2026年3月7日,OpenClaw发布了其迄今为止规模最大的一次版本更新:v2026.3.7。官方用一句话概括了这次升级的力度:We don't do small release。
这并非一句简单的营销口号。根据版本信息,本次更新由超过 190 位贡献者共同完成,带来了 89 项重要功能升级,并修复了 200+ 个问题。更关键的是,这次发布不是简单地“多接了几个模型、多加了几个工具”,而是对OpenClaw的系统边界、上下文机制、状态管理和部署形态进行了系统性重构。
如果说早期的人工智能 Agent框架更像“能跑起来的工作流拼装器”,那么OpenClaw v2026.3.7已经明显朝着“生产级AI原生操作系统”的方向演进。本文将从架构分层、执行链路、上下文引擎、双轨记忆、ACP持久化与双模型路由几个关键维度,拆解这一最新版本背后的设计逻辑。
一、版本跃迁:从“工具调用框架”到“AI基础设施”
OpenClaw新版本最值得关注的,不是某一个单点功能,而是整体架构思路的成熟。它正在形成一套鲜明的系统哲学:
- 文本驱动(Text-Driven): 统一以自然语言和结构化消息作为任务入口
- 本地优先(Local-First):尽可能在本地或边缘节点完成执行
- 事件调度(Event-Oriented Orchestration):通过网关和状态系统编排任务流转
- 微内核 + 插件化(Microkernel + Plugin Architecture):核心能力保持收敛,扩展能力全部可插拔
- 中心决策,边缘执行(Centralized Reasoning, Distributed Acting):推理在中心,动作在边缘
这意味着,OpenClaw的目标已经不只是“让大模型调用工具”,而是构建一套可部署、可扩容、可恢复、可治理的Agent基础设施。
二、架构总览:五大逻辑层与三大物理进程
