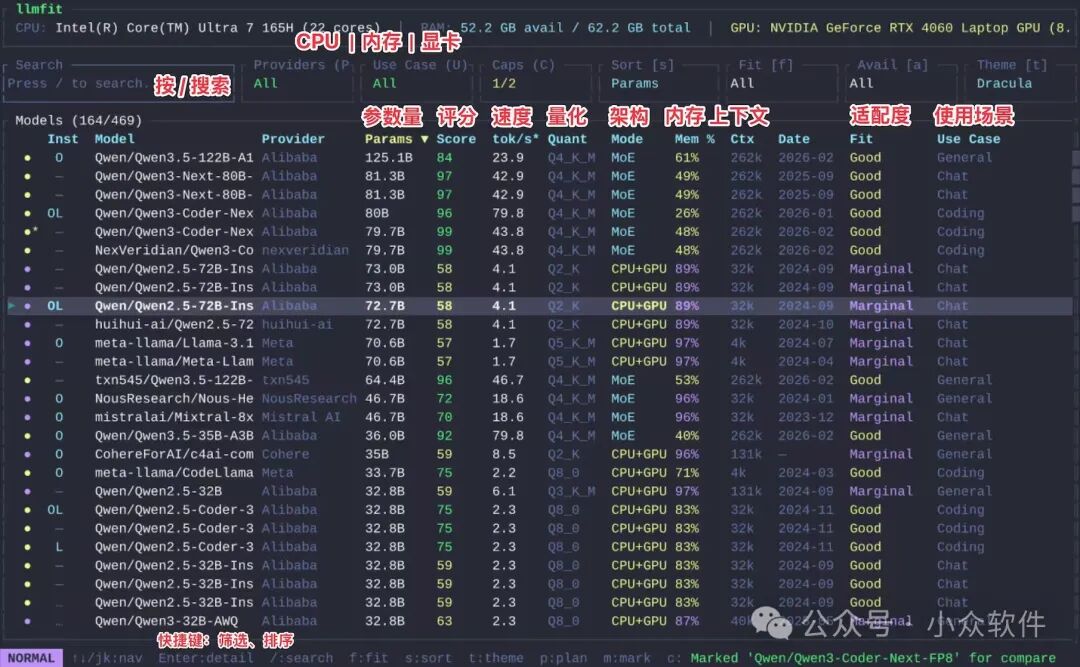
llmfit 是一款支持 Windows、macOS、Linux 系统的 TUI(终端用户界面)程序。它启动后会先自动检测你的 CPU、GPU 和内存配置,然后从一个包含超过 500 个模型的数据库中,快速计算出哪些模型可以在你的硬件上运行,并以清晰的列表展示:
- 模型综合评分
- 推理速度(tok/s)
- 预估内存占用百分比
- 上下文长度
- 模型主要用途(聊天、编码、通用等)
整个过程几乎是“秒出结果”,界面直观明了。
如何使用 llmfit 筛选模型
面对近 500 个模型,如何快速找到自己需要的?llmfit 提供了强大的筛选和排序功能。
例如,如果你只想看某个特定提供商(如阿里巴巴的 Qwen 系列)的模型,可以按下大写字母 P 键,打开提供商筛选面板。然后按 a 取消全选,再通过上下方向键和空格键选中“Alibaba”,即可快速筛选。
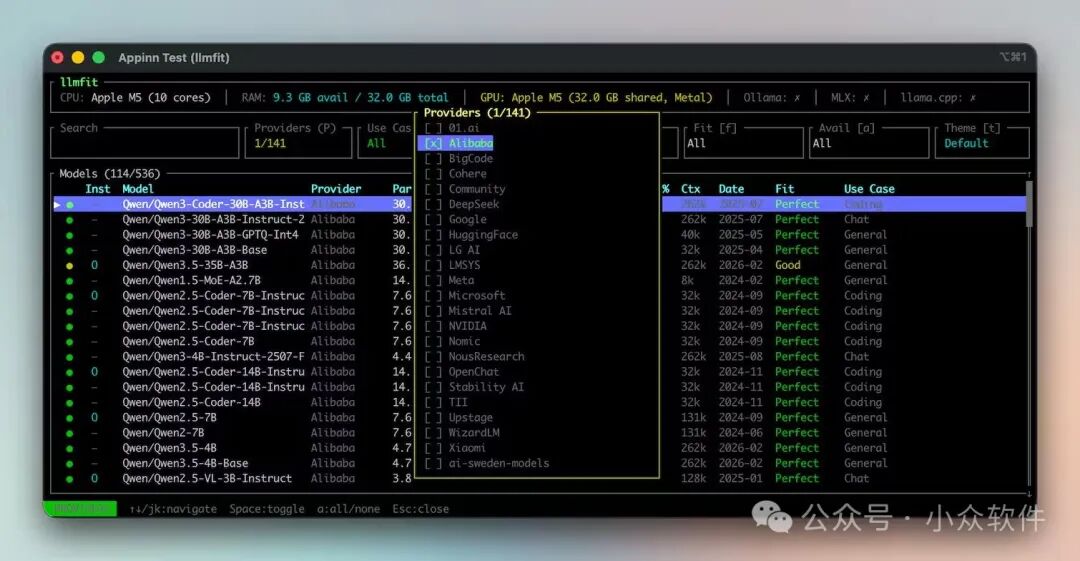
筛选后,你可以根据列表中的关键信息做进一步选择:
- Ctx:上下文长度,越长越好,但通常占用更多资源。
- Score:模型的综合评分,是重要的参考指标。
- Use Case:模型用途,如聊天(Chat)、编码(Coding)或通用(General)。
当你对某个模型感兴趣时,只需用方向键选中它,然后按下回车键,即可查看该模型的详细报告。
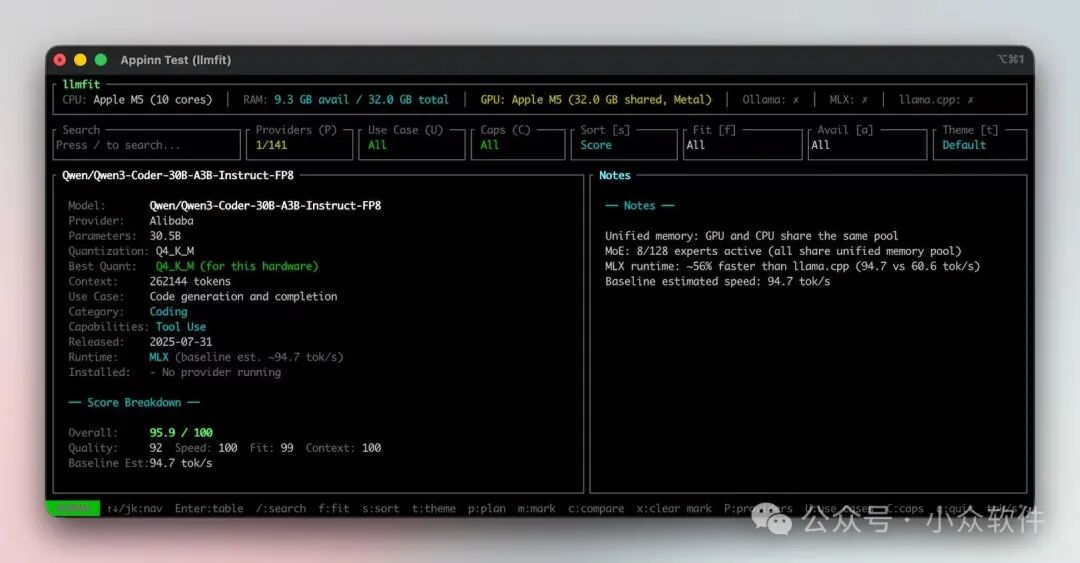
报告中会详细列出模型的参数量、量化方式、预估运行速度、内存占用分析以及评分细则。你甚至可以在这里直接找到模型在 HuggingFace 等平台上的官方地址,方便后续下载和使用。
获取 llmfit
为何要考虑本地部署大模型?
除了硬件兼容性,选择本地运行 AI大模型 还有几个不可忽视的核心优势:
