作为系统的核心,进程管理是每一位Linux系统管理员和开发者的必备技能。无论是进行服务部署、性能调优还是故障排查,对进程生命周期的深入理解和对管理工具的熟练运用都至关重要。本文将为你全面解析Linux进程管理的各个方面,涵盖从基础概念、常用工具到高级资源控制的完整知识体系。
进程管理基础概念
1.1 进程生命周期
每个进程都拥有自己的生命周期,从创建到终止会经历不同的状态。理解这些状态是诊断进程问题的第一步。
进程状态说明:
- R (Running/Runnable): 运行或可运行状态。进程正在CPU上执行或在运行队列中等待调度。
- S (Sleeping): 可中断睡眠状态。进程正在等待某个事件(如I/O完成),可以被信号唤醒。
- D (Uninterruptible Sleep): 不可中断睡眠状态。进程正在等待硬件I/O,通常与磁盘操作相关,此状态下不响应信号。
- T (Stopped): 停止状态。进程被信号(如SIGSTOP)暂停执行,可通过SIGCONT信号继续。
- Z (Zombie): 僵尸状态。进程已终止,但其退出状态尚未被父进程回收。
- X (Dead): 死亡状态。进程已完全终止,这是一个瞬时状态,通常不会在进程列表中看到。
进程优先级范围:
进程优先级决定了CPU调度器处理它们的顺序。
- 实时优先级: 范围1-99,数值越大优先级越高。此类进程会抢占普通优先级进程。
- 普通优先级: 范围100-139,对应nice值从-20到19。数值越小优先级越高,普通用户只能降低优先级(增加nice值)。
1.2 进程查看工具对比
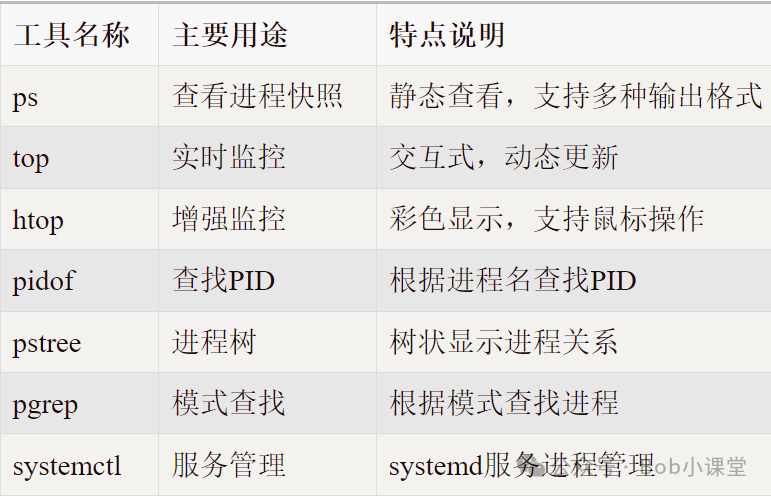
上图清晰地对比了ps、top、htop等常用进程查看工具的特性与适用场景,帮助你根据需求选择最合适的工具。
进程查看与监控
2.1 ps 命令详解
ps命令是查看进程瞬时状态的瑞士军刀,功能强大且参数繁多。掌握其常用组合能极大提升工作效率。
# 查看所有进程(BSD风格)
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 169232 9920 ? Ss 09:00 0:02 /usr/lib/systemd/systemd
# 查看所有进程(标准风格)
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 09:00 ? 00:00:02 /usr/lib/systemd/systemd
# 自定义输出格式:按CPU使用率降序排列,查看前20个进程
$ ps -eo pid,ppid,user,ni,pri,pcpu,pmem,cmd --sort=-pcpu | head -20
# 查看特定用户(如apache)的进程
$ ps -U apache -u apache u
# 查看进程树状结构
$ ps axjf
$ ps -ef --forest
# 查看指定PID进程的环境变量
$ ps ewww -p 1234
# 查看进程打开的文件:结合lsof命令
$ ps -o pid,cmd --no-headers -p 1234 | xargs -I {} lsof -p {}
2.2 top 命令高级用法
top命令提供实时的、动态刷新的系统进程状态视图,是交互式监控的首选。
# 启动top
$ top
# top交互命令详解:
# 1. 排序控制
# P - 按CPU使用率排序
# M - 按内存使用率排序
# T - 按运行时间排序
# N - 按PID排序
# 2. 显示控制
# c - 显示完整命令路径
# m - 切换内存信息显示模式
# 1 - 显示所有CPU核心的单独利用率
# f - 添加或删除显示字段
# o - 更改字段的显示顺序
# 3. 进程控制
# k - 终止选中的进程(发送信号)
# r - 调整选中进程的优先级(nice值)
# 4. 刷新与配置
# s - 更改刷新间隔(秒)
# d - 更改刷新频率
# W - 将当前配置保存到用户主目录的 ~/.toprc 文件
# 批处理模式:用于脚本或保存快照
$ top -b -n 1 > process_snapshot.txt
$ top -b -d 5 -n 3 > process_monitor.log
# 监控特定进程
$ top -p 1234,5678
$ top -u apache
# 带时间戳的输出(结合awk)
$ top -b -d 2 -n 3 | awk '/^top/ {print strftime("%Y-%m-%d %H:%M:%S"), $0} !/^top/ {print}'
2.3 htop 增强监控
htop是top的增强版,提供了彩色界面、鼠标支持、垂直和水平滚动查看进程列表及完整命令行的便利性。
# 在CentOS 8上安装htop
$ sudo dnf install htop
# htop常用快捷键操作
# F1 - 查看帮助
# F2 - 进入设置菜单,配置显示选项
# F3 - 搜索进程(按名称)
# F4 - 过滤进程,仅显示匹配项
# F5 - 以树状结构显示进程层次
# F6 - 选择排序的字段
# F7 - 降低选中进程的优先级(增加nice值)
# F8 - 提高选中进程的优先级(减少nice值)
# F9 - 向选中进程发送信号
# F10 - 退出htop
# 启动选项示例
$ htop -u apache # 只显示属于apache用户的进程
$ htop -p 1234 # 只显示PID为1234的进程
$ htop -s cpu # 启动时按CPU使用率排序
$ htop -d 10 # 设置刷新间隔为10秒
进程控制与管理
3.1 进程启动与终止
正确地启动和终止进程是确保服务稳定性的基础,尤其是在生产环境中。
# 前台启动进程:会占用当前终端
$ ./myapp
# 后台启动进程:& 符号使进程在后台运行
$ ./myapp &
# 使用nohup启动:使进程忽略挂断信号,退出终端后继续运行,并重定向输出到文件
$ nohup ./myapp > app.log 2>&1 &
# 使用终端复用器启动:如screen或tmux,即使断开连接,进程仍保留在会话中
$ screen -S mysession ./myapp
$ tmux new -s mysession './myapp'
