
你的AI Agent是否总在“失忆”?今天教会的规则,明天就忘得一干二净。这并非模型能力不足,而是架构设计上的普遍缺陷。
大多数Agent把所有上下文塞进短暂的对话提示中,一旦会话结束,记忆也随之清空。有没有一种方法能让Agent真正积累经验,越用越聪明?Google AI产品经理Shubham Saboo通过OpenClaw运行了40天,他手下的8个Agent全天候工作,每个都在持续进化。其核心秘密,就藏在几个看似简单的Markdown文件里。
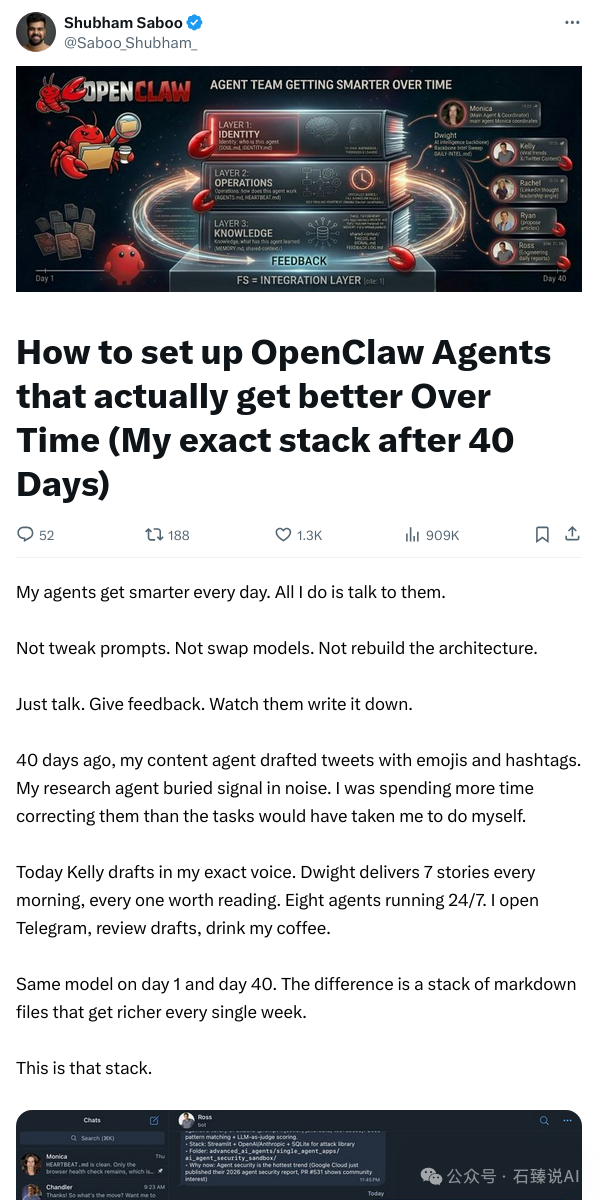
核心架构:三层文件系统
Shubham的系统摒弃了复杂的数据库和消息队列,其核心是一个三层Markdown文件架构。文件系统本身就是最高效的集成层。

第一层:身份层 (Identity)
SOUL.md: 定义Agent的核心人格与性格。IDENTITY.md: 快速参考卡片,包含名字、角色、表情符号。USER.md: 描述服务对象的背景与偏好。
第二层:操作层 (Operations)
AGENTS.md: 行为规则手册,定义每次启动的流程。HEARTBEAT.md: 系统健康自检规则。- 各类专业指南文件:针对具体任务的详细操作说明。
第三层:知识层 (Knowledge)
MEMORY.md: 精炼后的长期记忆,存储重要经验和教训。memory/YYYY-MM-DD.md: 每日操作日志,原始记录。shared-context/: 供所有Agent共享的跨域知识库。
第一层:为Agent注入灵魂

SOUL.md:定义核心人格
Shubham为每个Agent赋予了一个电视剧角色的名字。例如,他的研究Agent名叫Dwight(源自《办公室》中那个严谨较真的角色)。这种做法巧妙利用了模型训练数据中已存在的丰富角色设定。
关键原则:SOUL.md必须简短,控制在60行以内。因为它会在每次会话时加载,过长会挤占实际任务所需的上下文空间。
SOUL.md 模板:
# SOUL.md
## 核心身份
[Agent 名字] — [一句话描述]。[可选:参考的电视角色]
## 你的角色
[这个 Agent 具体做什么。要具体,不要泛泛而谈]
## 你的原则
1. [最重要的规则]
2. [第二重要的规则]
3. [第三重要的规则]
## 关系网络
[这个 Agent 和谁协作?谁会用它的输出?]
