深挖一些实战中的细节和技巧。很多朋友觉得SRC漏洞挖掘就是拿着扫描器一顿猛扫,其实不然。真正能挖到高危、拿到高额奖金的那些人,往往在信息收集和细节处理上投入了更多功夫。下面我将自己这几年来积累的一些关键经验分享出来,希望能给正在这条路上探索的你带来一些启发。
一、子域名收集:别小看SSL证书
子域名收集算是老生常谈了,但方法不同,效果简直是天差地别。我早年挖某个大厂的SRC挖了两年,自以为把他们的域名摸了个底朝天。直到我系统性地用上了基于SSL证书的查询方法,才发现自己之前漏掉了多少“宝藏”。
目前比较好用的证书查询网站主要有:
这两个网站通过持续扫描全网的SSL证书,能帮你挖掘出某个主域名下的所有子域名,其中不乏一些常规工具根本枚举不到的二级、三级甚至更深层级的域名。原理其实很简单:绝大多数支持HTTPS的站点都需要申请证书,而证书的“使用者可选名称”(SAN)字段里就包含了完整的域名信息。这些证书数据被Censys和crt.sh这样的平台收集索引后,就成了我们免费且高质量的子域名字典。
除了证书查询,还有一些第三方数据接口和工具也非常好用,可以组合使用:
- riskiq
- shodan
- findsubdomains
- dnsdb.io
这几个平台各有侧重,组合使用能让你的信息收集网更加严密。
实战案例分享
有一次,我在crt.sh上查到了一个二级域名 nss.a.com(已脱敏)。用常规的子域名爆破工具去扫,什么都没发现。但我没有轻易放弃,转而把这个二级域名丢到GitHub上进行代码搜索。结果,在一个公开的代码仓库里,我找到了一个引用该域名的三级域名接口地址,类似 http://nss.a.com/api/v1/test。

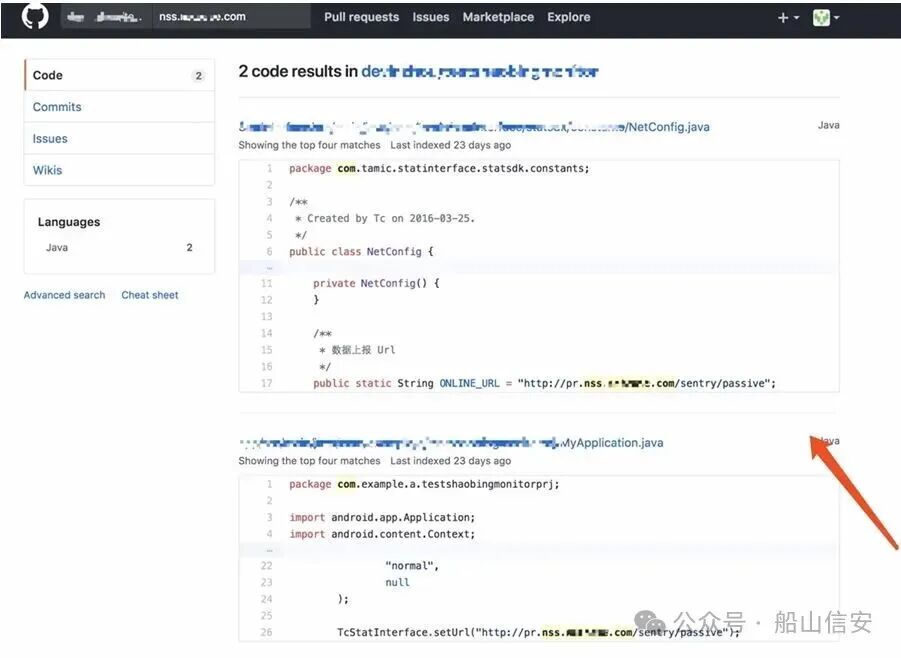
直接访问这个接口,页面提示缺少参数,并且参数名直接在报错信息里暴露了出来。我根据代码上下文和报错提示,构造了正确的JSON请求头,成功调通了这个API。

这时候,一个关键发现让我警觉起来:这个接口使用的JSON解析库是fastjson。它会不会存在反序列化漏洞?我立刻构造了一个Payload进行测试,果然一击即中,直接获取到了内网的访问权限。

