某电商平台遭遇恶意攻击,黑客用脚本随机生成10亿个不存在的商品ID发起请求,所有请求绕过Redis缓存直接冲击MySQL数据库,导致数据库连接池耗尽、服务瘫痪30分钟——这并非个案,而是缓存穿透具备的典型破坏力。本文将从原理剖析、方案对比、实战落地三个维度,为你拆解对抗Redis缓存穿透的立体防护体系。
一、什么是缓存穿透?
定义:查询一个根本不存在的数据,由于缓存和数据库中都没有该数据,导致每次请求都绕过缓存,直接冲击数据库。
典型场景:
// 黑客恶意攻击示例
for(let i=0; i<10000000; i++){
// 随机生成不存在的商品ID
let fakeId = Math.floor(Math.random() * 999999999);
fetch(`/api/product/${fakeId}`);
}
真实危害:
- 数据库连接池耗尽:10万QPS的无效请求可使MySQL瞬间瘫痪。
- 资源浪费:CPU、连接数被无效请求占用,正常请求得不到处理。
- 服务雪崩:缓存层形同虚设,系统失去性能屏障。
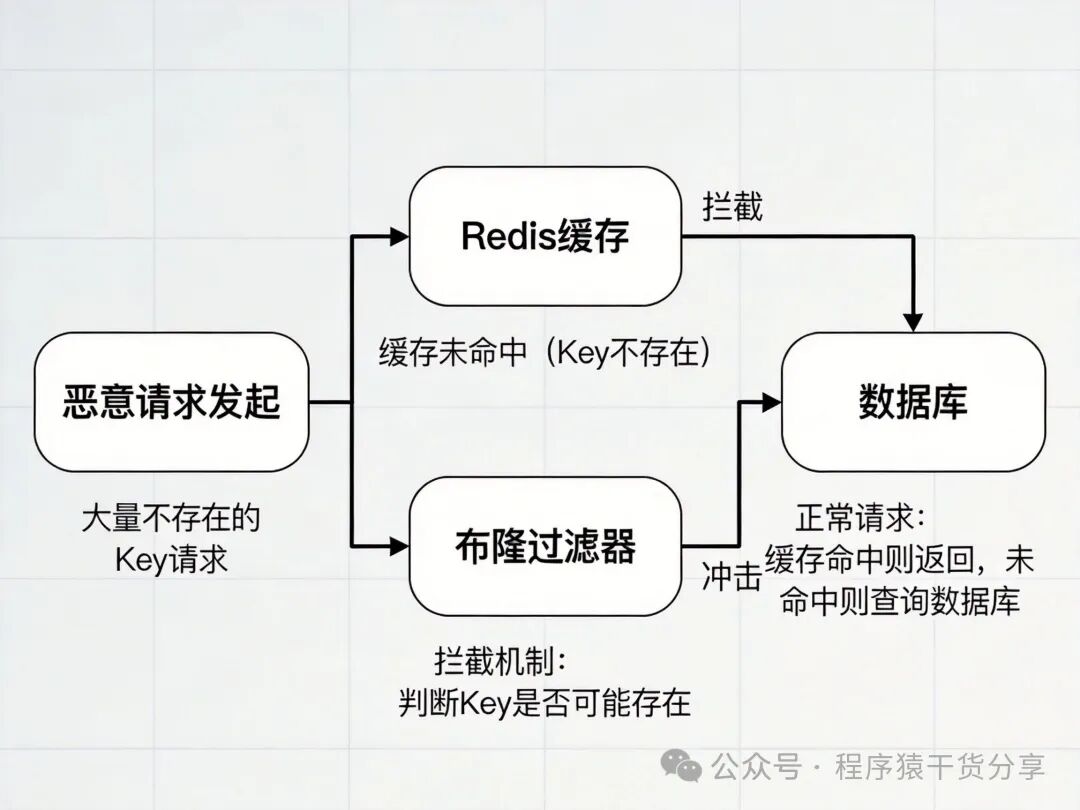
与缓存击穿、雪崩的本质区别:
| 问题 |
本质 |
发生场景 |
核心影响 |
| 缓存穿透 |
数据不存在 |
查询根本不存在的数据 |
绕过缓存直击DB |
| 缓存击穿 |
热点Key过期 |
单个热点Key刚好过期 |
瞬间大并发打崩DB |
| 缓存雪崩 |
大规模失效 |
大量Key同时过期或Redis宕机 |
整体流量冲击DB |
二、解决方案大比拼:布隆过滤器 vs 缓存空对象
面对来势汹汹的无效请求,我们主要有两大武器。选择哪种,取决于你的业务规模和技术储备。
方案一:缓存空对象 (Null Value Caching)
核心思路:当数据库查询结果为空时,系统仍然会将一个“空结果”(如特殊字符串“NULL”)写入缓存,并为其设置一个较短的过期时间(如3-5分钟)。这样,后续对同一个不存在ID的请求,在缓存层就会被拦截。
实现代码
@Service
public class ProductService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private ProductRepository productRepository;
// 缓存空对象的过期时间(短于正常数据)
private static final long NULL_CACHE_EXPIRE_SECONDS = 60;
// 防止缓存穿透的特殊标记
private static final String NULL_VALUE = "NULL";
public Product getProductById(String productId) {
// 1. 先从缓存中获取
String cacheKey = "product:" + productId;
Object cacheValue = redisTemplate.opsForValue().get(cacheKey);
// 2. 缓存存在且不是空标记,直接返回
if (cacheValue != null) {
if (NULL_VALUE.equals(cacheValue)) {
