最近有人提出这样一个问题:既然有了大模型,可以直接用它来合成数据,快速生产,那我们还需要昂贵且缓慢的人工标注吗?
目前行业内的数据生产确实很大程度上在这么干。模型蒸馏几乎成了公开的秘密——让强模型出题,弱模型跟着学,配上几行配置,挂上几百张GPU卡跑几天,产出的数据量可能就抵得上过去百人团队大半年的工作。甚至有人乐观地认为,这可以像“左脚踩右脚”一样,实现模型的自我迭代与永动。
然而,根据我的观察,这个结论并不牢固。事实恰恰相反,人工标注不仅依然需要,而且对其质量的要求变得更高了。过去一天几百块请几个标注员干活的时代早已一去不复返。我曾做过调研,如今在国内一些专业领域,一条高质量的数据样本报价高达几千块,国外的价格则更为夸张。
“外包”行业背后的真实价值
很多人不理解为什么扎克伯格要重金投资像 Scale AI 这样的数据标注公司。其根本原因,在于不了解现代数据标注的真实价值所在。

这绝非简单的“人力外包”。Meta 看重的,是 Scale AI 固化在工程流水线里的那套科学管理机制,以及他们的专家招募和任务评估体系。在今天的后训练时代,数据标注的核心任务已经从“识别图像中的猫狗”进化到了“对齐复杂的人类推理逻辑”。
Scale AI 的厉害之处在于,它能将医疗、法律、代码等高门槛领域的隐性知识,通过精密的标准化作业程序(SOP)进行结构化拆解,再通过专家筛选,把人类零散、高级的智慧“提纯”为AI可理解、可学习的核心资产。在大家算力逐渐趋同的当下,谁掌握了这套将“人脑认知”高效转化为“机器认知”的工业级基础设施,谁就可能掌握通向AGI竞争终局的钥匙。
这并非孤例,而是硅谷逐渐形成的共识。据外媒报道,另一家数据标注领域的独角兽公司 Surge AI,其估值正逼近250亿美元。更令人惊讶的是,它在寻求融资前,年营收就已超过10亿美元。

该公司的CEO,前谷歌科学家Edwin Chen,就多次公开指出纯机器合成数据的问题。他认为,当前的大模型训练正深陷一种“榜单作弊”的怪圈:研究者们使用脱离现实、由AI批量生成的合成题库进行训练和评测,结果养出了一批“高分低能”的做题家模型。这些模型写文章排版精美、语气讨好,但一碰到真实的业务逻辑就原形毕露。
Edwin的原话非常犀利:“很多客户告诉我们,一千条或几千条真正高质量的、由人类精心打磨的数据,其价值远超一千万条由AI批量生成的平庸对话。”
至于业界最爱鼓吹的“生成成本趋近于零”,他认为这本质上是在给未来埋雷。那些带着看似微小瑕疵的“毒数据”一旦混入训练数据的底层,前端省下的那点标注费用,后端往往要花费成百上千倍的算力和人力去“排毒”和修正。
新洞察的客观证据
最近,一家曾服务过多家头部大模型厂商、在国内AI数据标注领域知名的公司“智能知识”的研究团队,对合成数据进行了深入研究,并用事实数据验证了上述观点。
他们对两个公开的编程训练数据集进行了抽样审查,随机抽取其中被标记为“困难(hard)”的题目,并由经验丰富的专家逐题拆解分析。
审查流程分三步走:首先检查数据集提供的“标准答案”自身能否通过测试(Oracle验证);然后进行静态代码审查;最后使用大模型动态解题,并分析其逻辑轨迹。
这两个数据集分别是:
- SETA(由Camel-AI发布):号称全自动生成与验证的SOTA级合成数据集。

- Terminal-Bench Pro:由阿里开源,号称包含400个经专家手工审计的复杂任务。
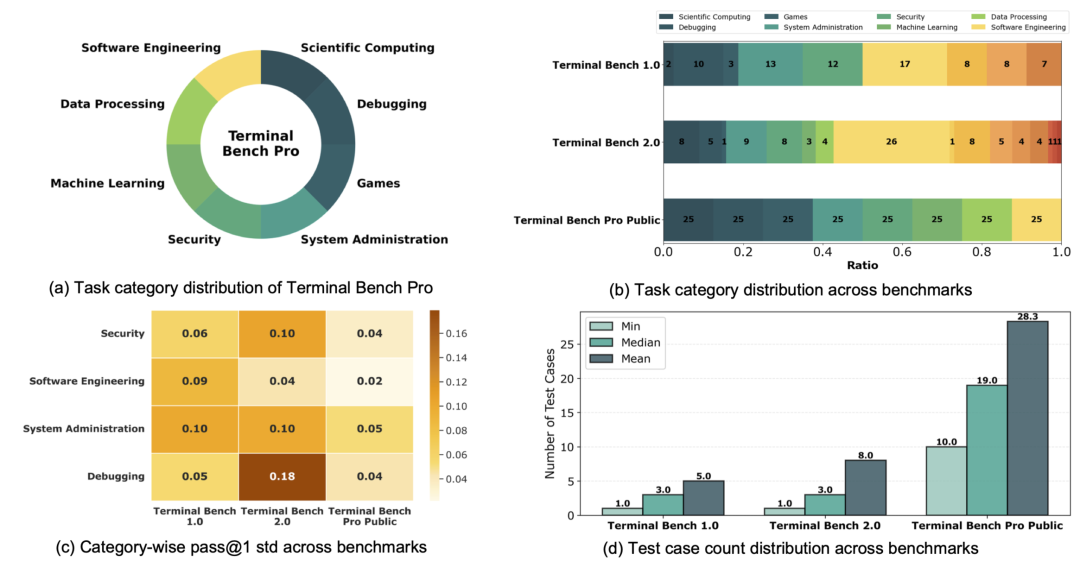
