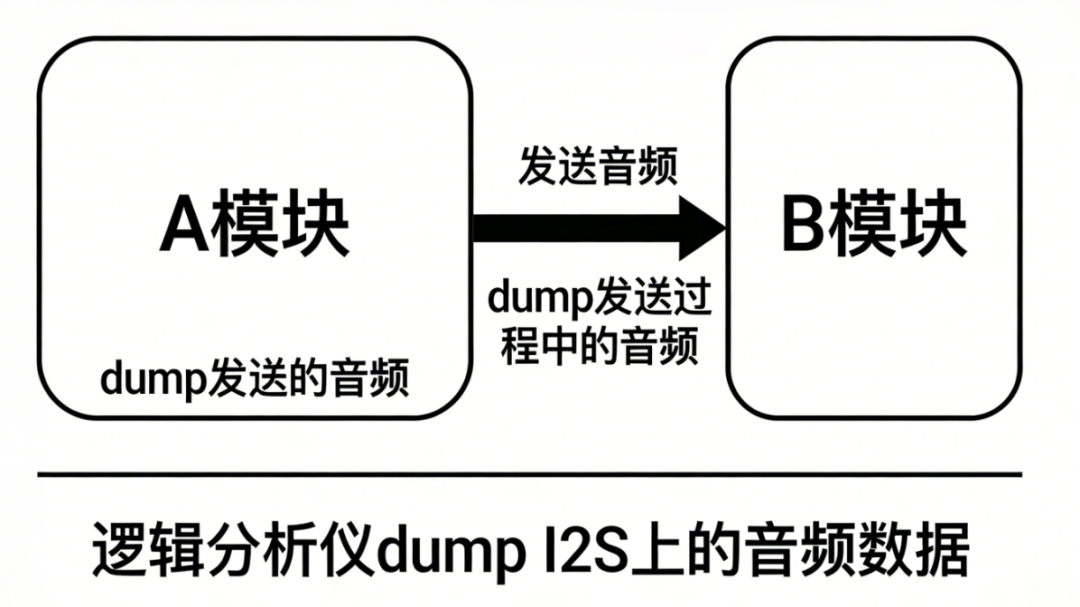
在音频开发与调试过程中,日志固然重要,但有时它无法提供直接的证据。一个常见且棘手的问题是:音频在A模块处理时是完好的,但发送到B模块后却出现了问题,比如噪声、失真或无声。此时,仅凭日志双方容易陷入“扯皮”——B模块开发者会说日志显示接收正常,问题可能出在A模块发送的音频数据本身。要厘清责任、定位症结,对原始音频流进行数据“抓包”(dump)就成为了比查看日志更直接、更可靠的手段。
这种场景下,我们通常需要dump两处数据:
- A模块准备发送的原始音频数据。
- 音频数据在传输线路上(例如I2S总线)的实际信号。
本文将介绍一种硬件级的排查方法:使用逻辑分析仪捕获I2S总线上的实际音频数据,并将其还原为可听、可分析的WAV文件,从而为模块间音频通信问题提供无可辩驳的“实锤”证据。
硬件连接与数据捕获
首先,需要将目标设备I2S总线的几个关键信号线连接到逻辑分析仪的通道上。通常需要连接:
- LRCK (LRCLK): 左右声道时钟(帧同步信号)。
- BCLK (SCLK): 位时钟(串行时钟)。
- SDO/SDIN: 数据输出/输入线(根据抓取方向选择)。
连接妥当后,在逻辑分析仪配套软件(如示例中的KingstVIS)中设置触发条件并开始捕获。成功捕获到一段时间的信号后,软件界面会显示出清晰的时序波形。
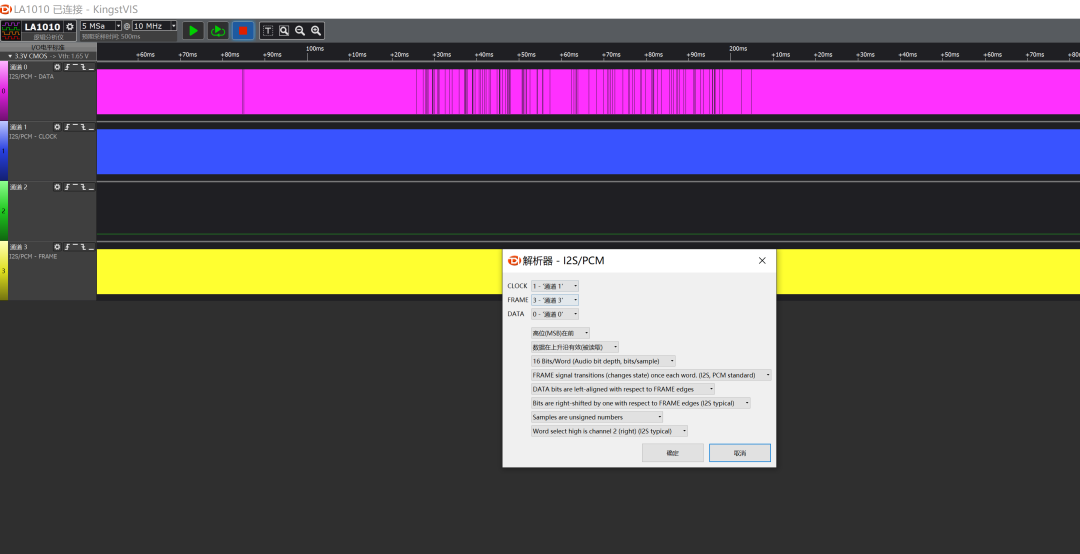
在软件中,需要正确配置I2S/PCM解析器的参数,以匹配你的音频格式,例如位深度(16 Bit)、对齐方式(I2S典型为右移一位)、声道与帧信号的关系等,确保软件能正确地将高低电平解读为数字音频数据。
数据导出
解析成功后,软件会将总线上的原始信号解析为十六进制的采样值。此时,需要将这些数据导出以供后续处理。
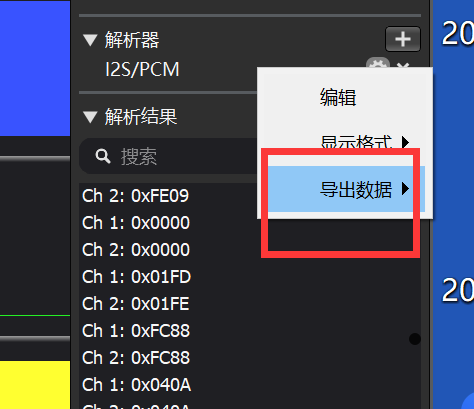
在解析结果窗口,通过右键菜单或相关选项选择“导出数据”。导出的数据通常是CSV(逗号分隔值)或类似的表格格式。
理解数据格式
