
你是否也遇到过这样的困惑?在搭建 RAG(检索增强生成) 系统时,明明从向量数据库里捞上来的文档相似度分数极高,可内容要么风马牛不相及,要么早已过时,根本无法用来生成可靠的答案。这背后暴露的,是传统 RAG 架构底层一个过于理想化的预设:相似度高就等于结果好。在实际生产环境中,这个假设往往不堪一击。高分文档可能已经失效,描述的场景完全不符,甚至信息本身就不完整。
针对这一核心痛点,CRAG(Corrective Retrieval-Augmented Generation,校正检索增强生成)机制应运而生。它的核心价值在于,在检索与生成之间,插入了一道“评估”环节。系统会对检索到的内容进行三元判决(正确/模糊/错误),在错误信息污染大模型推理之前,就将其拦截、修正或补充,从根源上提升检索的可靠性。本文将详细介绍 CRAG 的运作机制,并展示如何利用 LangChain 框架和 Milvus 向量数据库,一步步搭建一套完整的 CRAG 系统。
传统 RAG 的三个典型检索问题
在深入 CRAG 之前,我们先来厘清传统 RAG 模式在实际应用中常遇到的几个棘手问题:
-
检索偏差
语义相似并不等同于能解决问题。例如,在一个运维助手中,用户查询“如何在 Nginx 上配置 HTTPS 证书”,检索返回的 Top3 高分文档,可能分别是 Apache 的配置教程、早已停更的旧版本指南,以及 HTTPS 的原理解析文章。
-
时效性缺失
对于时效性要求高的查询,系统可能无法分辨新旧。例如,查询“Python 异步编程最佳实践”,检索结果可能同时包含 2018 年已废弃的写法和 2024 年官方推荐的新方案。
-
记忆污染
这是最令人头疼的问题。一旦错误的、过时的信息被检索到并用于生成,如果这些生成内容又被存回知识库,就会造成“记忆污染”。新旧内容在向量空间中混杂,导致后续检索命中错误内容的概率越来越高,形成难以摆脱的恶性循环。
因此,为 RAG 乃至更复杂的 Agent 系统引入检索质量评估机制,已从一个可选项变为必选项。
CRAG:检索质量的评估与纠正机制
传统 RAG 是“检索→生成”的二元流程,对检索结果往往只有“用”或“不用”两种粗暴处理。但现实情况中,大量检索结果处于“部分相关但不完全正确”的模糊地带,二元处理要么丢失有效信息,要么引入错误内容。
CRAG 的核心改进,就是将流程扩展为四步闭环:检索 → 评估 → 纠正 → 生成。
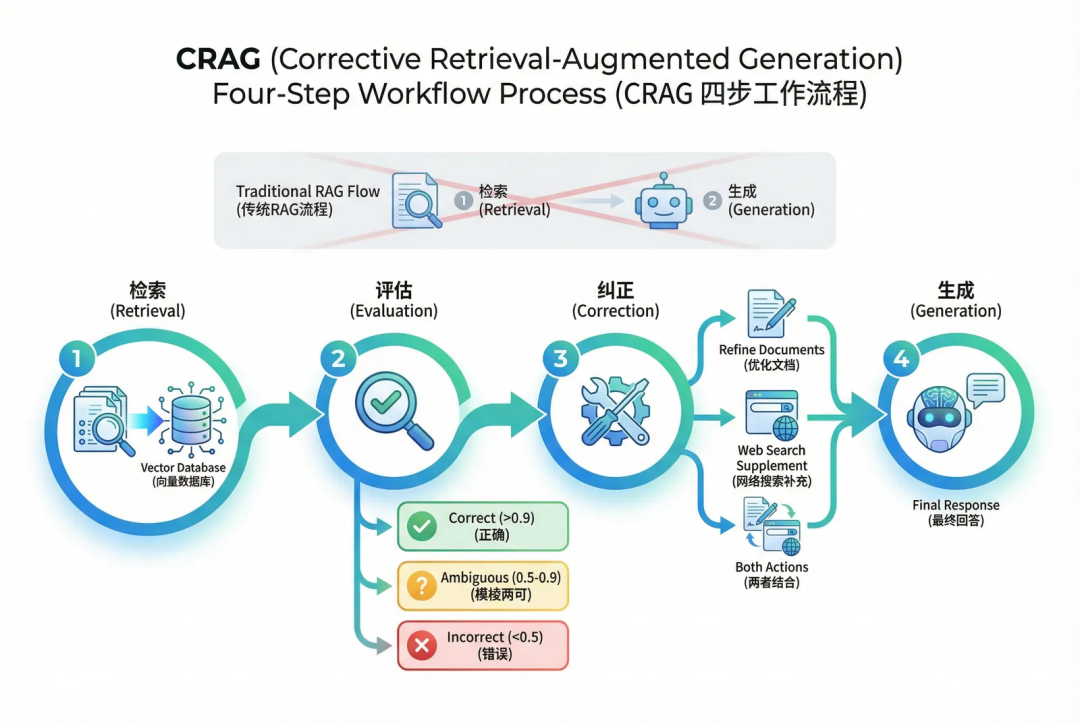
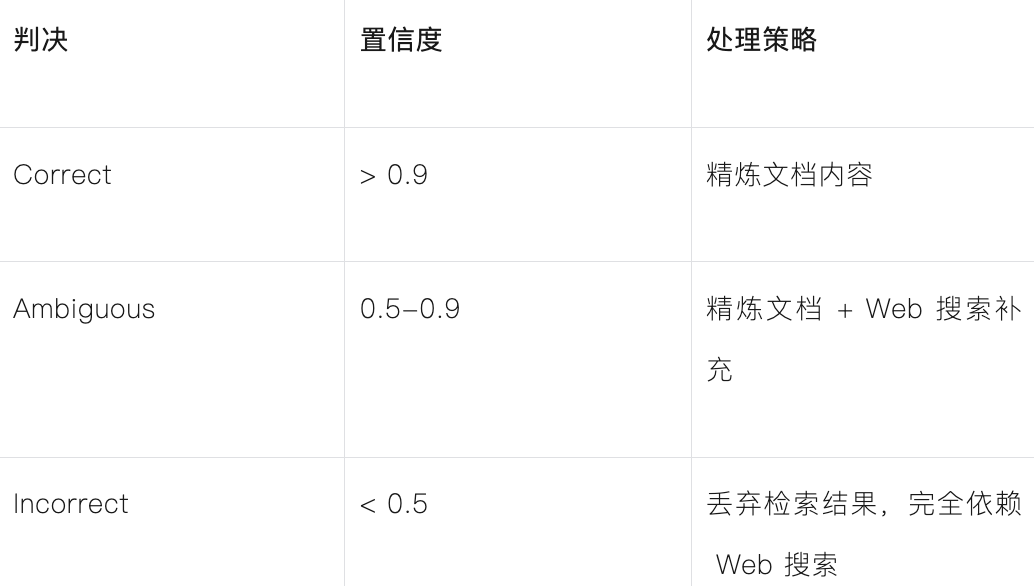
具体来说,CRAG 会根据评估结果,将检索到的文档分为三类,并采取不同的处理策略:
| 判决 |
置信度 |
处理策略 |
| Correct (正确) |
> 0.9 |
精炼文档内容后直接使用 |
| Ambiguous (模糊) |
0.5 – 0.9 |
精炼文档 + 补充 Web 搜索 |
| Incorrect (错误) |
< 0.5 |
丢弃检索结果,完全依赖 Web 搜索 |
然而,仅仅判断“能不能用”还不够。传统 RAG 另一个常见误区是:检索到文档后,不经处理就全文塞给大模型。这不仅浪费 tokens,无关信息还可能干扰模型,诱发“幻觉”。
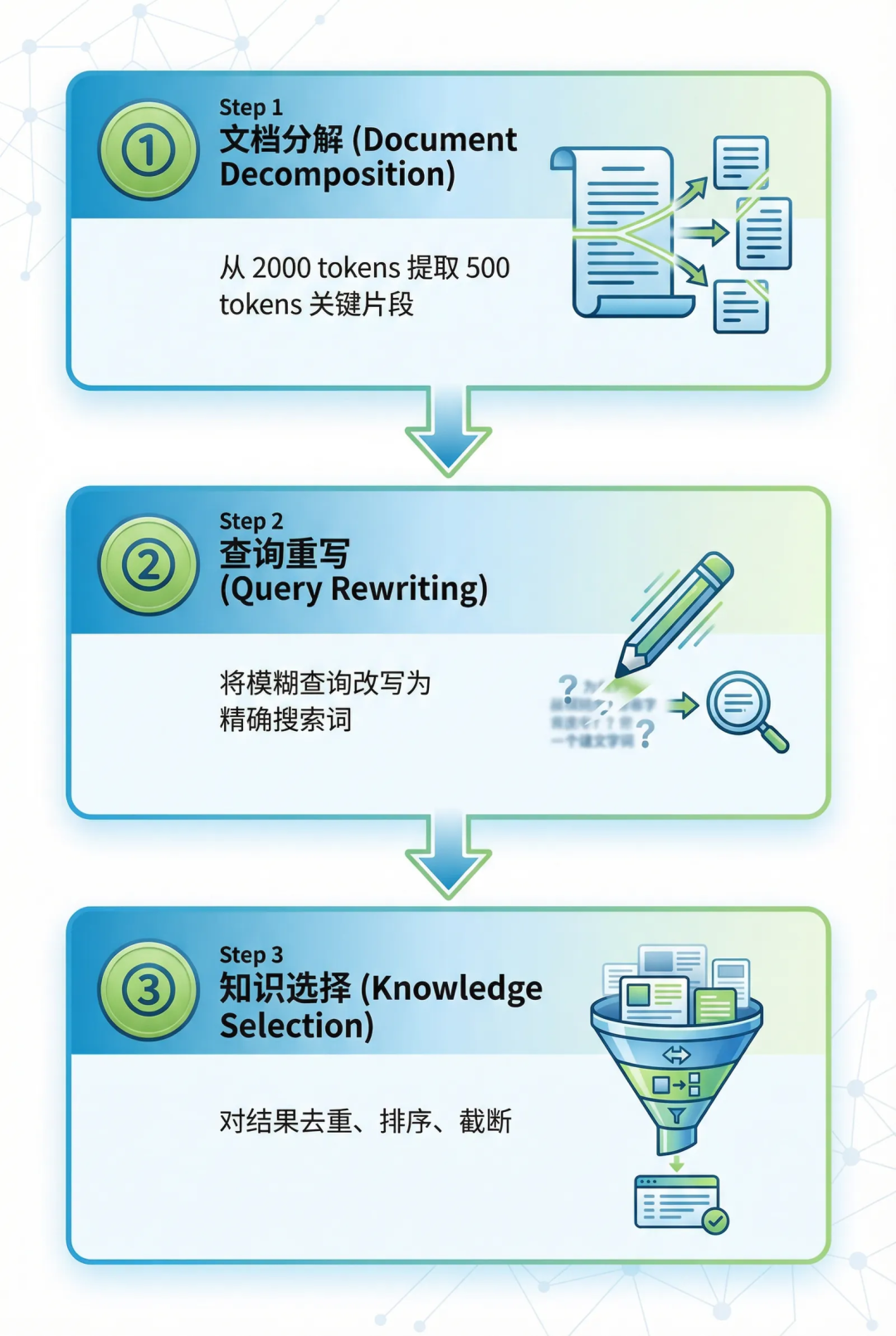