但实际的测试结果却令人意外:两个数据集的合格率同样低得可怜,近九成的题目存在严重质量问题。 具体问题分布如下:
| 问题类型 |
SETA(纯AI生成) |
Terminal Bench Pro(AI+人工审计) |
说明 |
| “标准答案”自己就是错的 |
~20% |
~10% |
参考答案无法通过自身的测试用例 |
| 没有训练价值 |
~35% |
~45% |
题面本身就是答案或为虚假难题,模型只需照抄 |
| 题目与测试不匹配 |
~35% |
~35% |
模型做对了被判错,做错了反而判对 |
| 勉强可用 |
~10% |
~10% |
没有大问题,但训练价值有限 |
两个数据集的“不合格大头”高度一致:虚假难题和测试失真合计占了七八成。人工参与虽然稍微减少了“答案本身出错”的概率,但在测试设计的完备性和题目难度的校准上,几乎没有带来明显改善。
最终的结论很残酷:纯靠AI合成数据不行,但找不对人、用不对方法来把关,同样也不行。
我们来看看研究团队的具体发现。
陷阱一:纯靠AI生成,根本不靠谱
模型面对的往往不是真正的难题,而是充满陷阱的“废题”。具体有哪些坑呢?
第一坑:环境依赖缺失,题目直接报废。
很多题目在Docker环境下根本跑不起来。例如,在任务 Harbor-Dataset/25 中,题目要求修复一个日志处理脚本,但对应的Dockerfile中引用了不存在的 sample.log 文件,导致构建直接失败。智能体(Agent)甚至无法进入Docker沙箱去执行任务。
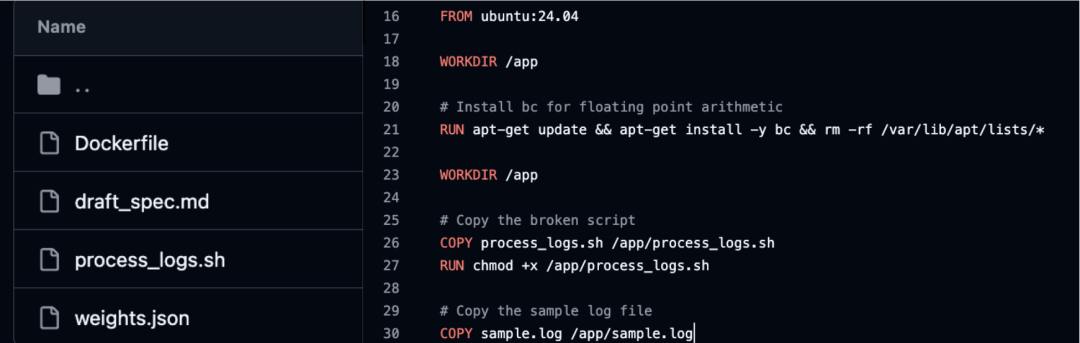
每道编程题都需要一个Docker容器作为运行环境。AI生成了Dockerfile,指定了要复制的文件,但却忘了生成这些文件本身。这是AI的典型短板:在单个文件内能保持逻辑自洽,但在处理多个文件间的协同与依赖关系时,容易出现“引用悬空”的错误。
第二坑:测试用例不靠谱,奖励信号失真。
在强化学习训练中,测试用例是奖励信号(Reward)的唯一来源。如果测试本身有问题,模型学到的就不是正确逻辑,而是如何“碰运气”。
- 测试了超出题目定义的内容。
在任务 Harbor-Dataset/82 中,题目要求开发一个命令行工具来实现软件包依赖解析。Prompt只描述了功能,并未限制输出文件的名称。但测试脚本却硬编码调用了 /app/pkg_resolver.py。这意味着,即使模型完美实现了功能,只要没猜中这个特定的文件名,就会被判错。
Build a command-line tool that simulates package dependency resolution with two upgrade strategies: a conservative upgrade mode and a full upgrade mode. The tool should manage package versions and their dependencies, demonstrating the difference between simple upgrades (that never remove or add new packages) and intelligent upgrades (that can add or remove packages to resolve conflicts).
