这个问题最早在一次常规的预算审查中被发现。
所有的监控图表看起来都运转正常:流量稳定、请求量稳定、SLO(服务等级目标)也没有任何波动。但月度云服务账单却在缓慢地、持续地上涨。
这不是那种会立刻触发警报的断崖式增长,而是那种“每个月都多一点点”的状态——多到足以让人感到困惑,却又不足以立即引发故障排查。这感觉就像家里的电费越来越贵,但所有灯的亮度却没有任何变化。
一个看似“无聊”的服务
出问题的服务其实非常普通,甚至可以说是那种你希望它一直保持“无聊”状态的核心服务。
它的架构在今天看来相当典型:
- 使用 Go 语言编写的 API 后端
- 无状态设计
- 运行在 Kubernetes 集群上
- 采用容器化部署
- 支持基于指标的自动扩缩容
流量模式也很常规:白天高、夜晚低,遇到促销活动时会出现流量峰值。自动扩缩容的策略由 CPU 和内存使用率驱动。这套系统已经稳定运行了一年多,没有明显的性能问题报告,但计算成本却在不知不觉中缓慢攀升。
常规排查一无所获
我们首先检查了所有常见的可疑点:实例规格是否配置过大、自动扩缩容的阈值是否合理、云厂商的折扣计划是否有变动……结果全部正常。
服务的性能指标也同样健康:延迟(latency)没有增加,错误率(error rate)保持平稳。唯一在持续变化的,只有云账单上的计算成本这一项。
被忽视的“大块头”:二进制文件与容器镜像
后来,我们把目光投向了容器镜像。这个服务是用 Go 编写的,编译后的产物情况如下:
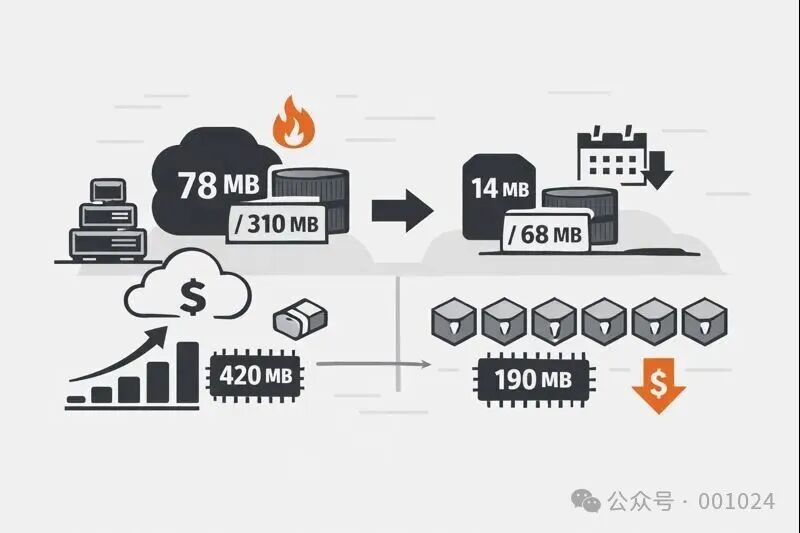
- Go 二进制文件大小:78MB
- 完整的容器镜像大小:约 310MB
这个大小在当时看来并不算特别离谱。Dockerfile 采用了标准的多阶段构建,项目依赖也是随着时间推移逐渐积累起来的,所以大家都没觉得这是个问题。这个庞大的二进制文件就像桌面上积累的灰尘——你每天都能看到它,但绝不会想到它正在悄悄地“烧钱”。
规模效应:当“大小”真正开始计费
真正的转折点,是我们将扩缩容事件与节点周转率(Node Churn) 关联分析之后。
我们发现,当 Kubernetes 因流量增加而触发水平扩展(scale-up)时,过大的容器镜像意味着拉取镜像(Image Pull)的速度更慢。尤其是在新启动的节点或本地缓存未命中的情况下,这一问题尤为突出。
后果是连锁式的:Pod 启动变慢 → 就绪探针(Readiness Probe)延迟响应 → 自动扩缩器(Autoscaler)误以为服务容量不足 → 触发启动更多的 Pod。一个低效的环节在弹性伸缩的机制下被不断放大。
更隐蔽的内存开销
另一个不易察觉的问题是,庞大的二进制文件不仅占用磁盘空间。当它被加载运行时,还会:
- 进入操作系统的页缓存(Page Cache)
- 被映射到进程的常驻内存集(RSS)
这导致每个 Pod 的基础内存占用更高。结果就是:每个物理节点上能够稳定运行的 Pod 数量变少。于是,集群需要启动更多的节点来承载相同的负载,节点的存活时间变长,规模缩减(scale-down)的速度也变慢了。
所有的这些影响都在进行微小的偏移,但成千上百个实例的微小偏移叠加在一起,最终都清晰地体现在了账单上。
行动:从精简二进制文件开始
我们并没有一个宏大的优化计划,最初仅仅是出于技术好奇。第一步是重新审视构建命令,尝试减小二进制体积。
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 \
go build -ldflags="-s -w" -trimpath -o app
这里有几个关键参数:
-ldflags="-s -w":移除调试符号信息(DWARF tables),可以显著减小编译产物体积。-trimpath:从二进制文件中移除构建路径的绝对信息,增强可重现性并略微减小体积。CGO_ENABLED=0:禁用 CGO,进行纯静态编译。这使得我们后续可以使用更小的基础镜像(如 scratch 或 alpine),进一步减小最终容器镜像的层大小。