return null; // 返回空对象
}
return (Product) cacheValue;
}
// 3. 缓存不存在,查询数据库
Product product = productRepository.findById(productId).orElse(null);
// 4. 数据库存在,缓存结果
if (product != null) {
redisTemplate.opsForValue().set(cacheKey, product, 30, TimeUnit.MINUTES);
return product;
}
// 5. 数据库不存在,缓存空对象
redisTemplate.opsForValue().set(cacheKey, NULL_VALUE, NULL_CACHE_EXPIRE_SECONDS, TimeUnit.SECONDS);
return null;
}
}
优缺点分析
| 优点 |
缺点 |
| 实现简单,逻辑直观 |
大量无效Key会占用缓存空间,影响命中率 |
| 有效拦截短期重复攻击 |
存在短期数据不一致风险 |
| 无需引入额外组件 |
内存占用较高,大量空值可能挤占正常数据 |
优化建议:务必评估缓存容量,合理设置空值的过期时间(如2-5分钟),避免内存溢出。
方案二:布隆过滤器 (Bloom Filter)
核心思路:在业务逻辑与Redis缓存之间,部署一道名为布隆过滤器的前置防线。系统会预先将数据库中所有存在的Key(如有效的商品ID)通过多个哈希算法映射到一个二进制位数组中。请求到达时,先用布隆过滤器判断Key是否“可能存在”,如果判定“一定不存在”,则直接拒绝,无需查询缓存或数据库。
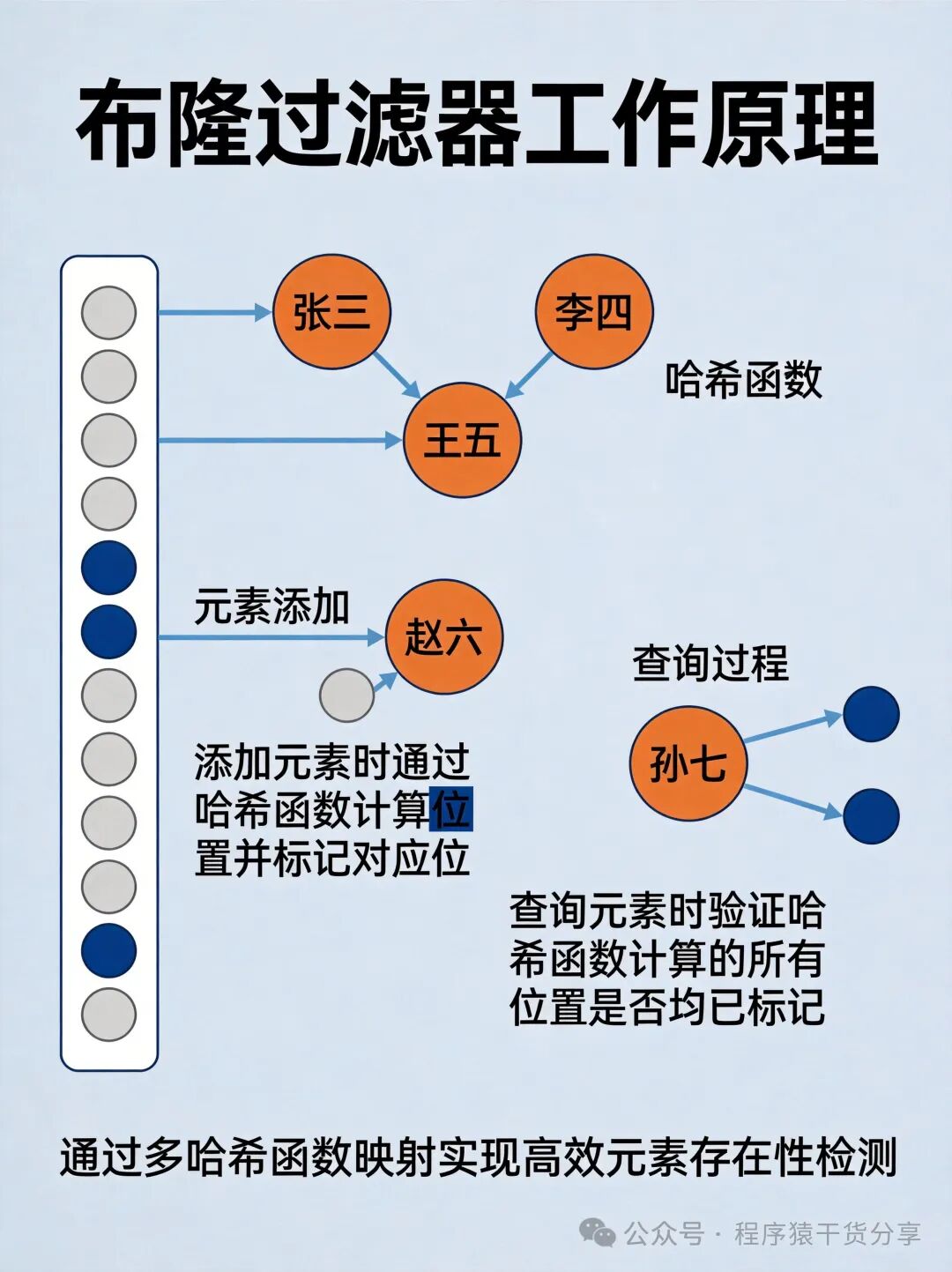
工作原理
布隆过滤器由一个二进制数组 + 多个哈希函数组成:
- 添加元素:将元素传入多个哈希函数,得到多个哈希值,将对应数组位置置为1。
- 判断元素:同样传入多个哈希函数,检查所有对应位置是否全为1——全为1则“可能存在”,有一个为0则“一定不存在”。
核心特性
- ✅ 绝不漏判:若过滤器判定“不存在”,则100%不存在,可安全拦截无效请求。
- ⚠️ 允许误判:可能将不存在的数据误判为存在(但概率可控,如0.1%-1%)。
- ❌ 不支持删除:传统布隆过滤器无法删除元素(需用计数布隆过滤器变种)。
实现代码
方式1:使用Redisson(推荐,开箱即用)
@Configuration
public class BloomFilterConfig {
@Bean
public RBloomFilter<String> productBloomFilter(RedissonClient redissonClient) {
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("product_id_bloom");
// 预计存储100万条商品ID,误判率控制在0.1%
bloomFilter.tryInit(1_000_000L, 0.001);
return bloomFilter;
}
}
@Service
