从手机到服务器,CPU(中央处理器)是所有计算设备的核心。过去五十多年,它从最初的几千个晶体管,演变成如今集成百亿晶体管的复杂芯片。这篇文章将和你一起回顾CPU架构的关键变革——从世界首款商用CPU到现代异构芯片,每一步都藏着工程师们突破物理极限的巧思。

一、CPU到底是什么?
1. 核心工作原理
CPU的本质是“执行指令的机器”,遵循“取指-解码-执行”循环:从内存获取指令 → 翻译指令含义 → 完成计算/数据操作 → 输出结果。
这套每秒重复数十亿次的基础流程,支撑起所有电子设备的运算能力,而它的物理基础是硅片上的晶体管(类似微小开关),通过光刻技术层层蚀刻,最终在指甲盖大小的芯片上集成百亿级晶体管。作为CPU发展的起点,早期处理器的晶体管数量和工艺与现代芯片有着天壤之别。

从数千个晶体管到百亿级晶体管的跨越,离不开精密制造技术的突破,其中光刻就是实现晶体管高密度集成的核心工艺。

2. 核心架构拆解
现代CPU是“分工明确的团队”,其设计本质上是冯诺依曼架构在当代的精细化演进——1945年冯诺依曼提出的“运算器、控制器、存储器、输入/输出设备分离联动”框架,至今仍是多数CPU的核心设计基础,而现代CPU的各类专用组件,正是这一框架的具体落地与升级。
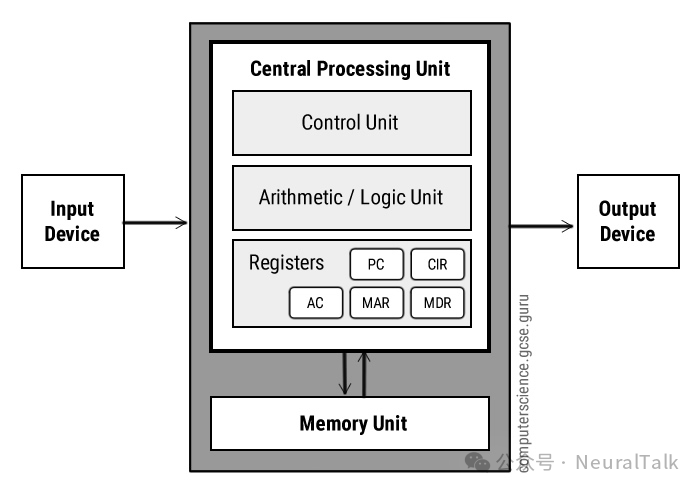
基于冯诺依曼架构的核心逻辑,现代CPU拆解为以下关键组件,各模块协同完成“取指-解码-执行”的完整流程:
- 前端单元:作为控制器的核心延伸,负责从存储器中取指、解码指令,同时通过分支预测技术预判程序执行路径,避免流水线因指令等待而闲置,提升执行连续性;
- 寄存器:相当于运算器的“超高速临时货架”,存储当前正在处理的运算数据与指令,其SRAM材质带来的极致速度,能大幅减少数据搬运延迟;
- 运算单元:对应架构中的运算器,细分出ALU(整数运算)、FPU(浮点运算)、SIMD(多数据并行)等专用模块,分别适配不同类型的计算任务,实现分工提速;
- 缓存系统:作为存储器与运算单元之间的“高速中转站”,L1/L2/L3缓存按速度递减、容量递增的层级设计,通过暂存高频访问数据,显著减少对主内存的依赖,降低整体延迟;
- 总线单元:承担输入/输出设备的核心功能,负责CPU与内存、外设之间的数据传输,是各组件与外部系统联动的“通信桥梁”。
二、x86架构:统治桌面的五十年传奇
在冯诺依曼架构的基础上,x86架构通过半个世纪的技术迭代,从早期16位芯片逐步进化为32位、64位通用计算架构,凭借极强的兼容性和持续的性能突破,成为桌面计算领域的绝对主导者。
1. 起点:Intel 8086(1978)
- 16位架构,20位地址总线(支持1MB内存),突破了当时8位处理器的内存限制;
- 首创“分段内存模型”,通过“段+偏移”的地址计算方式,用16位寄存器实现20位地址寻址,巧妙解决了寄存器宽度与内存需求的矛盾;
- 创新性地分为BIU(总线接口单元)和EU(执行单元),两者并行工作,同时引入6字节指令预取队列,让指令fetch与执行可重叠进行,成为早期流水线技术的雏形。