CRAG 对此的改进是:绝不直接使用检索全文,而是先进行一轮“知识精炼”,过滤掉无效信息,只保留与查询最相关的核心内容。原论文采用了“知识条带(Knowledge Strips)”加启发式规则的方法。在工程实践中,我们可以先用简化的关键词匹配方案实现;对于生产环境,则可以升级为 LLM 摘要或结构化提取,以追求更高的精炼质量。
一个典型的知识精炼流程可分为三步:文档分解(从长文中提取关键片段)、查询重写(将模糊查询改写为精确搜索词)、知识选择(对结果去重、排序和截断)。
精炼之后,便进入最核心的评估器环节。这里有一个关键原则:评估器的使命是快速筛选,而非复杂推理。它需要在毫秒级时间内判断内容是否可用。因此,CRAG 原论文推荐使用微调后的 T5-Large 这类轻量级模型,而非调用 GPT-4 等通用大模型。两者对比如下:
| 对比项 |
微调 T5-Large |
GPT-4 |
| 延迟 |
10-20ms |
200ms+ |
| 准确率 |
92%(论文实测数据) |
待测 |
| 任务适配性 |
高(专一任务,精准度高) |
中(通用模型,泛化性好) |

评估环节还会引出一个新问题:如果内部知识库的资料不足或完全错误,怎么办?CRAG 设计了一套内部检索与 Web 搜索的协同机制。简单说,当内部检索结果被判为“错误”或“模糊”时,系统会自动触发 Web 搜索,获取外部的最新信息进行补充,从而有效解决知识的时效性和完备性问题。
Milvus:支撑 CRAG 的高性能存储引擎
理解了 CRAG 的核心逻辑后,你可能会问:这套机制对底层的向量数据库有没有特殊要求?答案是肯定的。在经过多个向量数据库的选型测试后,我们发现 Milvus 的架构设计,恰好满足了 CRAG 在生产环境落地的三个核心刚需:多租户隔离、混合检索和动态 Schema。
Partition Key 实现零成本多租户隔离
在构建多 Agent 系统时,常常需要同时运行数百个实例,每个用户、每个场景的记忆必须完全独立,不能串数据。之前尝试为每个租户创建独立的 Collection,在管理和运维上都是噩梦。Milvus 的 Partition Key 功能完美解决了这个问题。只需在定义 Schema 时,为 agent_id 字段设置 is_partition_key=True,查询时系统会自动路由到对应分区,无需手动维护大量 Collection。实测在 1000 万向量、100 个租户的场景下,结合 Clustering Compaction,带来了 3-5 倍的 QPS 提升。
原生混合检索,搞定边界场景的检索失效
纯向量检索在遇到专有名词、型号编码(如 “SKU-2024-X5”)或精确版本号时容易失效。Milvus 2.5 版本原生支持稠密向量(语义)+ 稀疏向量(BM25)+ 元数据过滤的混合检索,并内置 RRF 融合排序算法,无需额外搭建多路检索和融合逻辑,大大降低了开发成本。实测数据显示,在 100 万向量规模下,Milvus 的 Sparse-BM25 检索延迟仅 6ms。
JSON 字段,支持记忆结构灵活演化
系统需求是不断变化的。随着 CRAG 评估机制的完善,我们可能需要为记忆新增 confidence、verified、source 等字段。如果使用传统结构化数据库,修改表结构往往需要停机维护。Milvus 的 JSON 字段允许灵活扩展元数据,想加就加,完全不影响线上服务。
