使用 OpenClaw 的朋友,大概都踩过类似的坑。
刚开始对话时一切正常,Agent 似乎也能“记住你”。但随着对话长度增加,问题就来了:之前设定的人物关系忘了,确认过的个人偏好也模糊了,甚至连几分钟前刚敲定的任务约束,都能在后续回复中被“漂没”。这种感觉很微妙——并非 Agent 完全失忆,而是它总能在关键时刻忘掉最关键的那几条信息。
这时你便会意识到,“拥有记忆”和“记忆真的能用”,其实是两码事。
最近出现的一个开源插件 memory-lancedb-pro,正是瞄准这个问题而来。它并非简单地为 OpenClaw 套上一个存储外壳,而是在记忆检索这一层上做得更为细致。项目主页如下:
许多基础记忆方案的核心痛点,往往不在于“存不进去”,而在于“取不出来”。你明明清楚地交代过所使用的模型接口、项目优先级,甚至某个角色的详细设定,但到了后续对话中,Agent 进行检索时,返回的要么是过于宽泛的旧信息,要么是语义沾边但优先级完全不对的片段。
memory-lancedb-pro 的价值点恰恰在此:它不再仅仅依赖偏向“模糊匹配”的单一方式进行记忆查找,而是将语义理解(向量搜索) 和关键词匹配(BM25全文搜索) 结合了起来。这听起来像是一句标准的技术描述,但实际意义重大。因为很多记忆检索失败,并非模型不够智能,而是检索层先将错误的上下文喂给了模型。该返回最近的记忆,它却给了更老的;该返回核心约束,它却提供了一个边角信息。如此一来,后续的大模型再强大,也只能在错误的上下文中艰难工作。
简而言之,对于长期记忆系统,存储并非最困难的部分,召回什么、如何排序、最终将什么信息塞给 AI,才是真正影响使用体验的关键。
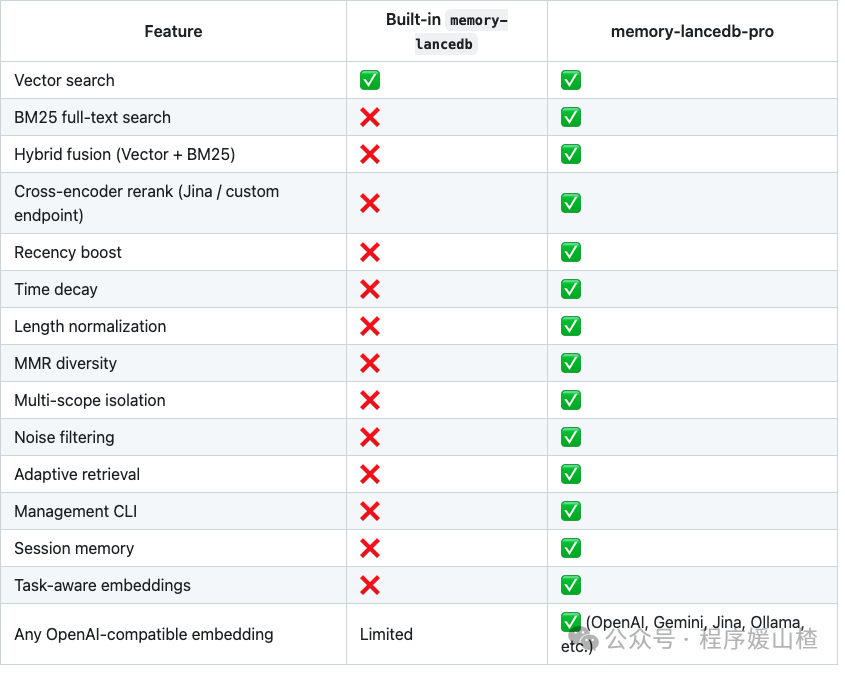
浏览这个插件时,一个强烈的感受是:它并非在炫技,而是在弥补 OpenClaw 一个非常现实的短板。项目说明中提到,它会尽力确保最终提取给 AI 的,是最新、最核心的那部分信息。这个思路非常正确,因为对于对话型 Agent 而言,记忆不怕少,就怕乱。给它十条过时的干扰信息,远不如提供三条当前仍然有效的关键约束。
此外,它还引入了噪声过滤和自适应检索这类能力。这一点很有意思。当前很多关于 Agent 记忆的讨论,仍停留在“能记下来就行”的层面。但在实际使用中,记忆库会逐渐“变脏”:旧信息未被淘汰、错误的总结被反复引用、用户后来修改的偏好未能覆盖前一个版本。长此以往,记忆非但不是资产,反而成了噪音源。因此,让 Agent 在使用过程中,能够顺手“修缮”自己的知识库,其意义远比“再多记几条”来得更大。至少,这个方向是对的。
另一个实用之处在于,该插件支持的接口范围相当广泛。Jina、OpenAI、Gemini、Ollama 等都能接入,这意味着你不必被绑定在某一种特定的嵌入服务上。无论是本地部署还是混合接入,都可以根据自己的环境灵活配置。对于已经将 OpenClaw 部署得七七八八的用户而言,这种灵活性至关重要。否则,插件功能再强大,如果接入成本过高,也很容易沦为“看起来很美,实际上懒得安装”的摆设。
它还自带了完整的 CLI 命令行工具,这一点个人非常赞赏。因为一旦记忆系统开始长期运行,你迟早会遇到两个需求:一是手动管理,比如删除脏数据、补录关键记忆;二是审计,你需要知道 Agent 到底记住了什么、引用了什么、以及为什么会给出某种回答。很多项目只关注“自动化智能”,反而将后台的可控性做得非常弱,导致一出问题就无从排查。CLI 这类工具并不炫酷,但非常实在。
它不一定能让 Agent 瞬间变得更聪明,但大概率能帮助其减少因记忆错乱而导致的低级错误。
我无意将这个插件吹捧成什么“记忆革命”。归根结底,长期记忆一直都不是一个单点问题,它与上下文管理、任务规划、工具调用,乃至模型本身的稳定性都紧密关联。
但 memory-lancedb-pro 至少抓住了一个关键事实:Agent 很多时候并非不会回答,而是经常拿错了资料再开始回答。 这无疑是在解决 AI Agent 长期记忆实用性道路上迈出的坚实一步。对于相关领域的技术实践者,不妨在 云栈社区 的人工智能板块交流更多关于 Agent 和 RAG 的实战经验。
项目 GitHub 地址:win4r/memory-lancedb-pro,作为一个开源实战项目,值得一试。
 发表于 2026-3-15 10:03:42
|
查看: 106|
回复: 0
发表于 2026-3-15 10:03:42
|
查看: 106|
回复: 0
