你是不是也有这种经历:晚上想刷五分钟短视频,结果一个小时过去了都没停下?明明很多视频都无聊重复,甚至感到有些乏味,但就是控制不住继续往下划动。
这并非单纯的意志力薄弱,而是因为你正身处一个精心设计的“注意力陷阱”之中。
你的大脑在等待下一次惊喜
我们生活在一个注意力被激烈争夺的时代,你的每一次点击、停留都价值不菲。为了更有效地开采这片金矿,平台们设计了一套精密的多巴胺游戏,通过不断优化推荐与奖赏结构,让你在不知不觉中“上头”。这套机制的核心,正是行为心理学中的经典策略:间歇性奖励机制(Intermittent Reinforcement)。
关键在于一个反直觉的理论:让人上瘾的不是奖励本身,而是对奖励的期待。
你肯定体验过:连续划过了十几条平淡无奇的视频后,突然出现一条特别打动你的,让你瞬间笑出声、感到愤怒、泪目或大呼“懂我!”。正是这一个突如其来的“爆点”,让你决定继续刷下去。这正是心理学家斯金纳(B.F. Skinner) 在上世纪提出的间歇性强化机制的精髓。
在间歇性奖励的各种模式中,最容易让行为持续下去的就是变量比率奖励机制(Variable Ratio Schedule),因为不确定的奖励远比确定的奖励更容易让大脑上瘾。
斯金纳的鸽子实验清晰地展示了这一点。他训练鸽子通过按按钮来获取食物。如果每按一次按钮就固定给一粒食物,鸽子很快就失去了兴趣。但当规则改为随机间隔投食——比如按三次给一次,按七次再给一次,按五次又给一次,鸽子们会变得异常狂热,几乎无休止地按下去。

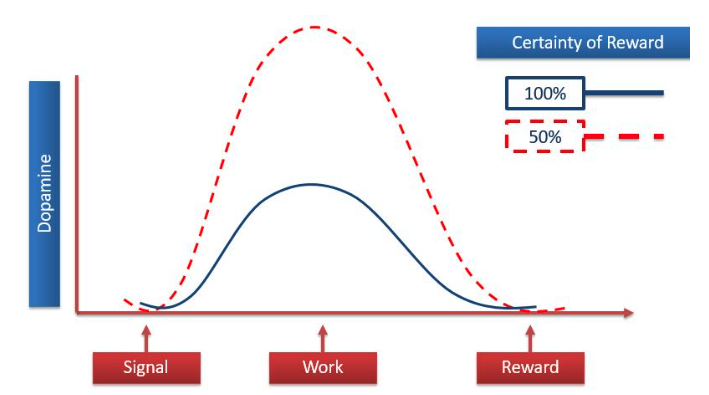
神经科学家 Robert Sapolsky 的研究进一步揭示:大脑在面对“确定奖励”与“不确定奖励”时,多巴胺的释放峰值并非出现在获得奖励的瞬间,而是在期待奖励的过程中。更有趣的是,当奖励从100%确定出现,变为只有50%几率出现时,多巴胺的释放反而更剧烈。这表明相比于确定的满足,大脑更容易被“可能有惊喜”的不确定性所驱动。
如今的短视频平台,就像一个全天候运作的注意力赌场。正如产品行为学专家 Nir Eyal 在《上瘾》(Hooked: How to Build Habit-Forming Products)一书中指出的,平台正是通过“触发—行为—奖赏—投入”这一行为闭环,不断强化用户的参与动机。

这也解释了为何我们对抽卡、开盲盒、老虎机等游戏容易上瘾:它们的底层机制完全一致——不确定的奖赏 → 持续的下注行为 → 多巴胺驱动的参与感。当你刷到停不下来时,很可能已不是在主动寻找想看的内容,而是在被动等待平台投喂那一个期待中的“惊喜”。
算法是如何越来越懂你的?
那么,这些让你上头的视频,平台究竟是如何筛选出来的?
你在看视频的同时,平台也在观察你
推荐系统的核心目标,是不断构建并更新一个尽可能精准的用户画像。你的每一次点击、停留时长、快进、点赞或划走,都是一次对自身偏好的“标注”行为。例如,你点进美食视频并停留超过5秒,系统就会打下“食物兴趣”标签;你总是快速划过鸡汤段子,它就知道你是“对煽情内容无感”的人群,并相应减少推荐。
这些源源不断的行为反馈被送入模型中,形成自我增强的循环:你刷视频 → 产生反馈 → 平台记录 → 模型更新 → 推送更精准的“诱饵” → 你产生更强反馈 → 继续刷…… 这背后正是经典的在线强化学习(Reinforcement Learning)系统在运作。
平台通常使用两种基础推荐策略:
- 协同过滤(Collaborative Filtering):核心是“人以群分”。喜欢相似东西的人,未来也可能喜欢相似的东西。比如,你喜欢视频A和B,而另一个用户也喜欢A和B,并且他还喜欢视频C,那么平台就会把C推荐给你。
- 内容过滤(Content-based Filtering):基于内容本身的相似度进行推荐。系统会分析你看过的视频的标签、关键词、时长、节奏、配乐、话题等内容特征,然后推荐与之相似的其他视频。
然而,平台并不会一味地推送你最爱看的内容,因为长期来看这容易导致内容疲劳甚至用户流失。因此,算法必须在“满足你”和“试探你”之间找到精妙的平衡。这就是推荐系统中的一个经典问题:探索 vs 利用(Explore vs Exploit)权衡。“探索”是为了试探你的新兴趣,挖掘未知内容;“利用”则是为了稳住你,继续推送你已经验证过的喜欢的内容。
这个问题在学术上也被称为多臂老虎机问题(Multi-Armed Bandit Problem)。就像赌场里的老虎机,每个“臂”代表一种内容选择,平台需要在不同臂之间做选择,既要最大化当前回报(推送你大概率会喜欢的内容),又要不断尝试未经验证的选项,以寻找更优的长期策略。

