大多数低时延高频交易系统设计的核心要点可以归结为:单进程配合多线程,在行情接收环节采用多线程并发处理,而在核心业务逻辑(如因子计算、策略执行)环节则采用单线程串行处理。其核心设计思想往往可以归纳为下图所示的流程:
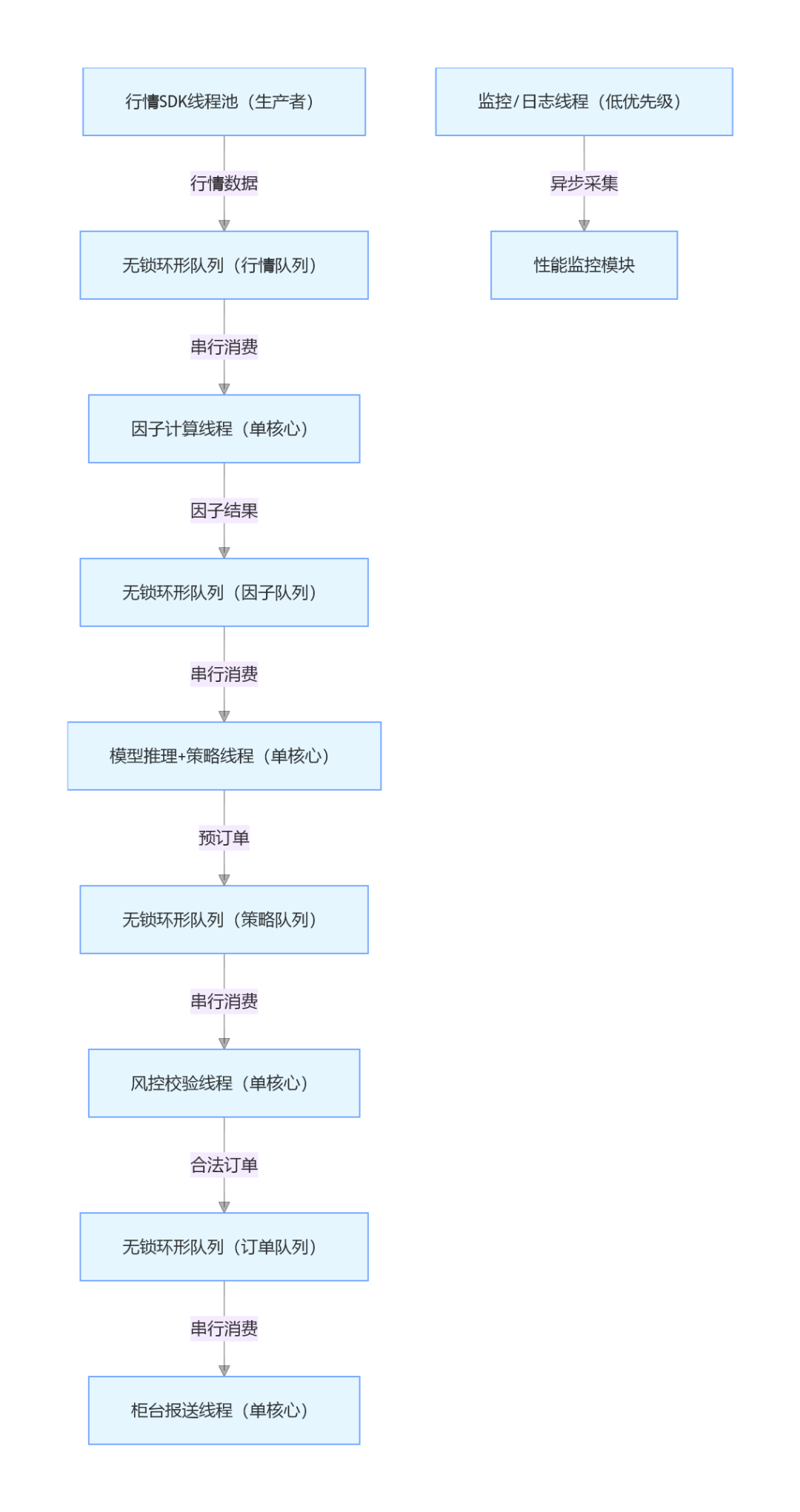
本篇内容将从系统的第一个关键模块——行情接收讲起,探讨如何通过有序队列的设计,将多线程并发接收到的、可能乱序的行情数据,有序且低时延地传递到下游需要单线程串行处理的核心模块。
在设计并发接收行情数据的多线程架构时,通常会面临两种“无序风险”:
- 不同线程接收的不同股票行情可能乱序:这通常对业务逻辑没有直接影响。
- 同一线程接收的同一支股票的行情,可能因网络延迟或行情SDK回调时序问题导致时间戳乱序:这会对依赖时间序列的策略产生严重影响。
因此,我们设计有序队列的核心目标非常明确:
- 保证单支股票的行情按时间戳严格递增,并将全局行情以“股票+时间戳”有序的方式交付给下游的单线程串行核心模块。
- 在整个处理链条中实现全程无锁,以满足极致的低时延要求。
如下图所示,虽然行情源(FPGA、裸协议、UDP/TCP等)和接入方式因供应商而异,但从SDK回调开始的高频交易系统内部设计,其架构通常可以分为三层来处理上述问题:

第一层:接收线程私有的无锁队列 (SPSC)
每个并发接收线程都独占一个SPSC (Single Producer Single Consumer) 无锁队列。行情SDK的回调数据直接写入该线程的私有队列,完全避免了跨线程竞争。这种“单生产者(接收线程)+ 单消费者(排序线程)”的模式是实现纳秒级入队/出队操作、保证极致低时延的基础。
以下是该无锁环形队列的一个核心示例实现(注:对接具体行情源SDK的功能性代码已省略):
// 单生产者单消费者无锁环形队列(核心:无锁、固定容量、缓存对齐)
template <typename T, size_t CAPACITY>
class SPSCRingBuffer {
private:
alignas(64) std::array<T, CAPACITY> buffer_; // 64字节对齐,避免缓存行伪共享
alignas(64) std::atomic<size_t> write_idx_{0}; // 写指针(生产者可见)
alignas(64) std::atomic<size_t> read_idx_{0}; // 读指针(消费者可见)
public:
// 生产者入队(非阻塞,失败返回false)
bool push(const T& data) noexcept {
size_t curr_write = write_idx_.load(std::memory_order_relaxed);
size_t next_write = (curr_write + 1) % CAPACITY;
if (next_write == read_idx_.load(std::memory_order_acquire)) {
return false; // 队列满,行情溢出(需做容错)
}
buffer_[curr_write] = data;
write_idx_.store(next_write, std::memory_order_release);
return true;
}
// 消费者出队(非阻塞,失败返回false)
bool pop(T& data) noexcept {
size_t curr_read = read_idx_.load(std::memory_order_relaxed);
if (curr_read == write_idx_.load(std::memory_order_acquire)) {
return false; // 队列空
}
data = buffer_[curr_read];
read_idx_.store((curr_read + 1) % CAPACITY, std::memory_order_release);
return true;
}
};
// 每个接收线程绑定私有队列
struct RecvThreadData {
std::jthread recv_thread;
SPSCRingBuffer<MarketData, 8192> private_queue; // 预分配8192个行情容量
};
std::array<RecvThreadData, 4> recv_threads; // 4个接收线程(匹配网卡队列数)
第二层:线程级排序缓冲区
这一层设计至关重要。即使由同一个线程接收同一支股票的行情,也可能因为SDK回调延迟、网络拥塞等不可控因素,导致时间戳乱序(例如先收到t+2时刻的行情,后收到t+1时刻的行情)。为了解决这个问题,我们需要为每支股票维护一个“时间戳排序缓冲区”(通常实现为环形数组),先将行情缓存起来,再按照时间戳递增的顺序输出。