# 终止进程:kill命令通过发送信号来终止进程
$ kill 1234 # 发送TERM信号(默认,信号15),建议首选
$ kill -9 1234 # 发送KILL信号(信号9),强制立即终止,不进行清理
$ kill -15 1234 # 显式发送TERM信号(优雅终止)
$ kill -SIGTERM 1234 # 使用信号名称发送TERM信号
$ kill -SIGKILL 1234 # 使用信号名称发送KILL信号
# 终止整个进程组(使用负的PID)
$ kill -9 -1234 # 终止PID为1234的进程所在的整个进程组
# 按名称终止进程:pkill命令
$ pkill myapp
$ pkill -f "python.*myapp" # 根据完整命令行进行匹配
$ pkill -u apache # 终止属于apache用户的所有进程
$ pkill -9 -u apache # 强制终止属于apache用户的所有进程
# 按名称查找并终止:killall命令(与pkill类似,但通常要求精确匹配程序名)
$ killall myapp
$ killall -u apache
$ killall -9 -v myapp # -v 详细模式,显示被杀死的进程信息
# 优雅终止脚本示例:给进程留出清理资源的时间
#!/bin/bash
# graceful_shutdown.sh
PID=$1
TIMEOUT=30
# 首先发送TERM信号,请求进程优雅退出
kill -TERM $PID
# 等待进程结束,设置超时时间
count=0
while kill -0 $PID 2>/dev/null; do
if [ $count -ge $TIMEOUT ]; then
echo "超时,强制终止进程 $PID"
kill -KILL $PID
break
fi
sleep 1
((count++))
done
echo "进程 $PID 已终止"
3.2 进程优先级管理
通过调整进程的优先级,可以合理分配有限的CPU资源,确保关键任务获得足够的计算能力。
nice命令:管理普通优先级
普通进程的优先级通过nice值调整,范围从-20(最高)到19(最低)。
# 启动新进程时设置优先级
$ nice -n 10 ./myapp # 以较低的优先级(nice值为10)启动程序
$ nice -n -5 ./myapp # 以较高的优先级(nice值为-5)启动程序,通常需要root权限
# 查看运行中进程的优先级信息
$ ps -o pid,ni,pri,cmd -p 1234
# 修改已运行进程的优先级:renice命令
$ renice 5 -p 1234 # 将PID为1234的进程的nice值改为5(降低优先级)
$ renice -5 -p 1234 # 提高PID为1234的进程的优先级(通常需要root权限)
$ renice 10 -u apache # 将apache用户所有进程的nice值改为10
$ renice -10 -g developers # 将developers组所有进程的nice值改为-10
chrt命令:管理实时优先级
对于需要确定性和快速响应的任务(如音视频处理、工业控制),可以赋予其实时调度策略和优先级。
# 查看进程的当前调度策略和优先级
$ chrt -p 1234
pid 1234‘s current scheduling policy: SCHED_OTHER
pid 1234’s current scheduling priority: 0
# 为已运行的进程设置实时调度策略
$ chrt -f -p 99 1234 # 设置为FIFO实时调度,优先级99(需要root权限)
$ chrt -r -p 50 1234 # 设置为Round-robin实时调度,优先级50
$ chrt -o -p 0 1234 # 设置为普通调度策略(SCHED_OTHER)
# 以实时调度策略启动新进程
$ chrt -f 99 ./realtime_app
$ chrt -r 50 ./realtime_app
# 调度策略说明:
# SCHED_OTHER (0): 默认的普通分时调度策略,使用nice值。
# SCHED_FIFO (1): 先进先出实时调度策略。高优先级进程会一直运行直到阻塞或主动让出CPU。
# SCHED_RR (2): 轮转实时调度策略。与FIFO类似,但同级进程会分时片轮转。
# SCHED_BATCH (3): 批处理调度策略,适用于非交互式、CPU密集型任务。
# SCHED_IDLE (5): 空闲调度策略,优先级极低。
# SCHED_DEADLINE (6): 截止时间调度策略,基于每个任务的最晚完成时间进行调度。
3.3 进程信号管理
信号是进程间通信的一种基本方式,用于通知进程某个事件的发生。熟练掌握信号是优雅控制进程的关键。
# 常用信号列表及其用途
# 1) SIGHUP 挂起。常用于通知守护进程重新加载配置文件。
# 2) SIGINT 中断。通常由 Ctrl+C 产生,请求进程终止。
# 3) SIGQUIT 退出。类似SIGINT,但会产生核心转储。
# 9) SIGKILL 强制终止。进程无法捕获或忽略,立即结束。
# 15) SIGTERM 终止。默认的kill信号,请求进程优雅退出。
# 18) SIGCONT 继续。让被暂停(SIGSTOP)的进程继续运行。
# 19) SIGSTOP 暂停。暂停进程的执行(不可捕获或忽略)。
# 20) SIGTSTP 终端暂停。通常由 Ctrl+Z 产生,请求进程暂停。
# 向进程发送特定信号
$ kill -1 1234 # 发送SIGHUP信号,使用数字
$ kill -HUP 1234 # 发送SIGHUP信号,使用名称
$ kill -USR1 1234 # 发送用户自定义信号USR1
# 在Shell脚本中捕获并处理信号
#!/bin/bash
# signal_handler.sh
# 使用trap命令定义信号处理函数
trap 'echo “收到SIGINT信号,正在清理...”; cleanup; exit' SIGINT
trap 'echo “收到SIGTERM信号,正在退出...”; exit' SIGTERM
trap 'echo “收到SIGHUP信号,重新加载配置...”; reload_config' SIGHUP
cleanup() {
echo “执行清理操作...”
