其实这篇分析成文已经有两个月了,恰好最近NVIDIA的GTC大会临近,关于这个话题的讨论又热了起来,索性重新发出来和大家探讨。
之前的一篇文章《谈谈那个被NV看上值20B的Groq》主要详细剖析了Groq的微架构和互连设计,仅在文末简要提及了NVIDIA如何吸收其技术。最近在X上, @XpeaGPU 也讨论了一个相关的业界传闻[1]:NVIDIA将在代号为“Feynman”的下一代产品中,通过3D堆叠技术集成Groq的LPU模块。
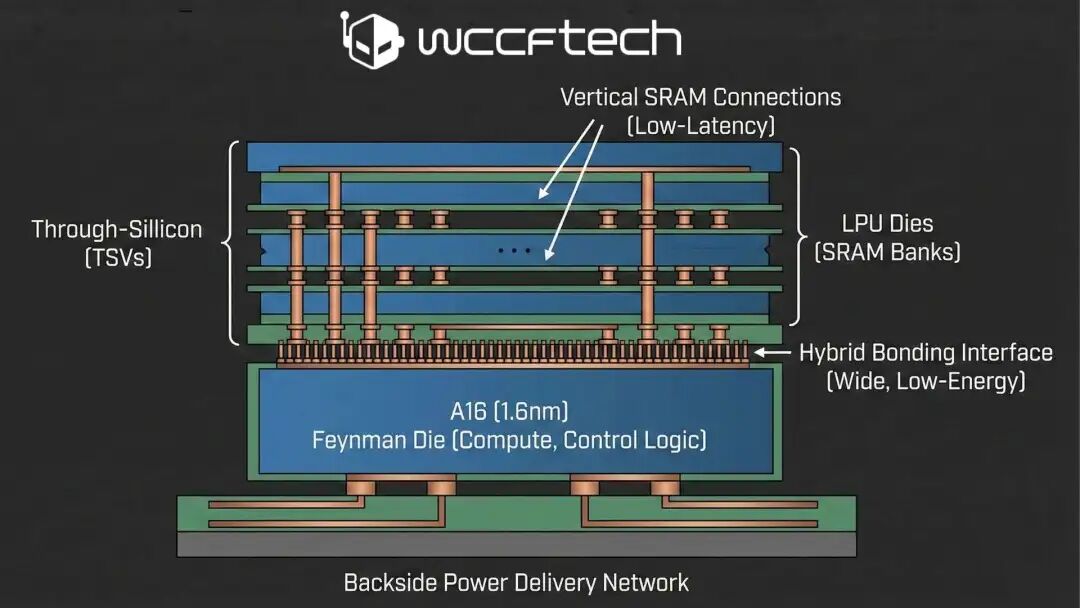
那么,NVIDIA究竟看中了Groq LPU的什么?两者融合的路径又会是怎样的?我们需要从根源上回答几个核心问题:
- Groq LPU相对于NVIDIA GPGPU,在性能、功耗和面积(PPA)上的优势源自何处?
- 两者在指令集层面应如何整合?
- 内存系统与芯片互连又该如何设计?