IDENTITY.md:快速名片
如果说SOUL.md是完整传记,那么IDENTITY.md就是一张便捷的名片。
# IDENTITY.md
- **Name:** Dwight
- **Role:** 研究 AI — 情报骨干
- **Vibe:** 认真、彻底、零容忍不准确
- **Emoji:** 🔍
- **Inspiration:** Dwight Schrute (The Office)
USER.md:了解你的用户
每个Agent都需要知道它在为谁工作。USER.md存放了用户的偏好、背景等上下文信息,确保Agent的行为符合个性化需求。
# USER.md
- **Name:** Shubham
- **Timezone:** PST (America/Los_Angeles)
- **Diet:** 素食
## 背景
- Google Cloud 高级 AI 产品经理
- Awesome LLM Apps 创建者(91k+ stars)
- Unwind AI newsletter 运营者(30k+ 订阅)
## 偏好
- 短段落,有力的句子
- 绝不用破折号
- 实践优先,理论靠边
细节决定成败。时区信息能避免Agent在凌晨安排任务,饮食偏好能确保起草聚餐通知时不会推荐牛排馆。这些细微之处的累积,塑造了高度贴合的体验。
第二层:定义清晰的工作流程
AGENTS.md:行为规则手册
SOUL.md定义了“我是谁”,AGENTS.md则规定了“我该怎么做”。它明确了会话启动流程、文件读取顺序和记忆管理规则。
根目录的AGENTS.md是所有Agent继承的基础规则:
# AGENTS.md
## 每次启动必做
1. 读 SOUL.md — 这是你的身份
2. 读 USER.md — 这是你服务的人
3. 读 memory/YYYY-MM-DD.md(今天+昨天)
4. 如果是主 session:也读 MEMORY.md
## 记忆规则
- "脑子里记住"不管用,重启就忘
- 有人说"记住这个" → 写进 memory 文件
- 文本 > 大脑
## 安全规则
- 不要泄露私人数据
- trash > rm(可恢复优于永久删除)
- 不确定时,先问
在此基础上,每个Agent可以扩展自己的专属规则。例如,负责X平台内容的Agent Kelly的AGENTS.md会包含更多具体的写作指南和素材来源。
Agent在会话之间没有记忆,一切从文件重新开始。如果纠正没有落到文件里,下次就不复存在。AGENTS.md让这一点成为铁律,迫使Agent把所有重要信息都写下来。
专业文件:让Agent变得锐利
专业文件是Agent能力精细化的关键。Kelly不仅有AGENTS.md,还有6个额外文件来定义内容创作:写作风格指南、推文格式参考、真实案例库、每日任务清单、目标受众画像等。这些详尽的指南,尤其是在开源实战中积累和迭代的最佳实践,是Agent输出质量飞跃的基础。
HEARTBEAT.md:实现自我修复
Agent团队是数字基础设施,而基础设施可能出故障。HEARTBEAT.md文件定义了系统的健康检查规则。
## 健康检查(每次心跳执行)
**浏览器:** 检查 OpenClaw 管理的浏览器(profile=openclaw)是否在运行。
如果 running: false,启动它。浏览器里登录了 X 账号。
Dwight 需要它来做情报扫描。
**定时任务:** 检查每日任务是否有 lastRunAtMs 过期(>26 小时)。
如果过期,通过 CLI 触发:openclaw cron run <jobId> --force
监控任务:
- Dwight 早报(8:01 AM)
- Kelly X 草稿(5:01 PM)
- Rachel LinkedIn(5:01 PM)
- Pam Newsletter(6:01 PM)
每次心跳 session 只运行每个检查一次。