# 在这里放置资源释放、临时文件删除等代码
}
reload_config() {
echo “重新加载配置...”
# 在这里放置重新读取配置文件的代码
}
echo “进程PID: $$”
while true; do
echo “运行中... $(date)”
sleep 5
done
systemd 服务进程管理
在现代Linux发行版中,systemd已取代传统的SysV init成为默认的初始化系统和服务管理器,它提供了更强大的服务管理能力。
4.1 systemctl 命令详解
systemctl是管理systemd单元(包括服务、挂载点、套接字等)的核心命令。
# 服务生命周期管理
$ sudo systemctl start nginx # 启动服务
$ sudo systemctl stop nginx # 停止服务
$ sudo systemctl restart nginx # 重启服务
$ sudo systemctl reload nginx # 重新加载服务的配置文件(不重启进程)
$ sudo systemctl status nginx # 查看服务的详细状态(推荐首先使用)
$ sudo systemctl enable nginx # 设置服务开机自启
$ sudo systemctl disable nginx # 禁止服务开机自启
$ sudo systemctl is-enabled nginx # 检查服务是否启用开机启动
$ sudo systemctl mask nginx # 屏蔽服务,使其无法被手动或自动启动
$ sudo systemctl unmask nginx # 取消对服务的屏蔽
# 使用journalctl查看服务日志(systemd的日志系统)
$ sudo journalctl -u nginx # 查看nginx服务的所有日志
$ sudo journalctl -u nginx -f # 实时跟踪(follow)日志输出
$ sudo journalctl -u nginx --since=“1 hour ago” # 查看最近1小时的日志
$ sudo journalctl -u nginx --since today # 查看今天以来的日志
$ sudo journalctl -u nginx -o json-pretty # 以美观的JSON格式输出日志
# 查看服务依赖关系
$ systemctl list-dependencies nginx # 查看nginx服务依赖哪些其他单元
$ systemctl list-dependencies --reverse nginx # 查看哪些单元依赖nginx服务
# 查看所有服务单元
$ systemctl list-units --type=service # 查看所有已加载且活动的服务
$ systemctl list-units --type=service --all # 查看所有服务(包括未运行/不活动的)
$ systemctl list-unit-files --type=service # 查看所有已安装的服务单元文件及其启用状态
4.2 创建自定义systemd服务
将自定义应用托管给systemd,可以获得自动重启、日志管理、依赖控制等生产级特性。在进行 运维/DevOps 工作时,编写标准的service文件是必备技能。
# 创建自定义服务单元文件:/etc/systemd/system/myapp.service
[Unit]
Description=My Custom Application
Documentation=https://example.com/docs
After=network.target nginx.service # 定义启动顺序:在网络和nginx之后启动
Wants=network.target # 声明“弱依赖”
Requires=nginx.service # 声明“强依赖”,nginx启动失败则本服务不启动
[Service]
Type=simple # 常见类型:simple, forking, oneshot, dbus, notify
User=myapp # 以非root用户运行,提升安全性
Group=myapp
WorkingDirectory=/opt/myapp # 设置进程的工作目录
ExecStart=/usr/bin/python3 /opt/myapp/main.py # 启动命令
ExecReload=/bin/kill -HUP $MAINPID # 定义reload操作(发送SIGHUP)
ExecStop=/bin/kill -TERM $MAINPID # 定义stop操作(发送SIGTERM)
Restart=on-failure # 失败时自动重启(其他选项:always, on-abort, no)
RestartSec=10 # 重启前等待的秒数
StartLimitInterval=60 # 启动频率限制的时间窗口(秒)
StartLimitBurst=5 # 在时间窗口内允许的最大启动次数
# 资源限制(防止单个服务耗尽系统资源)
LimitNOFILE=65536 # 最大打开文件描述符数
LimitNPROC=4096 # 最大进程数
LimitCORE=infinity # 核心转储文件大小限制
# 环境变量设置
Environment=“APP_ENV=production”
EnvironmentFile=/etc/myapp/env.conf # 从文件加载环境变量
# 安全与隔离设置(沙盒)
ProtectSystem=strict # 严格保护系统目录
ReadWritePaths=/var/log/myapp /var/lib/myapp # 明确指定可写路径
PrivateTmp=true # 使用私有的/tmp和/var/tmp
NoNewPrivileges=true # 进程及其子进程无法获得新权限
[Install]
WantedBy=multi-user.target # 表示当系统进入多用户模式时,本服务应被启用
# 启用并启动自定义服务
$ sudo systemctl daemon-reload # 重载systemd配置,必须修改服务文件后执行
$ sudo systemctl enable myapp.service # 启用开机自启
$ sudo systemctl start myapp.service # 立即启动服务
$ sudo systemctl status myapp.service # 检查服务状态
# 服务调试常用命令
$ sudo systemctl edit myapp.service # 创建临时的覆盖配置(在 /etc/systemd/system/service.d/)
$ sudo systemctl cat myapp.service # 查看完整的服务配置(合并了覆盖配置)
$ sudo journalctl -u myapp -xe # 查看该服务的详细日志,-e跳转到末尾
$ sudo systemd-analyze verify myapp.service # 验证服务单元文件的语法
4.3 systemd资源控制
systemd可以方便地通过cgroups对服务的资源使用进行精细化的限制。
# 在Service段中配置资源限制的示例
[Service]
# CPU限制
CPUQuota=50% # 限制该服务最多使用50%的单个CPU核心时间片(CFS配额)
CPUWeight=100 # 设置CPU权重(默认100),用于分配剩余CPU时间
StartupCPUWeight=200 # 服务启动期间的CPU权重,可使其启动更快
# 内存限制
MemoryLimit=512M # 硬限制:服务最大可使用内存(含交换分区),超过则触发OOM Killer
MemorySwapMax=1G # 交换分区使用限制
MemoryHigh=400M # 软限制:当服务内存使用超过此值,系统会开始积极回收其内存
# I/O限制
IOWeight=100 # I/O权重(相对权重),影响块设备I/O带宽分配
IODeviceWeight=/dev/sda 500 # 对特定设备(/dev/sda)设置I/O权重
IOReadBandwidthMax=/dev/sda 10M # 对特定设备设置最大读取带宽
IOWriteBandwidthMax=/dev/sda 5M # 对特定设备设置最大写入带宽
# 进程数限制
TasksMax=1000 # 该cgroup内允许的最大任务(进程+线程)数
LimitNPROC=500 # 限制运行该服务的用户所能创建的最大进程数
# 文件描述符限制
LimitNOFILE=65536 # 硬限制:单个进程最大打开文件数
LimitNOFILESoft=32768 # 软限制:超过会收到警告,但可暂时突破至硬限制
# 网络限制(需要 systemd >= 236)
IPAddressAllow=192.168.1.0/24 # 只允许访问指定网段
IPAddressDeny=any # 默认拒绝所有其他访问
PrivateNetwork=true # 服务运行在私有网络命名空间内
RestrictAddressFamilies=AF_INET AF_INET6 # 限制服务只能使用IPv4和IPv6套接字
cgroups v2 资源控制
5.1 cgroups v2基础
cgroups(控制组)是Linux内核功能,用于限制、记录和隔离进程组的资源使用(CPU、内存、I/O等)。从CentOS 8开始,默认使用cgroups v2。
# 查看cgroups v2的挂载点
$ mount | grep cgroup
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,seclabel)
# 查看cgroup的层次结构
$ ls -la /sys/fs/cgroup/
dr-xr-xr-x. 10 root root 0 Dec 1 10:00 .