从逻辑结构上看,OpenClaw v2026.3.7被划分为五大核心层级;而在工程部署层面,它又被折叠为三个主要物理进程。这种设计兼顾了“概念上的清晰解耦”和“部署上的极简落地”。
2.1 五大逻辑层
| 逻辑层 |
核心职责 |
典型能力 |
| 接入层 (Channel Layer) |
接收外部消息并做标准化 |
WebSocket, HTTP, Discord, Telegram, Slack, WhatsApp, Web UI, RPA/API |
| 网关层 (Gateway Layer) |
统一鉴权、安全检查、路由、状态调度 |
Context Engine, ACP Adapter, Node Manager |
| 智能体层 (Agent Layer) |
负责推理、决策与多智能体协同 |
ReAct Runtime, Master/Slave Agent, soul.md |
| 技能层 (Skill Layer) |
负责工具抽象与执行能力编排 |
通用工具、本地工具、远端工具、Cloud Hub工具 |
| 执行层 (Node Layer) |
负责动作实际落地 |
Local Node, Remote Node |
2.2 总体架构图
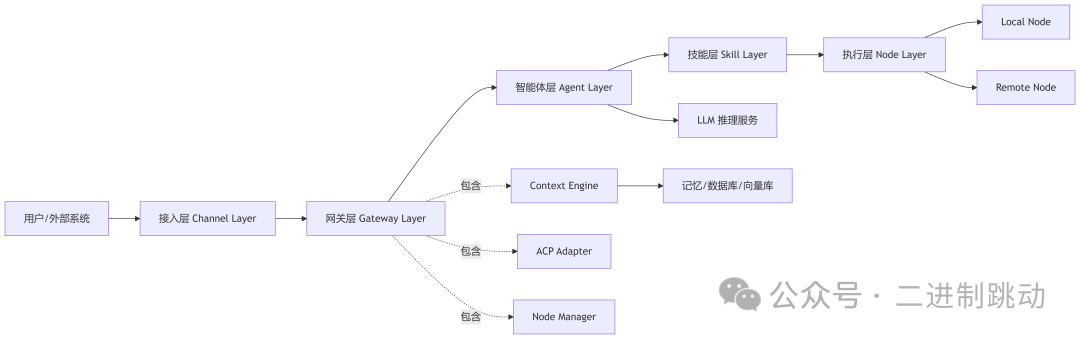
这张图反映了OpenClaw的核心原则:所有外部请求先被统一接入,再进入中心网关;推理决策在Agent Runtime中完成;实际执行则根据工具类型和目标设备,被路由到本地节点或远程节点。
三、从“五层逻辑”到“三个进程”:部署复杂度被压缩了
虽然五层逻辑看起来较为复杂,但OpenClaw在实际部署时,并没有把每一层都拆成独立服务,而是进行了高度工程化的折叠。
3.1 三大物理进程
| 进程 |
作用 |
