1、CXL 的由来、技术演进与野心
内存墙危机与 CXL 的诞生
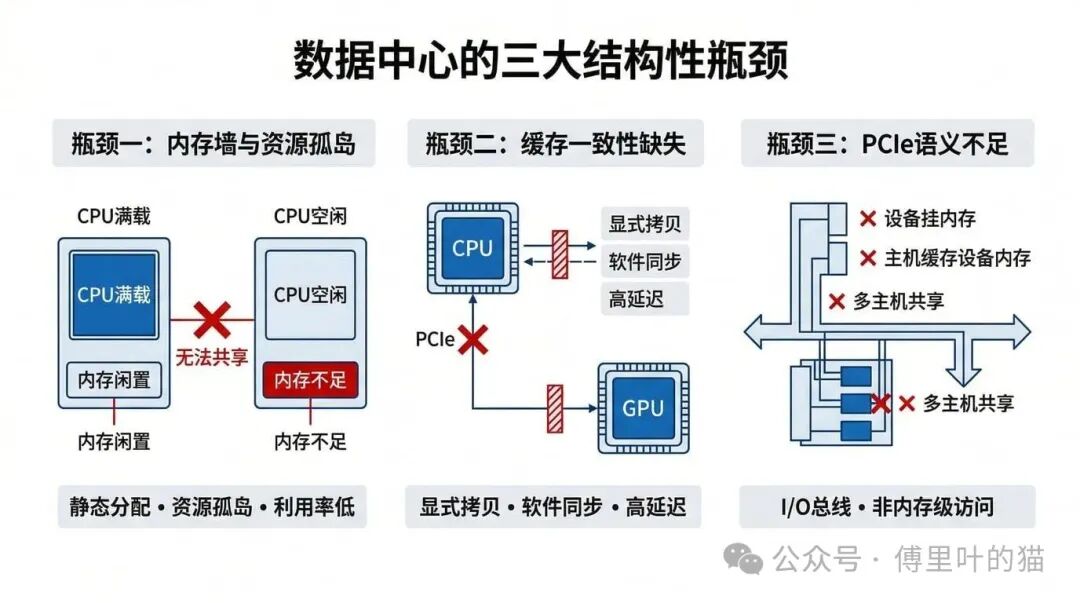
CXL 协议的出现,直接源于数据中心与高性能计算在发展中遇到的三大结构性瓶颈。
瓶颈一:内存墙与资源孤岛
在传统服务器架构中,内存(DRAM)与 CPU 是强绑定、静态分配的。每台服务器的内存容量在出厂时就已固定,无法动态调整。这导致了严重的资源错配:一台机器 CPU 满负载但内存大量闲置,另一台内存不足却无法借用邻近服务器的空闲内存。这种资源孤岛效应使得整体资源利用率低下,总体拥有成本居高不下。
瓶颈二:异构计算的缓存一致性缺失
在 AI 时代,GPU、FPGA、ASIC 等加速器已成为数据中心标配。但传统的 PCIe 协议不支持缓存一致性,CPU 与加速器之间的数据交换必须依赖显式拷贝和软件同步机制。这带来了三个核心问题:高延迟(每次数据传输都需要软件介入)、高编程复杂度(开发者必须手动管理数据一致性)、以及低效率(大量 CPU 周期浪费在数据搬运上)。
瓶颈三:PCIe 带宽与语义不足
PCIe 本质上是一个 I/O 总线,设计初衷是连接外设(如硬盘、网卡),而不是为“内存级访问”设计的。它的语义和带宽都无法满足现代数据中心的需求:无法支持设备直接挂载内存、无法支持主机缓存设备内存、无法支持多主机共享内存池。随着 AI 和大数据应用对内存带宽和容量的需求爆炸式增长,PCIe 的局限性越来越明显。
在 CXL 出现之前,业界其实已经有过多次尝试,例如 IBM 的 OpenCAPI、ARM 的 CCIX,还有 Gen-Z 协议。但这些方案最终都没能形成气候,根本原因在于缺乏足够的产业支持,特别是没有得到像 Intel 这样的市场主导者的认可。
2019 年,局面发生了关键性转变。Intel 做出了一个重要决定:将自己的专有互连规范捐献出来,联合阿里巴巴、思科、戴尔、Meta、谷歌、HPE、华为、微软等九家公司,共同成立了 CXL 联盟。这个协议的设计思路非常务实——基于已经成熟的 PCIe 5.0 物理层,在此之上增加缓存一致性协议。这样做的好处是能最大化地复用现有的 PCIe 生态,显著降低了产业链的接受门槛。
CXL 的技术演进路径
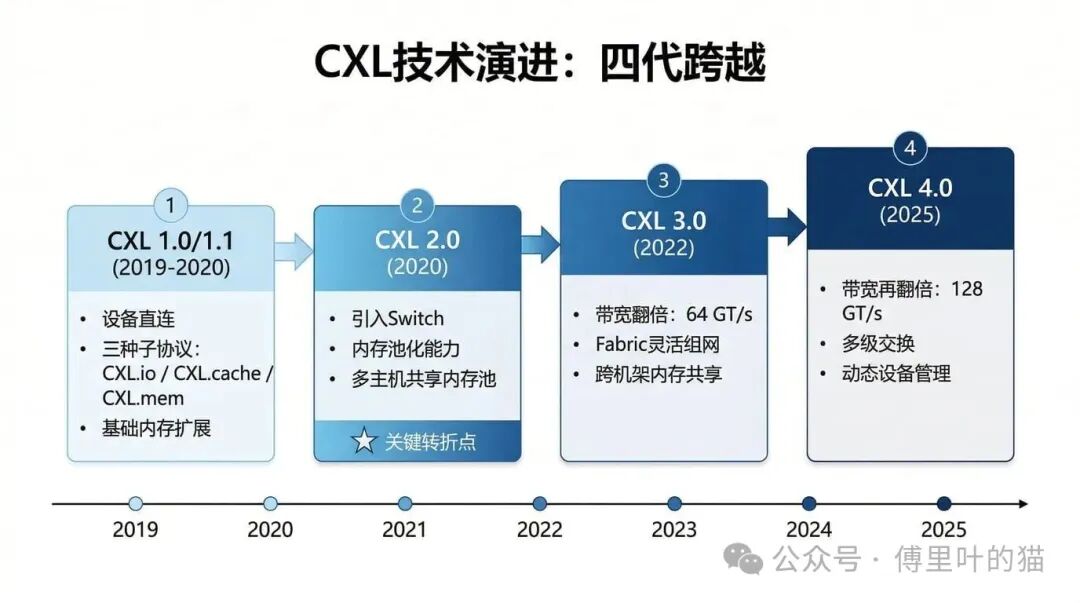
CXL 的发展可以分为四个阶段,每个阶段都在解决不同层次的问题。
CXL 1.0 和 1.1 在 2019 到 2020 年间推出,定义了三种基础协议:CXL.io 负责设备发现和配置,CXL.cache 允许设备访问主机内存,CXL.mem 则让主机可以访问设备内存。这个阶段主要是实现设备直连和基础的内存扩展功能。
真正的转折点是 2020 年的 CXL 2.0。这个版本引入了 Switch 和内存池化能力,支持多个主机共享同一个内存池。这是 CXL 从“内存扩展”走向“内存池化”的关键一步。从架构上看,这意味着内存不再是固定绑定在某台服务器上,而是可以作为一个独立的资源池,按需分配给不同的计算节点。
2022 年的 CXL 3.0 将带宽翻倍到 64 GT/s,并引入了基于 Fabric 的灵活组网能力。这个版本开始支持更大规模的内存池,可以构建跨机架的内存共享架构。
