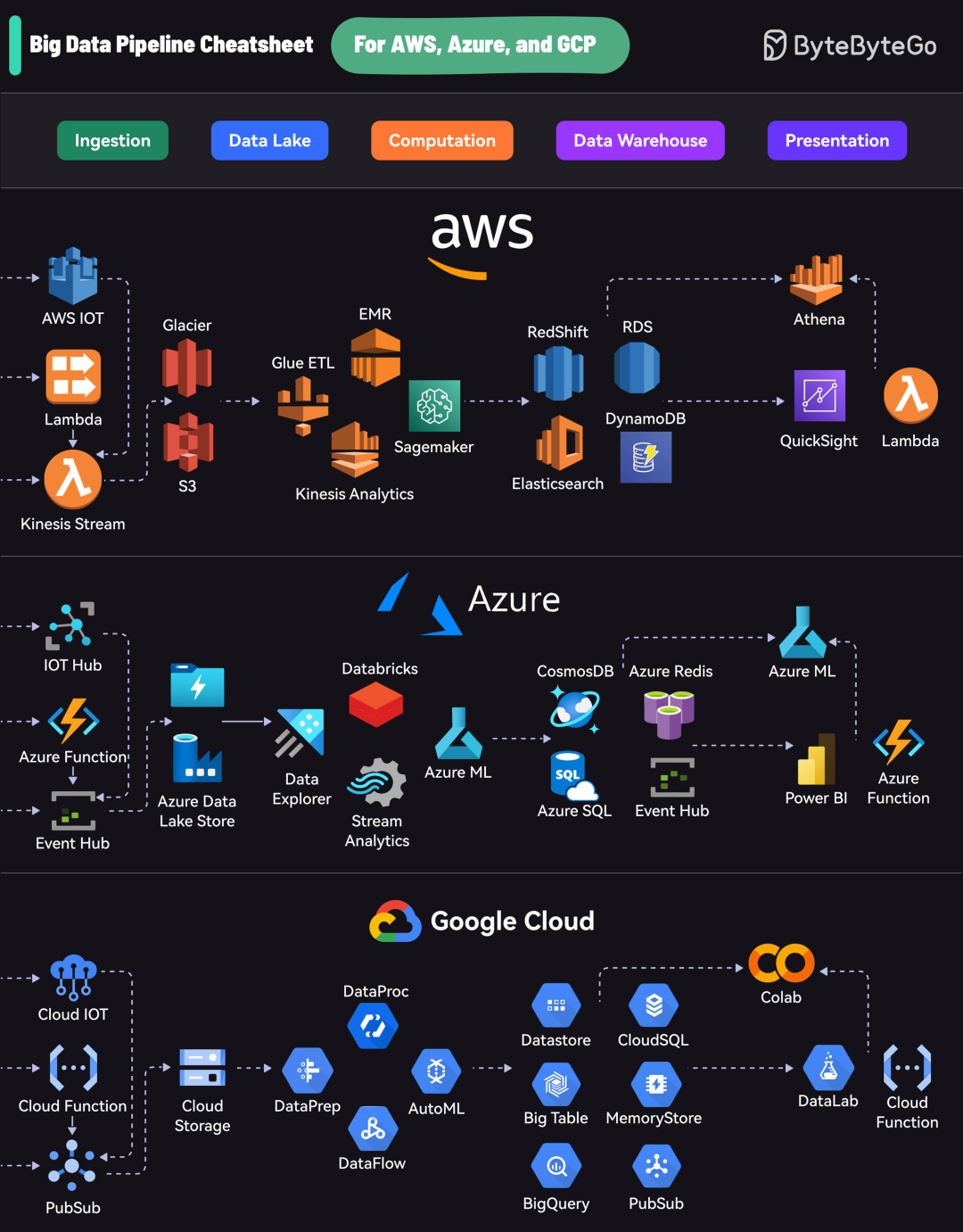
在构建现代化数据平台时,选择合适的技术栈至关重要。作为全球领先的云服务提供商,AWS、Azure 和 Google Cloud (GCP) 都提供了功能齐全的大数据解决方案。本文将对这三家云厂商的数据管道核心组件进行横向对比,帮助你根据自身需求做出更明智的技术选型。
数据管道生命周期
一个典型的大数据处理管道通常包含以下几个关键阶段,它们构成了数据从产生到产生价值的完整旅程:
- 数据采集(Ingestion):将来自不同源头的数据(如日志、设备、数据库)实时或批量地引入系统。
- 数据湖存储(Data Lake):用于存储海量的原始、半结构化和非结构化数据,通常基于低成本的对象存储服务。
- 数据处理(Computation):对存储的数据进行清洗、转换、聚合和分析,包括批处理和流处理。
- 数据仓库(Data Warehouse):将处理后的结构化数据存储起来,支持快速的商业智能(BI)查询和分析。
- 数据可视化(Presentation):将分析结果以图表、仪表盘等形式呈现给最终用户或决策者。
AWS 大数据方案
AWS 拥有最庞大和成熟的云服务生态,其大数据组件经过长时间的市场检验,集成度非常高。
| 阶段 |
服务 |
说明 |
| 采集 |
Kinesis |
用于实时数据流处理和分析。 |
| 存储 |
S3 |
对象存储服务,是构建数据湖的事实标准。 |
| 处理 |
EMR |
托管的 Hadoop/Spark 集群,用于大规模数据处理。 |
| 仓库 |
Redshift |
高性能、完全托管的数据仓库服务。 |
| 可视化 |
QuickSight |
云原生的商业智能和报表工具。 |
主要特点:其生态最为成熟,各类服务之间的集成度也最高,拥有最丰富的第三方工具和社区支持。
Azure 大数据方案
Azure 的优势在于其与微软企业级产品线的无缝集成,对于已经在使用 Microsoft 技术栈的组织来说非常友好。
| 阶段 |
服务 |
说明 |
| 采集 |
Event Hubs |
高吞吐量的事件流处理平台,类似于 Kafka。 |
| 存储 |
Data Lake Store |
专为大数据分析工作负载优化的存储服务。 |
| 处理 |
Databricks |
基于 Apache Spark 的协同数据分析平台,提供卓越的体验。 |
| 仓库 |
Cosmos DB / Synapse |
Cosmos DB 是多模型数据库,Synapse 是集成了数据仓库和大数据分析的统一服务。 |
| 可视化 |
Power BI |
业界领先的商业智能工具,与 Office 365 深度集成。 |
主要特点:与企业 Microsoft 生态(如 Active Directory, Office 365)的集成能力无人能及,Power BI 在企业 BI 市场占据主导地位。
Google Cloud 大数据方案