部署位置 |
| Gateway 主进程 |
承载接入、网关、Agent、Skill、本地节点 |
中心控制机 |
| LLM 推理进程 |
提供模型推理能力 |
本地推理服务或外部模型API |
| Remote Node 客户端 |
承载远端设备动作执行 |
被控设备、边缘设备 |
3.2 物理部署图
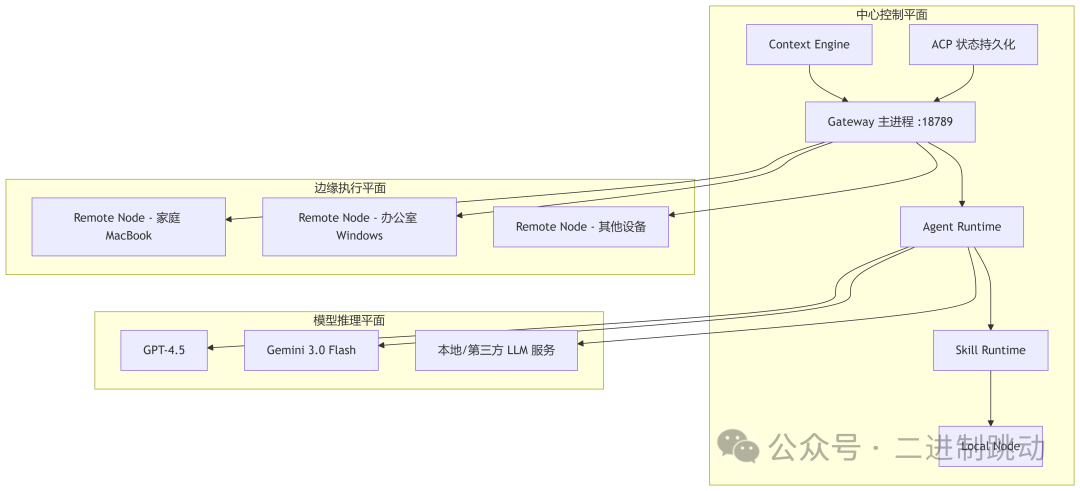
这套折叠式设计有一个非常现实的好处:它让OpenClaw同时支持两种运行范式。
- 极简单机模式: 只运行Gateway + 一个模型服务,就能完成本地Agent部署
- 分布式扩展模式: 在中心Gateway之外,挂载任意数量的Remote Node,实现跨设备控制和弹性扩容
这也是它能从“个人工作流工具”向“生产级多节点系统”进化的关键。
四、执行链路拆解:如何做到“中心推理,边缘执行”
理解OpenClaw,不能只看静态架构图,更要看请求在系统里如何流动。下面用两个典型场景解释它的执行闭环。
五、场景一:远端个性化执行链路
需求示例:用户在手机微信中发送一句话——把家里 MacBook 截屏发我
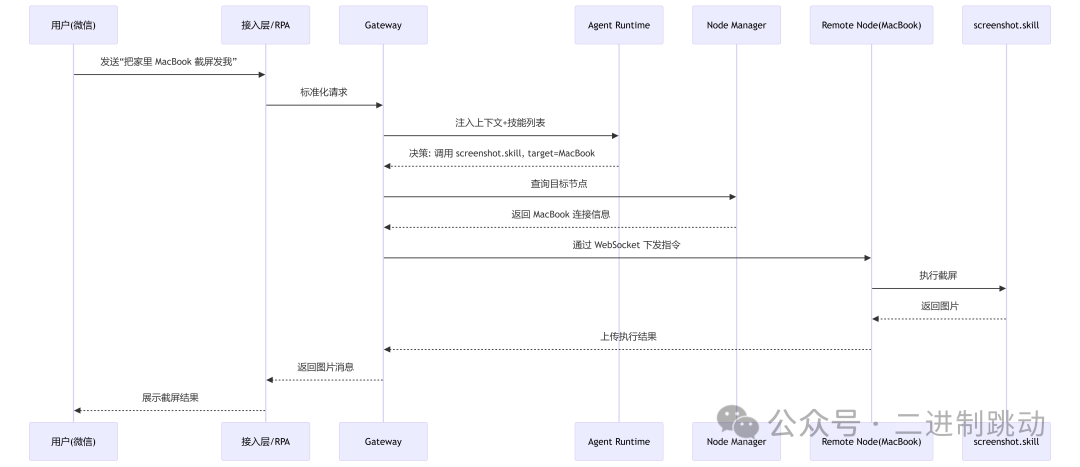
5.1 执行流程
- 用户请求从微信进入RPA或API接入器
- 接入层将消息标准化后转发给Gateway
- Gateway完成鉴权、上下文装配、状态记录
- Agent Runtime读取上下文与可用技能列表
- 大模型推理后决定调用
screenshot.skill
- Gateway通过Node Manager找到目标设备对应的Remote Node
- 指令通过WebSocket长连接下发到家里的MacBook
- 远端节点执行截屏操作并上传结果
- Gateway回收结果并通过微信接口返回给用户