以下是一个极简的 Schema 定义和混合检索示例:
fields = [
FieldSchema(name="agent_id", dtype=DataType.VARCHAR, is_partition_key=True), # 多租户
FieldSchema(name="dense_embedding", dtype=DataType.FLOAT_VECTOR, dim=1536), # 语义检索
FieldSchema(name="sparse_embedding", dtype=DataType.SPARSE_FLOAT_VECTOR), # BM25
FieldSchema(name="metadata", dtype=DataType.JSON), # 动态 Schema
]
# 混合检索 + 元数据过滤
results = collection.hybrid_search(
reqs=[
AnnSearchRequest(data=[dense_vec], anns_field="dense_embedding", limit=20),
AnnSearchRequest(data=[sparse_vec], anns_field="sparse_embedding", limit=20)
],
rerank=RRFRanker(),
output_fields=["metadata"],
expr='metadata["confidence"] > 0.9', # CRAG 置信度过滤
limit=5
)
此外,Milvus 还具备平滑迁移的优势。它提供 Lite(单机)、Standalone(单机可扩展)、Distributed(分布式)三种部署模式,代码完全兼容。我们可以在本地用 Lite 模式开发,生产环境无缝切换到 Distributed 模式,只需修改连接字符串即可。
基于 LangGraph Middleware + Milvus 的 CRAG 实战教程
在开始教程前,先聊聊选型思路。很多人实现 CRAG 时,喜欢用 LangGraph 画出复杂的节点和状态流转图,维护起来非常麻烦。在踩过这个坑之后,我们最终选择了 LangGraph 1.0 的 middleware(中间件)模式。它能在模型调用前直接拦截请求,一站式完成检索、评估、纠正的全流程,无需手动管理状态图,代码简洁、可读性高,出问题也容易排查。
整个流程分为四步:
- 检索:从 Milvus 获取 Top-3 相关文档,自动实现租户隔离。
- 评估:使用轻量级模型完成三元判决,判断文档质量。
- 纠正:根据判决结果,执行精炼文档、补充搜索或兜底替换策略。
- 注入:把处理好的上下文,通过动态提示词注入给最终的大模型。
环境变量配置
首先,需要配置必要的 API 密钥。
export OPENAI_API_KEY="your-api-key"
export TAVILY_API_KEY="your-tavily-key"
Milvus Collection 创建
在运行代码前,需要先在 Milvus 中创建 Collection 并定义 Schema(可参考前文 Schema 示例)。
核心代码实现
以下是完整的 CRAG Middleware 实现及 Agent 创建代码:
# filename: crag_agent.py
# ============ 导入依赖 ============
from typing import Literal, List