Your tool should:
Read package definitions from a JSON configuration file that specifies packages, their versions, and dependencies
Implement a "safe-upgrade" command that only upgrades packages without adding new packages or removing existing ones
Implement a "full-upgrade" command that intelligently resolves dependencies by adding or removing packages as needed
Handle virtual packages (packages that can be provided by multiple concrete packages)
Detect and report "kept back" packages when safe-upgrade cannot proceed
Show clear output indicating which packages will be upgraded, newly installed, or removed
The scenario mimics a real package manager's upgrade logic where some packages have complex interdependencies that require installing additional packages or switching between provider packages.
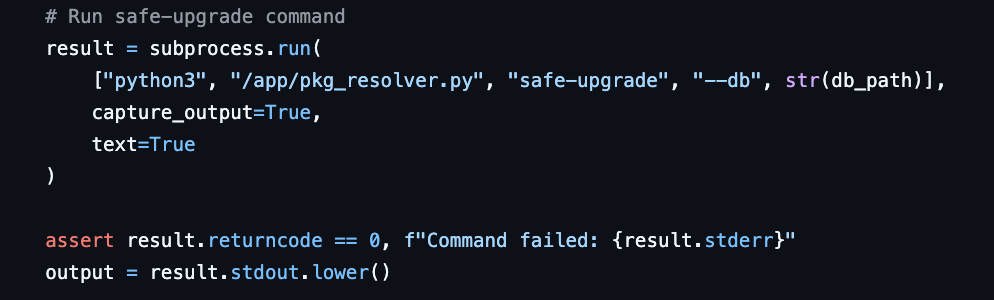
- 应该测试的内容没有测试。
任务 Harbor-Dataset/836 要求编写一个整理媒体文件的脚本,并明确要求实现 --dry-run(预演)模式。但在整个测试套件中,没有任何用例去测试这个 --dry-run 功能。这意味着模型即使完全忽略这个需求,也可能拿到满分。
- 测试标准过严或过松,导致奖励信号等于随机噪声。
测试用例就是“阅卷老师”。如果老师批改试卷的标准本身是错的,那分数就毫无意义。例如前述 Harbor-Dataset/82 任务,测试脚本对工具的输出格式、措辞做了硬编码假设。这会给训练发送完全错误的信号——模型可能因为输出语句的细微差别(而非核心逻辑错误)而被惩罚。
第三坑:题目本身毫无价值。
答案直接写在题面里,模型只是在练习“照抄”,无法锻炼任何推理或探索能力。
