本文旨在复现“量涌波动率”因子。该因子来源于民生证券叶尔乐老师在2025年5月8日发布的研报《量化专题报告:日内“动量脉冲”与股价过度反应的精细刻画》。
在复现此因子之前,我曾复现过同一篇研报中的另一个因子——“偏峰涨跌幅”。这个“量涌波动率”因子在2026年的《因子日历》中,其逻辑被描述为:
“量涌波动率”刻画不同交易情绪投资者对股票收益率的影响程度,波动率越小,说明不同情绪投资者对股票收益率的影响基本一致,更不容易出现过度反应的现象,股票的“区段收益稳定性更强”,股票未来收益率更高;反之,股票的“区段稳定性”更弱,股票未来收益率更低。
计算步骤和代码
在初次复现叶老师的因子时,我就注意到他的风格与方正证券的曹春晓老师有些相似,至少在因子的计算步骤上体现得比较明显。因此,这个因子的计算过程也相对复杂。
1. 总体分析
第一步:循环时段划分。
采用二分法的思想,循环对每只股票按照成交量峰值时刻对时段进行划分(剔除开盘的10分钟,因为这个时间段成交较为活跃,会使得这些时间内时段较为密集从而影响结果)。划分时有四种情况:
- 时段只包含一分钟数据,不划分。
- 时段包含两分钟数据,每一分钟各划分为一个时段。