依赖治理:做减法
接下来是最朴实无华的工作:清理依赖。
我们删除了一个引入大量间接依赖的 metrics 客户端(它意外地拖入了半个 OpenTelemetry 生态)。同时,将一个非必需的第三方 JSON 库替换为标准库 encoding/json,因为后者已完全满足需求。
这里没有高深的算法优化,仅仅是谨慎地做“减法”,移除那些不再需要或可以被更轻量替代的组件。
优化成果:数字会说话
优化后的效果是立竿见影的:
Binary
78MB → 14MB
Container image
310MB → 68MB
二进制文件和容器镜像的体积都缩小了约 80%。
连锁优化:调整运行时配置
在二进制文件变小之后,我们顺势重新审视了容器的运行时配置。
例如,我们之前一直沿用默认的内存限制(Memory Limits)。现在,我们根据优化后应用的实际 RSS 内存占用,设置了更精确、更紧致的限制。同时,我们设置了 GOMEMLIMIT 环境变量,使其值接近容器的内存限制。这有助于 Go 运行时在内存压力增大时更平滑地进行垃圾回收(GC),减少因 GC 导致的延迟毛刺。
启动速度与弹性效益
二进制文件变小带来了直观的启动速度提升:加载更快、内存映射(mmap)操作更少、初始化耗时缩短。
但最显著的变化体现在弹性伸缩的效率上。更小的镜像意味着 Pod 的创建和销毁都更快。Pod 能更快地结束并释放资源,节点也能更快地被集群自动扩缩器释放。整个系统终于能够按照我们最初设想的那样灵敏、高效地响应流量变化。
三十天后的财务复盘
优化部署三十天后,我们对比了数据。在流量模式、系统架构和集群配置均未改变的前提下,结果如下:
Binary
78MB → 14MB
Image
310MB → 68MB
RSS per pod
420MB → 190MB
Pods per node
4 → 8
而最关键的财务指标是:
Monthly cloud cost
$92,000 → $82,000
每月节省了约 10,000 美元。
为什么这类优化在此场景特别有效?
需要说明的是,这类“精简体积”的优化并非在所有系统上都效果显著。其关键在于我们的服务具有两个特征:高度依赖水平扩展和频繁的冷启动。
在这种模式下,任何一个低效的环节(如过大的镜像)都会被复制十次、五十次甚至上百次。默认值或初始设计中的微小低效,在规模化部署下会被急剧放大,从技术债直接转化为可观的财务成本。
那些“无效”的传统优化尝试
一个有趣的反差是,许多我们尝试过的传统性能优化手段,在这次成本攻坚中收效甚微。
例如,对热点代码路径进行微优化、对单个处理器进行基准测试、或者选择更激进的实例类型。这些措施可能提升了极致的性能,但并未改变整体的成本曲线。
这个案例告诉我们,有时节省成本的关键并非在于让代码运行得更快,而是在于让构建产物变得更轻。
组织内的涟漪效应
最早注意到变化的是基础设施(Infra)团队。他们观察到集群节点变得更加稳定,扩缩容事件大幅减少。接着是财务(Finance)部门,他们看到了云账单的意外下降。
当管理层询问“这是哪个成本优化项目带来的成果?”时,真实的答案显得有些“平凡”:仅仅是调整了几个构建参数、删除了几个冗余依赖,并更深入地理解了应用的运行时行为。这件事也让我们团队养成了新的工程习惯,开始持续关注二进制大小、启动行为和内存占用等指标。在云原生时代,这些不再仅仅是“技术细节”,它们本身就是重要的成本变量。
最终的结论很朴素:许多最有效的成本优化,看起来根本不像宏大的“成本优化项目”。它们更像是工程师终于愿意停下来,认真审视并处理那些曾经被认为“太小、不值得关心”的细节。这个过程不仅提升了技术效能,也为 云栈社区 的后端与架构实践积累了宝贵的经验。
 发表于 2026-3-15 11:49:00
|
查看: 195|
回复: 0
发表于 2026-3-15 11:49:00
|
查看: 195|
回复: 0