2. 迭代:从286到486(1982-1989)
x86架构在这一阶段的核心演进方向是:扩展内存容量、支持多任务操作系统、提升集成度与流水线效率,每一代升级都针对性解决前一代的技术瓶颈。
- 80286(1982):在8086分段内存模型的基础上,将地址总线扩展至24位(支持16MB内存),新增“保护模式”——通过descriptor表定义内存段的访问权限,实现程序间的内存隔离,为multitasking(多任务)提供硬件支持;
- 80386(1985):首次实现完整的32位架构(寄存器、数据总线、地址总线均为32位),支持4GB内存,彻底突破286的内存限制;同时引入分页机制和MMU(内存管理单元),让虚拟内存成为可能,完美适配Windows NT、早期Unix等现代操作系统;
- 80486(1989):延续32位架构,核心升级在于“集成化”——将原本外置的FPU(浮点运算单元)和8KB L1缓存集成到芯片内部,减少数据传输延迟;同时优化为8级流水线,支持指令重叠执行,性能较386提升2-4倍,进一步夯实了x86的性能优势。



3. 飞跃:Pentium系列(1993-2000)
进入90年代,单纯扩展位数和集成组件已难以满足性能增长需求,Pentium系列通过引入并行执行、乱序调度等核心技术,推动x86架构从“顺序执行”向“智能并行”跨越,成为现代CPU微架构的雏形。
- Pentium(1993):采用superscalar(超标量)架构,在486单流水线基础上,新增双整数流水线(U/Y管道),可同时执行互不依赖的指令;同时加入动态分支预测,通过记录分支执行历史减少流水线清空次数,从“指令级并行”层面提升IPC;
- Pentium Pro(1995):搭载P6架构,首次实现乱序执行、寄存器重命名等关键技术——将复杂的x86指令转译为更简洁的微操作(µops),存入重排序缓冲区后按数据就绪顺序执行,而非严格遵循程序顺序;配合寄存器重命名(将8个架构寄存器映射到40个物理寄存器),消除指令间的虚假依赖,大幅提升并行度;
- Pentium 4(2000):采用NetBurst架构,转向“高频优先”策略——通过20级长流水线设计,将时钟频率推至新高(最高3.8GHz),但长流水线导致分支误预测惩罚极高,且IPC较低、能耗飙升(TDP达100W+),最终未能延续优势。
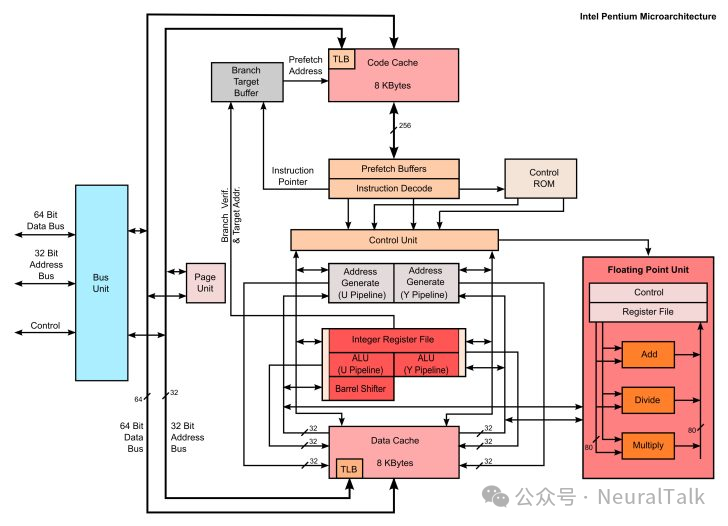
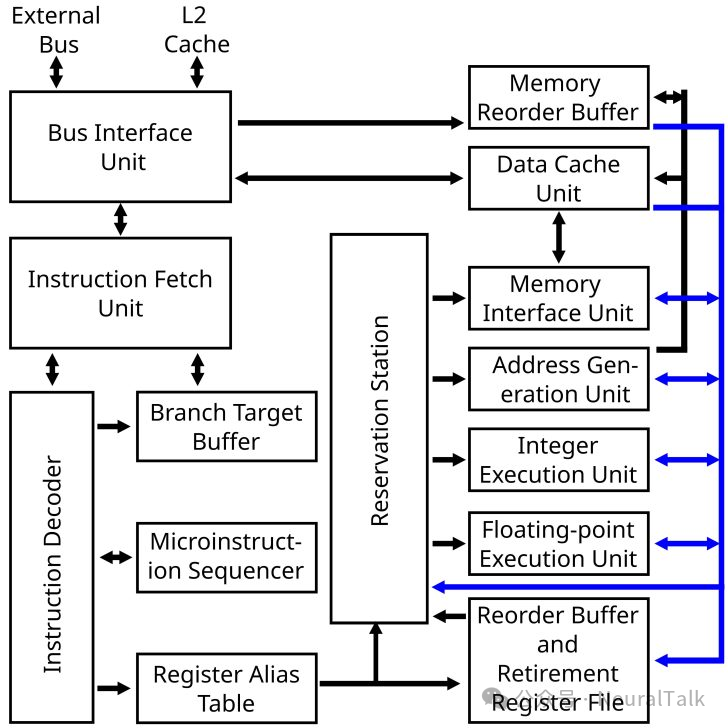