5.2 远端执行时序图
5.3 场景价值
这个链路最重要的一点在于:大脑在中心,手脚在边缘。
- 复杂推理不在远端设备完成,减少边缘节点负担
- 远端设备只负责执行动作,安全边界更清晰
- 节点可以独立增减,不影响网关主体
- 跨地域、跨设备、跨终端的一致控制成为可能
六、场景二:本地通用工具执行链路
需求示例:用户提问——最新星舰发射成功了吗?
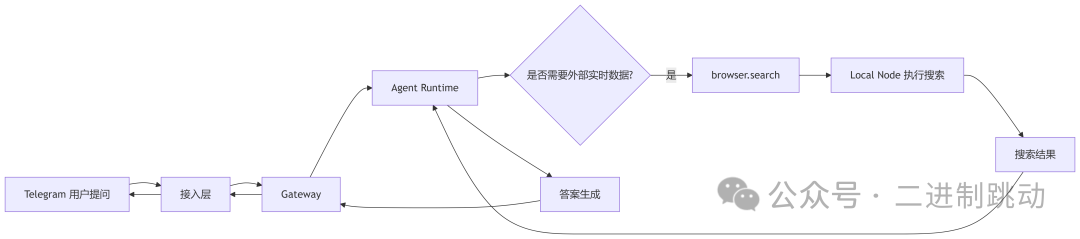
6.1 执行流程
- 用户从Telegram发起提问
- 请求经过接入层进入Gateway
- Gateway将上下文与技能信息交给Agent Runtime
- Agent判断当前问题需要最新数据
- 模型决定调用
browser.search
- Gateway发现该工具属于本地通用技能
- 请求直接在Local Node执行联网搜索
- 搜索结果返回Agent,进行信息归纳与答案生成
- 最终结果回传给Telegram
6.2 本地执行流程图
6.3 与远端执行的差异
| 维度 |
本地通用执行 |
远端个性化执行 |
| 决策位置 |
Gateway + Agent |
Gateway + Agent |
| 执行位置 |
Local Node |
Remote Node |
| 是否需要节点调度 |
否 |
是 |
| 是否依赖设备注册表 |
否 |
是 |
| 典型任务 |
搜索、天气、汇总 |
截屏、跨设备控制、文件操作 |
正是这种“同一套推理中枢,对应不同执行落点”的能力,让OpenClaw的通用技能与个性化设备能力可以在同一框架下统一编排。
七、真正的核心能力:可插拔的Context Engine
如果说分层架构定义了OpenClaw的“骨架”,那么 Context Engine 就是这次版本升级最核心的“神经系统”。