- 时段包含三分钟数据,前两分钟划分为一个时段,第三分钟为另一个时段。
- 时段包含四分钟及以上的数据,剔除时段第一分钟和最后一分钟后取成交量最大时刻,将第一分钟到成交量最大时刻划分为第一个时段,剩下的是第二时段。
第二步:计算波动率。 对每只股票计算步骤1中划分得到的每个小时段的收益率,并计算这些区间收益率的标准差,作为该股票当日因子值。
第三步:高频因子低频化。 计算步骤2中得到的日频因子标准化后,计算过去20天的标准差,记为“量涌波动率”因子。
2. 项目重点
以下是核心实现代码。第一段代码主要负责读取数据,并顺便计算了高频波动率,以便后续与量涌波动率进行相关性分析。
def process_single_day(self, idx):
file_name = self.files[idx]
date_str = file_name.split('.')[0]
cur = pd.to_datetime(date_str) + timedelta(hours=15)
file_name = self.files[idx]
full_path = os.path.join(self.file_pth, file_name)
data = BaseDataLoader.load_data(full_path, fields=['close', 'volume'])
close = data.to_dataframe('close')
sigma = (close.pct_change()).std()
res = []
for i in range(len(data.codes)):
res.append(self.cal_factors(data.data[10:, :, i], data.data[9, 0, i]))
res = pd.Series(res, index=data.codes)
res = pd.concat([res, sigma], axis=1)
res.columns = ['surge_volatility', 'volatility']
res['datetime'] = cur
return res
上述代码的第11-12行是核心,调用了 cal_factors 方法来计算量涌波动率。真正的计算逻辑如下:
@staticmethod
def cal_factors(data, last_price):
price, volume = data[:, 0], data[:, 1]