public class ProductService {
@Autowired
private RBloomFilter<String> productBloomFilter;
public Product getProductById(String productId) {
// 1. 布隆过滤器检查(第一道防线)
if (!productBloomFilter.contains(productId)) {
log.warn("Invalid product ID intercepted: {}", productId);
return null; // 直接拦截,无需查询缓存和DB
}
// 2. 查询缓存
String cacheKey = "product:" + productId;
Product product = (Product) redisTemplate.opsForValue().get(cacheKey);
if (product != null) {
return product;
}
// 3. 查询数据库
product = productRepository.findById(productId).orElse(null);
if (product != null) {
// 回写缓存
redisTemplate.opsForValue().set(cacheKey, product, 30, TimeUnit.MINUTES);
} else {
// 缓存空值作为兜底
redisTemplate.opsValue().set(cacheKey, NULL_VALUE, 60, TimeUnit.SECONDS);
}
return product;
}
}
方式2:使用RedisBloom模块(官方推荐,需安装模块)
@Component
public class BloomFilterHelper {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
private static final String BLOOM_KEY = "bloom:user:id";
/**
* 初始化布隆过滤器(应用启动时调用)
*/
@PostConstruct
public void initBloomFilter() {
// 预估用户总量:1亿,误判率1%
long expectedInsertions = 100_000_000L;
double falsePositiveProbability = 0.01;
// 检查是否已存在
Boolean exists = redisTemplate.hasKey(BLOOM_KEY);
if (Boolean.FALSE.equals(exists)) {
// RESERVE key error_rate capacity
redisTemplate.execute((RedisCallback<Object>) connection -> {
Object result = connection.execute(
"BF.RESERVE",
BLOOM_KEY.getBytes(),
String.valueOf(falsePositiveProbability).getBytes(),