from langchain.agents import create_agent
from langchain.agents.middleware import AgentMiddleware, before_model, dynamic_prompt
from langchain.chat_models import init_chat_model
from langchain_milvus import Milvus
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_community.tools.tavily_search import TavilySearchResults
# ============ CRAG Middleware(核心实现) ============
class CRAGMiddleware(AgentMiddleware):
"""CRAG 评估与纠正中间件"""
def __init__(self, vector_store: Milvus, agent_id: str):
super().__init__()
self.vector_store = vector_store
self.agent_id = agent_id # 多租户隔离
# 轻量评估器:用于相关性判定
self.evaluator = init_chat_model("openai:gpt-4o-mini", temperature=0)
# Web 搜索托底工具
self.web_search = TavilySearchResults(max_results=3)
@before_model
def run_crag(self, state):
"""在模型调用前执行检索→评估→纠正,准备最终上下文"""
# 获取最后一条用户消息
last_msg = state["messages"][-1]
query = getattr(last_msg, "content", "") if hasattr(last_msg, "content") else last_msg.get("content", "")
# 1. 检索:从 Milvus 获取文档(PartitionKey + 置信度过滤)
docs = self._retrieve_from_milvus(query)
# 2. 评估:三元判决
verdict = self._evaluate_relevance(query, docs)
# 3. 纠正:根据判决决定处理策略
if verdict == "incorrect":
# 检索失败,完全依赖 Web 搜索
web_results = self._web_search_fallback(query)
final_context = self._format_web_results(web_results)
elif verdict == "ambiguous":
# 检索模糊,精炼文档 + Web 搜索补充
refined_docs = self._refine_documents(docs, query)
web_results = self._web_search_fallback(query)