drwxr-xr-x. 9 root root 0 Dec 1 10:00 ..
-r--r--r--. 1 root root 0 Dec 1 10:00 cgroup.controllers # 本层可用的控制器
-r--r--r--. 1 root root 0 Dec 1 10:00 cgroup.max.depth
-r--r--r--. 1 root root 0 Dec 1 10:00 cgroup.max.descendants
-rw-r--r--. 1 root root 0 Dec 1 10:00 cgroup.procs # 写入PID可将进程加入本组
-r--r--r--. 1 root root 0 Dec 1 10:00 cgroup.stat
-rw-r--r--. 1 root root 0 Dec 1 10:00 cgroup.subtree_control # 向下层启用的控制器
-rw-r--r--. 1 root root 0 Dec 1 10:00 cgroup.threads
# 查看当前层级支持的资源控制器
$ cat /sys/fs/cgroup/cgroup.controllers
cpuset cpu io memory hugetlb pids rdma misc
5.2 使用systemd创建cgroup
systemd是管理cgroups v2的主要用户空间工具,它通过单元文件(.service, .slice, .scope)自动管理cgroup。
# 1. 创建临时的systemd作用域(scope),并立即运行命令
$ sudo systemd-run --scope --unit=mycgroup --slice=myapp.slice \
-p CPUQuota=50% \
-p MemoryLimit=512M \
/opt/myapp/start.sh
# 这会创建一个名为 `mycgroup.scope` 的临时单元,并将进程置于其中。
# 2. 通过服务单元文件创建带资源限制的cgroup
$ sudo tee /etc/systemd/system/myapp-cgroup.service << ‘EOF‘
[Unit]
Description=MyApp with cgroup limits
[Service]
Type=simple
ExecStart=/opt/myapp/start.sh
CPUQuota=30%
MemoryLimit=256M
MemorySwapMax=512M
IOWeight=100
TasksMax=500
EOF
# 3. 使用systemd-run创建临时cgroup运行测试命令
$ sudo systemd-run --unit=test-cgroup --slice=user.slice \
-p CPUQuota=20% \
-p MemoryLimit=100M \
sleep 3600
# 查看和管理cgroup
$ systemd-cgls # 以树状图显示cgroup层次结构
$ systemd-cgtop # 类似top,显示各cgroup的资源使用情况
$ systemctl show myapp-cgroup # 查看服务单元的详细属性,包括cgroup设置
5.3 手动管理cgroup
虽然不推荐在生产中手动操作/sys/fs/cgroup,但理解其原理有助于深入理解cgroups。
# 创建自定义的cgroup目录(例如 myapp)
$ sudo mkdir -p /sys/fs/cgroup/myapp
# 在刚创建的cgroup中启用子控制器(cpu, memory, pids)
$ echo “+cpu +memory +pids” | sudo tee /sys/fs/cgroup/myapp/cgroup.subtree_control
# 配置CPU限制(单位:微秒)
$ echo “100000 100000” | sudo tee /sys/fs/cgroup/myapp/cpu.max
# 格式:`$MAX $PERIOD`,表示每$PERIOD周期内最多使用$MAX时间。此处表示100% CPU。
# 配置CPU权重(默认100)
$ echo “50000” | sudo tee /sys/fs/cgroup/myapp/cpu.weight # 权重设为50000
# 配置内存硬限制(单位:字节,此处为512MB)
$ echo “536870912” | sudo tee /sys/fs/cgroup/myapp/memory.max
# 配置内存软限制(256MB),超过此值内核会尝试回收内存
$ echo “268435456” | sudo tee /sys/fs/cgroup/myapp/memory.high
# 配置最大进程数
$ echo “100” | sudo tee /sys/fs/cgroup/myapp/pids.max
# 将进程加入cgroup
$ echo 1234 | sudo tee /sys/fs/cgroup/myapp/cgroup.procs # 将PID为1234的进程加入
$ echo $$ | sudo tee /sys/fs/cgroup/myapp/cgroup.procs # 将当前shell进程加入
# 使用cgexec命令直接在新cgroup中启动进程(需安装libcgroup-tools)
$ cgexec -g cpu,memory:myapp ./myapp
# 查看cgroup的当前使用统计
$ cat /sys/fs/cgroup/myapp/cpu.stat
$ cat /sys/fs/cgroup/myapp/memory.current
$ cat /sys/fs/cgroup/myapp/pids.current
进程监控与日志
6.1 实时进程监控脚本
自动化监控是保障服务稳定运行的关键。以下脚本提供了一个基础的进程监控框架,可监控指定进程的存活状态及资源使用情况。
#!/bin/bash
# process_monitor.sh - 进程监控脚本
LOG_FILE=“/var/log/process_monitor.log”
ALERT_THRESHOLD_CPU=80 # CPU使用率告警阈值(%)
ALERT_THRESHOLD_MEM=70 # 内存使用率告警阈值(%)
CHECK_INTERVAL=60 # 检查间隔(秒)
PID_FILE=“/tmp/process_monitor.pid”
# 创建PID文件,用于管理监控脚本本身
echo $$ > $PID_FILE
trap “rm -f $PID_FILE; exit” SIGTERM SIGINT
# 核心监控函数
monitor_process() {
local process_name=$1
local warning_email=$2
while true; do
# 1. 检查进程是否存在
local pid=$(pgrep -o $process_name) # 获取最老的匹配进程PID
if [ -z “$pid” ]; then
echo “$(date): 进程 $process_name 未运行” | tee -a $LOG_FILE
send_alert “$warning_email” “进程 $process_name 已停止”
sleep 10
continue
fi
# 2. 获取进程资源使用率
local cpu_usage=$(ps -p $pid -o %cpu --no-headers | awk ‘{print int($1)}‘)
local mem_usage=$(ps -p $pid -o %mem --no-headers | awk ‘{print int($1)}‘)