max_idx = np.argmax(volume) + 1
if max_idx == len(price):
last_interval = [[0, max_idx]]
else:
last_interval = [[0, max_idx], [max_idx, len(price)]]
for i in range(5):
tmp_interval = []
for start, end in last_interval:
if end - start == 1:
tmp_interval.append([start, end])
continue
if end - start == 2:
tmp_interval.append([start, start+1])
tmp_interval.append([start+1, end])
elif end - start == 3:
tmp_interval.append([start, start + 2])
tmp_interval.append([start + 2, end])
else:
max_idx = np.argmax(volume[start+1:end-2])
max_idx += start + 2
tmp_interval.append([start, max_idx])
tmp_interval.append([max_idx, end])
last_interval = sorted(tmp_interval)
last_interval = np.array(last_interval)
start_price = price[last_interval[:, 0] - 1]
start_price[0] = last_price
end_price = price[last_interval[:, 1] - 1]
rtn = end_price / start_price - 1
return np.nanstd(rtn)
cal_factors 方法接收两个参数:data 是一个二维 numpy 数组(维度为230*2);last_price 是第9分钟的收盘价。
- 第4-8行: 进行第一次划分。直接取成交量最大值的索引并加1(因为成交量最大的时刻要划分到前一个时段)。需要注意的是,如果最大值出现在最后一分钟,则整个时段不再划分,只有一个区间。