GCP 在大数据和机器学习领域拥有深厚的技术积累,其服务以强大的性能和先进的设计理念著称。
| 阶段 |
服务 |
说明 |
| 采集 |
Pub/Sub |
全局、高可用的消息队列和流处理服务。 |
| 存储 |
Cloud Storage |
统一的对象存储服务,性能与成本表现均衡。 |
| 处理 |
DataProc / DataFlow |
DataProc 是托管的 Spark/Hadoop 服务,DataFlow 是基于 Apache Beam 模型的流批统一处理服务。 |
| 仓库 |
BigQuery |
无服务器的数据仓库,以其极速的 SQL 查询和分析能力闻名。 |
| 可视化 |
Looker Studio |
免费且功能强大的数据可视化和仪表盘工具。 |
主要特点:BigQuery 在性能上口碑极佳,DataFlow 提供了先进的流批统一编程模型。同时,GCP 对开源技术(如 Kubernetes, TensorFlow)的原生支持最好。
选型建议
没有“最好”的云,只有“最适合”的云。你可以根据以下场景进行选择:
优先考虑 AWS:
- 你的团队需要最成熟、最稳定的生态,并期望有最多的第三方工具和解决方案可供选择。
- 公司现有的基础设施已经大量部署在 AWS 上,希望保持一致性和简化运维。
- 对服务的丰富性和可定制性有较高要求。
优先考虑 Azure:
- 企业内部已经广泛使用 Microsoft 技术栈(如 Windows Server, Active Directory, SQL Server, Office 365)。
- 安全和身份管理需要与企业 AD 深度集成。
- 数据分析团队重度依赖或计划使用 Power BI 作为主要的 BI 工具。
优先考虑 GCP:
- 工作负载重度偏向于大数据分析和人工智能/机器学习。
- 对数据仓库的查询性能有极致要求,希望使用 BigQuery 这样的无服务器方案以简化架构。
- 技术栈以开源为主,尤其是正在使用或计划使用 Kubernetes 和 TensorFlow。
混合云与多云策略
越来越多的企业为了避免厂商锁定并发挥各家所长,开始采用混合或多云策略。例如:
- 数据采集层:使用开源的 Apache Kafka(可部署在任何云或本地),保持入口的灵活性和中立性。
- 存储层:采用 AWS S3 或其兼容协议(如 MinIO)作为统一的数据湖存储,因其接口已成为行业事实标准。
- 处理层:使用 Databricks 这类跨云平台的分析工具,实现计算与存储解耦,一次开发多处运行。
- 分析层:将处理后的数据同步到 GCP 的 BigQuery,利用其卓越的分析性能完成即席查询和报表生成。
这种“最佳组件”组合的方式,能够让你在架构设计上拥有更大的灵活性和议价能力。如果你在进行技术选型时仍有疑惑,或想了解更具体的落地案例,欢迎到 云栈社区 与更多同行交流探讨。 |  发表于 2026-3-15 12:34:27
|
查看: 172|
回复: 0
发表于 2026-3-15 12:34:27
|
查看: 172|
回复: 0