本文将从这几个维度展开详细分析。
1. Groq LPU的PPA优势来源
1.1 数据路径设计
1.1.1 以320B向量为“一等公民”
在Groq LPU中,数据路径的核心是320B宽的向量。这个320B向量由20个“超级通道”(Superlane)构成,每个通道4个存储体(Bank),每个存储体4字节。

芯片内部的数据流主要在东西方向(水平)传输,形成了简洁高效的数据通路。
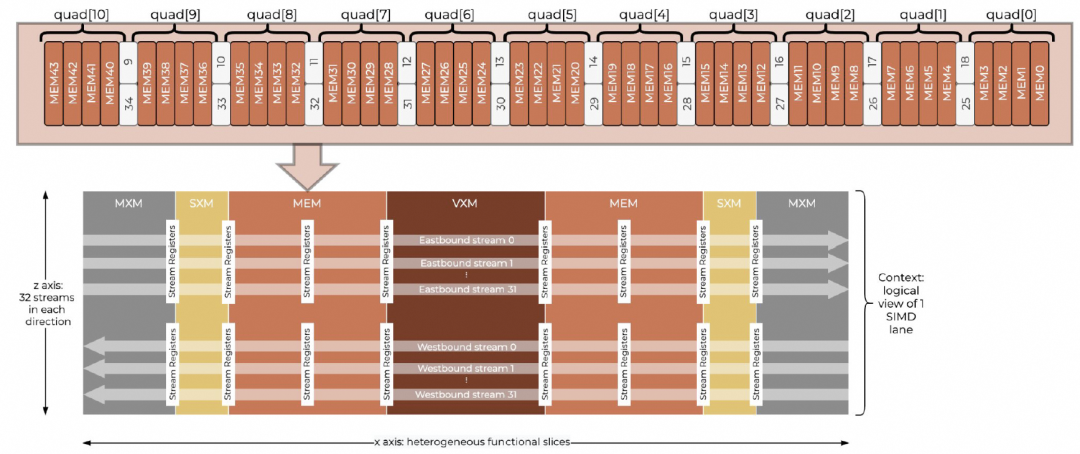
相比之下,NVIDIA的GPGPU由于SIMT(单指令多线程)执行模型的设计,其流多处理器(SM)到全局交叉开关(Global XBAR)的数据位宽通常为32B,二级缓存(L2 Cache)的位宽为128B。从内存访问效率来看,Groq LPU的宽向量设计更具优势,并且其整个数据路径的位宽是对齐且统一的。
1.1.2 简化片上网络:消除复杂的2D路由
Groq LPU的所有数据流向被限定在东西方向。这意味着整个片上数据流和数据流生命周期管理变得相对简单,无需处理复杂2D网格网络中的路由问题。对于任何潜在需要南北向(垂直)流动的数据,则由专门的移位/置换单元(SXM)通过Shuffle或Transpose操作来完成。
这种设计带来一个潜在好处:基本无需考虑数据路径上的存储体冲突(bank conflict)问题,也无需处理复杂的交织(swizzle)逻辑。整个数据链路的加载/存储(LD/ST)位宽也非常大。
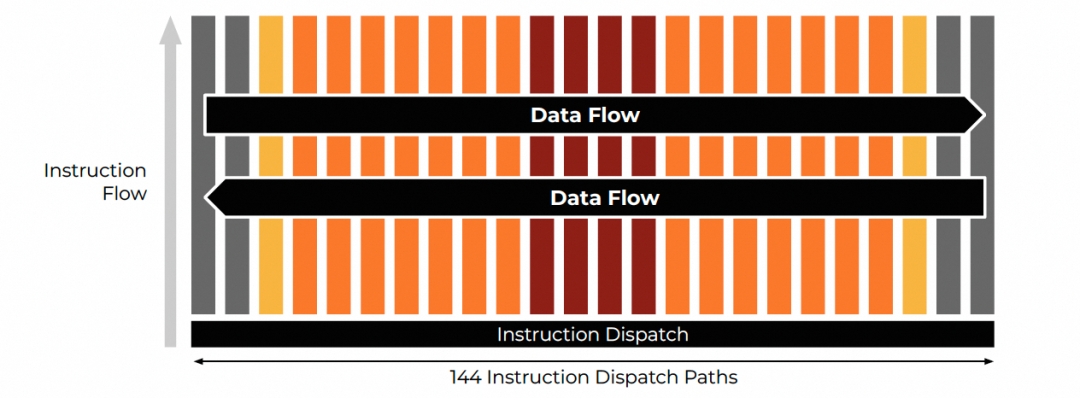