final_context = self._merge_context(refined_docs, web_results)
else:
# 检索质量良好,只精炼文档
refined_docs = self._refine_documents(docs, query)
final_context = self._format_internal_docs(refined_docs)
# 4. 将上下文放入临时键,仅用于“当前模型调用”
state["_crag_context"] = final_context
return state
@dynamic_prompt
def attach_context(self, state, prompt_messages: List):
"""将 CRAG 合成上下文以 SystemMessage 注入到本次模型调用的提示前"""
final_context = state.get("_crag_context")
if final_context:
sys_msg = SystemMessage(
content=f"以下是相关背景信息,请基于这些信息回答用户问题:\n\n{final_context}"
)
# 仅对当前调用生效,不永久写入 state["messages"]
prompt_messages = [sys_msg] + prompt_messages
return prompt_messages
# ======== 内部方法:检索 / 评估 / 精炼 / 格式化 ========
def _retrieve_from_milvus(self, query: str) -> list:
"""从 Milvus 检索文档(Partition Key + 置信度过滤)"""
try:
# 注意:不同版本适配器对过滤参数位置可能不同,这里使用 search_kwargs 传递 expr
docs = self.vector_store.similarity_search(
query,
k=3,
search_kwargs={"expr": f'agent_id == "{self.agent_id}"'}
)
# 置信度过滤(避免低质量记忆污染)
filtered_docs = [
doc for doc in docs
if (doc.metadata or {}).get("confidence", 0.0) > 0.7
]
return filtered_docs or docs # 若无高置信度,退回原结果以便 evaluator 判定
except Exception as e:
print(f"[CRAG] 检索失败: {e}")
return []
def _evaluate_relevance(self, query: str, docs: list) -> Literal["relevant", "ambiguous", "incorrect"]:
"""评估文档相关性(三元判决),简化版:LLM 直接返回 verdict"""
if not docs:
return "incorrect"
# 只评估 Top-3 文档,每个文档取前 500 字符
doc_content = "\n\n".join([
f"[文档{i+1}] {(doc.page_content or '')[:500]}..."