String.valueOf(expectedInsertions).getBytes()
);
System.out.println("✅ 布隆过滤器已初始化: " + BLOOM_KEY);
return result;
});
}
}
/**
* 添加用户ID到布隆过滤器
*/
public void addUserToBloom(String userId) {
redisTemplate.execute((RedisCallback<Boolean>) connection ->
(Boolean) connection.execute("BF.ADD", BLOOM_KEY.getBytes(), userId.getBytes())
);
}
/**
* 批量添加用户ID
*/
public void addUsersToBloom(List<String> userIds) {
List<byte[]> args = new ArrayList<>();
args.add(BLOOM_KEY.getBytes());
userIds.forEach(id -> args.add(id.getBytes()));
redisTemplate.execute((RedisCallback<Object>) connection ->
connection.execute("BF.MADD", args.toArray(new byte[0][]))
);
}
/**
* 判断用户ID是否存在
*/
public boolean mightContain(String userId) {
return redisTemplate.execute((RedisCallback<Boolean>) connection ->
(Boolean) connection.execute("BF.EXISTS", BLOOM_KEY.getBytes(), userId.getBytes())
);
}
}
性能对比:布隆过滤器 vs 缓存空对象
| 指标 |
布隆过滤器(100万数据) |
缓存空对象(100万数据) |
提升幅度 |
| 内存占用 |
14.4MB(误判率0.1%) |
>3GB |
节省96%+ |
| 查询延迟 |
平均0.8μs, P99 2.3μs |
平均3.5ms |
降低99%+ |
| 吞吐量 |
125万次/秒 |
5.8万次/秒 |
提升21倍 |
| 误判率 |
0.1% |
0% |
- |
结论:在处理海量无效Key的场景下,布隆过滤器在内存占用、查询延迟、吞吐量三个核心维度上全面碾压缓存空对象方案。
一致性问题与优化
挑战:当数据库新增或删除数据时,必须同步更新布隆过滤器,否则会出现误判(新数据查不到)或漏判(已删数据还能查到)。
解决方案:
- 定时批量同步:每小时或每日,全量同步一次数据库中的有效ID集合到布隆过滤器。
- 增量更新:在数据库写入(新增或逻辑删除)操作完成后,通过消息队列或异步任务更新布隆过滤器。
- 采用变种过滤器:使用Counting Bloom Filter支持元素的删除操作。
三、方案选型与决策树
如何选择?可以遵循以下决策树:
是否遭遇恶意攻击?