到了 2025 年的 CXL 4.0,带宽再次翻倍到 128 GT/s,增加了多级交换和动态设备管理功能。这些都是针对 AI 时代大规模集群场景所做的针对性优化。
CXL 背后的三大野心
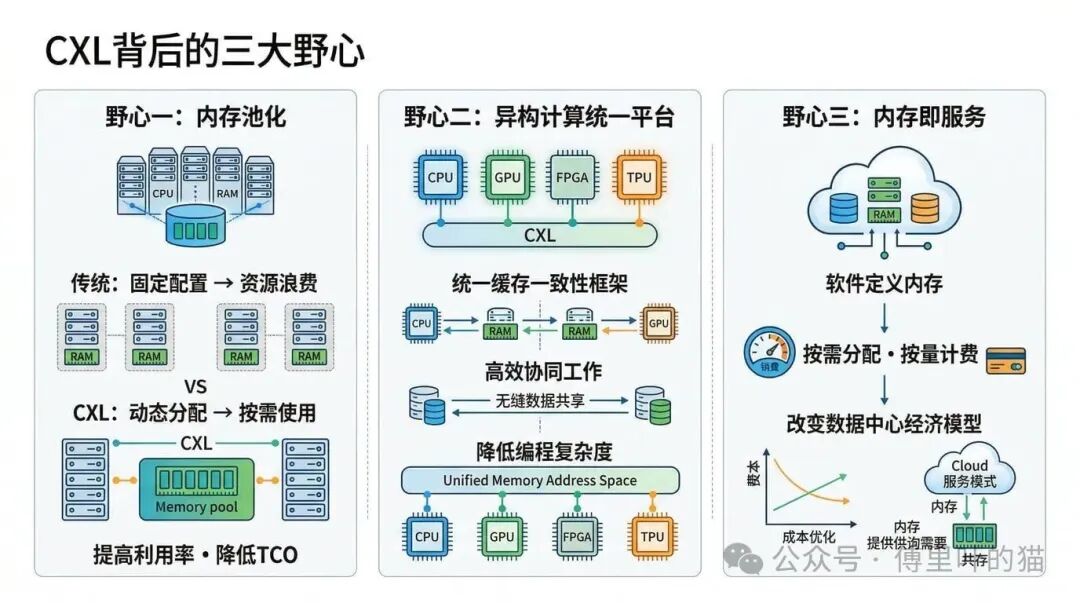
CXL 联盟推动这个标准,背后有着三个层次的目标。
第一个目标是内存池化。传统的服务器配置是固定的,买了多少内存就是多少,用不完是浪费,不够用就只能换机器。内存池化的思路是把内存从服务器上解耦出来,变成一个可以动态分配的资源池。这样可以大幅提高资源利用率,降低总体拥有成本。
第二个目标是为异构计算提供统一平台。现在的数据中心里,CPU、GPU、FPGA、TPU 等各种加速器并存,它们之间的互连和协同一直是个难题。CXL 提供了一个统一的缓存一致性框架,让这些不同架构的芯片可以更高效地协同工作,同时也降低了编程的复杂度。
第三个目标更加长远,是实现软件定义内存和“内存即服务”的商业模式。如果内存可以像云计算资源一样按需分配、按使用量计费,这将在根本上改变数据中心的经济模型。
2、全球科技巨头的 CXL 策略
Intel 与 AMD:开放标准的推动者
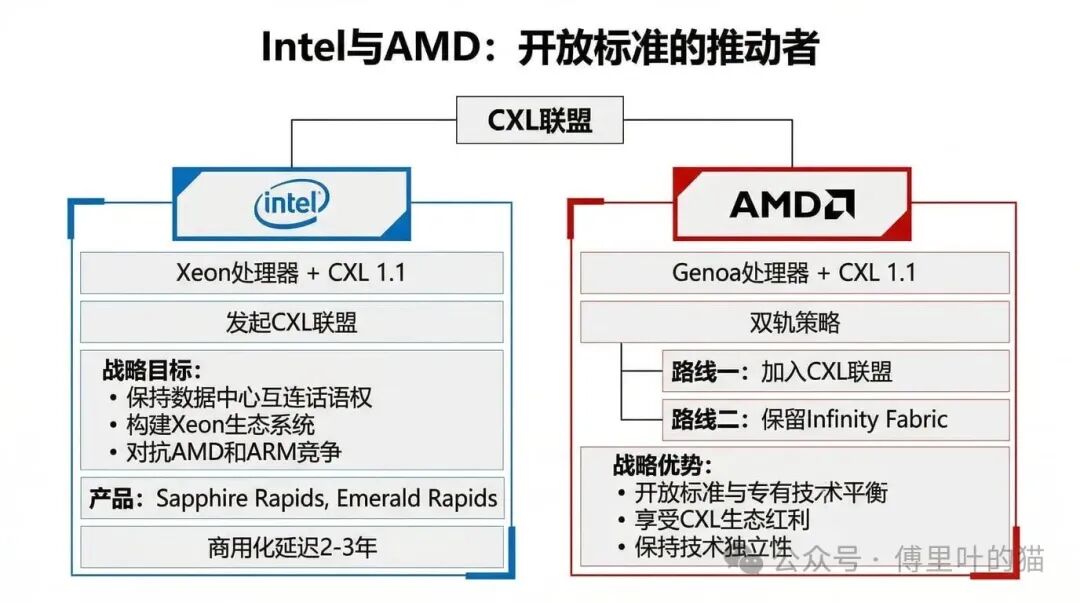
Intel 作为 CXL 联盟的发起者,推动这个标准有着明显的战略考量。在 CPU 市场,Intel 正面临着来自 AMD 和 ARM 的激烈竞争,而在 AI 加速器领域,Nvidia 的 GPU 已经占据了主导地位。通过推动 CXL 这样的开放标准,Intel 可以在数据中心互连层面保持话语权,同时也为自己的 Xeon 处理器构建更大的生态系统。
Intel 的 Sapphire Rapids 和 Emerald Rapids 处理器都支持 CXL 1.1,但市场起量的速度比预期慢了不少。业界普遍认为,CXL 的真正商用化比最初的预期延迟了 2 到 3 年。
AMD 的策略则更加灵活。一方面,AMD 加入了 CXL 联盟,其 Genoa 处理器也支持 CXL 1.1;另一方面,AMD 并没有放弃自己的 Infinity Fabric 专有技术。这种双轨策略让 AMD 在开放标准和专有技术之间保持了平衡,既可以享受 CXL 生态的红利,又不会完全依赖于开放标准。
Nvidia:专有生态的坚守者
Nvidia 对 CXL 的态度一直比较保守,这背后有深层次的原因。
在 GPU 互连方面,Nvidia 有自己的 NVLink 技术,双向带宽可以达到 7200GB/s,远超 PCIe 和 CXL 的性能。在 Grace Hopper 架构中,CPU 和 GPU 之间通过 NVLink-C2C 连接,这种紧密耦合的设计是 CXL 难以替代的。对 Nvidia 来说,保持专有技术的领先性,就是保持生态系统的控制权。
但 Nvidia 并不是完全忽视 CXL。2025 年 9 月,Nvidia 收购了 Enfabrica 的核心团队,其 Vera CPU 支持 CXL 3.1 协议。不过,Nvidia 真正发力的方向是自己的 CMX 方案。
