在开发大多数智能体(Agent)系统时,对记忆(Memory)的处理方式往往比较简单直接。常见的实现无外乎两种:
方式一:直接保存历史对话,下次对话时原封不动地塞给大模型。
方式二:将对话内容存入向量数据库,再次对话时通过向量检索把相关内容召回,并放回模型上下文。
乍一看,这两种设计确实解决了两个基础问题:
- 模型能够访问历史信息。
- 对话能够保持一定的连续性。
然而,当Agent系统开始承担更复杂的任务时,这种设计的局限性就暴露无遗了:这种所谓的“记忆”,本质上只是对上下文窗口的补充,远非一个系统级的记忆体系。
当Agent的能力从简单的“对话”扩展到“执行多任务”时,系统需要的远不止是“回忆信息”。它必须能够管理:
- 长期任务状态——那份市场分析报告,究竟写到哪一步了?
- 执行策略——用户要订会议室,到底应该优先选择哪一间?
- 用户上下文——当前这位用户,是喜欢简洁回复,还是需要详细说明?
- 历史经验——上次采用类似的方案执行任务,是不是失败了?
这些信息在生命周期、访问方式以及重要程度上都完全不同。如果仍然用统一的文本记忆加上向量检索来硬扛,系统很快就会面临三个棘手问题:
第一,记忆规模失控,上下文窗口的成本将难以承受。
第二,记忆混成一团,系统难以分辨什么才是真正重要的信息。
第三,系统无法形成长期、稳定的行为能力,每次任务都可能让模型从头开始规划一遍。
这背后其实反映了一个普遍的认知偏差:我们习惯性地将“记忆”视为普通的数据存储,却忽略了它本质上是支撑智能体长期、连贯行为的系统级记忆体系。这也是许多Agent系统在复杂场景下表现不稳定的根本原因。
因此,讨论Agent记忆时,我们真正要解决的并非“如何让模型记住更多信息”,而是 “如何为Agent设计一套能支撑其长期、复杂行为的记忆体系” 。接下来,我们将从架构设计的角度,探讨一套完整的Agent记忆体系该如何构建。
一、Agent记忆的基本分类
在实际系统中,Agent的记忆并非单一结构,而是由多种类型的信息复合而成。这些信息在作用、生命周期以及访问方式上存在显著差异。如果将所有信息都统一存储为文本,再通过向量检索进行召回,很难支撑复杂系统的稳定运行。
因此,在架构设计上,记忆通常需要进行分层组织。一个清晰的划分框架,是将Agent的记忆分为以下五类:
1. Context Memory(上下文记忆)
Context Memory用于维护当前推理过程的即时上下文信息,例如:
- 最近几轮对话内容。
- 当前任务的中间推理结果。
- 工具调用后的即时反馈。
这类记忆具有几个明显特点:
- 生命周期极短(秒级到分钟级)。
- 更新频率非常高。
- 通常直接进入模型的上下文窗口。
在实现上,一般通过对话缓存或滑动窗口来管理,并受到Token预算的严格控制。
2. Task Memory(任务记忆)
当Agent开始执行复杂任务时,仅依赖对话上下文是远远不够的。系统需要记录任务执行过程中的结构化状态,例如:
- 当前任务目标。
- 已完成步骤。
- 未完成任务。
- 各步骤的执行结果。
示例:
- 任务:生成市场分析报告
- 步骤1:收集数据(状态:完成)
- 步骤2:数据分析(状态:进行中)
- 步骤3:生成报告(状态:未开始)
这些信息如果仅仅混杂在自然语言对话中,很容易被后续的对话内容淹没或覆盖。因此,在Agent系统中,Task Memory应该以结构化的状态形式进行管理,而非简单的文本。
3. User Memory(用户记忆)
对于需要提供持续、个性化服务的Agent而言,用户相关的信息也需要被系统地记录,例如:
- 用户偏好(如回复风格、详细程度)。
- 历史执行过的任务。
- 用户的使用习惯。
- 个性化的系统配置。
这些信息通常具有长生命周期,并且会在多个不同的任务之间被重复使用。如果每次任务都要让模型重新理解这些信息,不仅效率低下,还容易导致Agent行为不一致。因此,User Memory通常独立于对话系统进行管理,并在任务需要时注入到上下文中。
4. Knowledge Memory(知识记忆)
Agent在执行任务时,经常需要访问外部知识,例如:
- 产品文档、说明书。
- 业务数据库中的信息。
- 公司内部的业务流程与规则。
- 相关的历史资料与报告。
这类信息本质上属于系统的知识存储层。Knowledge Memory通常由RAG(检索增强生成)系统来承担,其特点是:
- 数据规模可能非常大。
- 更新频率相对较低(与对话相比)。
- 主要通过语义检索或关键词过滤来获取。
因此,它通常由向量数据库或专门的检索系统进行管理。
5. Experience Memory(经验记忆)
当Agent长期运行时,它会逐渐积累自己的执行经验,例如:
- 哪些任务规划策略更有效?