心跳机制监控关键依赖(如浏览器)和定时任务。它们环环相扣:浏览器宕机,研究Agent无法扫描;研究停止,内容Agent将无米下炊。这个文件是在经历实际故障后建立的,针对性极强。
第三层:积累与精炼知识

MEMORY.md:精炼的长期记忆
这不是原始日志,而是经过提炼的重要经验和教训。
Monica (主Agent) 的 MEMORY.md 片段:
# MEMORY.md
## Shubham 的写作偏好
- 绝不用破折号。用冒号、句号或重构。
## 血的教训
- 绝不在没问 Shubham 的情况下删除项目文件夹。2 月 26 日,
清理时删了 Ross 的 gemini-council React 应用。React
版本永久丢失了。删除 agent 项目目录前必须先问。
注意“血的教训”部分。一次严重的误操作被永久记录在长期记忆中,防止所有未来会话重蹈覆辙。一次纠正,永久生效。
安全提示: MEMORY.md仅在直接会话中加载,不在群聊等共享上下文中加载,避免敏感信息泄露。
memory/YYYY-MM-DD.md:每日会话日志
这是原始材料,记录当天发生的所有事情、起草的内容和收到的反馈。
# Kelly 每日日志 — 2026 年 2 月 5 日
## 5:00 PM — 每日 X 草稿
### 今日热点
- Opus 4.6 vs GPT-5.3-Codex 相隔 27 分钟发布
- Anthropic 的 C 编译器(16 个 agent,$20k,能编译 Linux 内核)
### 提交的草稿
1. C 编译器 — 单条推文,发现格式
2. Mitchell Hashimoto 的 6 步法 — 串推格式
3. Opus 4.6 vs GPT-5.3-Codex — 热评
### 等待中
- Shubham 对草稿的反馈
维护规则: 每日日志增长迅速,需定期修剪归档,通常只加载今天和昨天的日志,避免上下文过度膨胀影响输出质量。
shared-context/:跨Agent共享知识库
这是后期增加但改变游戏规则的一层。一个所有Agent启动时都会读取的共享文件夹。
shared-context/
├── THESIS.md — 我当前的世界观
├── FEEDBACK-LOG.md — 适用于所有 Agent 的纠正
└── SIGNALS.md — 我在追踪的文章和趋势
- THESIS.md 是统一的世界观,确保所有Agent的研究、创作和规划对齐到同一战略方向。
- FEEDBACK-LOG.md 是中央纠正日志。例如,告知Kelly“不用破折号”的反馈会记录于此,这样Rachel、Ryan、Pam等所有内容型Agent都能读到,实现一次纠正,全局生效。这类文件的管理和编写,本身就是一门值得深入学习的技术文档艺术。
Agent之间如何协作?文件即协调
没有API调用,没有消息队列。协作通过读写文件完成。
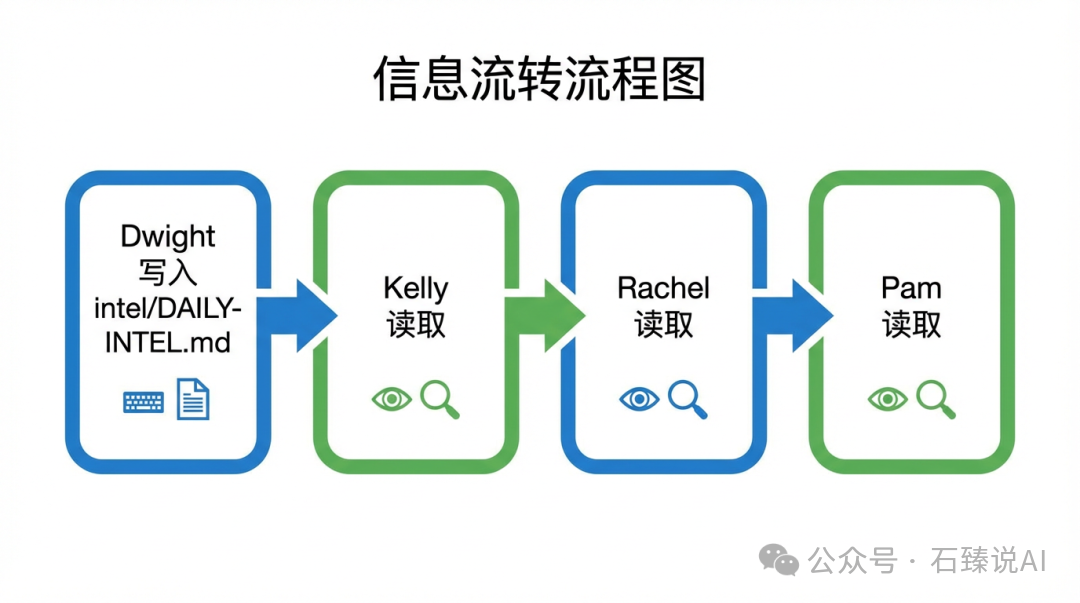
研究Agent Dwight将成果写入 intel/DAILY-INTEL.md。内容Agent Kelly、Rachel和Pam读取这个文件作为素材来源。协调的媒介就是磁盘上的Markdown文件。
单写者规则: 确保每个共享文件只有一个写入者,多个读取者。这从根本上避免了需要调试的协调冲突。
调度是关键: Dwight在早上8点运行,Kelly等在下午5点运行。严格的执行顺序保障了下游Agent总能获取到新鲜出炉的“情报”。
完整的目录结构
workspace/
├── SOUL.md # Monica(主 Agent)
├── IDENTITY.md # Monica 的快速参考
├── AGENTS.md # 根行为规则(所有 Agent 继承)
├── USER.md # 关于我(所有 Agent 共享)
├── MEMORY.md # Monica 的长期记忆
├── HEARTBEAT.md # 自我修复检查