更为巧妙的是,控制指令流恰好是沿着南北方向进行广播和流动的。这样一来,整个芯片的数据流与控制流路由清晰分离,架构显得非常干净。
1.1.3 流式寄存器文件(Streaming RF)
与GPGPU需要在全局内存(GMEM)、共享内存(SMEM)、张量内存(TMEM)和寄存器文件(RF)之间多次显式搬运数据不同,Groq LPU采用了“流式寄存器文件”的设计。

由于计算结果直接保留在寄存器文件中,下一级功能单元在下一个时钟周期即可直接处理,从而大幅减少了数据搬运的功耗和延迟。整个芯片因此不需要复杂片上网络(NoC)和繁琐的多级内存层次来处理数据移动。
1.1.4 确定性的状态机模型
在整个推理过程中,Groq LPU通过一个“流”(Stream)来定义一个确定性的状态机。数据从SRAM中加载,经过矩阵(MXM)、向量(VXM)、移位(SXM)等单元处理后,再写回SRAM,构成一个完整的状态变更周期。
这种确定性模型有一个显著优势:当发生单粒子翻转(SDC)或多位错误(MBE)时,相对于GPGPU,状态恢复要容易得多。从宏观视角看,由于没有太多控制面和数据面的副作用影响,通常只需重新执行(Replay)整个流指令即可。
此外,对于故障后的现场可更换单元(FRU)替换或热迁移也相对简单,只需要将SRAM中的约220MB数据迁移到另一颗芯片即可。
1.2 控制路径设计
1.2.1 高指令效率