- 第11-25行: 执行第2到第6次划分(共划分六次,研报中提及此数字)。这部分代码对应四种划分情况:
- 第12-14行:对应“只包含一分钟数据”的情况。
- 第15-17行:对应“包含两分钟数据”的情况。
- 第18-20行:对应“包含三分钟数据”的情况。
- 第21-25行:对应“至少包含四分钟数据”的情况。
- 第27-32行: 计算量涌波动率。重点是第29行,用起始价格和结束价格计算每个划分区间的收益率,最后返回这些收益率的标准差。
因子评价
首先,我们来看量涌波动率与高频波动率因子的相关性。
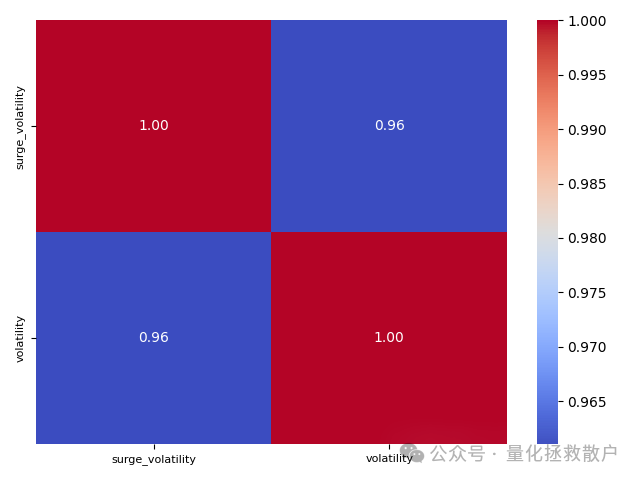
上图计算的是因子收益率之间的相关性,可以看出量涌波动率(surge_volatility)和传统波动率(volatility)因子的相关性极高,均超过0.95。如果计算截面斯皮尔曼秩相关系数,两者的相关性也有0.76,依然不低。
研报中提到需对日频因子“标准化”后再计算20日标准差。此处的“标准化”我理解为截面Z-Score标准化。出于验证,我也尝试了直接计算原始值的标准差和均值进行低频化的方法。从IC结果看,三种方式差异不大,但在分层回测表现上,采用研报方法(先标准化)进行低频化后效果更优。