local vsz=$(ps -p $pid -o vsz --no-headers) # 虚拟内存大小(KB)
local rss=$(ps -p $pid -o rss --no-headers) # 驻留物理内存大小(KB)
# 3. 检查是否超过阈值并触发告警
if [ $cpu_usage -gt $ALERT_THRESHOLD_CPU ]; then
local msg=“进程 $process_name (PID: $pid) CPU使用率过高: ${cpu_usage}%”
echo “$(date): $msg” | tee -a $LOG_FILE
send_alert “$warning_email” “$msg”
fi
if [ $mem_usage -gt $ALERT_THRESHOLD_MEM ]; then
local msg=“进程 $process_name (PID: $pid) 内存使用率过高: ${mem_usage}%”
echo “$(date): $msg” | tee -a $LOG_FILE
send_alert “$warning_email” “$msg”
fi
# 4. 记录常规状态日志
echo “$(date): $process_name - PID: $pid, CPU: ${cpu_usage}%, MEM: ${mem_usage}%, VSZ: ${vsz}, RSS: ${rss}” >> $LOG_FILE
sleep $CHECK_INTERVAL
done
}
# 告警发送函数(示例:邮件和系统日志)
send_alert() {
local email=$1
local message=$2
# 发送邮件(需要配置好mail命令)
echo “$message” | mail -s “进程监控告警” “$email”
# 同时记录到系统日志(syslog)
logger -t process_monitor “$message”
}
# 主函数:启动多个进程的监控
main() {
echo “$(date): 开始进程监控” | tee -a $LOG_FILE
# 启动后台子进程来监控不同的服务
monitor_process “nginx” “admin@example.com” &
monitor_process “mysqld” “admin@example.com” &
monitor_process “redis-server” “admin@example.com” &
# 等待所有后台监控进程(实际上会一直运行)
wait
}
# 执行入口
main
6.2 进程审计配置
Linux Audit子系统可以详细记录系统事件,包括进程的创建、执行和终止,是安全审计和故障排查的强大工具。
# 安装audit审计工具
$ sudo dnf install audit
# 配置进程相关的审计规则,规则文件通常放在/etc/audit/rules.d/
$ sudo tee /etc/audit/rules.d/process.rules << ‘EOF‘
# 审计所有进程创建事件(execve, fork, clone系统调用)
-a always,exit -F arch=b64 -S clone,execve,fork -k process-creation
-a always,exit -F arch=b32 -S clone,execve,fork -k process-creation
# 审计特权命令的执行(su, sudo)
-a always,exit -F path=/bin/su -F perm=x -k privileged-process
-a always,exit -F path=/usr/bin/sudo -F perm=x -k privileged-process
# 审计进程退出事件
-a always,exit -F arch=b64 -S exit_group,exit -k process-exit
-a always,exit -F arch=b32 -S exit_group,exit -k process-exit
# 审计身份变更事件(setuid, setgid系统调用)
-a always,exit -F arch=b64 -S setuid,setgid -k identity-change
-a always,exit -F arch=b32 -S setuid,setgid -k identity-change
EOF
# 加载审计规则
$ sudo auditctl -R /etc/audit/rules.d/process.rules
# 查询审计日志
$ sudo ausearch -k process-creation -ts today # 查找今天所有的进程创建事件
$ sudo ausearch -k privileged-process # 查找特权命令执行事件
$ sudo ausearch -p 1234 # 查找与特定PID相关的所有审计事件
# 生成审计报告
$ sudo aureport -p --summary # 进程相关的报告摘要
$ sudo aureport -e --summary # 事件报告摘要
# 实时监控审计日志(过滤显示进程执行事件)
$ sudo tail -f /var/log/audit/audit.log | grep -E “type=SYSCALL.*exe=”
# 使用auditctl临时添加自定义审计规则(重启失效)
$ sudo auditctl -a always,exit -F arch=b64 -S execve -F path=/usr/bin/python3 -k python-execution
$ sudo auditctl -a always,exit -F arch=b64 -S execve -F path=/bin/bash -k shell-execution
计划任务与定时执行
7.1 cron定时任务
cron是经典的Unix定时任务调度器,适用于按照固定时间点或周期执行任务。
# 编辑当前用户的crontab
$ crontab -e
# 系统级的crontab文件路径
$ sudo vim /etc/crontab
$ ls /etc/cron.*/ # 查看cron.daily, cron.hourly等目录
# 常用cron时间格式示例
# 分钟(0-59) 小时(0-23) 日(1-31) 月(1-12) 星期(0-7, 0和7代表周日) 命令
* * * * * /path/to/command # 每分钟执行一次
*/5 * * * * /path/to/command # 每5分钟执行一次
0 * * * * /path/to/command # 每小时的第0分钟执行(每小时一次)
0 2 * * * /path/to/command # 每天凌晨2点执行
0 2 * * 0 /path/to/command # 每周日凌晨2点执行
0 2 1 * * /path/to/command # 每月1日凌晨2点执行
0 2 1 1 * /path/to/command # 每年1月1日凌晨2点执行
# 特殊的预定义字符串(可读性更好)
@reboot /path/to/command # 系统启动时执行一次
@yearly /path/to/command # 每年执行一次 (等同于 0 0 1 1 *)
@annually /path/to/command # 同 @yearly
@monthly /path/to/command # 每月执行一次 (等同于 0 0 1 * *)
@weekly /path/to/command # 每周执行一次 (等同于 0 0 * * 0)