320B的向量作为芯片的基本操作单元,在东西方向上构成了一条超长指令字(VLIW),通过在南北方向广播形成单指令多数据流(SIMD)。这相较于NVIDIA的SIMT模型,极大地提高了指令效率。因此,片上不会像NVIDIA GPU那样每个线程都需要独立的译码和指令发射逻辑,而是由一个统一的指令控制单元(Instruction Control Unit)集中处理。
其指令集也针对高维张量的加载/存储操作在内存功能单元(MEM FU)上做了优化,避免了重复的地址生成计算。

1.2.2 静态与确定性调度
由于整个系统是确定性的,每条指令完成的时钟周期是完全可预测的。因此,芯片不需要复杂的动态调度器,也无需为各种复杂的异步操作隐藏流水线延迟。而在NVIDIA GPGPU中,由于指令完成时间的不确定性,寄存器的分配和排布本身就颇具挑战,寄存器溢出(Register Spill)在某些情况下难以避免。
2. NVIDIA如何整合吸收Groq的技术
在X上,@XpeaGPU 的原帖主要阐述了当前SRAM在制程微缩中遇到的瓶颈,以及3D-SRAM堆叠的可能路径。

然而,将Groq LPU与NVIDIA GPGPU架构深度融合,还有更多软硬件细节需要考虑。
2.1 没有Groq技术的3D堆叠方案
首先,假设没有Groq的技术,仅通过3D堆叠能实现什么?一个基本的想法是能否通过逻辑堆叠逻辑(Logic-on-Logic)的方式,构建一个支持双SM的芯片级网关适配器(CGA)?但这会面临供电、功耗控制、散热以及硅通孔(TSV)穿孔等一系列严峻挑战。
那么,类似于AMD的3D V-Cache那样,采用内存堆叠逻辑(Memory-on-Logic)的方式是否可行呢?这或许是条路,但可能无法完全发挥3D集成的潜力。