过去,大多数Agent系统对“记忆”的处理方式都很僵硬:
- 上下文结构固定
- 记忆注入方式固定
- 压缩策略固定
- 存储后端固定
这在demo阶段问题不大,但一旦进入企业级场景,很快就会遇到以下问题:
- 企业已有MySQL、ES、向量库和RAG系统,难以接入
- 不同业务对记忆写入、检索、隔离、过期规则要求完全不同
- 多智能体协同时,记忆污染和上下文串扰严重
- 上下文窗口成本高,压缩策略无法细粒度控制
OpenClaw v2026.3.7的关键改进,是把上下文系统从“内置逻辑”升级为“可插拔引擎”。
7.1 Context Engine生命周期钩子
| 阶段 |
作用 |
| Startup |
建立数据库连接、预热缓存、初始化记忆后端 |
| Ingest |
拦截输入内容,做清洗、切分、向量化 |
| Assemble |
在请求前注入或裁剪上下文 |
| Compact |
在窗口逼近阈值时触发压缩 |
| After-turn |
在回合结束后决定哪些内容持久化 |
7.2 上下文引擎工作流
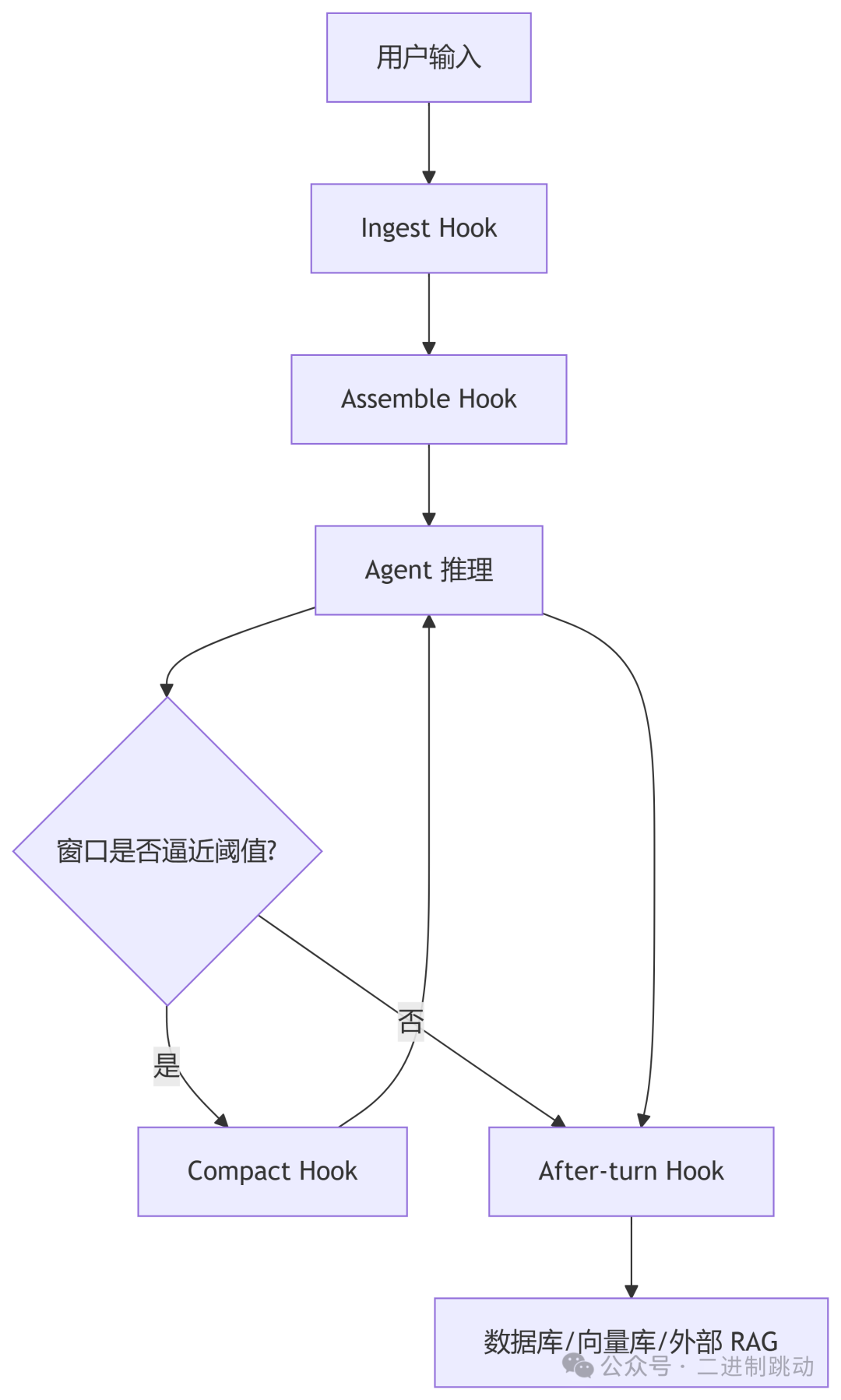
7.3 这意味着什么
这套机制带来的不是“更灵活一点”,而是系统边界彻底改变了:
- 企业可以直接接入自有数据库/中间件/技术栈和知识库
- 可以替换Embedding模型,例如切换到自定义向量化服务
- 可以自定义上下文裁剪规则和窗口预算
- 可以按业务场景决定哪些记忆写入、哪些只保留在会话内
- 可以在多Agent协作时实现更细致的记忆隔离与回流
换句话说,Context Engine让OpenClaw的“记忆系统”不再是一个黑盒,而是变成了一个完整的扩展面。
八、双轨制“无损记忆”:解决长对话中的信息坍缩
传统Agent系统在上下文窗口接近上限时,通常采用一种简单策略:总结旧对话,然后丢弃原文。