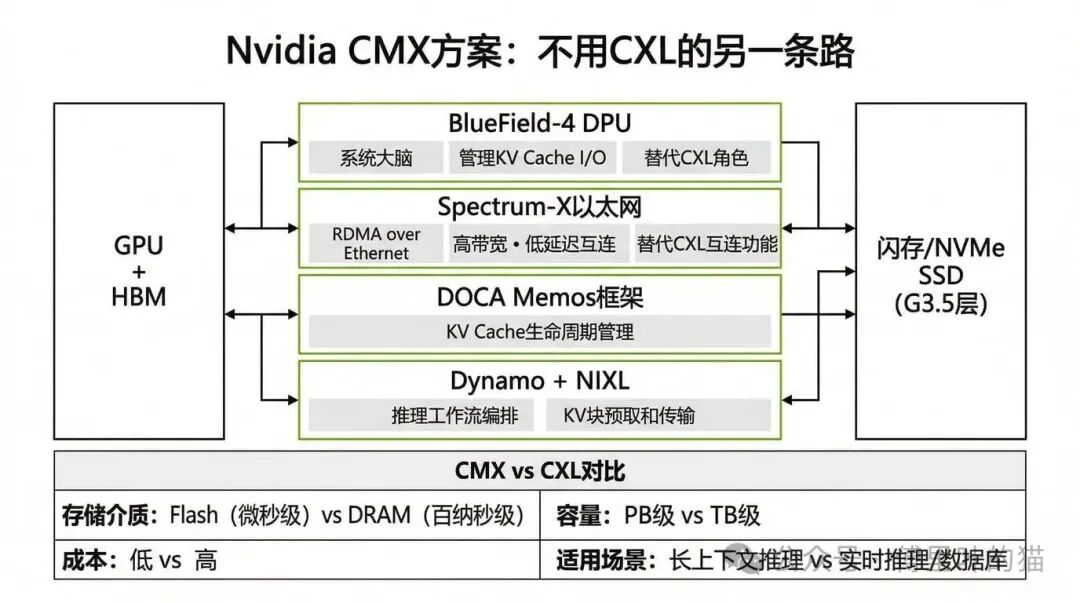
Nvidia 的 CMX 方案:不用 CXL 的另一条路
CMX 的全称是 Context Memory eXtension,这是 Nvidia 针对 AI 推理场景设计的存储层级。随着 Agentic AI 工作流的兴起,上下文窗口被推向百万级 token,KV Cache 的容量需求呈线性增长,而重算的成本增长更快。GPU 的 HBM 虽然性能最好,但价格昂贵、容量有限;传统的对象存储又不适合存储临时的 KV Cache。Nvidia 的解决方案是在 GPU 内存和传统存储之间插入一个新的层级,称为 G3.5 层。
CMX 的核心架构包含四个组件。首先是 BlueField-4 DPU,这是整个系统的大脑,负责管理 KV Cache 的 I/O,实际上替代了 CXL 的角色。其次是 Spectrum-X 以太网,通过 RDMA over Ethernet 提供高带宽、低延迟的互连,这替代了 CXL 的互连功能。第三是 DOCA Memos 框架,负责管理 KV Cache 的生命周期。最后是 Dynamo 和 NIXL,负责编排推理工作流,实现 KV 块的预取和传输。
CMX 与 CXL 方案的核心差异在于存储介质的选择。CMX 使用闪存(Flash/NVMe SSD),延迟在微秒级,但成本低、容量可以做到 PB 级。CXL 方案使用 DRAM,延迟在百纳秒级,但成本高、容量只能做到 TB 级。这两种方案适用的场景不同:CMX 更适合长上下文、多轮对话的场景,可以通过预取来弥补延迟;CXL 更适合实时推理和数据库场景,对延迟的要求更严格。
Nvidia 选择不用 CXL,还有一个重要原因:CXL 是为 CPU 设计的,强调缓存一致性,但 KV Cache 是临时数据,并不需要严格的缓存一致性。用闪存存储 KV Cache,成本更低,容量更大,延迟可以通过智能预取来弥补。更重要的是,通过构建全栈解决方案,Nvidia 可以避免依赖开放标准,保持对生态的控制。
不过,Nvidia 的态度也在发生微妙变化。收购 Enfabrica 团队、Vera CPU 支持 CXL,这些信号表明 Nvidia 至少把 CXL 作为一个备选方案。但从目前看,CMX 仍然是 Nvidia 主推的方向。
谷歌:革命性的 TPU + CXL 方案
TPU v7 的现状
在 2025 年,谷歌的 TPU v7 使用的是 ICI(Inter-Chip Interconnect)互连架构,采用 3D Torus 拓扑,最大可以连接 9216 颗 TPU。这个架构中,OCS(光路交换)负责 TPU 之间的互连,配比大约是 1.2%,也就是说每 100 颗 TPU 配备 1.2 个 OCS 端口。每颗 TPU 配备 192GB 的 HBM3E 板载内存。这个架构中并没有使用 CXL。
TPU v8 的革命性计划
到了 2027 年计划推出的 TPU v8,谷歌打算做一个彻底的架构变革:去除或大幅减少 HBM。
这个决定背后有很现实的考量。HBM 面临严重的产能危机,全球供应短缺,价格高昂,而且依赖台积电的 CoWoS 封装,交付周期很长。更重要的是,HBM 的容量有上限,目前单颗 TPU 只能配 192 到 256GB,这对于万亿参数的模型来说是不够的。