2.2 Groq LPU在3D堆叠中的独特优势
Groq官方资料显示,由于其执行具有确定性,在功耗和散热优化方面拥有巨大优势。编译器可以在纳秒级别精确分析和预测整个系统的功耗。
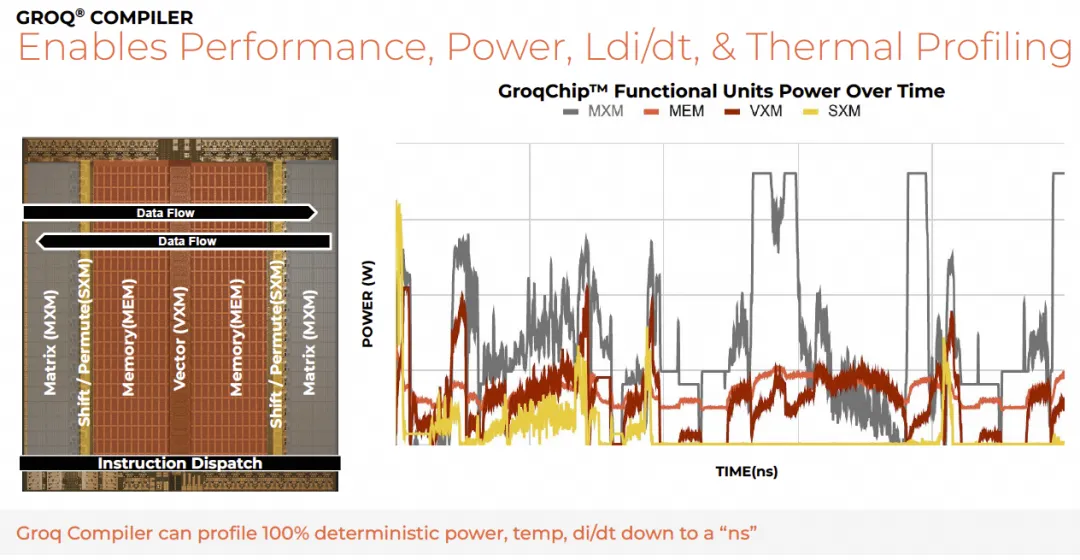
这种能力使得逻辑堆叠逻辑(Logic-on-Logic)的3D集成成为可能,因为可以精确地调度和错开不同芯片上功能单元的工作负载,实现互补的功耗分布,从而管理热密度。
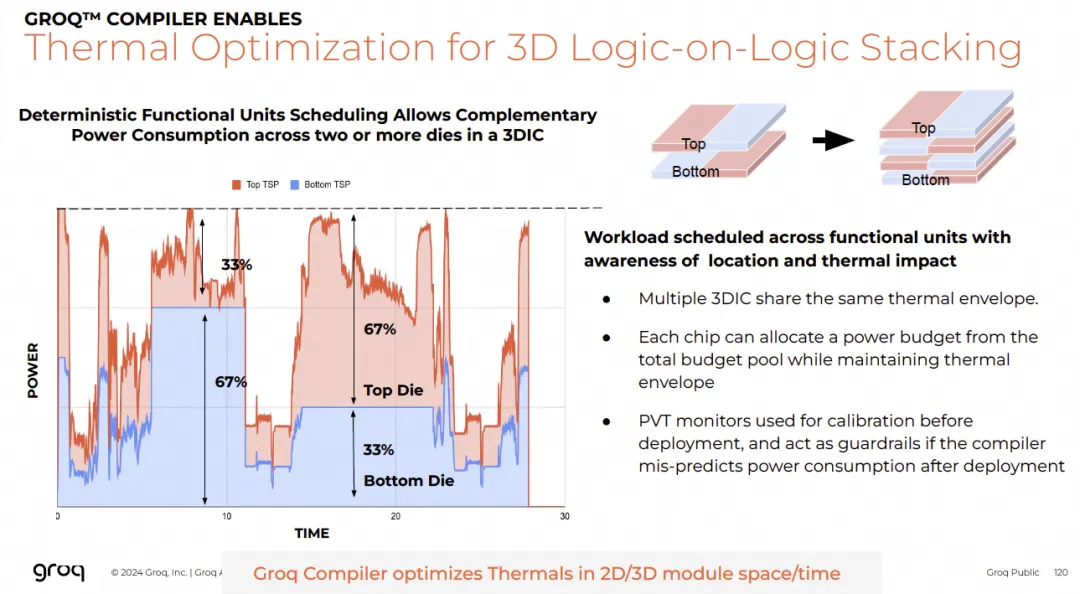
另一方面,Groq架构本身也支持通过3D技术扩展SRAM容量,并通过调整超级通道(Superlane)的数量来灵活支持不同规格的芯片设计,甚至可以以Chiplet或IP的形式进行输出。
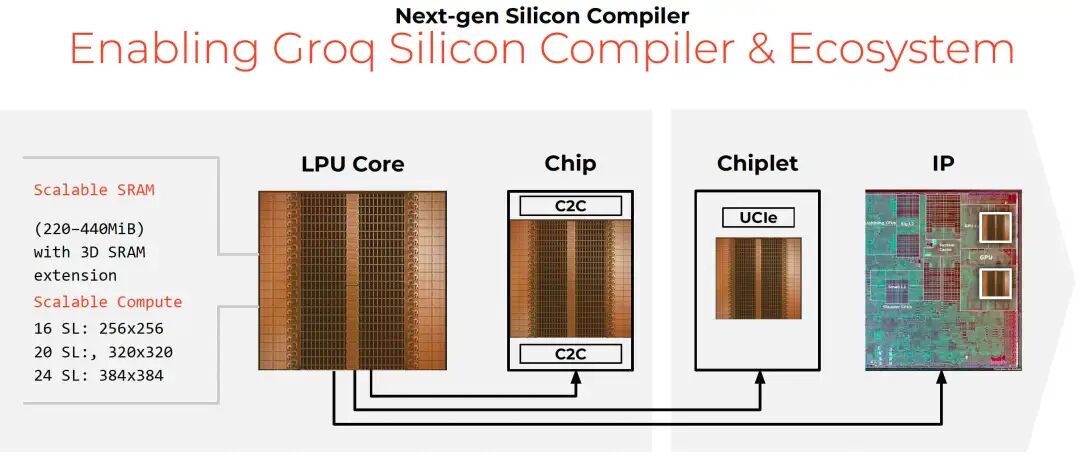
2.3 NVIDIA整合Groq LPU的路径猜想
2.3.1 硬件整合视角
一个实质性的问题是:如何将Groq LPU视为一个“近内存处理”的SRAM来整合?利用其确定性执行特性,我们可以将其看作一个功能增强版的TensorCore。
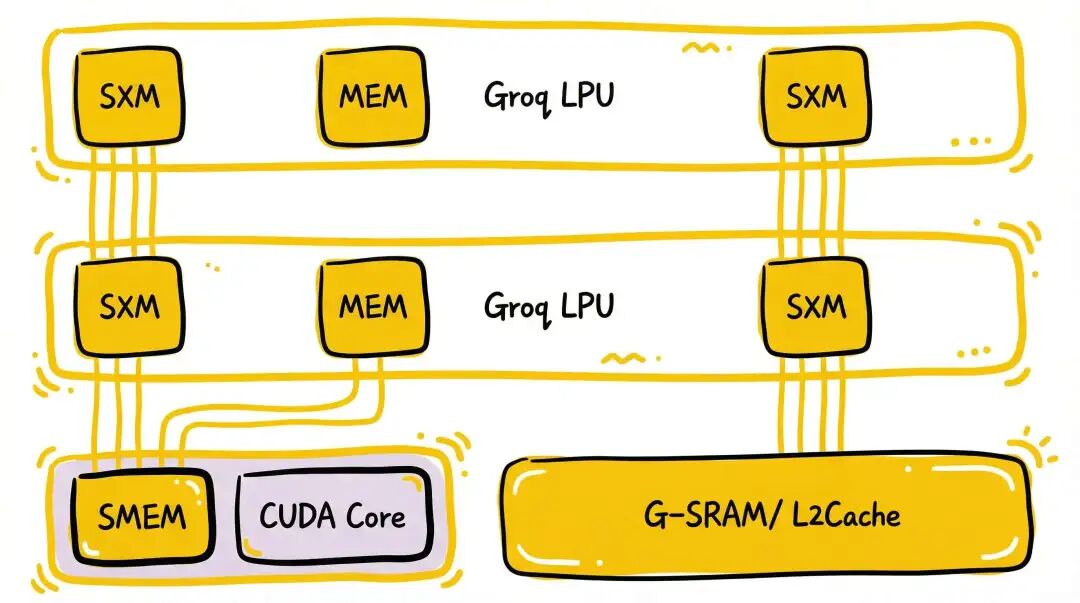
从数据路径看,一种可能的选择是采用16个超级通道(对应256B位宽)来对齐NVLink的带宽。LPU芯片和Feynman主计算芯片之间需要通过SRAM进行连接,以避免加载/存储操作的不确定性。同时,还需要额外的硬件来处理CUDA端的MBarrier与LPU端SYNC/NOTIFY指令之间的交互。