这个案例清晰地告诉我们:子域名收集仅仅是万里长征的第一步。后续结合GitHub等平台的代码审计、对发现的接口进行深入测试,往往能挖出那些意想不到的高危漏洞。
二、IP段收集:巧用CNNIC Whois
拿到了域名,下一步就是搞清楚目标厂商的IP地址段,这是进行后续端口扫描的基础。很多人习惯直接ping一下域名,拿到一两个IP就开始扫,这其实很片面。对于大型互联网公司,其业务可能分布在非常广泛且分散的IP段里。
我常用的一个高效方法是使用 CNNIC IP地址注册信息查询系统(http://ipwhois.cnnic.net.cn/)。操作很简单:先找一个已知属于目标公司的IP(比如通过其官网域名解析获得),例如 123.58.191.1,丢进去查询。查询结果会显示这个IP所属的“网络名称”,比如“Netease-Network”。

接下来,你就可以用这个“网络名称”作为条件进行二次查询,系统会把归属于这个网络名称下的所有IP地址段都列出来。像网易这样规模的公司,其网络名称可能不止一个。虽然CNNIC的官方接口不支持模糊查询,但我们可以手动多尝试几个可能的关键词,比如公司英文名、常用缩写等,尽可能把能关联到的IP段都收集齐全。这样一来,你的端口扫描目标池就会丰富、准确得多。
三、端口扫描:masscan + nmap 的进阶玩法
面对收集到的大批量IP地址,我通常的扫描策略是:masscan进行全端口快速扫描 + nmap进行精准服务识别。关于基础操作,网上有很多优秀文章,这里不再赘述。
但在实际的大规模扫描中,我经常遇到一个恼人的问题:有些服务器前面部署了WAF(Web应用防火墙)。当masscan扫描这些IP时,WAF可能会拦截并返回大量虚假的“开放端口”响应,一扫描就显示开放了成百上千个端口,这完全是干扰信息。如果等它全部扫描完再进行人工判断,会浪费大量时间。
我的解决办法是:动态监控masscan的输出。具体思路是设定一个阈值(比如80),然后使用Python的subprocess模块实时抓取masscan在终端打印的“found=xx”信息。一旦程序发现当前正在扫描的IP其报告的开放端口数超过了预设的阈值,就立即kill掉这个扫描进程,跳过该IP,继续扫描下一个。这样可以极大提升效率,快速过滤掉WAF的干扰。
实现这个逻辑的示例代码如下:
import re, subprocess, os
limitNumber = 80
command = 'masscan 59.111.14.159 -p1-65535 --rate 2000'
child = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, shell=True)
while child.poll() is None:
output = child.stdout.readline()
line = str(output, encoding='utf-8').strip()
if 'found=' in line:
print(line)
foundNumber = re.findall(r'found=(\d{1,5})', line)
if int(foundNumber[-1]) > limitNumber:
os.kill(child.pid, 9)
print('疑似有WAF!存活端口' + foundNumber[-1] + '个')
break
注意:如果你使用 -oX 或 -oJ 参数让masscan直接将结果输出到文件,就无法实时捕获到终端输出了。因此这里采用监控标准输出的方式,扫描完成后再用正则从日志中提取最终的端口信息。
masscan跑完,得到了干净的开放端口列表后,就该nmap上场进行深度服务识别了。我常用的命令组合如下:
nmap -sV -sT -Pn --version-all --open <target>
-sV:探测服务及版本信息。-sT:全连接扫描(TCP Connect Scan)。这种方式不需要root权限,虽然速度比SYN扫描慢一些,但在普通用户权限下就能执行,通用性更好。-Pn:跳过主机发现(Ping扫描)。因为masscan已经确认主机是存活的,这里可以节省时间。-open:只显示状态为“开放”的端口。-version-all:对每个端口尝试所有版本的探测脚本,提高服务识别准确率。
服务识别出来后,针对不同的服务(如HTTP、Redis、MySQL等)进行常规的安全测试,那就是各位安全研究者各显神通的时候了,这里就不再展开。
写在最后
SRC漏洞挖掘本质上是一场比拼耐心、细心和经验的持久战。无论是前期的信息收集、字典的积累,还是扫描测试技巧的持续优化,都需要在一次次实战中不断总结和沉淀。希望我分享的这几条关于信息收集和网络资产梳理的实战经验,能为你打开一些新的思路。
 发表于 2026-3-15 16:17:56
|
查看: 261|
回复: 0
发表于 2026-3-15 16:17:56
|
查看: 261|
回复: 0