谷歌的解决方案是一个三层解耦架构:计算层是 TPU 芯片(去除或减少 HBM),传输层是 OCS 光交换加上 CXL 协议,存储层是独立的 DRAM 内存机柜。
这个架构中最巧妙的设计是双 CPU 架构。TPU 主板上有一个 CPU(一级 CPU),负责处理算力通信,发起 CXL 内存访问。远端的内存机柜里有另一个 CPU(二级 CPU),专门负责协调内存访问,支持 CXL 协议。这样设计可以避免协议转换带来的效率损失。
OCS 在这个架构中扮演双重角色。它既要负责原有的 TPU 之间的 ICI 互连,又要负责新增的 TPU 到内存池的 CXL 互连。因此,OCS 的配比要从 1.2% 提升到 3%。
这个方案的技术指标是:单 TPU 的内存容量从 192GB 提升到 512GB 甚至 768GB 以上,是原来的 4 倍;延迟目标是控制在 100 纳秒以内,接近 HBM 的水平;性能损失要控制在 2% 以内。
3、中国厂商的 CXL选择
阿里云
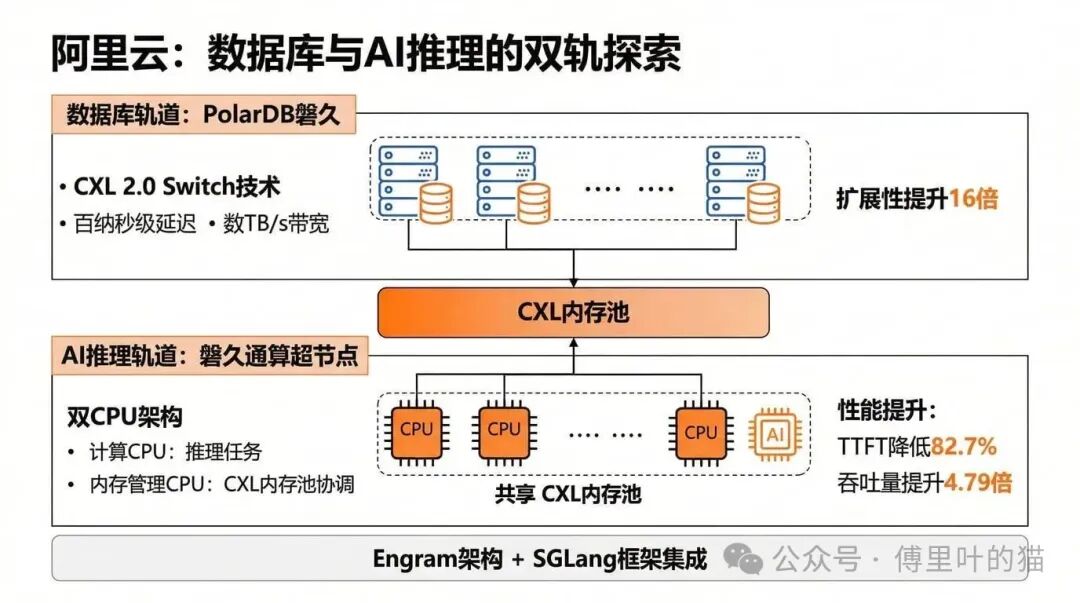
阿里云在 CXL 的应用上走得比较激进,在数据库和 AI 推理两个方向都有深度实践。
PolarDB 磐久 CXL 内存池化服务器
2025 年的云栖大会上,阿里云发布了全球首款基于 CXL 2.0 Switch 技术的数据库专用服务器。这个方案的核心思路是用 CXL 替代 RDMA 网络,实现百纳秒级延迟和数 TB/s 的带宽。相比传统的本地内存方案,扩展性提升了 16 倍。
对于数据库场景来说,这个方案解决了一个长期存在的痛点:数据库对内存容量的需求很大,但传统服务器的内存插槽数量有限。通过 CXL 内存池化,可以让多台数据库服务器共享一个大容量的内存池,既提高了资源利用率,又降低了成本。
磐久通算超节点 CXL 方案
在 AI 推理场景,阿里云推出了磐久通算超节点,专门用于 KV Cache 管理。这个方案采用了双 CPU 架构:一个计算 CPU 负责推理任务,一个内存管理 CPU 负责 CXL 内存池的协调。多个 CPU 节点可以共享同一个 CXL 内存池。
相比传统的 RDMA 方案,这个架构的优势很明显:首次 Token 时间(TTFT)降低了 82.7%,吞吐量提升了 4.79 倍。这是因为 CXL 的延迟比 RDMA 网络低得多,而且内存池化避免了数据在不同节点之间的重复传输。
Engram 内存池化架构
2026 年 3 月,北京大学和阿里云联合提出了 Engram 内存池化架构,这是首次将 CXL 内存池用于存储 Engram(一种新型的 KV Cache 管理机制)。这个方案集成到了 SGLang 推理框架中,实现了接近本地 DRAM 的端到端性能。
CXL 串行化内存技术
阿里云还在探索一个更激进的方向:用 CXL 直插内存取代传统的 DDR 内存。传统 DDR 内存受限于 Pin 速率和 PCB 布局,带宽很难继续提升。如果用 CXL 串行化传输,以 128 对 CXL serdes 为例,读写双向可以达到 2TB/s 的带宽,这是传统 DDR 难以企及的。