这会引发一个根本性问题:摘要会不可避免地损失细节,而某些关键细节往往恰恰在后续任务中非常重要。OpenClaw这次引入的,是一套更接近“分层存储”的双轨记忆架构。
8.1 机制说明
当上下文压缩被触发时,系统不会直接删除原文,而是做两件事:
- 为大模型保留一份摘要,降低token开销
- 将原始内容写入底层存储,并保留指针信息
该指针通常包含:
模型在对话中看到的是“摘要 + 指针元数据”。如果后续推理中发现某段历史细节有必要被重新检查,系统就可以依据指针按需拉回原文。
8.2 双轨记忆结构图

8.3 为什么这很重要
这本质上是在Agent体系里引入“分页记忆”和“延迟加载”的能力。相比传统摘要压缩,它的优势在于:
- 更低token成本: 模型平时只看摘要
- 更高信息完整性: 原文不被销毁
- 更强推理鲁棒性: 需要细节时可动态召回
- 更适合长链任务: 尤其适合多步骤规划和长期会话
从工程角度看,这已经不只是“记忆优化”,而是把AI上下文管理推进到了更接近数据库系统设计的层面。
九、走向生产可用:ACP持久化与双模型路由
一个真正的生产系统,不仅要“能推理”,更要“不会轻易中断”。OpenClaw v2026.3.7在可用性层面最重要的两项升级,是 ACP持久化 与 双模型智能路由。
十、ACP状态持久化:让中断任务可以从断点恢复
以往很多Agent系统都有一个共同缺陷:只要主进程重启,正在执行的复杂任务就会丢失状态,用户只能从头再来。OpenClaw通过 ACP(Agent Client Protocol)Adapter,为任务执行过程引入了状态持久化层。
10.1 ACP工作方式
- 任务每进入一个关键步骤,系统都记录状态
- 状态数据与上下文、执行阶段、节点信息绑定
- 如果Gateway异常退出或重启,系统可恢复到最近一个已提交状态点