@daily /path/to/command # 每天执行一次 (等同于 0 0 * * *)
@hourly /path/to/command # 每小时执行一次 (等同于 0 * * * *)
@midnight /path/to/command # 同 @daily
# 在crontab开头设置环境变量(cron的环境变量很精简)
$ crontab -l | head -5
SHELL=/bin/bash
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=admin@example.com # 指定任务输出邮件的接收地址
# 查看cron任务的执行日志
$ sudo tail -f /var/log/cron
$ grep CRON /var/log/cron
# 禁止cron发送邮件(将输出重定向到空设备)
* * * * * /path/to/command >/dev/null 2>&1
# 或者,如果命令可能以非零状态退出,可以这样忽略错误
* * * * * /path/to/command >/dev/null 2>&1 || true
7.2 systemd定时器
systemd timer是cron的现代替代品,与systemd服务深度集成,支持更精细的时间控制和依赖管理。
# 1. 创建systemd定时器单元文件:/etc/systemd/system/backup.timer
[Unit]
Description=Run backup daily at 2:00 AM
[Timer]
OnCalendar=daily # 每天执行
Persistent=true # 如果上次执行时间错过了,启动后会立即补执行一次
Unit=backup.service # 指定要触发的服务单元
# 更复杂的时间设定示例:
# OnCalendar=*-*-* 02:00:00 # 每天2点(等同daily)
# OnCalendar=Mon..Fri 02:00:00 # 每周一到周五2点
# OnCalendar=*-1,15 02:00:00 # 每月1号和15号的2点
# 基于相对时间的触发:
# OnBootSec=15min # 系统启动后15分钟执行
# OnUnitActiveSec=1h # 上次服务被激活后1小时执行(例如用于间隔性任务)
[Install]
WantedBy=timers.target # 安装目标,使定时器能随系统启动
# 2. 创建对应的service单元文件:/etc/systemd/system/backup.service
[Unit]
Description=Backup service
[Service]
Type=oneshot # 一次性服务,执行完即退出
ExecStart=/usr/local/bin/backup.sh
User=backup # 指定运行用户
Group=backup
[Install]
WantedBy=multi-user.target
# 3. 启用并管理systemd定时器
$ sudo systemctl daemon-reload # 重载配置
$ sudo systemctl enable backup.timer # 启用定时器(开机自启)
$ sudo systemctl start backup.timer # 立即启动定时器
$ sudo systemctl list-timers --all # 列出所有定时器及其下次触发时间
$ sudo systemctl status backup.timer # 查看定时器状态
$ sudo journalctl -u backup.service # 查看该定时任务执行的历史日志
# 手动立即运行一次定时器对应的服务(不等待定时触发)
$ sudo systemctl start backup.service
7.3 at一次性任务
at命令用于安排一次性任务在未来某个特定时间运行,适合执行临时的、非周期性的任务。
# 安装at(CentOS 8可能默认未安装)
$ sudo dnf install at
$ sudo systemctl enable --now atd # 启用并启动at守护进程
# 创建at任务(通过管道传递命令)
$ echo “/path/to/command” | at now + 1 hour # 1小时后执行
$ echo “/path/to/command” | at 2:00 tomorrow # 明天凌晨2点执行
$ echo “/path/to/command” | at 2pm next week # 下星期下午2点执行
# 交互式创建at任务(更灵活,可输入多行命令)
$ at 14:30 2024-12-01
at> /path/to/command1
at> /path/to/command2
at> <EOT> # 按 Ctrl+D 结束输入并提交任务
job 1 at Mon Dec 1 14:30:00 2024
# 查看等待执行的at任务队列
$ atq
$ at -l
# 查看特定编号任务的具体内容
$ at -c 1
# 删除(移除)尚未执行的任务
$ atrm 1
$ at -d 1
# 访问控制:通过allow/deny文件限制用户使用at命令
$ sudo vim /etc/at.allow # 只允许列表中的用户使用at
$ sudo vim /etc/at.deny # 拒绝列表中的用户使用at(如果allow文件存在,则deny被忽略)
进程故障排查
当系统出现性能问题或服务异常时,高效的进程诊断能力是快速恢复的关键。以下是常见的排查思路和工具组合。
8.1 常见问题诊断
# 1. 诊断CPU使用率过高的问题
$ ps aux --sort=-%cpu | head -10 # 查看CPU使用率最高的前10个进程
$ top -b -n 1 | head -20 # 获取top快照查看详情
$ pidstat -u 1 5 # 每1秒采样一次,共5次,查看进程CPU统计详情
# 2. 诊断内存使用率过高或内存泄漏
$ ps aux --sort=-%mem | head -10 # 查看内存使用率最高的前10个进程
$ top -b -n 1 -o %MEM | head -20 # 按内存排序查看top快照
$ pidstat -r 1 5 # 查看进程的内存统计(RSS、VSZ等)
# 3. 查找卡住的进程:不可中断睡眠(D)或僵尸进程(Z)
$ ps aux | awk ‘$8==“D”‘ # 查找处于不可中断睡眠的进程(通常与I/O相关)
$ ps aux | awk ‘$8==“Z”‘ # 查找僵尸进程
$ ps aux | grep ‘defunct‘ # 另一种查找僵尸进程的方法
# 4. 诊断文件描述符泄漏
$ lsof -p 1234 | wc -l # 统计PID为1234的进程打开的文件数
$ ls -l /proc/1234/fd | wc -l # 通过proc文件系统查看(更高效)
$ cat /proc/1234/limits # 查看该进程的资源限制,包括Max open files
# 5. 分析进程死锁或挂起
$ strace -p 1234 # 跟踪进程的系统调用,看其卡在哪个调用上
$ pstack 1234 # 打印进程的堆栈跟踪(需要安装gdb)
$ gdb -p 1234 # 使用GDB附加到进程进行交互式调试
# 6. 进程性能剖析(Profiling)
$ perf stat -p 1234 # 对进程进行基础性能统计(周期、缓存命中率等)
$ perf top -p 1234 # 实时显示进程内哪些函数/符号消耗CPU最多