- 哪些工具调用组合或参数设置容易导致失败?
- 在不同场景下,完成任务的最佳流程是什么?
这些经验信息如果能够被记录和复用,可以显著提升系统的稳定性和效率。与静态的知识库不同,Experience Memory的来源是系统自身的执行历史。例如:
- 成功任务的完整执行路径。
- 任务失败的具体原因分析。
- 经过优化验证后的高效执行策略。
这部分记忆甚至会成为驱动系统持续自我优化的重要数据来源。
二、五类记忆的协同机制
在实际运行中,这五类记忆并非孤立存在。它们围绕Agent的一次任务执行周期,形成完整的数据流动闭环。下图展示了一次典型的复杂任务中,各类记忆是如何被调用和更新的:
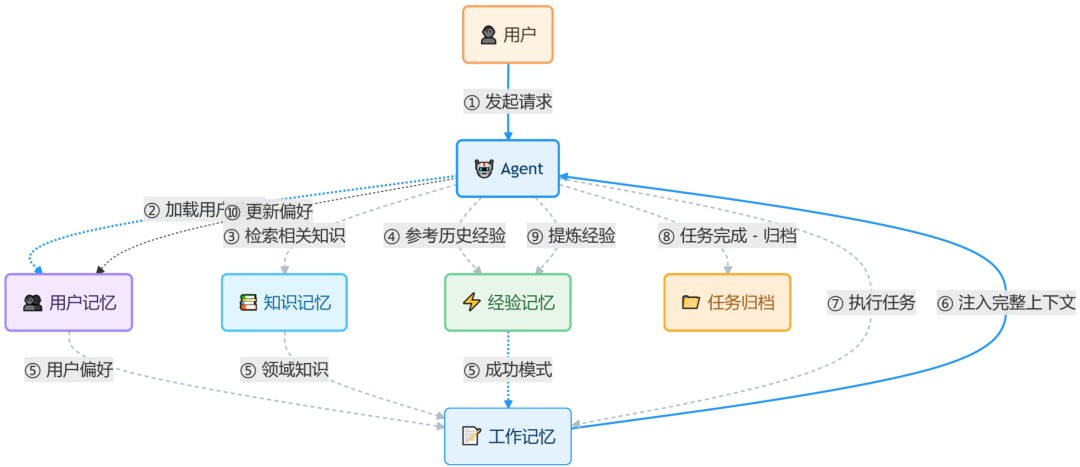
协同流程说明:
1. 任务启动阶段(记忆加载)
- Agent收到用户请求后,首先从 User Memory 加载该用户的偏好和历史上下文。
- 根据任务类型,从 Knowledge Memory 检索相关的领域知识。
- 从 Experience Memory 中查找类似任务的成功执行模式或失败教训。
- 所有这些被检索到的信息,共同加载到“工作记忆”区,形成本次任务的完整初始化上下文。
2. 任务执行阶段(状态流转)
- Context Memory 负责维护当前对话的实时状态(多轮交互内容)。
- Task Memory 则记录任务的进度、步骤结果等结构化状态。
- 两者在“工作记忆”区动态交互与更新,确保Agent随时了解“任务现在进行到什么程度”,并做出连贯的决策。
3. 任务完成阶段(记忆沉淀)
- 任务结束后,完整的执行过程经过压缩和总结,被存入 Task Memory 进行归档。
- 本次任务中成功的经验或失败的教训,被提炼出来,更新到 Experience Memory。
- 如果在任务中发现了用户新的偏好或行为模式,则同步更新 User Memory。
三、记忆的生命周期管理
明确了记忆的分类与协同,下一个需要解决的是记忆的演进问题。不同类型的记忆拥有截然不同的生命周期,我们需要为每一类设计合适的“创建、更新、归档、销毁”机制。
各类记忆的生命周期策略:
1. Context Memory(秒级-分钟级)
- 创建:当新的对话会话开始时创建。
- 更新:每轮对话后实时更新。
- 销毁:会话结束后,或经过总结压缩后清空。
- 管理策略:滑动窗口 + Token预算控制。
2. Task Memory(分钟级-小时级)
- 创建:当识别出一个新任务时创建。
- 更新:任务每完成一个步骤或子目标时更新状态。
- 归档:任务彻底结束后,将关键过程和结果压缩存储,以备历史查询。
- 管理策略:状态机 + 检查点(Checkpoint)机制。
3. User Memory(持久化)
- 创建:用户首次与系统交互时创建基础档案。
- 更新:系统通过显式(用户设置)或隐式(行为分析)反馈发现新偏好时更新。
- 维护:定期校验和清理可能过时或矛盾的信息。
- 管理策略:版本控制 + 显式/隐式反馈结合。
4. Knowledge Memory(持久化)
- 创建:知识库在系统初始化或接入时创建。
- 更新:知识内容发生变更时,通过异步任务进行增量或全量更新。
- 管理策略:向量索引构建 + 元数据过滤。
5. Experience Memory(长期演进)
- 创建:任务成功或失败时,创建对应的经验记录。
- 更新:当出现更优的新模式,或对旧经验有新的归纳时更新。
- 提炼:定期对积累的历史经验进行聚类、归纳和总结,形成更高阶的“策略”。
- 管理策略:强化学习反馈 + 经验回放(Experience Replay)机制。
四、记忆的存取策略
有了清晰的分类和生命周期管理,我们还需要解决一个实际问题:在具体任务中,系统该如何决定调用哪类记忆? 这涉及到记忆系统的智能查询与路由策略。
基于任务特征的自动路由
系统需要能够解析当前任务的上下文,自动判断需要加载哪些类型的记忆。以下是一个路由逻辑的伪代码示例:
# 伪代码示例:记忆系统的查询路由
class MemoryRouter:
def retrieve_for_task(self, task_context, user_id):
retrieved_memories = {}
# 1. 始终加载用户基础信息
retrieved_memories['user'] = self.user_memory.get(user_id)
# 2. 提取任务的多维度特征
task_features = self._extract_task_features(task_context)
# 返回示例:{
# 'requires_knowledge': True,
# 'is_complex': True,
# 'has_history': True,
# 'domain': 'finance',
# 'task_type': 'analysis'
# }
# 3. 基于特征组合选择性加载记忆
# 知识类任务:检索相关知识
if task_features.get('requires_knowledge'):
retrieved_memories['knowledge'] = self.knowledge_memory.search(
query=task_context.query,
domain=task_features.get('domain'), # 限定领域
top_k=5
)
# 复杂任务:需要历史经验参考
if task_features.get('is_complex'):
retrieved_memories['experience'] = self.experience_memory.find_similar_tasks(
task_context=task_context,
task_type=task_features.get('task_type'),
min_success_rate=0.7,
limit=3
)
# 延续性任务:加载历史进度
if task_features.get('has_history'):
# 判断是哪种历史延续
if task_features.get('task_type') == 'report_generation':
# 报告生成类任务:加载之前写到的部分
retrieved_memories['task_progress'] = self.task_memory.get_task_progress(
task_id=task_context.task_id,
user_id=user_id
)
else:
# 普通历史任务:加载最近的任务记录
retrieved_memories['task_history'] = self.task_memory.get_recent_tasks(
user_id=user_id,
task_type=task_features.get('task_type'),
limit=5
)
# 4. 如果是特定领域,加载领域专属知识
if task_features.get('domain') in ['finance', 'medical', 'legal']:
domain_memory = self.domain_memory.get(
domain=task_features.get('domain'),
user_id=user_id
)
if domain_memory:
retrieved_memories['domain'] = domain_memory
# 5. 合并去重后返回工作记忆
return self.consolidate_to_working_memory(retrieved_memories)
def _extract_task_features(self, task_context):
"""从任务上下文中提取多维特征"""
features = {
'requires_knowledge': self._needs_knowledge(task_context),
'is_complex': self._is_complex_task(task_context),
'has_history': self._has_task_history(task_context),