├─ 是 → 海量无效Key?
│ ├─ 是 → 布隆过滤器(内存占用极低,性能最优)
│ └─ 否 → 缓存空对象(实现简单,快速落地)
│
└─ 否 → 数据规模?
├─ 大(百万级+) → 布隆过滤器
└─ 小(万级以下) → 缓存空对象
实战建议:组合使用,构建四层防护体系
最佳实践往往是组合拳,为你的系统构建多道防线:
- 接口层校验:过滤非法参数(如ID小于等于0、非数字格式等),从源头拦截。
- 布隆过滤器:拦截绝大部分数据库中不存在的Key(误判率可控在1%以下)。
- 缓存空对象:作为兜底,处理布隆过滤器误判放行的那一小部分Key。
- 热点Key限流:针对数据库查询本身进行限流,作为最后的保护措施。
public Product getProductWithDefense(String productId) {
// 第一层:接口参数校验
if (!isValidProductId(productId)) {
throw new IllegalArgumentException("Invalid product ID");
}
// 第二层:布隆过滤器前置校验
if (!bloomFilter.contains(productId)) {
log.warn("Invalid key intercepted by bloom filter: {}", productId);
return null;
}
// 第三层:查询缓存(含空对象)
String cacheKey = "product:" + productId;
Object cacheValue = redisTemplate.opsValue().get(cacheKey);
if (cacheValue != null) {
if (NULL_VALUE.equals(cacheValue)) {
return null;
}
return (Product) cacheValue;
}
// 第四层:限流保护(使用Redisson)
RRateLimiter rateLimiter = redissonClient.getRateLimiter("rate:product:" + productId);
rateLimiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.SECONDS);
if (!rateLimiter.tryAcquire(1)) {
throw new RateLimitExceededException("Too many requests");
}
// 查询数据库并回写缓存
Product product = productRepository.findById(productId).orElse(null);
if (product != null) {
redisTemplate.opsValue().set(cacheKey, product, 30, TimeUnit.MINUTES);
} else {
redisTemplate.opsValue().set(cacheKey, NULL_VALUE, 60, TimeUnit.SECONDS);
}
return product;
}
四、生产环境实战数据参考
某电商平台优化效果对比
| 指标 |
优化前(无防护) |
优化后(布隆过滤器+多级缓存) |
提升效果 |
| 数据库查询量 |
12万次/秒 |
1.2万次/秒 |
降低90% |
| 平均响应时间 |
180ms |
35ms |
降低79% |
| 服务可用性 |
98.5% |
99.99% |
提升4个9 |
| 资源成本 |
10台数据库服务器 |
3台数据库服务器 |
节省70%成本 |
压测数据对比(测试环境:2核4GB云服务器, Redis 6.2.6集群)
| 防御措施 |
无防护 |
基础防护(空值缓存) |
立体防护(布隆+多级) |
| 数据库峰值QPS |
28,000 |
9,500 |
1,200 |
| Redis连接数峰值 |
5,000 |
3,200 |
800 |
| 错误率 |
23.7% |
5.1% |
0.03% |
| 平均响应时间 |
347ms |
189ms |
52ms |