for i, doc in enumerate(docs[:3])
])
prompt = f"""你是文档相关性评估专家。评估以下文档是否能回答查询。
查询:{query}
文档内容:
{doc_content}
评估标准:
- relevant:文档直接包含答案,高度相关
- ambiguous:文档部分相关,需要补充外部知识
- incorrect:文档不相关,无法回答查询
只返回一个词:relevant 或 ambiguous 或 incorrect
"""
try:
result = self.evaluator.invoke(prompt)
verdict = (getattr(result, "content", "") or "").strip().lower()
if verdict not in {"relevant", "ambiguous", "incorrect"}:
verdict = "ambiguous"
return verdict
except Exception as e:
print(f"[CRAG] 评估失败: {e}")
return "ambiguous"
def _refine_documents(self, docs: list, query: str) -> list:
"""精炼文档(简化条带:基于关键词的句子筛选)"""
refined = []
# 简单中文句号替换 + 英文断句的粗切
keywords = [kw.strip() for kw in query.split() if kw.strip()]
for doc in docs:
text = doc.page_content or ""
sentences = (
text.replace("。", "。\n")
.replace(". ", ".\n")
.replace("! ", "!\n")
.replace("? ", "?\n")
.split("\n")
)
sentences = [s.strip() for s in sentences if s.strip()]
# 命中任一关键词
relevant_sentences = [
s for s in sentences
if any(keyword in s for keyword in keywords)
]
if relevant_sentences:
refined_text = "。".join(relevant_sentences[:3])
refined.append(Document(page_content=refined_text, metadata=doc.metadata or {}))
return refined if refined else docs # 若未提取到,回退原文档
def _web_search_fallback(self, query: str) -> list:
"""Web 搜索托底"""
try:
return self.web_search.invoke(query) or []
except Exception as e:
print(f"[CRAG] Web 搜索失败: {e}")
return []
def _merge_context(self, internal_docs: list, web_results: list) -> str:
"""合并内部记忆与外部知识为最终上下文"""
parts = []
if internal_docs:
parts.append("【内部记忆】")
for i, doc in enumerate(internal_docs, 1):
parts.append(f"{i}. {doc.page_content}")
if web_results:
parts.append("【外部知识】")
for i, result in enumerate(web_results, 1):
content = (result or {}).get("content", "")
url = (result or {}).get("url", "")
parts.append(f"{i}. {content}\n 来源: {url}")
return "\n\n".join(parts) if parts else "未找到相关信息"
def _format_internal_docs(self, docs: list) -> str:
"""格式化内部文档"""
if not docs:
return "未找到相关信息"
parts = ["【内部记忆】"]
for i, doc in enumerate(docs, 1):
parts.append(f"{i}. {doc.page_content}")
return "\n\n".join(parts)
def _format_web_results(self, results: list) -> str:
"""格式化 Web 搜索结果"""
if not results:
return "未找到相关信息"
parts = ["【外部知识】"]
for i, result in enumerate(results, 1):
content = (result or {}).get("content", "")
url = (result or {}).get("url", "")
parts.append(f"{i}. {content}\n 来源: {url}")
return "\n\n".join(parts)
# ============ 初始化 Milvus 向量数据库 ============
vector_store = Milvus(
embedding_function=OpenAIEmbeddings(),
connection_args={"host": "localhost", "port": "19530"},
collection_name="agent_memory"
)
# ============ 创建 Agent ============
agent = create_agent(
model="openai:gpt-4o",
tools=[TavilySearchResults(max_results=3)], # Web 搜索工具
middleware=[
CRAGMiddleware(
vector_store=vector_store,
agent_id="user_123_session_456" # 多租户隔离:每个 Agent 实例使用独立 ID
)
]
)
# ============ 运行示例 ============
if __name__ == "__main__":
# 示例查询:使用 HumanMessage 以保证兼容性
response = agent.invoke({
"messages": [
HumanMessage(content="Nike 最新季度财报中的运营成本是多少?")