华为:自主可控的 UB-Mesh 路线
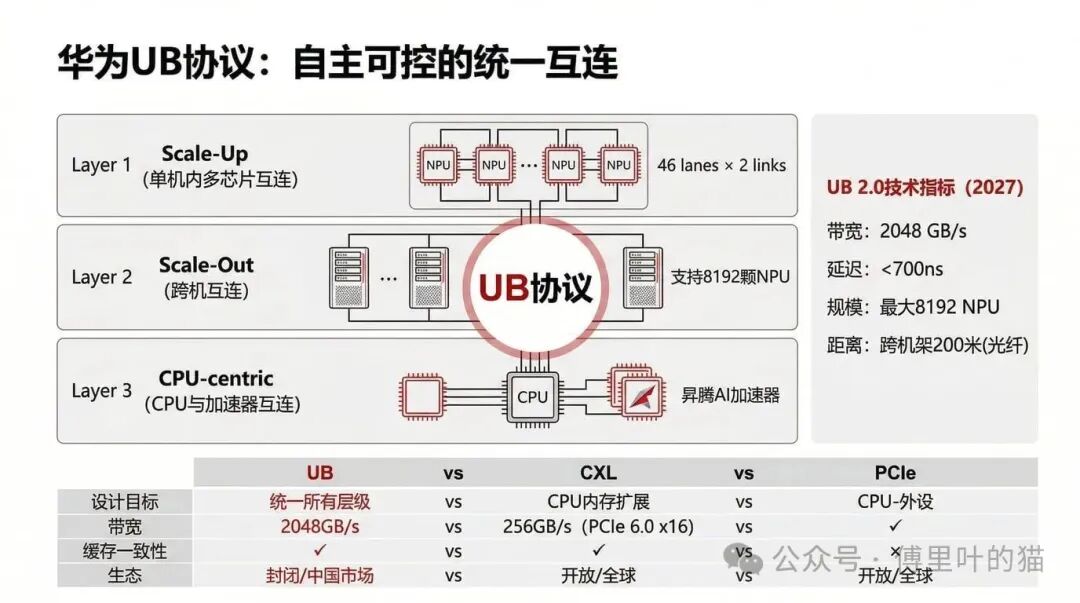
华为的路线和其他厂商完全不同,它选择了自主研发 UB(Unified Bus)协议,目标是取代 CXL 和 PCIe。
华为 UB 协议的战略定位
华为推出 UB 协议的背景是应对出口限制。在无法完全依赖全球标准协议的情况下,华为选择了自主可控的路线。UB 协议的设计目标是统一互连架构,跨 Scale-Up(单机内多芯片互连)、Scale-Out(跨机互连)、CPU-centric(CPU 与加速器互连)三层统一使用同一套协议。
UB 协议的技术指标
UB 1.0 在 2025 年推出,单向带宽 14GB/s,每颗 NPU 有 46 lanes × 1 link,全双工总带宽 1280GB/s,延迟小于 1000ns,最大可以支持 384 颗 NPU。信号传输距离在机架内,使用 DAC 线缆可以达到 1 米以内,使用 AEC 线缆可以达到 3 到 5 米。
到了 2027 年计划推出的 UB 2.0,每颗 NPU 的链路数翻倍到 46 lanes × 2 links,全双工总带宽达到 2048GB/s,延迟降低到 700ns 以内,最大可以支持 8192 颗 NPU。更重要的是,传输距离可以跨机架,使用光纤可以达到 200 米。
UB vs CXL vs PCIe 的对比
从设计目标看,UB 的野心更大,它要统一所有层级的互连,而 CXL 主要聚焦于 CPU 内存扩展,PCIe 主要用于 CPU 与外设的连接。从带宽看,UB 2.0 的 2048GB/s 远超 PCIe 6.0 x16 的 256GB/s。从延迟看,UB 的 700ns 也在可接受范围内。UB 和 CXL 都支持缓存一致性,这是 PCIe 不具备的。
但 UB 最大的问题是生态封闭。这是华为的专有协议,只在昇腾 AI 集群中使用,很难吸引第三方厂商加入。而且 UB 目前只在中国市场推广,全球影响力有限。
华为的垂直整合策略
华为的策略是垂直整合:昇腾 AI 加速器 + UB 协议 + 自研交换机 + 集成集群方案。在中国市场,这种垂直整合可以构建一个平行于全球标准的创新路径,减少对外部技术的依赖。
UB 的优势在于统一架构、自主可控、针对昇腾优化。劣势在于封闭生态、难以吸引第三方、仅限中国市场。
4、CXL 的挑战、机会与未来
SemiAnalysis 的批判与反思
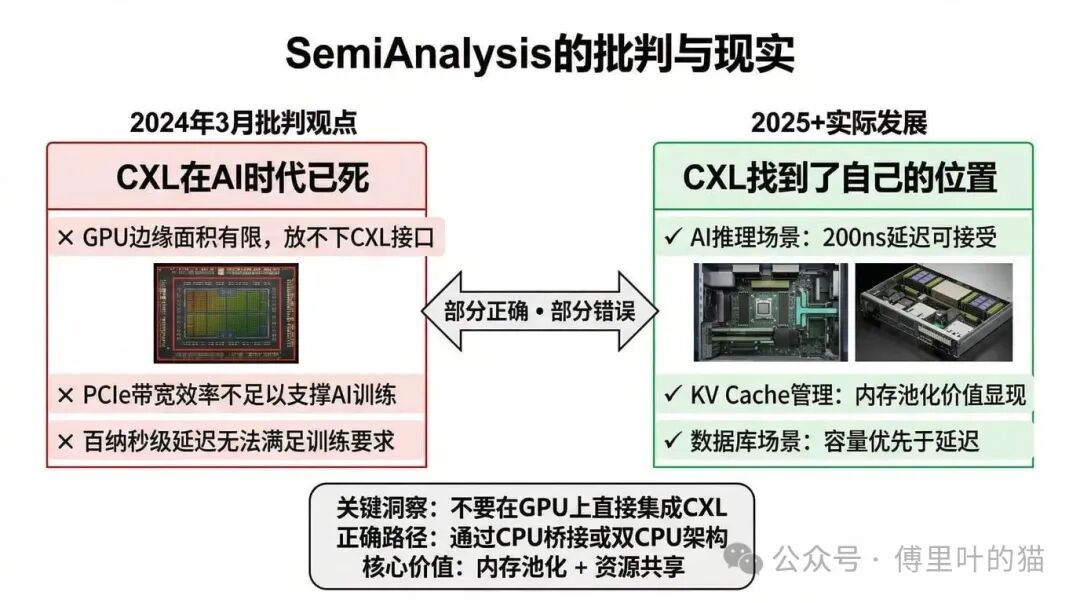
2024 年 3 月,SemiAnalysis 发布了一篇报告,标题很直接:“CXL 在 AI 时代已死”。这篇报告的核心论据有三点:第一,GPU 边缘面积有限,放不下 CXL 接口;第二,PCIe 的带宽效率不足以支撑 AI 训练的需求;第三,AI 训练场景对延迟极度敏感,CXL 的百纳秒级延迟无法满足要求。
这个判断对吗?从现在的发展来看,部分正确,部分错误。
正确的部分是:CXL 确实不适合 GPU 训练场景。AI 训练需要极低延迟(小于 50ns),而 CXL 的延迟在百纳秒级,这个差距很难弥补。而且 GPU 的边缘面积确实有限,Nvidia 选择把这些宝贵的空间用于 NVLink,而不是 CXL。