三、并行计算:多核与多线程的崛起
在Pentium 4陷入“高频高功耗”的瓶颈后,CPU行业彻底放弃单纯提升主频的思路,转而通过并行化突破性能上限,多核与多线程技术就此登上舞台,成为现代CPU性能提升的核心路径。
1. 从单核到多核(2005年后)
单核时代末期,CPU已撞上严重的功耗墙与发热墙,继续提升时钟频率只会导致功耗、温度失控,性能难以有效增长。行业因此转向多核架构,用“多核心并行”替代“单核狂飙”:
- 2005年AMD推出Athlon 64 X2(首款双核消费级CPU);
- 核心逻辑:通过多核心并行处理多线程,避开“功耗墙”,在不大幅提升主频的前提下实现整体性能增长;
- 如今桌面CPU已达16核32线程,服务器级产品核心数量更是突破100核,并行能力成为衡量高端CPU的关键指标。

2. 超线程(SMT)技术
多核是增加物理核心数量,而超线程则是深挖单核心潜力的技术,与多核架构形成互补,进一步提升并行效率:
- Intel 2002年在Pentium 4中引入Hyper-Threading(超线程技术),是商用SMT(同步多线程)的开端;
- 原理:单个核心模拟两个“逻辑核心”,共享执行单元、缓存等硬件资源,在核心执行单元闲置时切换处理另一线程,最大化提升硬件线程利用率;
- 效果:多线程任务性能提升30%左右,成本远低于增加物理核心,成为现代主流CPU的标配技术。
四、RISC vs CISC:从对立到融合
在x86架构主导桌面市场的同时,CPU指令集领域长期存在两大设计阵营的激烈竞争,二者从早期理念对立、场景分割,逐步走向技术融合,共同推动现代CPU架构发展。
1. 两大阵营的初心
两大指令集的核心差异源于设计初衷与优化方向的不同:
- CISC(复杂指令集):x86为代表,指令复杂且长度可变,单指令可完成多步操作,设计初衷是减少指令数量、强化软件兼容性,支撑x86数十年的生态延续;
- RISC(精简指令集):ARM、PowerPC为代表,指令格式统一、执行逻辑简单,可实现单周期高效执行,流水线效率更高,天生具备低功耗优势,更适合移动与嵌入式场景。
2. 关键案例
在RISC架构发展历程中,PowerPC与Cell处理器是极具代表性的里程碑,也印证了RISC架构的高性能潜力:
- PowerPC:IBM、苹果、摩托罗拉联合开发,采用经典RISC设计,曾用于苹果Mac电脑与多款游戏主机,是移动端外RISC架构的重要应用;
- Cell处理器:IBM、索尼、东芝合作研发,属于异构多核RISC芯片,含1个Power核心+8个SPE协同处理单元,专为并行计算优化,用于PS3与早期超级计算机;
- 现代融合:如今两大架构已不再绝对对立,x86 CPU内部会将复杂指令转译为RISC风格的简单微操作再执行,兼顾兼容性与执行效率;而RISC架构也加入SIMD等复杂指令扩展(如ARM NEON),提升并行计算能力,二者取长补短完成技术融合。