]
})
print(response["messages"][-1].content)
评估器的进阶优化
上面的 _evaluate_relevance() 方法是简化实现,适合快速验证。如果你需要更完善、包含置信度和推理过程的评估器,可以参考以下基于 Pydantic 的结构化输出实现:
from pydantic import BaseModel
from langchain.prompts import PromptTemplate
class RelevanceVerdict(BaseModel):
"""评估结果的结构化输出"""
verdict: Literal["relevant", "ambiguous", "incorrect"]
confidence: float # 置信度分数(用于记忆质量监控)
reasoning: str # 判断理由(用于调试和审核)
# 注意:CRAG 论文使用微调的 T5-Large 评估器(10-20ms 延迟)
# 这里使用 gpt-4o-mini 作为工程实现方案(更易部署,但延迟略高)
grader_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
grader_prompt = PromptTemplate(
template="""你是文档相关性评估专家。评估以下文档是否能回答查询。
查询:{query}
文档内容:
{document}
评估标准:
- relevant:文档直接包含答案,置信度 > 0.9
- ambiguous:文档部分相关,置信度 0.5-0.9
- incorrect:文档不相关,置信度 < 0.5
返回 JSON 格式:{{"verdict": "...", "confidence": 0.xx, "reasoning": "..."}}
""",
input_variables=["query", "document"]
)
grader_chain = grader_prompt | grader_llm.with_structured_output(RelevanceVerdict)
# 替换 CRAGMiddleware 中的 _evaluate_relevance() 方法
def _evaluate_relevance(self, query: str, docs: list) -> Literal["relevant", "ambiguous", "incorrect"]:
"""评估文档相关性(返回结构化结果)"""
if not docs:
return "incorrect"
# 只评估 Top-3 文档,每个文档取前 500 字符
doc_content = "\n\n".join([
f"[文档{i+1}] {doc.page_content[:500]}..."
for i, doc in enumerate(docs[:3])
])
result = grader_chain.invoke({
"query": query,
"document": doc_content
})
# 将置信度存储到日志或监控系统
print(f"[CRAG 评估] verdict={result.verdict}, confidence={result.confidence:.2f}")
print(f"[CRAG 推理] {result.reasoning}")
# 可选:将评估结果存储到 Milvus,用于记忆质量分析
self._store_evaluation_metrics(query, result)
return result.verdict
def _store_evaluation_metrics(self, query: str, verdict_result: RelevanceVerdict):
"""存储评估指标到 Milvus(用于记忆质量监控)"""
# 示例:将评估结果存储到单独的 Collection 用于分析
# 实际使用时需要创建 evaluation_metrics Collection
pass
CRAG 生产部署的核心建议
当你准备将 CRAG 系统部署到生产环境时,建议重点关注以下三个层面:
第一,成本控制:评估器的选型是关键
评估器是 CRAG 流程中调用最频繁的环节,选型直接决定系统延迟和运营成本。对于高并发线上场景,应优先考虑微调 T5-Large 这类轻量级专用模型,延迟可控制在 10-20ms,成本可控。对于快速验证或小流量场景,则可使用 GPT-4o-mini 等托管模型,部署快捷,但需接受更高的延迟和调用成本。
第二,可观测性:搭建完善的监控体系
看不见的问题最致命。幸运的是,Milvus 原生支持 Prometheus 指标导出,应重点监控 milvus_query_latency_seconds(查询延迟)、milvus_search_qps(查询吞吐量)、milvus_insert_throughput(写入吞吐量)等核心指标。同时,必须将 CRAG 自身的评估判决分布、Web 搜索触发率、置信度分布等业务指标也接入监控系统,以便快速定位问题是出在检索层、评估层还是其他环节。
第三,长期治理:建立机制严防记忆污染
Agent 系统运行时间越久,知识库中积累的低质量或过期“记忆”就越多。必须提前建立治理机制:
- 前置过滤:在检索时即通过
expr='metadata["confidence"] > 0.7' 之类的表达式,只返回高置信度记忆。
- 时间衰减:为记忆添加时间戳,并在检索排序时引入衰减函数(如按 30 天半衰期降低权重),避免过期内容长期占据前列。
- 定期清理:设置定时任务,定期(如每周)扫描并删除低置信度、长期未被验证或已过期的记忆条目,为知识库“瘦身”,从根源上切断记忆污染的恶性循环。
通过上述方法,你可以构建一个既智能又可靠的 RAG 系统。CRAG 架构与 Milvus 这类高性能向量数据库的结合,为应对复杂、动态的知识检索需求提供了坚实的工程基础。希望这篇来自云栈社区的分享,能为你解决 Embedding 相似度虚高的问题带来切实可行的思路。
 发表于 2026-3-12 08:22:19
|
查看: 140|
回复: 0
发表于 2026-3-12 08:22:19
|
查看: 140|
回复: 0