错误的部分是:也许 CXL 在 AI 推理场景找到了自己的位置。对于 KV Cache 管理这样的场景,200ns 的延迟是可以接受的,而 CXL 带来的内存池化能力可以大幅提升系统效率。
关键洞察是:不要试图在 GPU 上直接集成 CXL,而是通过 CPU 桥接或双 CPU 架构,让 CXL 发挥它擅长的作用——内存池化和资源共享。
CXL 面临的挑战
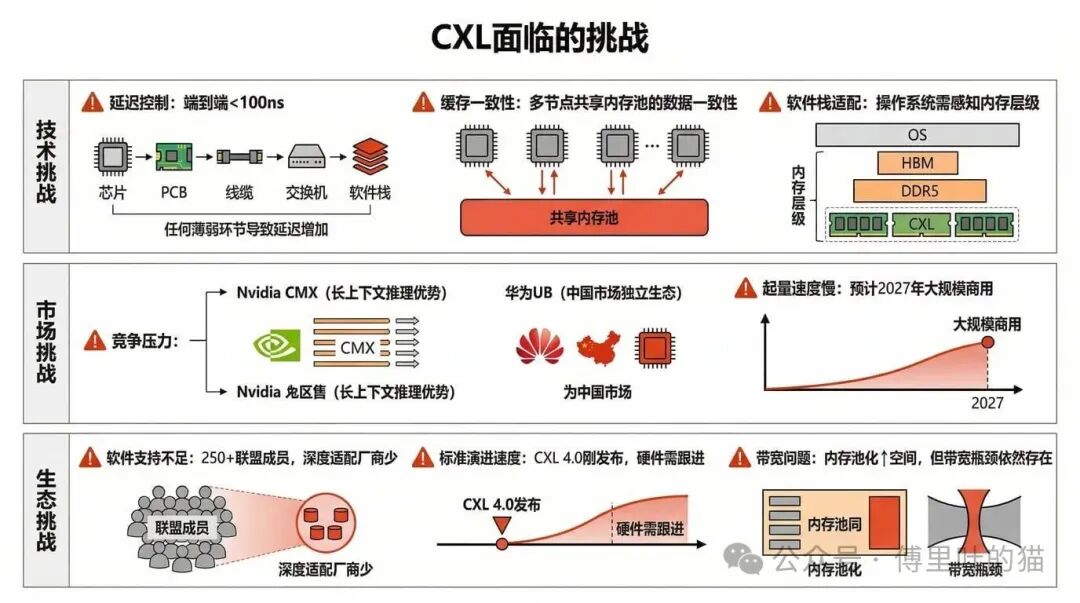
尽管有这些成功案例,CXL 仍然面临不少挑战。
技术层面,延迟控制是最大的难题。要实现百纳秒级的端到端延迟,需要在整个链路上做优化,包括芯片、PCB、线缆、交换机、软件栈。任何一个环节出问题,延迟都会显著增加。缓存一致性也是一个复杂的问题,当多个节点共享同一个内存池时,如何保证数据的一致性,这需要精细的协议设计和硬件支持。软件栈的适配也是挑战,操作系统和应用程序需要能够感知内存层级,做出智能的调度决策。你可以在 云栈社区 的计算机基础板块找到更多关于这些底层原理的讨论。
市场层面,CXL 面临来自多个方向的竞争。Nvidia 的 CMX 方案在长上下文推理场景有明显优势,可能会分流一部分客户。华为的 UB 协议在中国市场构建了独立的生态,这也会影响 CXL 的市场空间。
生态层面,软件支持不足是一个瓶颈。虽然 CXL 联盟有 250 多家成员,但真正在软件层面做深度适配的厂商还不多。操作系统、虚拟化、容器编排工具都需要针对 CXL 做优化,这需要时间。标准演进的速度也是一个问题,CXL 4.0 刚刚发布,硬件厂商的产品还需要时间跟进。
CXL 面临的另一个问题是,内存池化可以增加 DRAM 的空间,但现在 AI 任务中非常棘手的带宽问题,却无能为力。
5、CXL 产业链全景图
协议标准制定者

CXL 联盟是整个产业链的源头。这个联盟成立于 2019 年 3 月,创始成员包括 Intel、阿里巴巴、思科、戴尔、Meta、谷歌、HPE、华为、微软九家公司。后来 AMD、Nvidia、三星、ARM、瑞萨、IBM、Marvell、Synopsys、Cadence 等公司陆续加入。截至 2026 年,CXL 联盟已经有 250 多家成员,涵盖了芯片、系统、软件、云服务等各个环节。联盟的主要职能是制定和维护 CXL 协议规范,推动产业生态建设。
JEDEC 固态技术协会也在 CXL 生态中扮演重要角色。JEDEC 负责内存相关标准的制定,CXL 内存接口芯片厂商如澜起、Rambus、瑞萨都是 JEDEC 的活跃会员。JEDEC 参与 DDR5、DDR6 与 CXL 的协同标准制定,确保 CXL 和传统内存技术的兼容性。
接口芯片厂商
接口芯片是 CXL 产业链中最核心的环节,负责实现 CXL 协议的物理层和控制逻辑。
