来自普林斯顿大学的研究团队开源了一款创新的强化学习框架——OpenClaw-RL。
这个项目的核心思想非常简单:让OpenClaw这类AI Agent在与用户的日常对话过程中,就能自动学习并进化。你完全不需要准备专门的标注数据或训练集,甚至不必中断使用。它能够在后台悄无声息地持续优化自身能力,真正实现“越用越聪明”。

项目地址:https://github.com/Gen-Verse/OpenClaw-RL
与市面上大多数需要预先收集、格式化批量数据的“高冷”强化学习框架不同,OpenClaw-RL的设计思路截然相反。它将整个训练流程分解为四个独立的异步模块:模型服务、数据收集、评分评估和策略训练。这些模块各司其职,互不干扰。
这意味着,当你正在使用模型进行聊天或解决问题时,数据收集、模型评分和策略训练已经在后台并行运行。整个系统是实时流动的,彻底改变了传统“使用”与“训练”分离的模式。
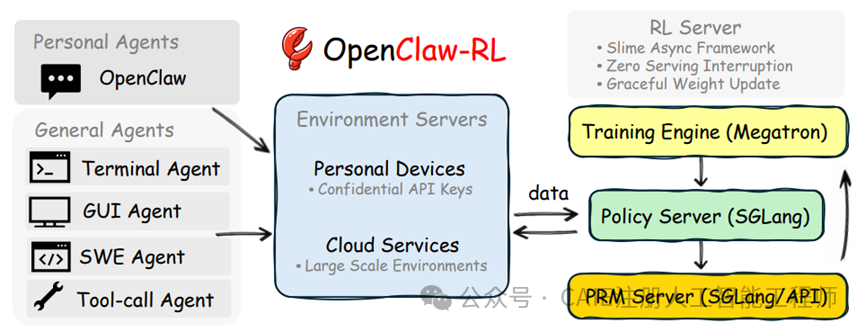
举例来说,在你与OpenClaw交互的同时,系统后台就在自动完成以下工作:整理多轮对话数据、调用评估模型进行打分、并基于这些反馈计算奖励以优化模型策略。你再也不用面临“停下来训练”还是“继续使用”的两难选择。
该框架最令人惊喜的特性之一是强大的自动化数据处理能力,它将开发者从繁琐的手动数据标注工作中解放出来。框架能够自动将用户与智能体的多轮对话,整理成具有上下文会话感知的训练轨迹。它还能智能地区分哪些对话片段可用于核心训练,哪些属于无需训练的辅助性内容。
同时,系统会将用户后续的反馈、环境给出的回应,乃至工具调用的执行结果,都视作天然的训练信号,并自动调用评估模型进行打分。在需要时,它还会通过多数投票机制来提升评分的准确性。最后,所有这些信号会被转换成模型能够理解的梯度。从反馈收集到训练素材生成,全程无需人工干预。
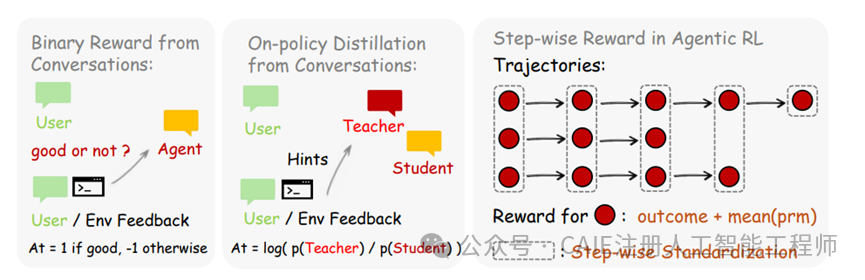
此外,OpenClaw-RL还集成了三种优化方法,以适应不同类型的反馈:
- 二值强化学习:利用过程奖励模型为每轮对话生成一个分数(好或坏),并基于此分数进行策略优化。
- 在线策略蒸馏:当后续状态能提供有价值的事后信息时,让评分模型生成文字提示来增强原始问题,从而形成一个更聪明的“教师”模型,用于指导学生模型的训练。
- 混合方法:将上述密集的数值监督和丰富的词级别方向信号融合在一起,其效果通常优于单独使用任何一种方法。
这个框架不仅适配OpenClaw,也适用于其他类型的智能体。无论是终端命令行操作、图形界面(GUI)交互、软件工程(SWE)任务,还是工具调用,这些真实的智能体应用场景它都能覆盖。它是一个真正意义上的异步框架,训练过程完全在后台进行,不会中断用户的正常使用。
目前,这款开源框架虽然刚刚发布不久,但已经在GitHub上获得了超过2700颗星。它特别适合以下几类开发者或团队:
- 希望训练个性化AI助手的个人开发者。
- 企业内部需要私有化部署并能持续自我优化AI服务的团队。
- 专注于智能体和强化学习方向的研究人员与技术爱好者。
对这类前沿AI训练技术感兴趣?欢迎在云栈社区与其他开发者交流探讨,获取更多开源实战经验。 |  发表于 2026-3-16 05:37:47
|
查看: 125|
回复: 0
发表于 2026-3-16 05:37:47
|
查看: 125|
回复: 0