$ perf record -p 1234 -g # 记录进程的性能数据(带调用图),生成perf.data
$ perf report # 分析上面记录的perf.data文件
8.2 系统资源诊断工具集
一个强大的 运维/DevOps 工程师离不开一套顺手的综合诊断工具。
# 安装常用的诊断工具包
$ sudo dnf install sysstat dstat htop iotop iftop nethogs
# 综合监控仪表(dstat是一个全能选手)
$ dstat -cdngy 1 # 同时显示CPU、磁盘、网络、内存页面、系统统计,每秒刷新
# 虚拟内存和系统统计
$ vmstat 1 10 # 每秒采样一次,共10次,查看进程、内存、swap、IO、CPU等
$ mpstat -P ALL 1 # 查看所有CPU核心的详细利用率统计,每秒刷新
# 磁盘I/O监控
$ iostat -x 1 # 查看扩展磁盘I/O统计,包括await、%util等关键指标
$ iotop -o # 类似top,但显示的是实时磁盘I/O使用情况按进程排序
# 网络监控
$ iftop -i eth0 # 实时监控eth0网卡的流量,按连接对显示
$ nethogs eth0 # 按进程显示eth0网卡的实时网络带宽使用情况
$ ss -tulpn # 比netstat更快的工具,查看监听端口和连接及其对应进程
# 内存详细情况
$ free -h # 查看内存和swap使用概览(-h人类可读格式)
$ cat /proc/meminfo # 查看极其详细的内存信息
$ slabtop # 实时显示内核slab缓存信息(内核对象缓存)
# 进程家族关系分析
$ pstree -p 1234 # 以树状形式显示PID为1234的进程及其所有子进程
$ ps -ef --forest | grep -A5 -B5 “1234” # 用forest参数显示进程树,并过滤出目标进程上下文
8.3 核心转储配置与分析
当进程发生严重错误(如段错误)时,生成核心转储文件(core dump)是事后分析崩溃原因的生命线。
# 配置系统级别的核心转储
$ sudo tee /etc/sysctl.d/50-coredump.conf << ‘EOF‘
# 设置core文件生成路径和命名模式
kernel.core_pattern = /var/coredump/core-%e-%p-%t
# %e: 可执行文件名,%p: PID,%t: 崩溃时间戳
kernel.core_uses_pid = 1 # 在core文件名后加上.PID
fs.suid_dumpable = 2 # 允许setuid程序生成core dump(安全环境下)
EOF
$ sudo sysctl -p /etc/sysctl.d/50-coredump.conf # 应用配置
# 创建核心转储目录并设置权限
$ sudo mkdir -p /var/coredump
$ sudo chmod 1777 /var/coredump # 粘滞位,防止用户删除他人的core文件
# 为当前Shell会话设置核心转储文件大小限制为无限制
$ ulimit -c unlimited
# 永久生效:将上行添加到对应用户的 ~/.bashrc 文件中
# 在systemd服务中启用核心转储
[Service]
LimitCORE=infinity # 允许生成任意大小的core文件
# 使用GDB分析核心转储文件
$ gdb /path/to/program /var/coredump/core-program-1234-1234567890
(gdb) bt # 打印崩溃时的堆栈回溯(backtrace)
(gdb) info threads # 查看所有线程的信息
(gdb) thread apply all bt # 查看所有线程的堆栈回溯
# 使用systemd的coredumpctl工具管理核心转储(更现代化)
$ coredumpctl list # 列出系统记录的所有核心转储
$ coredumpctl info 1234 # 显示PID为1234的进程生成的核心转储信息
$ coredumpctl gdb 1234 # 直接用GDB打开PID为1234对应的最新核心转储进行调试
最佳实践与安全
9.1 进程安全配置
遵循最小权限原则是保障系统安全的基础,应避免任何进程以不必要的root权限运行。
# 1. 使用专用非特权用户运行服务
$ sudo useradd -r -s /sbin/nologin myservice # -r创建系统用户,-s指定无法登录的shell
$ sudo chown -R myservice:myservice /opt/myservice # 将程序文件所属权改为该用户
# 2. 使用Linux Capabilities替代完整的root权限
# 例如,如果程序只需要绑定到1024以下端口,无需以root运行整个程序
$ sudo setcap CAP_NET_BIND_SERVICE=+eip /usr/bin/myapp
# 赋予myapp程序CAP_NET_BIND_SERVICE能力,使其可以绑定特权端口
# 3. 充分利用systemd的沙盒和安全选项(在Service段中配置)
PrivateTmp=true # 服务使用私有的/tmp和/var/tmp,与系统隔离
PrivateDevices=true # 服务无法直接访问物理设备(如磁盘、声卡)
PrivateNetwork=true # 服务运行在新的网络命名空间,初始无网络
ProtectSystem=strict # 使文件系统根目录只读,仅允许写入特定目录
ProtectHome=true # 使/home, /root, /run/user目录对服务不可访问
NoNewPrivileges=true # 确保服务及其子进程无法获得新的特权(如通过setuid)
# 4. 使用Linux命名空间进行进程隔离(手动示例)
$ sudo unshare --pid --fork --mount-proc /bin/bash # 创建新的PID和mount命名空间
$ sudo nsenter --target 1234 --pid --mount # 进入PID为1234的进程所在的命名空间
# 5. 监控特权命令的执行(结合前面讲的audit)
$ sudo auditctl -w /usr/bin/sudo -p x -k privileged_command
$ sudo ausearch -k privileged_command -ts today
9.2 性能优化配置
通过合理的资源限制和调度策略,可以优化系统整体性能,防止个别异常进程拖垮系统。
# 一个优化的systemd服务配置示例
[Service]
# CPU调度与统计
CPUAccounting=true # 启用CPU使用量统计
CPUQuota=75% # 限制该服务最多使用75%的单个CPU核心
CPUShares=1024 # 设置CPU份额(权重),默认1024
# 内存限制与统计
MemoryAccounting=true # 启用内存使用量统计
MemoryMax=1G # 硬内存限制
MemorySwapMax=2G # 交换分区限制
# I/O优先级与统计
IOAccounting=true # 启用I/O统计
IOWeight=100 # 设置I/O权重(相对值)
# 进程数限制
TasksMax=500 # 该cgroup内最大任务数
LimitNPROC=500 # 用户最大进程数限制
# 文件描述符优化
LimitNOFILE=65536 # 单个进程最大打开文件数(硬限制)
LimitNOFILESoft=32768 # 软限制
# 服务启动/停止行为优化
TimeoutStartSec=30s # 启动超时时间,超时则视为启动失败