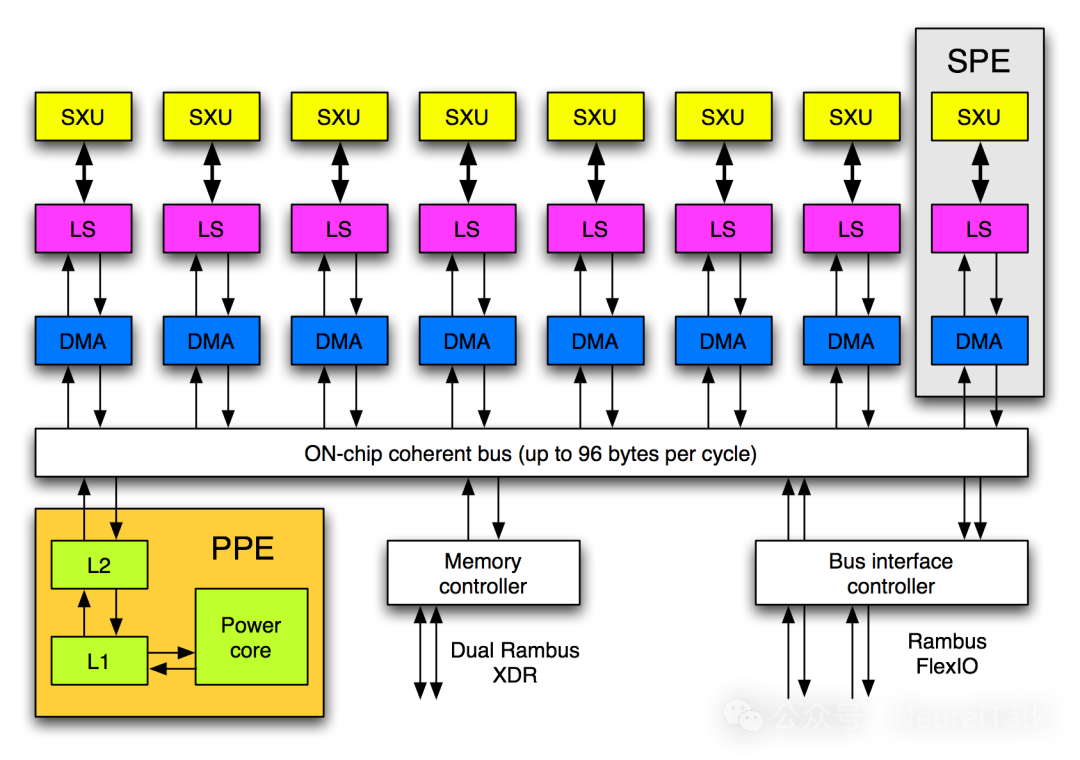
五、现代CPU:芯片组、SoC与苹果硅
在多核架构成熟、指令集技术融合的基础上,当代CPU彻底跳出传统设计框架,向模块化拆分、高度集成化、定制化异构计算方向升级,Chiplet芯片组、SoC系统级芯片与苹果硅架构,成为现代CPU发展的三大核心方向。
1. 芯片组(Chiplet)设计
传统单核大芯片在先进制程下,极易因局部缺陷导致整颗芯片报废,良率低、成本高且核心数扩展不灵活,Chiplet设计正是为解决这一痛点而生:
- 打破“单芯片”模式,将核心、缓存、I/O拆分为独立小芯片;
- 优势:提升良率、混合制程、灵活扩展核心数;
- 代表:AMD Zen系列(CCD核心芯片+IOD I/O芯片)、Intel Sapphire Rapids。