导出的CSV文件,用Excel或文本编辑器打开后,通常包含多列数据,例如时间戳(Time)、通道标识(Channel)和数值(Value)。其中,Value列保存的就是以十六进制补码形式表示的音频采样值。
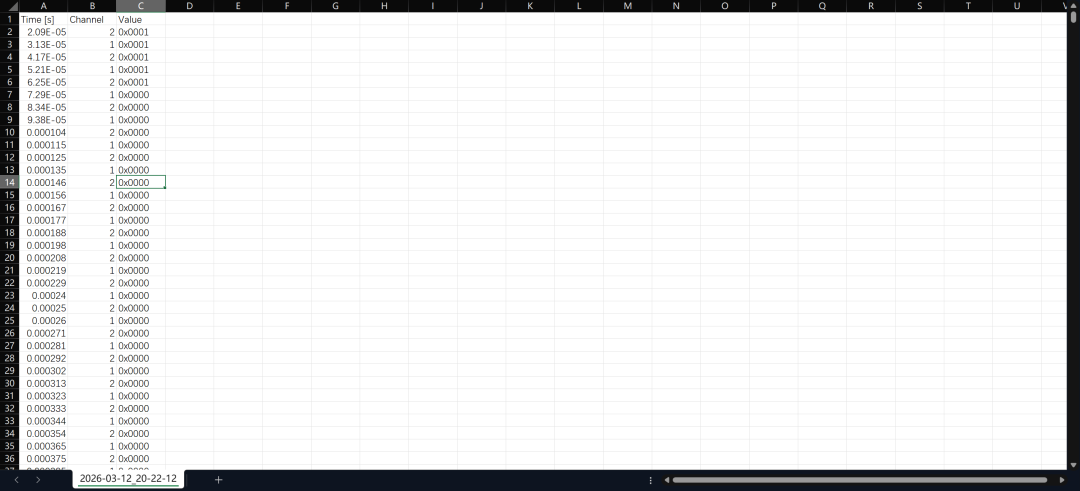
从数据中可以看到,左右声道的采样值是交替出现的(例如Channel标识1和2交替),这正是立体声I2S数据流的典型特征:左声道采样, 右声道采样, 左声道采样, 右声道采样, ...。
数据转换:从CSV到WAV
到这一步,我们手头是一堆数字,而非可听的音频。接下来的关键就是编写一个脚本,将这些十六进制数据转换为标准的WAV文件格式。
转换的核心步骤包括:
- 读取CSV文件,提取出代表音频采样的那一列(通常是第3列)。
- 将十六进制字符串转换为16位有符号整数(处理补码)。
- 将交替排列的左右声道数据分离,并重新组织成立体声音频帧数组。
- 设置正确的采样率(如48kHz),使用音频库将数组写入WAV文件。
以下是一个完整的Python转换脚本示例:
'''
i2s csv to wav
将逻辑分析仪导出的 I2S 音频数据(CSV 格式)转换为标准 WAV 音频文件
使用方法: python audio_python.py input.csv output.wav
数据流: 逻辑分析仪抓取 I2S 总线 -> 导出 CSV -> 本脚本转换 -> WAV 文件
'''
import sys
import numpy as np
from scipy.io import wavfile
# 校验命令行参数:需要输入 CSV 路径和输出 WAV 路径
if len(sys.argv) != 3:
print('Usage: python {} csv wav'.format(sys.argv[0]))
sys.exit(1)
csv = sys.argv[1] # 逻辑分析仪导出的 CSV 文件
wav = sys.argv[2] # 输出的 WAV 文件
def conv(s):
"""将十六进制字符串转换为 16-bit 有符号整数(补码处理)
例如: 0x7FFF -> 32767, 0x8000 -> -32768, 0xFFFF -> -1
"""
x = int(s, 16)