TimeoutStopSec=30s # 停止超时时间,超时则发送SIGKILL强制终止
RestartSec=5s # 自动重启前等待的时间,避免频繁重启循环
9.3 监控告警配置
将进程指标纳入集中式监控系统(如Prometheus),是实现可观测性和主动告警的现代实践。
# Prometheus监控配置示例:添加process-exporter采集任务
# 编辑 /etc/prometheus/prometheus.yml
scrape_configs:
- job_name: ‘process_exporter‘
static_configs:
- targets: [‘localhost:9256‘] # process-exporter默认监听端口
# 安装并使用process-exporter(导出进程级别的指标)
$ sudo dnf install process-exporter
# 配置process-exporter监控哪些进程(可选,默认监控所有)
$ sudo tee /etc/process-exporter.yml << ‘EOF‘
process_names:
- name: “{{.Comm}}” # 按命令名分组
cmdline:
- ‘.+‘ # 匹配所有进程
EOF
# 使用node_exporter的文本文件收集器也能监控进程(如果已安装node_exporter)
# 可以编写脚本将ps命令输出转换为Prometheus格式,放入指定目录
$ curl http://localhost:9100/metrics | grep -E “(process|cpu|memory)” # 查看基础指标
实用脚本工具
10.1 进程管理工具箱
以下是一个综合性的Shell脚本,封装了多种常用的进程管理操作,方便日常使用。
#!/bin/bash
# process_toolbox.sh - 进程管理工具箱
set -e # 遇到错误立即退出
# 颜色定义,用于美化输出
RED=‘\033[0;31m‘
GREEN=‘\033[0;32m‘
YELLOW=‘\033[1;33m‘
NC=‘\033[0m‘ # No Color
# 显示使用帮助
show_help() {
cat << EOF
进程管理工具箱
用法: $0 [选项] [参数]
选项:
monitor [进程名] 监控指定进程的状态和资源
find [进程名] 查找进程(支持名称和命令行匹配)
kill [进程名] 终止指定名称的进程(强制)
limit [PID] 查看并设置进程资源限制(示例)
stats 显示系统进程统计(按用户)
top5 显示TOP5 CPU和内存消耗进程
clean 尝试清理僵尸进程
tree [PID] 显示进程树(不指定PID则显示全部)
analyze [PID] 详细分析指定PID的进程
help 显示此帮助信息
EOF
}
# 功能1:交互式监控进程
monitor_process() {
local process=$1
echo -e “${GREEN}监控进程: $process${NC}”
while true; do
clear
echo “=== 进程监控: $process ===”
echo “时间: $(date)”
echo
local pids=$(pgrep -d‘,‘ “$process”) # 获取所有匹配的PID,逗号分隔
if [ -z “$pids” ]; then
echo -e “${RED}进程未运行${NC}”
else
echo “PID列表: $pids”
echo
# 显示详细的进程信息,按CPU排序
ps -p “$pids” -o pid,ppid,user,%cpu,%mem,rss,vsz,cmd --sort=-%cpu
echo
echo “=== 资源统计 ===”
# 计算总的CPU和内存使用
ps -p “$pids” -o %cpu --no-headers | awk ‘{sum+=$1} END {printf “CPU使用率: %.1f%%\n”, sum}‘
ps -p “$pids” -o rss --no-headers | awk ‘{sum+=$1} END {printf “内存使用: %.1f MB\n”, sum/1024}‘
fi
echo
echo “按Ctrl+C退出监控”
sleep 2
done
}
# 功能2:多维度查找进程
find_process() {
local pattern=$1
if [ -z “$pattern” ]; then
echo “请输入查找模式(支持正则表达式)”
return 1
fi
echo -e “${GREEN}查找进程: $pattern${NC}”
echo “=== 根据进程名查找 ==="
pgrep -l “$pattern”
echo -e “\n=== 根据完整命令行查找 ==="
pgrep -fl “$pattern”
echo -e “\n=== 详细进程信息 (ps aux) ==="
ps aux | grep -E “$pattern” | grep -v grep # grep -v 排除掉grep进程本身
}
# 主控制函数
main() {
case “$1” in
monitor)
if [ -z “$2” ]; then
echo “请指定要监控的进程名”
exit 1
fi
monitor_process “$2”
;;
find)
if [ -z “$2” ]; then
echo “请指定查找模式”
exit 1
fi
find_process “$2”
;;
kill)
if [ -z “$2” ]; then
echo “请输入要终止的进程名”
exit 1
fi
pkill -9 “$2” # 强制终止
echo “已发送SIGKILL给进程: $2”
;;
stats)
echo “=== 系统进程统计(按用户) ===”
ps -eo user= | sort | uniq -c | sort -rn
;;
top5)
echo “=== TOP5 CPU消耗进程 ===”
ps aux --sort=-%cpu | head -6 # head -6 因为第一行是标题
echo -e “\n=== TOP5 内存消耗进程 ===”
ps aux --sort=-%mem | head -6
;;
clean)
echo “尝试清理僵尸进程...”
# 谨慎操作!这里强制杀死所有僵尸进程。
kill -9 $(ps aux | awk ‘$8==“Z” {print $2}‘ 2>/dev/null) 2>/dev/null || true
echo “完成。”
;;
tree)
if [ -n “$2” ]; then
pstree -p “$2”
else
pstree
fi
;;
analyze)
if [ -z “$2” ]; then
echo “请输入要分析的进程PID”
exit 1
fi
echo “=== 进程深度分析 PID: $2 ===”
echo “1. 基础状态与命令:”
ps -p “$2” -o pid,stat,cmd
echo -e “\n2. 打开的文件(前20个):”
lsof -p “$2” | head -20
echo -e “\n3. 内存映射(前20行):”
pmap “$2” | head -20
# 可以扩展:查看环境变量、cgroup信息、线程等
;;
help|*)
show_help
;;
esac
}
# 脚本执行入口
main “$@”
 发表于 2025-12-9 04:54:00
|
查看: 209|
回复: 0
发表于 2025-12-9 04:54:00
|
查看: 209|
回复: 0