1. 隐私安全
这是最核心的优势。你必须清楚,任何输入到云端大模型的数据,从技术上讲,服务提供商都有能力访问。即使对方承诺“数据不用于训练”或“不记录”,也无法从技术根子上杜绝被查看的可能。因此,涉及公司内部资料、核心代码、机密文档或个人敏感信息时,本地模型是唯一可靠的选择。
2. 可控的成本
云端大模型通常按 Token 或调用次数计费。对于高频使用者,尤其是使用能调用工具、执行复杂任务的 Agent(如 OpenClaw)时,费用可能快速累积。而本地模型只需一次性下载,后续的长期运行成本几乎只有电费,真正做到不限次数、不限量使用。
3. 离线与无限制使用
- 离线可用:没有网络也能正常运行。
- 内网可用:适合在不便连接外网的公司或隔离环境中部署。
- 无使用限制:无需担心服务商的速率限制、内容过滤或突发服务中断。
如何开始运行本地模型?
如果你是第一次尝试在本地运行大模型,从 Ollama 开始是个不错的选择。它提供了极其简单的客户端,只需在界面中选择并下载模型即可运行,对新手非常友好。
除了 Ollama,你还可以尝试以下流行的本地模型运行方案:
- LM Studio:功能丰富的图形化客户端,支持多种后端。
- llama.cpp:一个高效的 C++ 库,支持在纯 CPU 或搭配 GPU 的情况下运行模型,是许多工具的后端基础。
这些工具都能让你相对方便地在个人电脑上体验和运用大模型的能力。最后,也是最重要的一点:祝你有足够大的内存!在云栈社区的 智能 & 数据 & 云 板块,你可以找到更多关于算力优化和模型部署的讨论与资源。
原文链接:https://www.appinn.com/llmfit/
|  发表于 2026-3-9 05:21:22
|
查看: 631|
回复: 0
发表于 2026-3-9 05:21:22
|
查看: 631|
回复: 0