为了让推荐列表看起来不那么套路化,平台还会加入随机扰动机制,例如使用 Gumbel-Max Trick 这类采样方法。简单来说,系统会为每个视频估算一个点击概率(例如,你点击美食视频的概率是0.9,点击汽车视频的概率是0.6),然后为每个概率值加上一个符合Gumbel分布的随机噪声。这种做法制造了不确定性,最终让高分内容更容易被选中,但也给低分内容一些曝光机会。
这就实现了一种微妙的效果:你刷到的内容中,大部分是你可能喜欢的,但总混杂着一部分未知的新奇内容。这些内容有时平淡,有时却异常出彩,且出现得足够随机,让你持续产生“下一个会不会更好”的期待。这就像赌场老板精心设计的伪随机程序,有意混入几次“中大奖”来吊住你,让你持续下注。
这种不确定、持续下注的体验,还在悄悄抬高你的刺激阈值。长时间沉浸在这种高频快感的节奏中,大脑会愈发渴求更强的刺激,导致你开始需要更短、更快、更炸裂的内容才能感到满足,而对那些节奏缓慢、需要深度思考的内容,则变得越来越难以专注。
有一种焦虑叫“害怕错过”
FOMO(Fear of Missing Out,错失恐惧) 是一种对可能错过重要信息或机会的持续担忧——你总觉得,下一条短视频可能就藏着某个关键知识点、搞笑段子或重大新闻。这种焦虑感,在无形中主宰了我们注意力的分配。
但真相往往是:内容的碎片化特性,导致你刷完后也记不住多少实质性信息。随之而来的是一种空虚感,于是你立即刷下一个视频来填补它。这是一种被“信息满足”的幻觉所劫持的惯性依赖。平台用源源不断的、“可能有用”的信息碎片投喂你,而你被FOMO焦虑绑架,持续上缴自己宝贵的注意力。
然而,信息时代最大的悖论或许是:你真正需要构建的知识体系与认知结构,从来不是靠“刷”出来的。认知的升级往往发生于对知识的主动选择、深度咀嚼、反复推演的漫长过程中,而非在碎片化内容的狂轰滥炸下,侥幸获得那一瞬间“有收获的错觉”。

如何抵抗短视频的上瘾机制?
要重新找回那种不依赖外部高频刺激也能感到充实的状态,我们需要做的不是简单地强制戒断,而是系统地重建自己的“奖赏系统”。
1. 重设刺激阈值
- 设置固定时间窗口:例如,规定自己只在午饭后或睡前拥有10分钟的“短视频时间”。
- 设立主动停止点:比如,每看到3条有趣的内容,就主动暂停一下,练习“提前结束”的能力。
短时间、高频次的刺激会不断抬高大脑的多巴胺阈值。刻意拉长获取刺激的间隔、降低其频率,有助于恢复多巴胺系统的敏感性与韧性。
2. 刻意培养长期奖赏回路
大脑并非只喜欢短期刺激,它也能被成就感、节奏感、结构化输出所驱动。尝试给自己设立“长线任务-奖赏”机制:例如,完成一项有挑战的工作、读完一章书、或运动半小时后,才允许自己刷一会儿短视频。逐渐地,用这些更缓慢但成就感更高的行为,来反向刺激大脑,重新建立“深度投入 → 延迟满足 → 真实回报”之间的神经连接。这本质上是从追求多巴胺(快感,但易空虚) 的回路,转向依赖内啡肽(成就感,更扎实) 的回路。

3. 提升觉察力
你越理解算法如何建模你、预测你、引导你上钩,你就越能保持清醒,抵抗诱惑。可以经常问自己两个问题:“我现在是在主动选择想看的内容,还是在被动接受投喂?”、“这条信息对我真的重要或有价值吗,还是仅仅在消耗我的时间?”
比单纯依靠意志力“忍住不刷”更根本的解决之道,是设计出一个比短平快的刺激更有趣、更具成就感的日常生活与学习系统。你的注意力是宝贵的认知资源,它值得被更深刻、更长久的满足感所支配。希望这篇从推荐算法与行为心理角度的剖析,能帮助你更理性地看待数字生活中的“诱惑”,并在云栈社区找到更多深度交流与成长的可能。
参考资料:
[1] Reward and Decision Processes in the Brain. Montague, P. R. https://doi.org/10.1126/science.1130935
[2] How TikTok uses Reinforcement Learning for Realtime Recommendations. https://bytehouse.cn/blog/tiktok-reinforcement-learning-recommendations/
[3] Newport, C. (2019). Digital Minimalism: Choosing a Focused Life in a Noisy World. https://www.calnewport.com/books/digital-minimalism/
[4] Skinner’s Operant Conditioning: How Reward Shapes Behavior. Simply Psychology. https://www.simplypsychology.org/operant-conditioning.html
[5] Reward Prediction Error and Dopamine. https://neurosciencenews.com/reward-prediction-error-dopamine-20528/
 发表于 2026-3-15 04:54:43
|
查看: 403|
回复: 0
发表于 2026-3-15 04:54:43
|
查看: 403|
回复: 0