澜起科技是这个领域的重要玩家。2022 年 5 月,澜起推出了全球首款 CXL 2.0 MXC(内存扩展控制器)芯片。在 CXL 3.1 MXC 市场,澜起的市占率达到 92%。澜起的产品线还包括 PCIe 5.0/CXL 2.0 Retimer 芯片,以及 DDR5 RCD/DB 接口芯片,在 DDR5 接口芯片市场排名全球第二,仅次于瑞萨 IDT。三星的 512GB CXL DRAM 模组就采用了澜起的 MXC 芯片。澜起的优势在于它是中国大陆唯一的 Retimer 供应商,深度绑定了国内的服务器厂商。但澜起也面临挑战,CXL 的起量速度慢于预期,业界预计要到 2027 年才会大规模商用。
Astera Labs 是 CXL 内存池化芯片的先驱。2024 年,Astera Labs 推出了业界首个 CXL 2.0 Memory Accelerator SoC Platform。在 PCIe Retimer 市场,Astera Labs 占据绝对领先地位,是最早量产 PCIe 5.0 Retimer 的公司,在 PCIe 4.0 和 5.0 市场占据大半份额。Astera Labs 的客户包括亚马逊、微软、谷歌、Nvidia,在 Nvidia 的 GPU 系统中几乎是独家供应 PCIe Retimer。Astera Labs 的产品线还包括 CXL Switch 芯片。作为纳斯达克的 CXL 概念股龙头,Astera Labs 的股价从 2023 年的 40 多美元飙升到 2025 年的 200 多美元,市场给予了很高的估值。
Rambus 是全球三大内存接口芯片供应商之一。Rambus 的产品线包括 CXL 内存扩展控制器、DDR5 RCD/DB 接口芯片,以及 MRDIMM 方案。MRDIMM 是一种双通道内存技术,Rambus 的方案是用两个 6400MT/s 拼出 12800MT/s 的双倍带宽。2025 年,Rambus 的全年营收约 700 到 710 million 美元,其中 200 million 是专利授权,120 到 130 million 是 IP 授权,剩余的是接口芯片业务。Rambus 的股价从 2023 年的 40 多美元涨到 2025 年的 100 多美元,市场表现不错。Rambus 在 DDR5 时代的市场份额持续增长,在中国市场还有广阔的空间。
Marvell 通过收购进入 CXL 领域。Marvell 收购了 XConn,获得了 Ultra IO Transformer 技术,还收购了 Tanzanite Silicon,获得了内存加速器技术。Marvell 的产品方向是 CXL 内存扩展和池化解决方案。
其他玩家还包括谱瑞科技(Parade Technologies),这是一家台湾厂商,提供 PCIe Retimer 产品。Microchip 也在研发 PCIe Retimer。Credo 拥有高速 SerDes 技术,计划进军 PCIe Retimer 和 CXL 市场。瑞萨(Renesas/IDT)在 DDR5 接口芯片市场排名全球第一,但在 CXL 方面的布局相对保守。三星和 SK 海力士据悉即将推出自研的 CXL 控制器芯片。
IP 授权厂商
IP 厂商不直接生产芯片,而是将 CXL 协议的 IP 核心授权给芯片设计公司,收取 License 费用和 Royalty。