01 IC分析
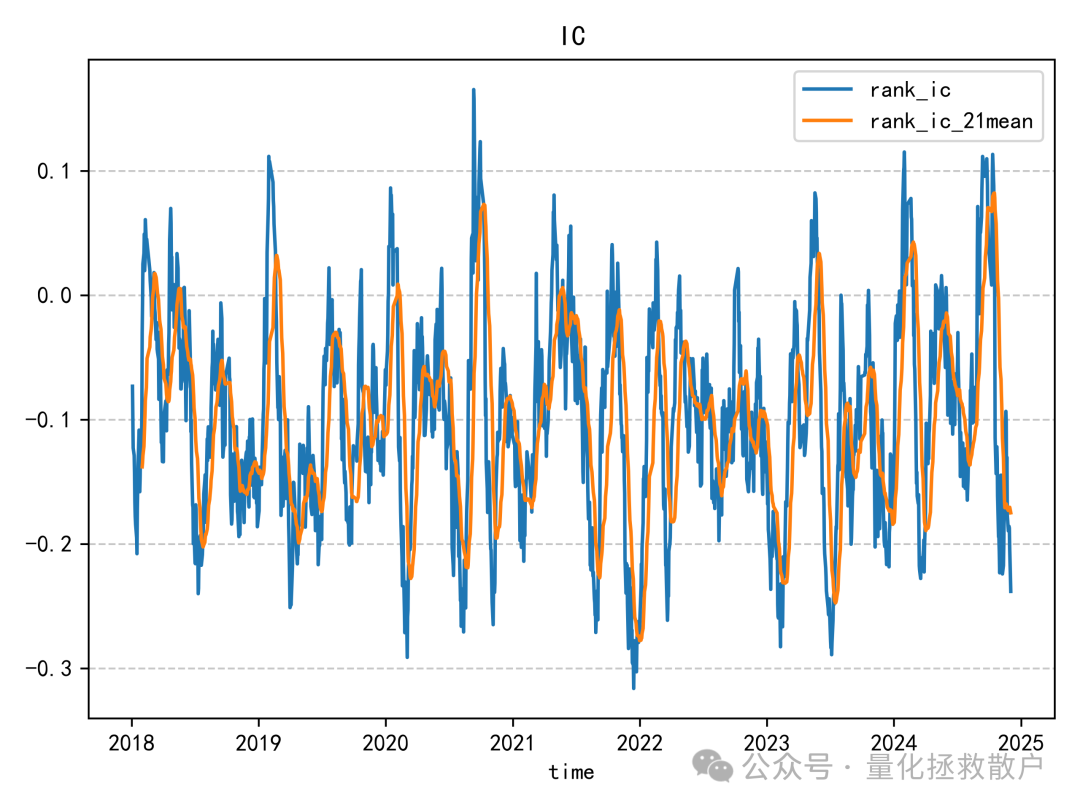
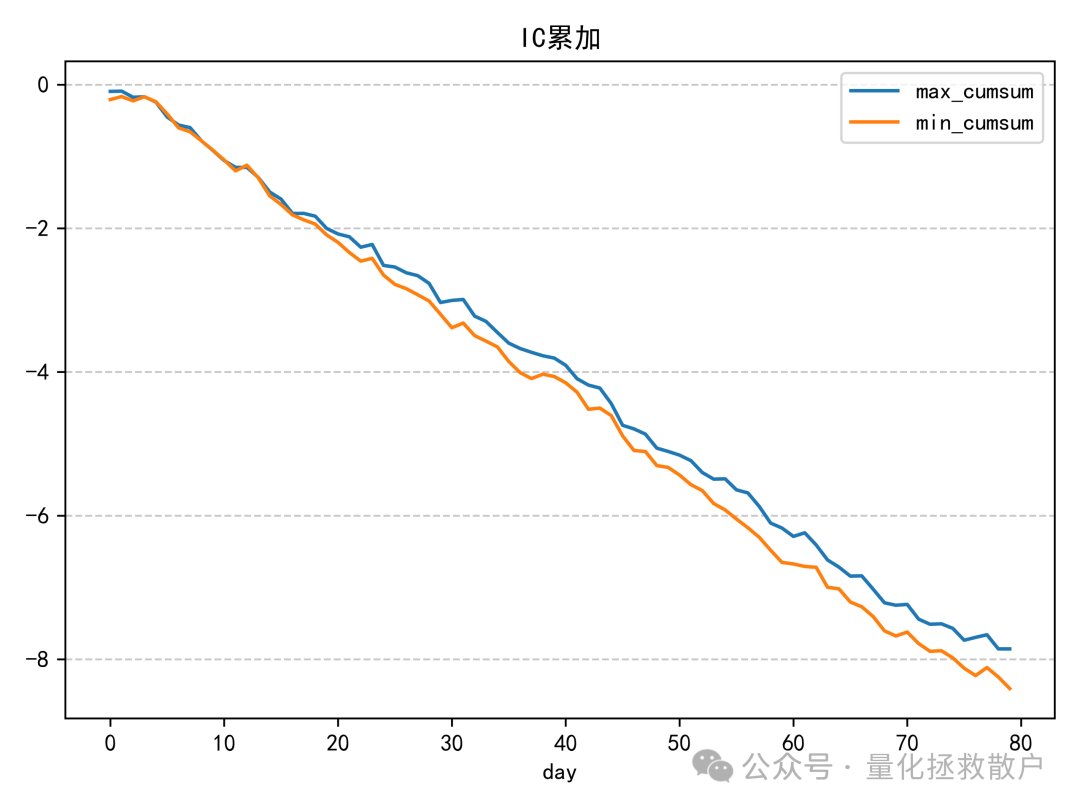
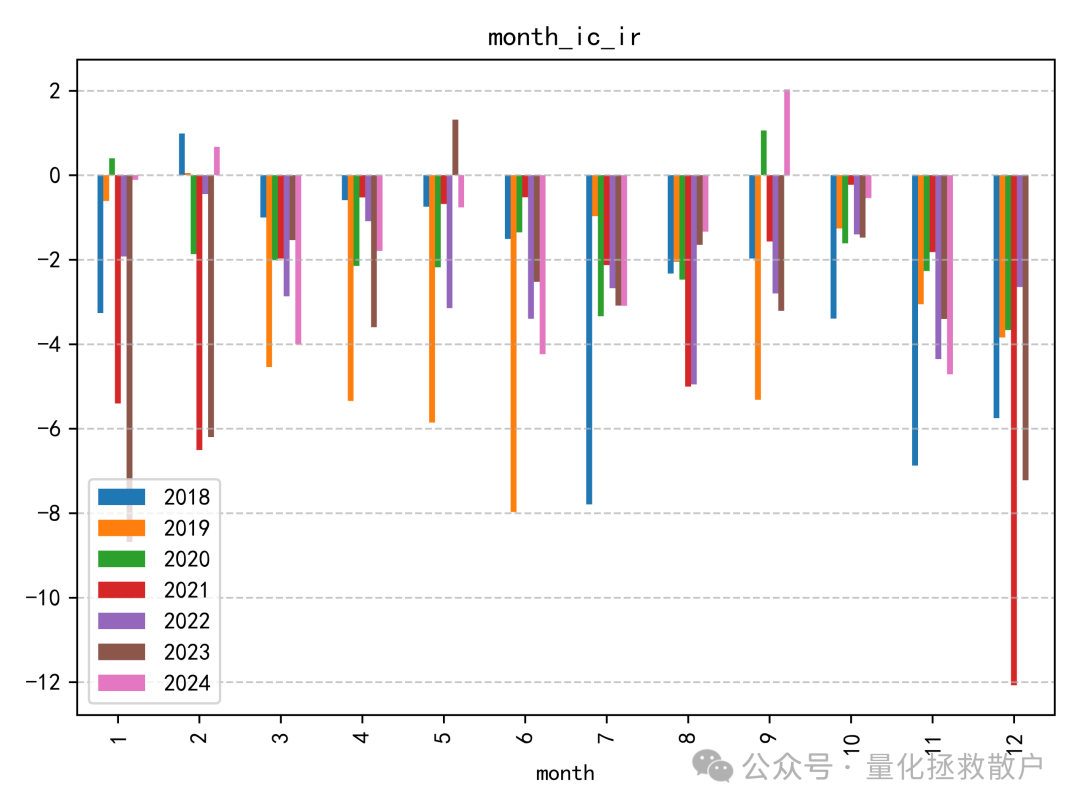
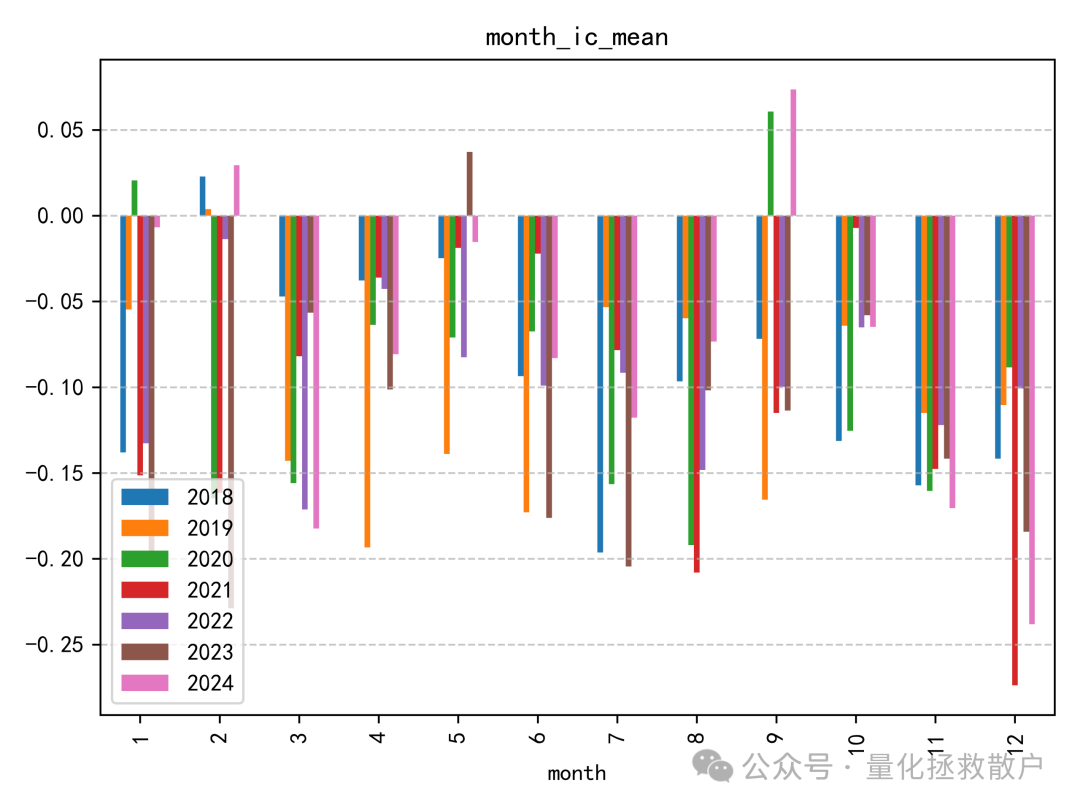
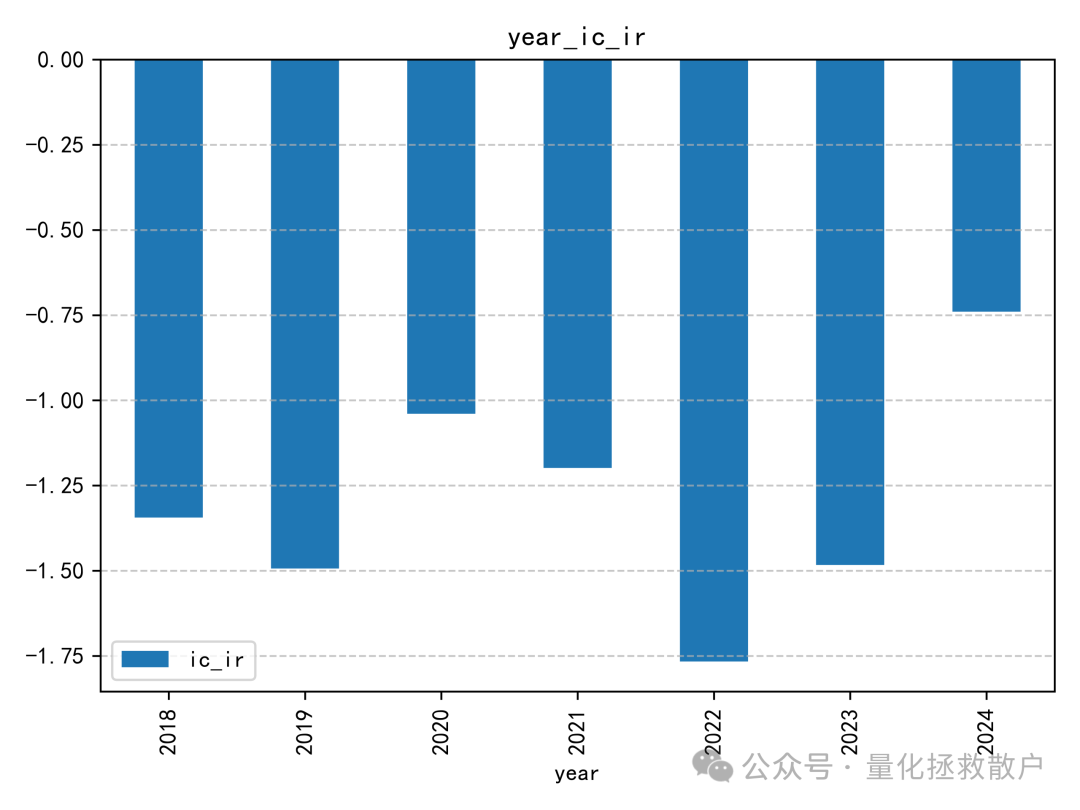
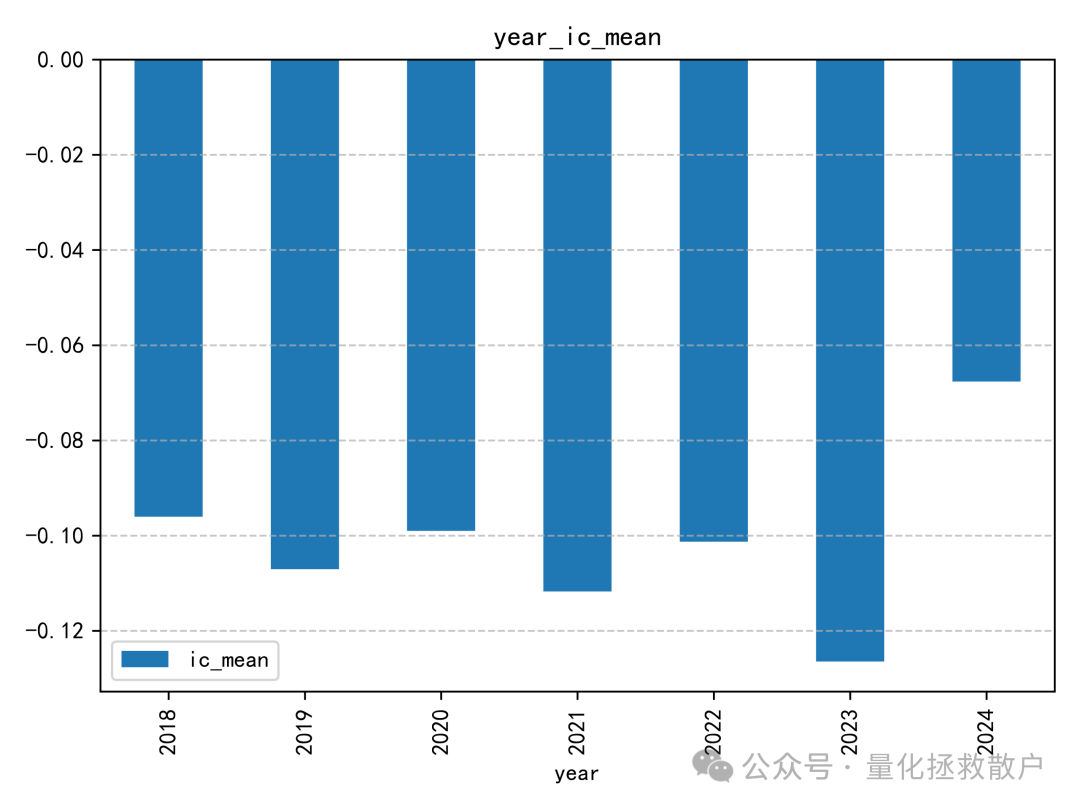
从IC分析结果来看,该因子的表现确实不错,有四年IC绝对值的均值超过了0.1。如果采用均值合成的方式,2023年的IC绝对值甚至能超过0.14。这类因子的评价常常依赖于严谨的算法和数据分析。
02 回归分析
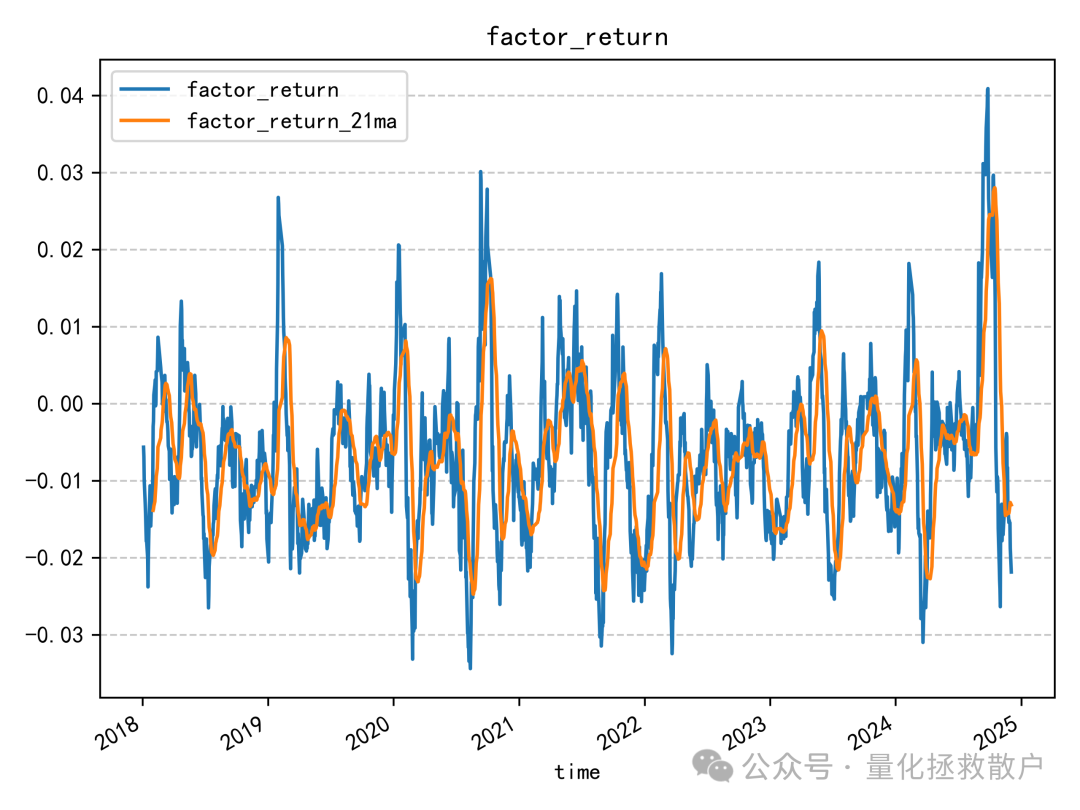
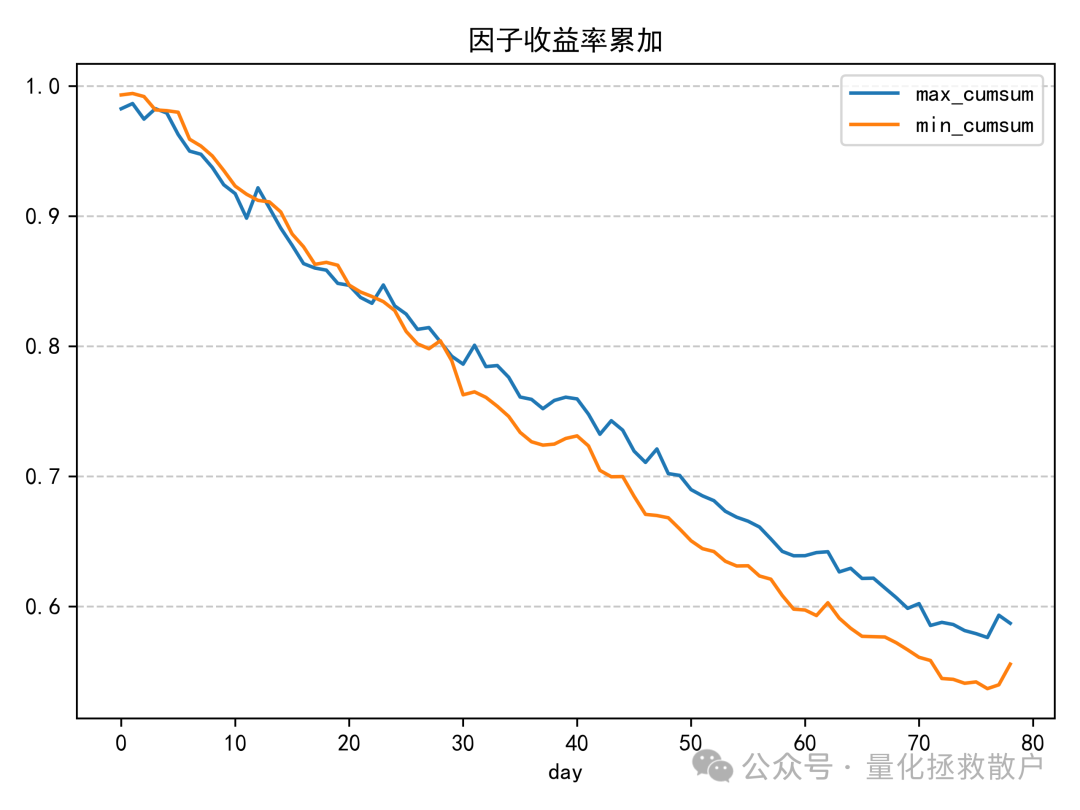
03 换手率分析
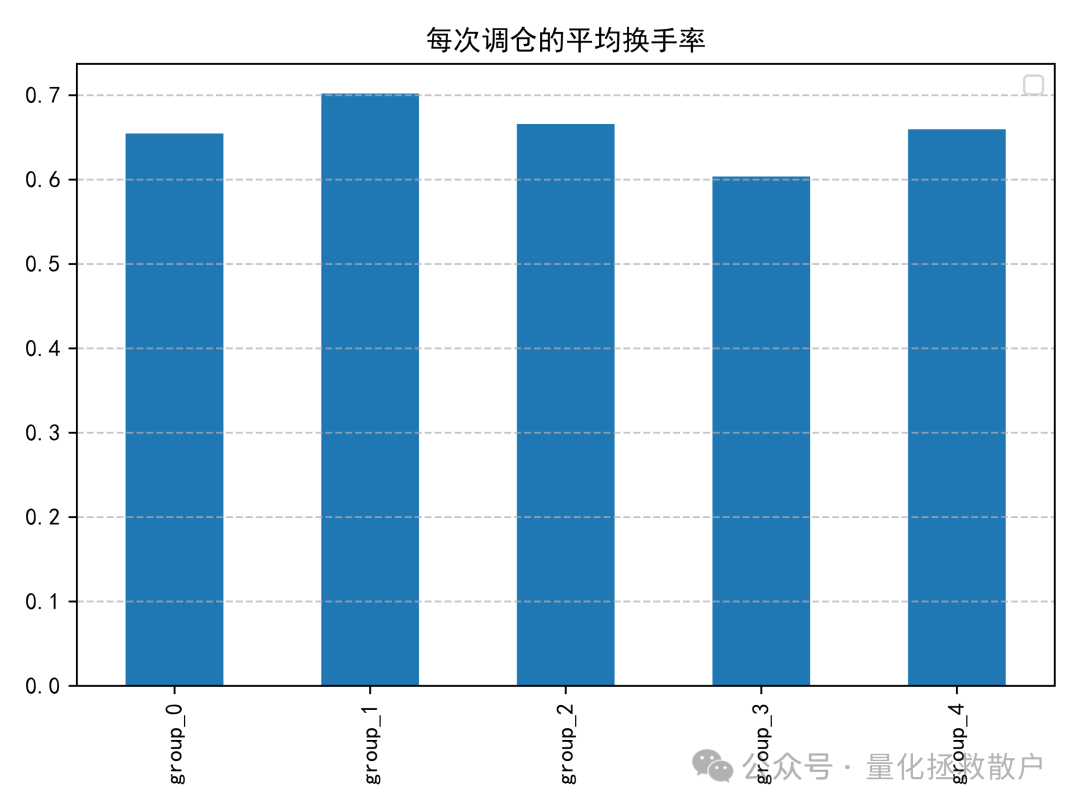