对于NVIDIA GPU微架构而言,一个显著的变化或需求是:在LPU和GPU的HBM之间,需要一片确定性的缓冲空间(DATA FIFO),以避免直接读写DRAM带来的延迟不确定性。这可能需要在全局的L2缓存中划出一块区域作为共享内存(SMEM)空间。
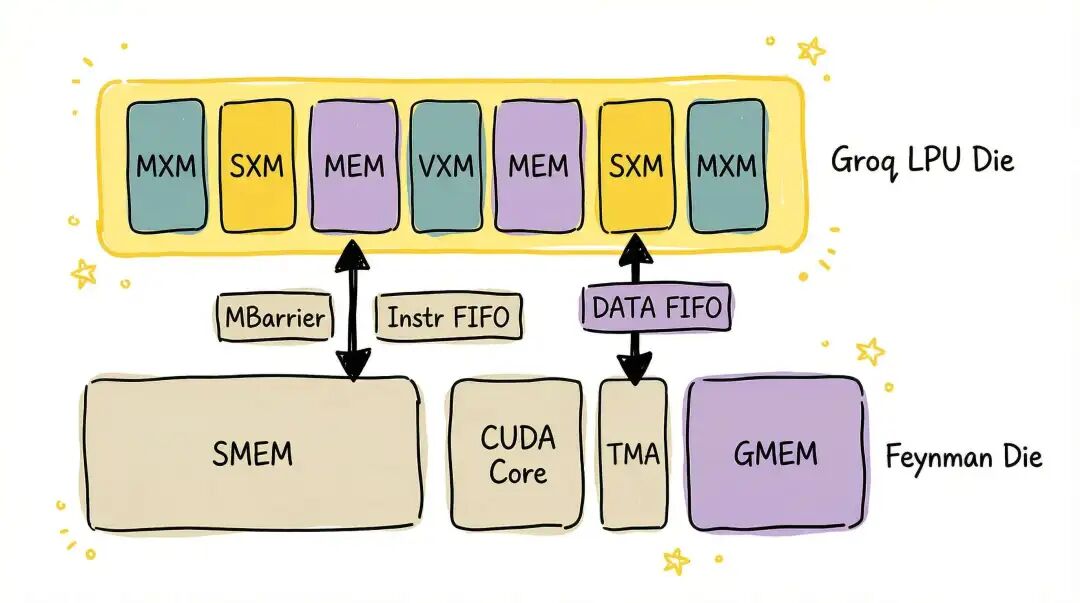
另一方面,考虑到Feynman可能采用的先进封装技术,例如台积电的晶圆级系统(SoW-X),那么在Groq LPU芯片上也可以通过多颗芯片进行D2D互连,进一步扩展规模和带宽。
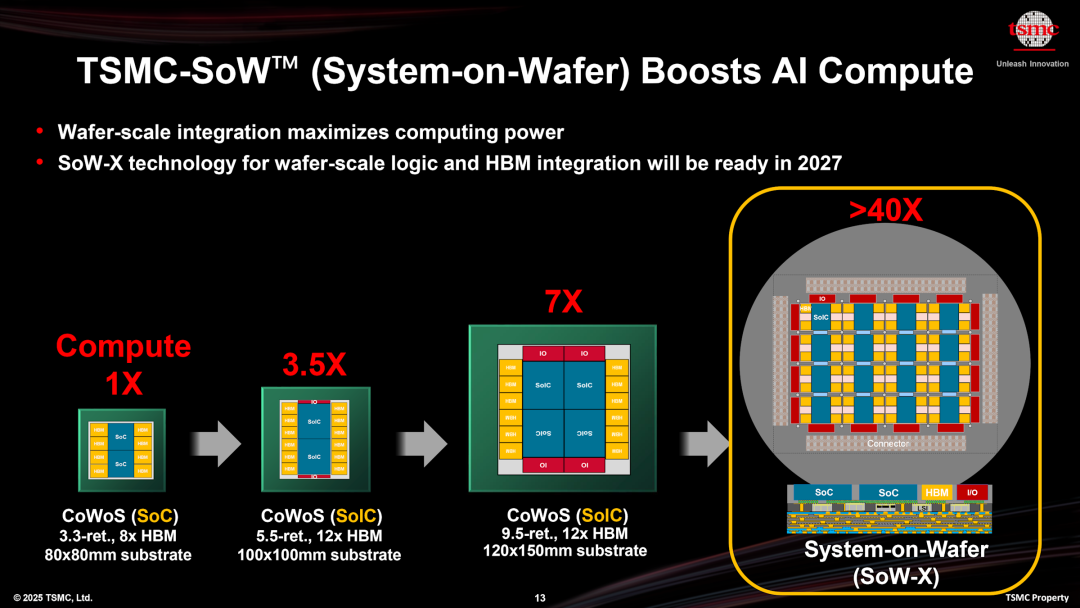
整个封装估计可提供11GB~16GB的Groq LPU SRAM容量。为了保证Groq LPU在芯片内操作的确定性,在设计时需要充分利用NVLink Chip-to-Chip(C2C)技术,同样需要专用的SRAM来构建数据FIFO。
对于跨封装(例如两个Feynman SoW之间)的互连,沿用现有的NVLink Switch架构,所增加的不确定性在可控范围内。
2.3.2 软件整合视角
从软件角度看,算法工程师已经习惯了如NumPy/PyTorch基于张量的计算范式。从实际工作负载来看,传统高性能计算(HPC)中在SIMT上具有优势的微分方程数值求解等应用,在当前主流AI负载中的占比已经很小。事实上,最近出现的一系列领域特定语言(DSL),包括NVIDIA自家的cuTile,都有一个明确的趋势:将张量块(Tensor Tile)作为一等公民,即使是一个标量也被视为 tile<T> 类型。并进一步引入内存排序语义(memory_ordering_semantics)和内存作用域(memory_scope)属性。