- 多轮任务不再因进程生命周期而被完全中断
10.2 ACP恢复流程图
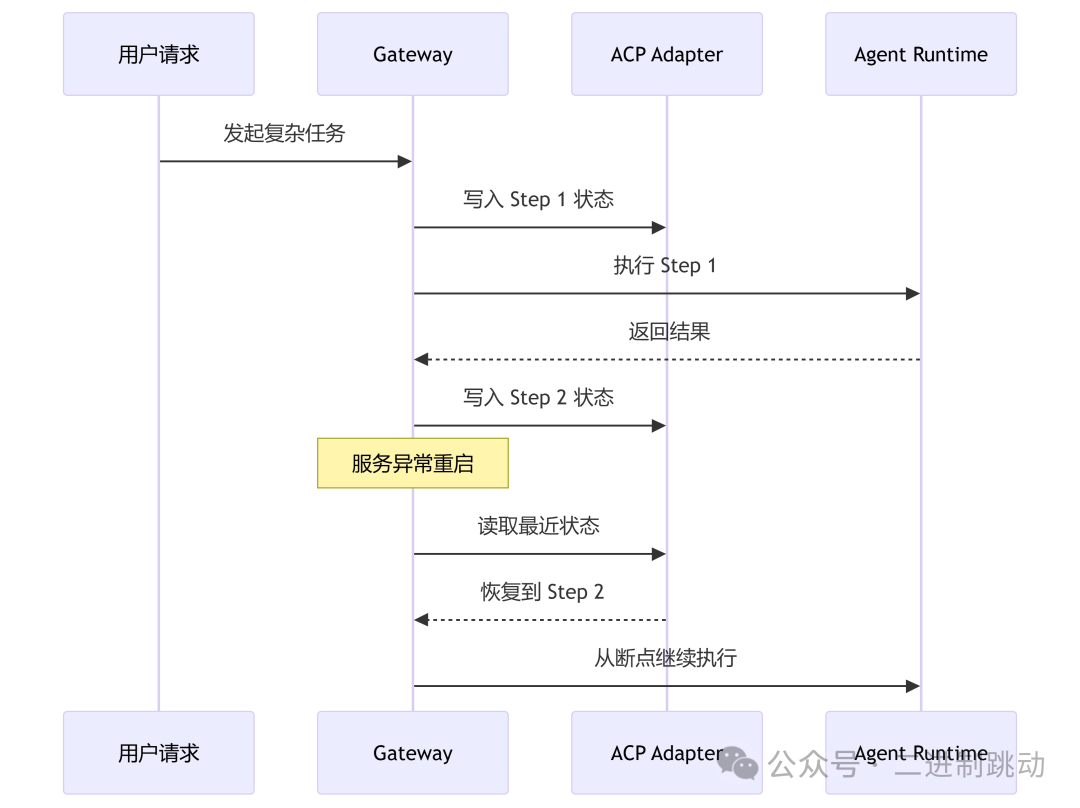
10.3 生产价值
- 长任务不怕服务重启
- 复杂会话可恢复
- 多节点协作更可靠
- 系统可维护性和SLA更高
十一、双模型智能路由:从“可选模型”升级到“容灾模型”
OpenClaw新版首发适配了 GPT-4.5 与 Gemini 3.0 Flash。但这项能力的价值,不只是“兼容更多模型”,而是将多模型能力真正变成了生产级调度系统的一部分。
11.1 双路由设计目标
- 主模型承担默认推理任务
- 备用模型在限流、超时、过载时自动接管
- 保持服务连续性
- 避免单模型供应链风险
11.2 模型路由图
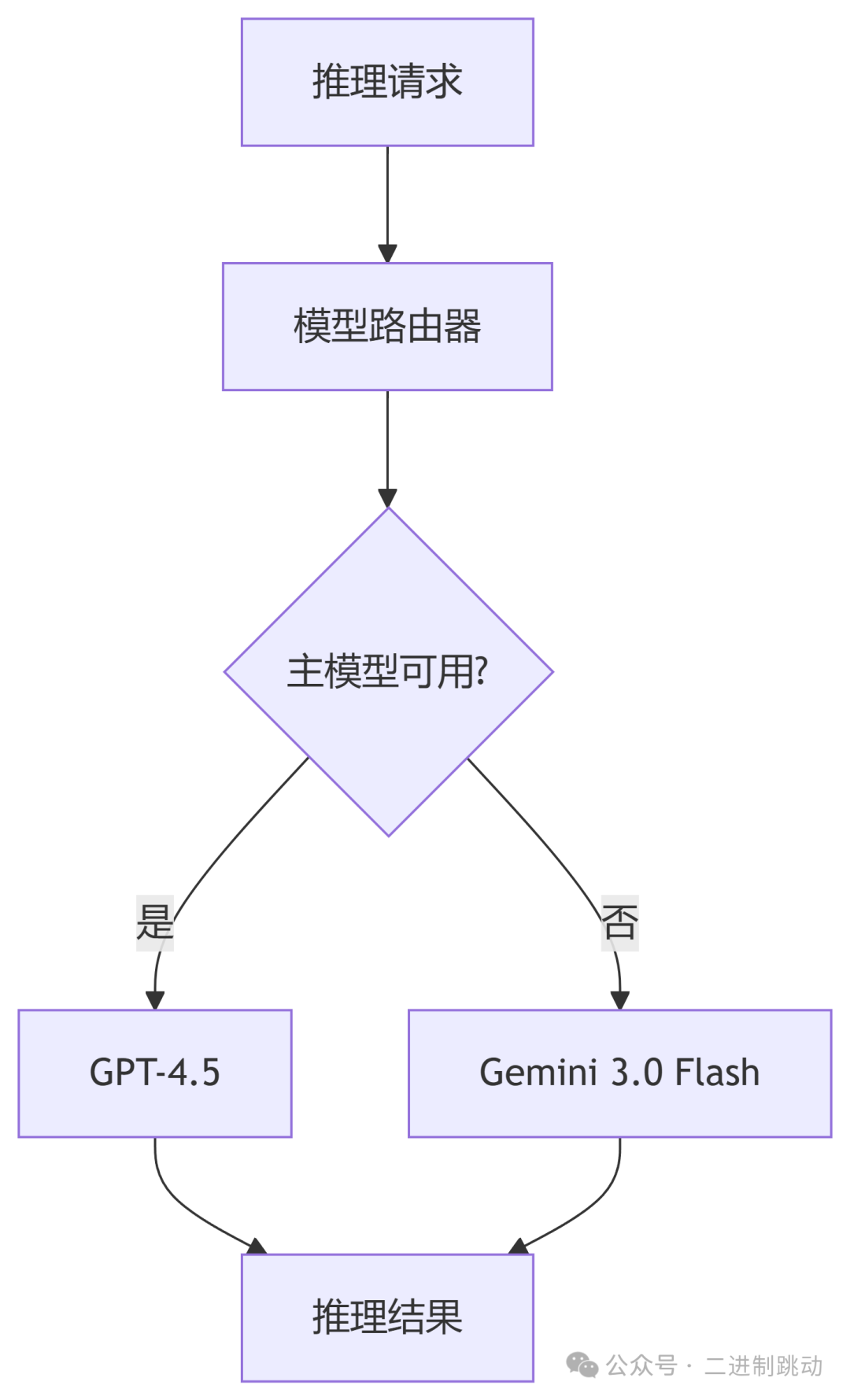
11.3 它解决了什么问题
在很多线上场景中,真正影响系统稳定性的,并不是Agent本身,而是模型供应的不确定性:
- 限流
- 高峰期响应抖动
- 单模型API不可用
- 某模型成本过高
双模型路由本质上是一种 推理层高可用策略。一旦模型推理被视为后端 & 架构的一部分,那么多模型容灾就不再是“锦上添花”,而是必选项。
十二、为什么说OpenClaw指向了AI Native架构的未来
如果把OpenClaw当前版本再往前抽象一步,会发现一个AI原生系统最终会收敛到三类能力:
| 核心层 |
作用 |
| 智能体业务层 |
负责目标理解、任务规划、工具调度 |
| 模型推理层 |
负责语言理解、推理和生成 |
| 知识与记忆层 |
负责长期状态、知识检索、上下文恢复 |
OpenClaw已经初步把这三类能力向工程可落地方向推进。但从更长远的演进看,未来AI Native系统还会进一步补齐更多“治理型模块”。