'domain': self._detect_domain(task_context),
'task_type': self._classify_task_type(task_context)
}
return features
记忆的重要性评分机制
为了避免信息过载,我们需要对检索到的记忆条目进行重要性排序,只将最相关、最重要的信息注入模型的有限上下文窗口。一个常见的评分模型会综合多个维度:
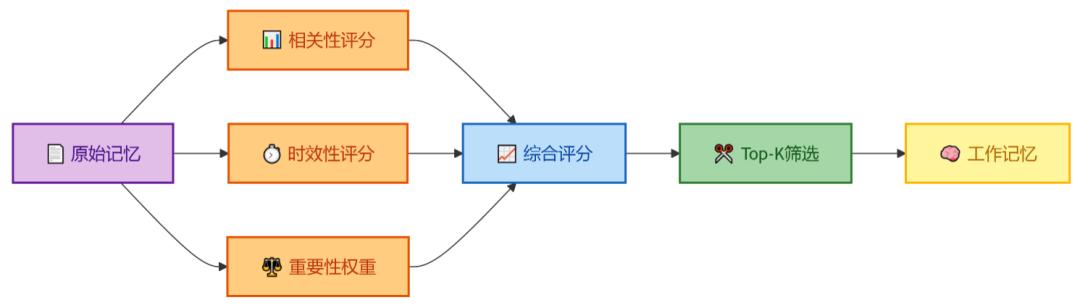
- 相关性评分:基于向量相似度或关键词匹配,计算记忆内容与当前查询的语义相关度。
- 时效性评分:引入时间衰减因子,让越新的记忆获得更高得分,同时可以为不同类型的记忆(如新闻vs.基础知识)设置不同的衰减速率。
- 重要性权重:基于用户行为(如用户手动标记重要)、历史访问频率、或预设的业务规则,为记忆条目打上静态或动态的重要性标签。
最终的综合评分决定了哪些记忆能进入关键的“工作记忆”区。
五、从理论到实践:架构落地建议
最后,我们来谈谈如何在现有的技术架构中落地这套分层记忆设计。以下是一个可供参考的技术栈选型方案:
| 记忆类型 |
推荐存储 |
索引方式 |
访问模式 |
| Context Memory |
Redis |
Key-Value |
实时读写,低延迟 |
| Task Memory |
PostgreSQL / MongoDB |
结构化查询(SQL/NoSQL) |
状态追踪与更新 |
| User Memory |
PostgreSQL + Redis缓存 |
关系模型 |
高频读取,低频更新 |
| Knowledge Memory |
向量数据库(如 Pinecone, Weaviate) |
向量检索 |
相似度语义搜索 |
| Experience Memory |
图数据库(如 Neo4j) / 时序数据库 |
路径查询 / 模式匹配 |
关联分析与策略查找 |
渐进式实施路径
如果你的Agent系统目前还处于早期阶段,无需追求一步到位。可以按照以下路径渐进式演进:
第一阶段:基础分层
- 先把Context Memory(对话上下文)和Task Memory(任务状态)从逻辑和存储上分开管理。
- 引入简单的User Memory,用于存储用户配置和基础偏好。
第二阶段:引入结构化记忆与知识库
- 建立Task Memory的完整状态管理机制(创建、更新、查询、归档)。
- 将知识库从全文检索迁移到向量检索,构建真正的Knowledge Memory层。
第三阶段:经验沉淀与初步优化
- 开始系统性地记录成功与失败的任务轨迹。
- 构建简单的经验回放(Experience Replay)机制,使Agent能在类似任务中参考历史经验。
第四阶段:智能优化与自治
- 基于积累的Experience Memory,引入规则或学习算法来优化任务规划策略。
- 探索强化学习等机制,实现系统的持续自我优化。
总结
通过将Agent的记忆系统设计为由Context、Task、User、Knowledge、Experience五类构成的分层结构,并配合精细的生命周期管理与智能的存取路由策略,我们才能让Agent真正具备支撑长期、复杂、个性化行为的记忆能力。
这种架构设计的核心价值在于:
- 解耦:不同类型的信息采用最适合其特性的存储、索引和访问方式,物尽其用。
- 可扩展:各记忆层可以相对独立地演进、优化和扩容。
- 可观测:记忆的创建、流转、使用和沉淀过程变得清晰可控,便于调试和优化。
- 持续进化:系统能够将执行经验沉淀下来,并反哺到未来的决策中,形成良性循环。
最终,一个配备了完善记忆体系的Agent,将不再是一个每次任务都近乎“从头开始”的对话工具,而是一个能够积累经验、适应个性、不断优化其行为模式的真正智能体。对于更深入的Agent架构与实践讨论,欢迎在技术社区进行交流。
 发表于 2026-3-15 01:02:30
|
查看: 200|
回复: 0
发表于 2026-3-15 01:02:30
|
查看: 200|
回复: 0