因此,Groq LPU编译器可以生成针对LPU硬件优化的内核(Kernel)。对于LPU Kernel所需的数据依赖(例如需要从HBM加载的数据),则由张量内存加速器(TMA)来负责生成和搬运。对于一些LPU难以高效处理的算子,则可以卸载(Offload)到传统的CUDA核心上执行。
整体上,CUDA核心通过MBarrier与LPU芯片进行异步交互。CUDA核心可以根据MBarrier的状态来触发LPU指令的执行。或者,运算完成的数据可以通过LPU的SXM单元拷贝到CUDA核心的SMEM中。同时,SMEM也可以作为一个缓冲区,为LPU的访存操作提供确定性保障。
假设LPU采用16个超级通道对齐256B位宽,那么CUDA端可能需要两个SM来处理与之对接的数据。这部分CUDA核心可以继续沿用现有的计算全局原子(CGA)集群架构来处理。
在云栈社区,我们持续关注此类前沿硬件架构的融合与演进,它们正在重新定义AI计算的效率边界。这种确定性计算与通用可编程性的结合,或许正是下一代AI加速器的关键形态。
参考资料
[1] 关于Feynman集成LPU的传闻: https://x.com/XpeaGPU/status/2005128578045018500
 发表于 2026-3-15 04:08:49
|
查看: 163|
回复: 0
发表于 2026-3-15 04:08:49
|
查看: 163|
回复: 0