示例代码如下:
// 单股票的时间戳排序缓冲区
struct StockSortBuffer {
std::array<MarketData, 128> buffer; // 缓存最近128条行情
size_t size = 0;
int64_t last_timestamp = 0; // 上一次输出的时间戳
// 插入行情并按时间戳排序(仅在缓冲区满/超时触发)
bool insert_and_sort(const MarketData& md) noexcept {
if (size >= buffer.size()) {
return false; // 缓冲区满,需扩容或丢弃
}
// 插入到对应位置(简单插入排序,仅128条数据,开销可忽略)
size_t i = size++;
for (; i > 0 && buffer[i-1].timestamp > md.timestamp; --i) {
buffer[i] = buffer[i-1];
}
buffer[i] = md;
return true;
}
// 输出有序行情(仅输出比last_timestamp大的)
bool pop_ordered(MarketData& md) noexcept {
if (size == 0) return false;
if (buffer[0].timestamp > last_timestamp) {
md = buffer[0];
last_timestamp = md.timestamp;
// 前移数据(仅128条,低开销)
for (size_t i = 1; i < size; ++i) {
buffer[i-1] = buffer[i];
}
size--;
return true;
}
return false; // 暂无可输出的有序行情
}
};
// 线程级排序工作函数(每个接收线程对应一个排序线程)
void sort_worker(int thread_id) noexcept {
RecvThreadData& thread_data = recv_threads[thread_id];
// 为该线程负责的股票预分配排序缓冲区(按股票代码哈希映射)
std::unordered_map<std::string, StockSortBuffer> stock_buffers;
MarketData md;
while (true) {
// 1. 从私有队列读取原始行情
if (thread_data.private_queue.pop(md)) {
// 2. 找到该股票的排序缓冲区(不存在则创建)
auto& buffer = stock_buffers[md.stock_code];
buffer.insert_and_sort(md);
// 3. 尝试输出有序行情到全局分发队列
MarketData ordered_md;
while (buffer.pop_ordered(ordered_md)) {
global_mpsc_queue.push(ordered_md);
}
} else {
_mm_pause(); // 自旋等待,比阻塞低时延
}
}
}
第三层:全局有序分发队列 (MPSC)
此队列负责将已经按股票、按时间戳排序好的行情,分发给下游需要单线程串行处理的核心模块(如因子计算引擎)。我们可以用C++ 实现的MPSC (Multi Producer Single Consumer) 无锁队列 来替代有锁的 std::queue,具体性能提升需结合实际场景测试。
这层设计的关键在于:多个排序线程可以并发地向此队列入队数据而无需加锁;下游的串行核心模块独占出队权限,从而保证了全局消费的有序性。由于单支股票的行情已经在第二层被严格排序,所以即使不同股票之间的行情在全局队列中的顺序是交错的,也不会影响业务逻辑。
示例代码如下:
// 多生产者单消费者无锁队列(核心:基于链表,无锁入队)
template <typename T>
class MPSCRingQueue {
private:
struct Node {
T data;
std::atomic<Node*> next{nullptr};
};
alignas(64) std::atomic<Node*> head_; // 消费者可见
alignas(64) std::atomic<Node*> tail_; // 生产者可见
std::atomic<size_t> size_{0};
public:
MPSCRingQueue() {
Node* dummy = new Node;
head_.store(dummy, std::memory_order_relaxed);