Synopsys(新思科技)是业界首款 CXL IP 核解决方案的供应商。2019 年 9 月,Synopsys 推出了 DesignWare CXL IP 解决方案,包含 Controller、PHY、IDE 安全模块和验证 IP。这套方案支持 CXL 3.0、2.0、1.1、1.0 全系列规范,支持 x2 到 x16 的 CXL 链路带宽,数据路径宽度包括 128、256、512、1024 bit。2020 年 12 月,Synopsys 推出了业界首个 CXL 2.0 VIP(验证 IP),基于 SystemVerilog UVM 架构,集成了 Verdi 协议分析仪。Synopsys 已经向多个客户交付了支持 IDE 的 CXL 2.0 和 3.0 解决方案,这些方案在客户产品中经过了硅验证,并在硬件中证实了与第三方的互操作性。作为 CXL 联盟的早期贡献者,Synopsys 可以快人一步获悉最新的规范。
Cadence 是业界首个 CXL 3.0 验证 IP 的供应商。2022 年 8 月,Cadence 推出了针对 CXL 3.0 标准的 VIP 和系统级 VIP,集成了 PCIe 6.0,提供了从 IP 到 SoC 的完整解决方案。Cadence 和 Synopsys 并列为 EDA 巨头,都提供一站式的 IP 组合。
Arteris IP 是互连 IP(NoC)市场的领导者。2019 年,Arteris IP 在互连 IP 市场占据 31.3% 的份额。Arteris IP 的核心产品包括 FlexNoC Interconnect、Ncore Cache Coherent Interconnect、CodaCache Last Level Cache IP。Arteris IP 的客户包括百度、Mobileye、三星、华为/海思、东芝、NXP。Arteris IP 的技术特点是即插即用,允许设计师优化吞吐量、功耗、延迟和平面图。
其他 IP 厂商还包括 Alphawave,提供高速 SerDes IP 授权。Credo 的 SerDes 技术不仅可以以 IP 授权方式出售,还可以以 Chiplet 形式集成到多芯片模块片上系统(MCM SoC)中。
产业链总结
CXL 产业链呈现“协议标准 → IP 授权 → 芯片设计 → 系统集成”的四层结构。
在协议标准层,CXL 联盟和 JEDEC 负责制定规范,推动生态。在 IP 授权层,Synopsys、Cadence、Arteris 通过 License 和 Royalty 收费。在接口芯片层,澜起、Astera Labs、Rambus、Marvell 负责芯片销售。在系统集成层,阿里云、浪潮、联想、新华三、HPE、Dell 提供整机方案。
中国厂商在这个产业链中的位置比较明确。澜起科技在接口芯片层处于全球领先地位。阿里云和浪潮在系统集成层做场景落地。华为选择了自主路线,推出 UB 协议,不参与 CXL 生态。
根据行业专家的判断,CXL 接口芯片的大规模商用预计在 2027 年。主要瓶颈是系统厂商的认证周期很长,通常需要 1.5 到 2 年,而且软件生态还不够成熟。但一旦这些瓶颈突破,CXL 的市场规模会有一个明显的跃升。
 发表于 2026-4-14 06:02:20
|
查看: 241|
回复: 0
发表于 2026-4-14 06:02:20
|
查看: 241|
回复: 0