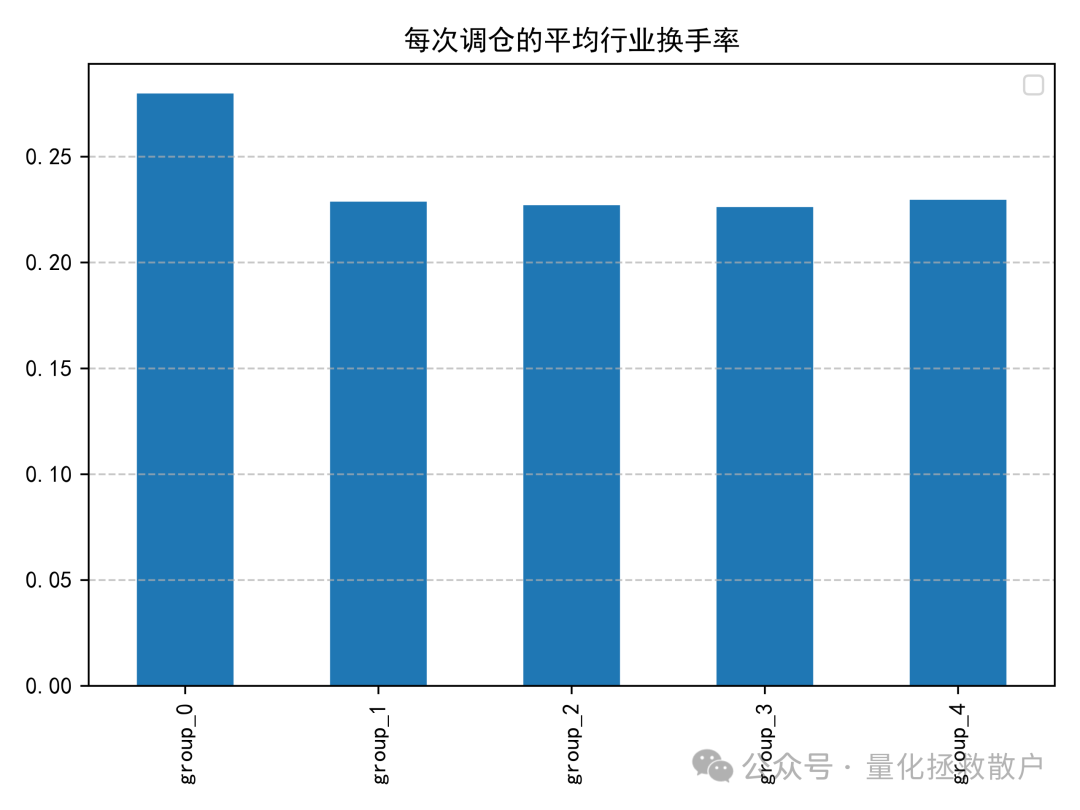
04 收益分析
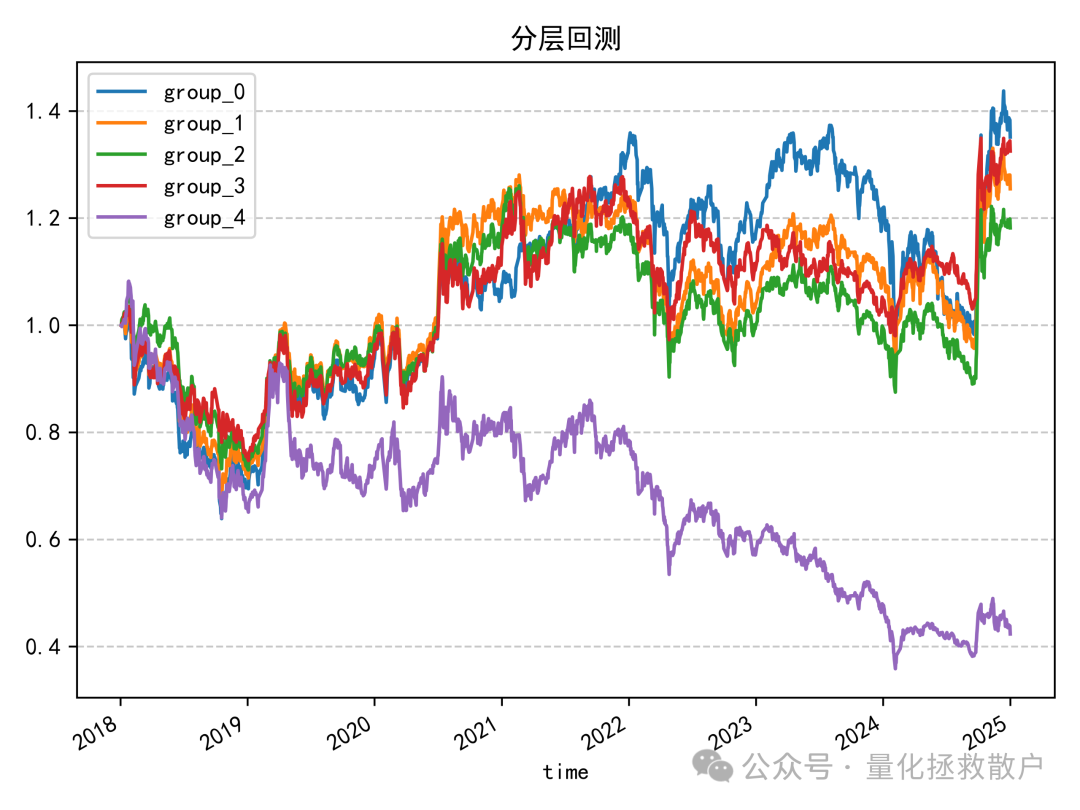
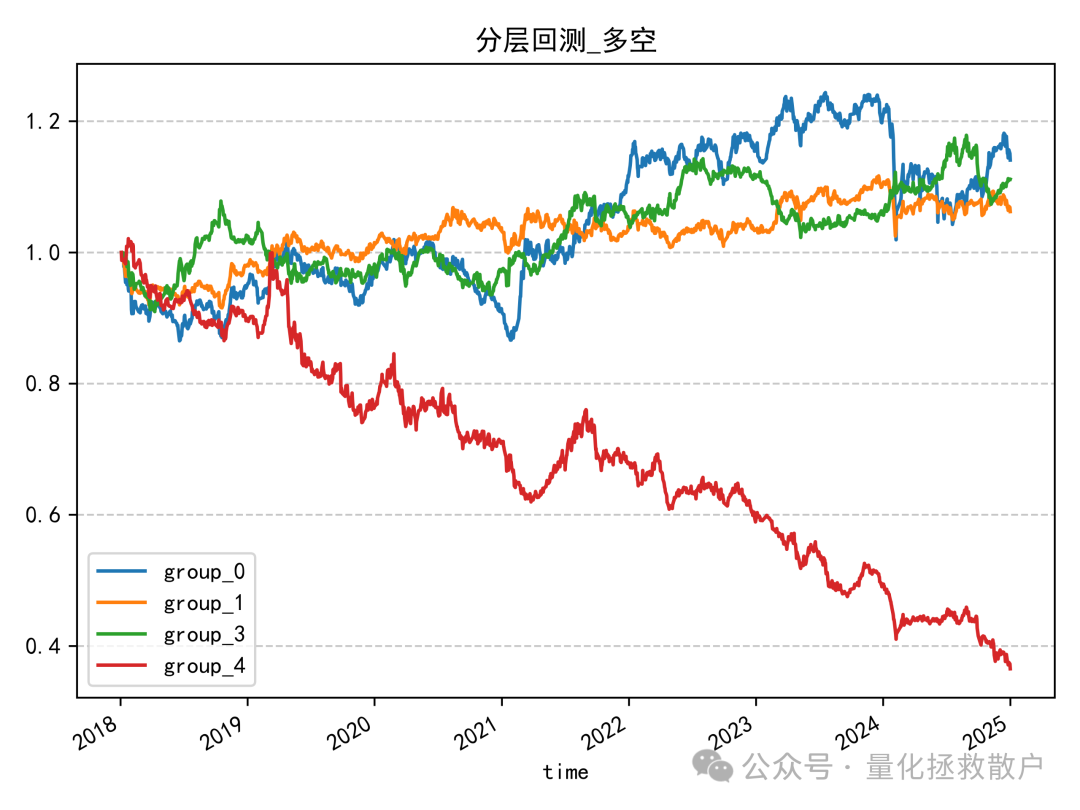
从分层回测结果看,该因子的多头收益并不突出,前四组净值曲线交织在一起,难以区分优劣,只有因子值最大的一组(group_4)表现远逊于其他组。
总结
综合来看,“量涌波动率”因子的IC表现确实较高,是一个有效的信号。但其核心问题在于,它与传统高频波动率因子的相关性过高,且两者的分层回测结果基本一致。这意味着,该因子可能并未带来显著的信息增益,其预测能力很大程度上与波动率因子重叠。
最近尝试挖掘一些独特的因子但收效甚微,因此只能继续复现研报中的经典因子。这个过程也是对数据科学在金融领域应用的一次深度实践。希望本次关于“量涌波动率”因子的复现与解析,能为大家在量化策略研究中提供一些参考。更多技术干货和开源项目,欢迎访问 云栈社区 进行探讨。
 发表于 2026-3-16 03:15:12
|
查看: 193|
回复: 0
发表于 2026-3-16 03:15:12
|
查看: 193|
回复: 0