return x if x < 0x8000 else x - 0x10000
# 读取 CSV 文件,只取第 3 列(索引 2)的 I2S 音频采样数据
# 逻辑分析仪 CSV 格式通常为: 时间戳, 通道标识, 数据(hex), ...
data = np.genfromtxt(
csv,
usecols=(2,), # 第 3 列:音频数据
delimiter=',', # 逗号分隔
skip_header=1, # 跳过表头
converters={2: conv} # 用 conv 函数将 hex 转为有符号整数
)
# I2S 双声道数据交替排列: L, R, L, R, ...
# 将一维数组重塑为 (N, 2) 的立体声帧数组
size = int(len(data) // 2) # 完整的立体声采样帧数
print('size=%d'%(size))
data = data[:size*2] # 截断为偶数个,确保左右声道配对
stereo = data.reshape((size, 2)) # 重塑为 [左声道, 右声道] 的二维数组
# 以 48kHz 采样率写入 16-bit 立体声 WAV 文件
# 注意:如果实际 I2S 采样率不同(如 44.1kHz、16kHz),需修改 fs
fs = 48000
wavfile.write(wav, fs, stereo.astype('int16'))
脚本使用说明:
- 确保已安装
numpy 和 scipy 库。
- 在命令行中运行:
python audio_python.py 你导出的数据.csv output.wav。
- 脚本中的采样率(
fs = 48000)需要根据你的I2S实际配置进行修改。
结果验证
运行脚本后,你将得到一个标准的 output.wav 文件。使用任何音频播放器或音频编辑软件(如Audacity)打开它,就能直观地听到和分析从I2S总线上“抓取”下来的真实音频了。
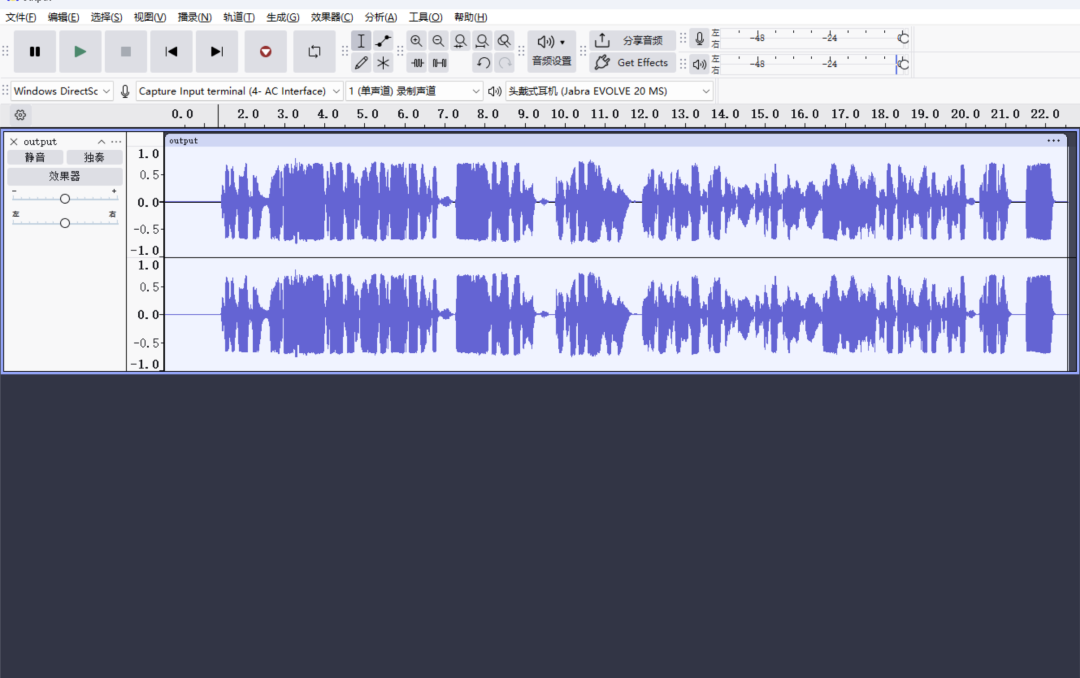
至此,你完成了一次完整的硬件音频数据抓取与分析。无论是为了验证发送端的数据是否正确,还是确认传输过程中是否受到干扰,这个方法都能提供最直接的证据。希望这篇指南能帮助你在下一次遇到棘手的音频问题时,快速找到突破口。欢迎在 云栈社区 分享你在硬件调试中的其他实战经验与技巧。
 发表于 2026-3-16 03:50:07
|
查看: 199|
回复: 0
发表于 2026-3-16 03:50:07
|
查看: 199|
回复: 0