├── shared-context/
│ ├── THESIS.md # 我当前的世界观
│ ├── FEEDBACK-LOG.md # 跨 Agent 纠正
│ └── SIGNALS.md # 我在追踪的趋势
├── intel/
│ ├── DAILY-INTEL.md # Dwight 的输出(其他 Agent 读这个)
│ └── data/
├── agents/
│ ├── dwight/ # 研究 Agent
│ │ ├── SOUL.md
│ │ ├── IDENTITY.md
│ │ ├── AGENTS.md
│ │ ├── TARGET-AUDIENCE.md
│ │ ├── RESEARCH-PROTOCOL.md
│ │ ├── HEARTBEAT.md
│ │ └── memory/
│ ├── kelly/ # X/Twitter 内容 Agent
│ │ ├── SOUL.md
│ │ ├── IDENTITY.md
│ │ ├── AGENTS.md
│ │ ├── X-CONTENT-GUIDE.md
│ │ ├── X-ARTICLES-INSTRUCTIONS.md
│ │ ├── X-STRATEGY.md
│ │ ├── DAILY-ASSIGNMENT.md
│ │ └── memory/
│ └── [其他 Agent...]
└── memory/
├── shubham/ # 私人笔记
├── shared/ # 共享上下文
└── 2026-02-27.md # 每日操作日志
为什么这个方案行之有效?复利的力量
文件不是静态的,它们在持续进化。
第1天Kelly的SOUL.md是粗略草稿,第40天时,里面已充满了具体的语音示例、她自己总结的“错误模式清单”和“永不再提”的话题黑名单。
Dwight的研究原则从泛泛的“找热点”,进化到“如果目标读者今天用不上就跳过”,并增加了具体的来源验证步骤。
shared-context层直到第20天才出现,诞生于“向多个Agent重复相同纠正”的痛苦之中。它的建立所带来的效率提升,远超任何提示词微调。
最关键的是:第1天和第40天使用的是同一个模型。 模型不会因为使用时长而变聪明,但包裹它的文件系统会变得越来越丰富、锐利、贴合你的特定需求。这些积累的上下文构成了真正的护城河。而构建这条护城河的方法,就是每天与你的Agent对话,并将对话的精华沉淀到文件里。
如何开始你的40天养成计划?
不要试图一个周末搭建完整个系统。跟随节奏,循序渐进:
- 今天: 安装OpenClaw。编写第一个SOUL.md、IDENTITY.md和USER.md。选择一个你日常重复的任务,设置一个定时任务,让它先跑起来。
- 3天后: 输出可能很普通。开始给予具体的反馈,并确保这些反馈被写入
memory/下的日志文件,而不只是留在聊天记录里。
- 1周后: 创建AGENTS.md,定义清晰的会话启动流程和记忆管理规则。
- 2周后: 开始提炼MEMORY.md。回顾每日日志,把那些你反复纠正的点,变成永久的记忆条目。此时,你将开始感受到“复利”的苗头。
- 3周后: 添加第二个Agent。建立基于文件的协作:一个写,另一个读。随着模式浮现,逐步加入角色专属的指南文件。
- 约第3周: 当你发现自己总在重复相同的跨Agent纠正时,就是建立
shared-context/层的时候了。
- 4周后: 在经历第一次系统故障后,创建HEARTBEAT.md。你会非常清楚该监控什么,因为你已经亲身体验过什么会出问题。
你所要做的就是坚持与你的Agent对话,文件系统会负责完成剩下的知识积累与系统进化工作。如果你想了解更多AI与开源技术的实战结合,可以到云栈社区与更多开发者交流探讨。
参考链接
 发表于 2026-3-12 06:46:53
|
查看: 184|
回复: 0
发表于 2026-3-12 06:46:53
|
查看: 184|
回复: 0