12.1 未来AI Native平台可能的模块化版图
功能侧模块
- 流量网关
- Agent API网关
- 消息队列
- 主智能体层
- 从智能体层
- 技能层
- MCP网关
- AI网关层
- 模型层
- 记忆层
- 知识库层
治理侧模块
- AI注册中心
- AI配置中心
- AI安全体系
- AI评估体系
- AI弹性伸缩中心
- AI可观测平台
12.2 未来形态示意图
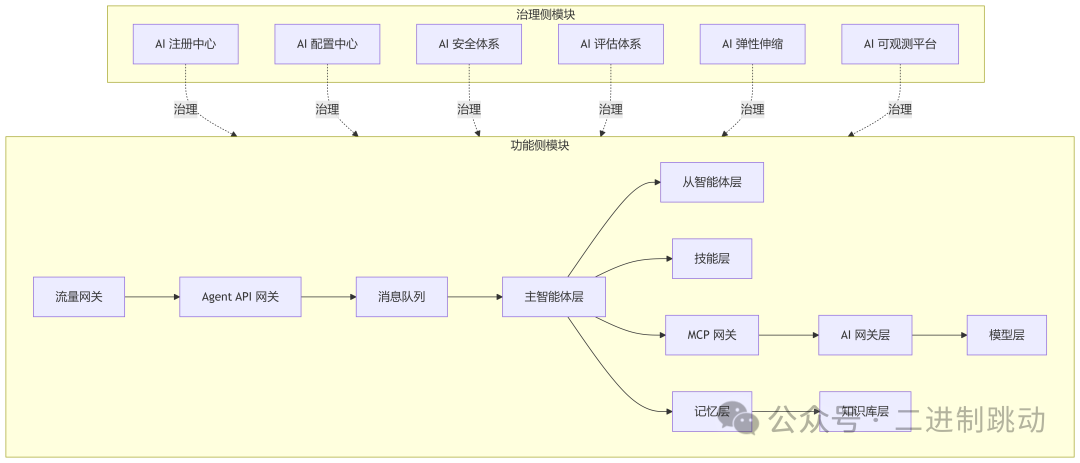
这张图说明的是:AI系统的发展路径,正在重演云原生和微服务架构曾走过的道路。只是这一次,服务编排的中心对象,不再是HTTP接口,而是模型、上下文、Agent与技能。
十三、结语:OpenClaw v2026.3.7的真正意义
OpenClaw v2026.3.7的价值,不在于它一次性增加了多少功能,而在于它把Agent框架从“工具调用器”提升为“可治理、可恢复、可扩展的系统底座”。
它完成了几个关键跃迁:
- 从单体工具流转向微内核+插件化架构
- 从静态记忆转向可插拔上下文引擎
- 从摘要式压缩转向双轨无损记忆
- 从单模型依赖转向双模型容灾路由
- 从任务易丢失转向ACP状态持久化恢复
- 从单机Agent转向中心决策、边缘执行的分布式形态
这说明一个趋势正在越来越清晰:未来真正有竞争力的AI应用,不会只是“把大模型接进业务系统”,而是围绕 上下文管理、技能编排、状态恢复、节点调度和治理体系,构建完整的AI Native基础设施。而OpenClaw v2026.3.7,已经把这条路径提前走通了一大步。关于人工智能架构的更多前沿探讨,你也可以在云栈社区与更多开发者交流。
 发表于 2026-3-12 06:41:32
|
查看: 172|
回复: 0
发表于 2026-3-12 06:41:32
|
查看: 172|
回复: 0