2. SoC(系统级芯片)
与Chiplet的“拆分组合”不同,SoC走高度集成化路线,将计算机的核心功能组件全部整合到单颗芯片中,实现更小体积、更低功耗的完整计算平台:
- 集成CPU、GPU、内存控制器、AI加速器等,一站式解决方案;
- 特点:低功耗、低延迟,适配移动设备和轻薄本;
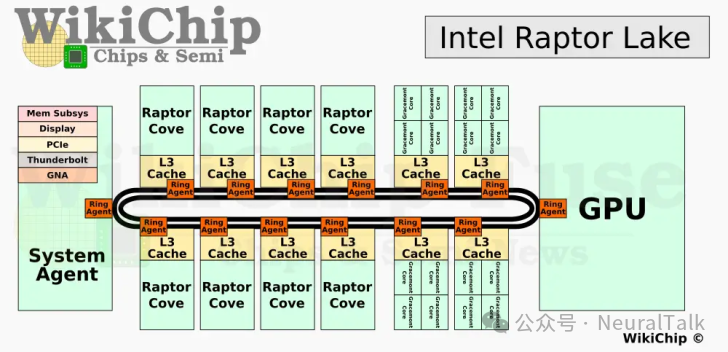
- 代表:手机骁龙/天玑芯片、Intel Raptor Lake、苹果M系列。
3. 苹果硅(Apple Silicon):ARM的桌面逆袭
在ARM长期主导移动市场、x86垄断桌面市场的格局下,苹果基于ARM架构深度定制,推出苹果硅芯片,完成了Mac平台的彻底转型,实现了ARM架构在桌面端的逆袭:
- 2020年推出M1芯片,基于ARM架构,3年完成Mac平台转型;
- 核心优势:
- 超宽架构(M1 Firestorm核心每周期解码8条指令),指令级并行能力大幅提升;
- 超大缓存(L1数据缓存64KB/核,共享L2缓存达32MB),最大限度降低内存访问延迟;
- 极致集成(CPU、GPU、神经网络引擎、DRAM同封装),软硬件深度协同优化;
- 性能表现:M1 Max的IPC较Intel旗舰高30%,性能功耗比领先x86。

M系列芯片的成功,与其说是ARM指令集的胜利,不如说是苹果在计算机架构设计与系统级优化上工程能力的集中体现。ARM提供了一个高效简洁的基础,而苹果在此基础上构建了宽解码、大缓存和统一内存的“摩天大楼”。
六、未来趋势:CPU的下一个五十年
历经半个多世纪的架构迭代,在摩尔定律逐步放缓、物理制程逼近极限的当下,CPU的发展不再局限于单一维度的升级,而是朝着集成化、专业化、开放化、高效化四大方向迈进,勾勒出下一个五十年的核心演进路径:
- 芯片组与3D堆叠:多芯片融合+3D封装,打破二维平面的物理限制,进一步提升集成度与数据传输效率;
- 异构计算:通用核心+专用加速器(AI、加密、视频),针对不同负载做深度优化,告别“通用算力一刀切”;
- 开源架构:RISC-V崛起,打破x86/ARM长期垄断的格局,更好适配物联网、嵌入式等场景的定制化需求;
- 能效优先:在摩尔定律放缓背景下,单纯追求性能已不再现实,性能功耗比成为衡量芯片竞争力的核心指标。
结语
从Intel 4004的2300个晶体管,到M3 Max的920亿个晶体管,CPU架构的进化史就是一部“追求效率”的历史——从堆频率到堆核心,从单芯片到异构集成,每一步都在突破工艺与架构的双重物理极限。
未来,CPU或许不再是传统意义上“单一处理器”,而是由多模块、多算力单元协同工作的计算集群,但贯穿始终的核心使命始终不变:让计算更快、更省、更智能。了解这些架构演进的脉络,有助于我们在云栈社区这样的技术平台中,更深刻地理解当下软硬件技术的底层逻辑与发展方向。
 发表于 2026-3-15 11:45:35
|
查看: 223|
回复: 0
发表于 2026-3-15 11:45:35
|
查看: 223|
回复: 0