tail_.store(dummy, std::memory_order_relaxed);
}
// 多生产者入队(无锁)
bool push(const T& data) noexcept {
Node* new_node = new(std::nothrow) Node{data};
if(!new_node) return false;
Node* old_tail = tail_.load(std::memory_order_acquire);
while(!tail_.compare_exchange_weak(old_tail, new_node,
std::memory_order_release, std::memory_order_relaxed)) {
old_tail = tail_.load(std::memory_order_acquire);
}
old_tail->next.store(new_node, std::memory_order_release);
size_.fetch_add(1, std::memory_order_relaxed);
return true;
}
// 单消费者出队(无锁)
bool pop(T& data) noexcept {
Node* old_head = head_.load(std::memory_order_acquire);
Node* next = old_head->next.load(std::memory_order_acquire);
if(!next) return false;
data = next->data;
head_.store(next, std::memory_order_release);
delete old_head;
size_.fetch_sub(1, std::memory_order_relaxed);
return true;
}
};
// 全局MPSC队列(所有排序线程生产,串行核心消费)
MPSCRingQueue<MarketData> global_mpsc_queue;
// 串行核心工作函数(因子/模型/策略)
void serial_core_worker() noexcept {
MarketData md;
while(true) {
// 从全局队列读取有序行情(自旋等待,低时延)
while(!global_mpsc_queue.pop(md)) {
_mm_pause();
}
// 执行因子计算/模型推理/策略逻辑(单线程,无锁)
calculate_factor(md);
model_inference(md);
strategy_logic(md);
}
}
设计要点梳理与优化总结
核心架构要点:
- 单线程私有队列接收行情:每个并发接收线程使用无锁环形队列 (SPSC) 接收原始行情,从源头避免跨线程竞争。
- 单股票按时间戳排序:为每支股票维护独立的排序缓冲区,确保单股票行情严格按时间戳递增输出。
- 全局MPSC队列分发:利用多线程并发入队、单线程串行出队的MPSC队列,实现“并发接收、有序交付”的最终目标。
关于“有序”的保证:
- 单股票时间戳递增:排序缓冲区只输出比上一次时间戳更大的行情。
- 多线程入队不破坏有序性:通过股票代码哈希路由,确保同一支股票的行情始终由同一个排序线程处理。
- 全局消费有序:串行核心线程独占出队权,按FIFO顺序消费。由于单股票内部已有序,全局队列中不同股票间的顺序不影响业务。
低时延优化要点(需结合性能测试持续调整):
- 自旋替代阻塞:核心线程在队列空时使用
_mm_pause() 自旋等待,避免 pthread_cond_wait 等系统调用引入的微秒级延迟。
- 内存预分配:队列节点、行情对象均从预分配的自定义内存池中获取,彻底避免运行时
new/delete 的系统开销。
- 缓存对齐:队列的读写指针、关键数据结构均进行64字节对齐,有效防止CPU缓存行伪共享(False Sharing)导致的性能下降。
- 批量处理:排序缓冲区在攒够一定数量(如128条)或超时(如100μs)时,才批量输出有序行情,减少入队/出队操作的频率。
- 溢出容错:当私有队列或排序缓冲区满时,采取丢弃最旧行情(而非阻塞生产者)的策略,优先保证行情接收的实时性。
这套从并发到串行、层层递进的无锁队列设计模式,是构建高性能低时延系统的基石之一。希望本文的探讨和代码示例能为你在设计类似系统时提供一些切实可行的思路。如果你对多线程编程或高性能C++ 有更多兴趣,欢迎到 云栈社区 的相应板块与更多开发者交流探讨。
 发表于 2026-3-15 12:30:09
|
查看: 230|
回复: 0
发表于 2026-3-15 12:30:09
|
查看: 230|
回复: 0