五、高级优化:从布隆过滤器到布谷鸟过滤器
布谷鸟过滤器 (Cuckoo Filter)
Redis 6.2 引入了官方布谷鸟过滤器模块。相比传统布隆过滤器,它带来了重要改进:
核心优势:
- 支持删除:可以安全删除元素,而不会影响其他元素的判断准确性。
- 空间效率更高:在相同的误判率下,内存占用比布隆过滤器低约30%。
- 查询延迟更低:平均查询延迟约0.65μs,比布隆过滤器降低20%。
性能对比:
| 指标 |
布隆过滤器 |
布谷鸟过滤器 |
提升幅度 |
| 内存占用 |
14.4MB |
10.1MB |
节省30% |
| 查询延迟 |
平均0.8μs |
平均0.65μs |
降低20% |
| 吞吐量 |
125万次/秒 |
154万次/秒 |
提升23% |
| 动态更新支持 |
不支持 |
支持 |
- |
Java实现示例(使用Redisson):
@Configuration
public class CuckooFilterConfig {
@Bean
public RCuckooFilter<String> cuckooFilter(RedissonClient redissonClient) {
RCuckooFilter<String> filter = redissonClient.getCuckooFilter("valid_item_ids");
// 容量1000万,每个桶2个指纹,误判率0.01%
filter.tryInit(10_000_000, 2, 0.0001);
return filter;
}
}
@Service
public class CacheService {
@Autowired
private RCuckooFilter<String> cuckooFilter;
@Autowired
private StringRedisTemplate redisTemplate;
public String getData(String key) {
// 1. 布谷鸟过滤器判断是否存在,不存在直接返回
if (!cuckooFilter.contains(key)) {
log.warn("Invalid key intercepted: {}", key);
return null;
}
// 2. 过滤器命中,查询缓存
String value = redisTemplate.opsValue().get(key);
if (value != null) {
return value;
}
// 3. 缓存未命中,查询数据库并回写缓存(省略数据库查询逻辑)
// ...
return value;
}
}
六、总结与选型建议
| 场景 |
推荐方案 |
核心考虑 |
| 中小规模系统,试错成本低 |
缓存空对象 |
开发成本低,可快速落地验证 |
| 海量数据,且存在恶意攻击风险 |
布隆过滤器 |
内存占用极低,查询性能最优 |
| 金融/支付等高一致性场景 |
布隆过滤器 + 多层防护 + 强同步 |
追求极低的误判率和极高的数据一致性 |
| 快速迭代的业务初期 |
缓存空对象 → 布隆过滤器 |
分阶段演进,先解决问题,再优化架构 |
最佳实践总结:
- 分阶段落地:不必追求一步到位。可先用“缓存空对象”快速上线止血,待业务稳定、数据规模清晰后,再平滑升级到“布隆/布谷鸟过滤器”。
- 监控告警:为缓存未命中率、数据库QPS等关键指标设置监控和告警,以便及时发现潜在的穿透攻击或方案缺陷。
- 参数调优:布隆过滤器的误判率和容量是需要权衡的关键参数。根据业务对准确性的要求(误判率)和未来的数据增长(容量)进行精细调整。
- 组合防护:没有银弹。结合接口校验、过滤器、空值缓存、限流等多种手段,才能构建起应对缓存穿透的立体防护网,确保核心数据库的稳定。
解决缓存穿透是构建健壮高并发系统的必备技能。希望本文提供的从原理到代码的完整方案,能帮助你根据自身业务特点做出最合适的技术选型。如果你想深入探讨分布式系统中的其他经典问题,例如缓存击穿、雪崩,或者高并发场景下的其他设计模式,欢迎在云栈社区与更多开发者交流实战经验。
 发表于 2026-3-15 12:39:47
|
查看: 234|
回复: 0
发表于 2026-3-15 12:39:47
|
查看: 234|
回复: 0