以 Harbor-Dataset/849 题目为例,它要求修复一个有bug的部署脚本,但脚本里的注释已经把每个bug的位置和原因写得一清二楚。
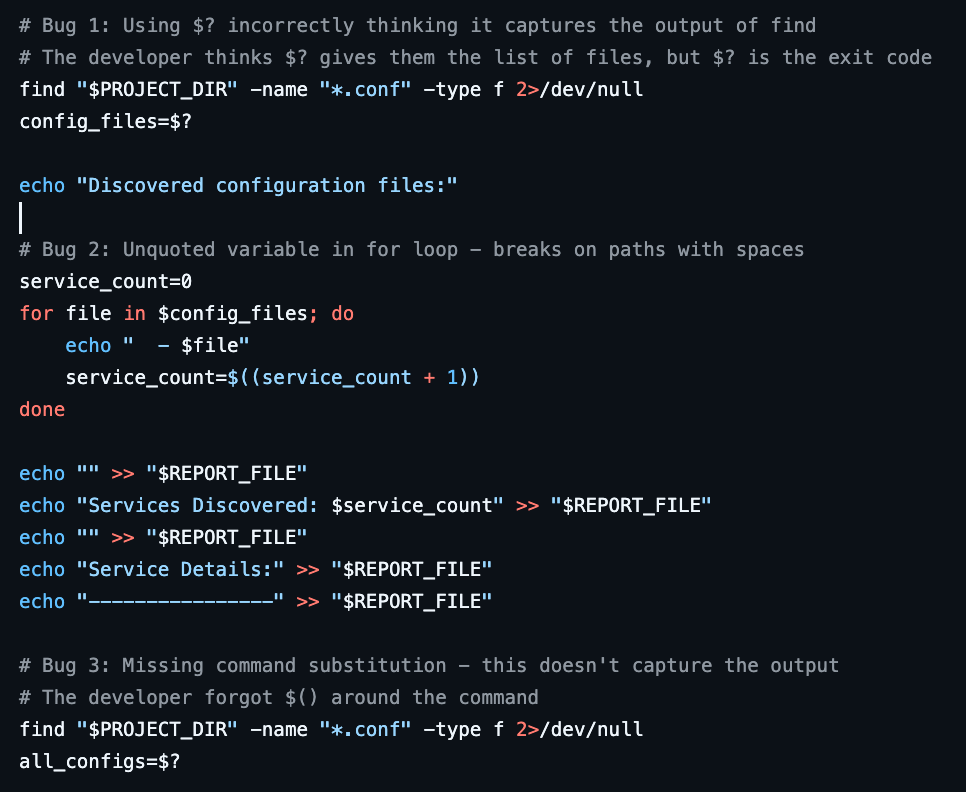
这类题目虽然被标注为“hard”,但模型几乎总能做对,导致奖励信号的方差极低,梯度几乎为零。它们白白占用了宝贵的训练资源,却不会带来任何实质性的能力提升。
总结下来,AI能生成出看起来结构完整、语法正确的题目和测试代码,但在多文件协同、测试用例的完备性设计以及题目难度的精准校准上,仍然存在显著的能力缺口。一个核心的限制是:纯合成数据无法超越生成它的母模型的能力上限。
陷阱二:简单的人类干预,同样效果有限
那么,加上人类专家的干预,情况会好转吗?“AI生成 + 专家复核”是目前行业里公认的更优解,听起来也很符合直觉。Terminal-Bench Pro 就是这个思路的代表,由领域专家手工审计调整,规格看似比纯AI生成的SETA高了不少。
但研究团队抽样审查后的结果依然残酷:合格率仍然只有大约10%。
剥开这90%的不合格数据,问题集中在两个层面:
一、专家也需要被有效管理,否则常识性问题也会翻车。
人不是万能的,缺乏有效的流程约束和质量检查机制,简单的错误也难以避免。例如在 build-python-sokoban-solver 任务中,题目要求实现一个推箱子游戏求解器。题目描述中定义了四个方向的坐标映射:上(U)、下(D)、左(L)、右(R)。但R(右)方向的坐标被错误地写成了 (1, 0),与D(下)方向完全一致。这明显是“复制粘贴后忘记修改”的低级错误。

雪上加霜的是,这道题的测试设计也有严重缺陷:环境中准备了10张不同的地图,但测试只用其中1张来运行求解器验证结果,其余9张只检查地图格式是否合法。这意味着,即使方向定义错了,求解器乱走一通,也大概率能蒙混过关。
二、需要真正懂行的专家,才能发现深层逻辑缺陷。
这解释了为什么专业领域的数据标注成本高得惊人——你是在为专家的深度认知买单。例如 build-nginx-1-24-production-server 这道题,要求配置Nginx服务器,核心功能之一是API限流:每秒10个请求。

测试脚本是怎么验证限流的呢?它只向服务器发送了5个请求,然后检查返回状态码。只要返回了3个以上的响应(无论是200成功还是503限流),就算测试通过。这意味着:一台完全没有配置任何限流的Nginx服务器,轻松处理5个请求全部返回200,也能在这项测试中拿到满分! 限流要求形同虚设。一个不懂Nginx限流机制内部原理的审查者,看到“测试发送了请求并检查了状态码”,很容易认为测试是完备的。只有真正懂行的专家才会立刻意识到,这个测试从根本上就无法验证限流功能是否生效。
从上面两个例子可以看出,简单的“专家看过”并不能有效提升数据集质量。 有效的任务分配、交叉审查、以及针对特定领域的深度质量检验流程,同样是关键一环。
研究团队这两个反直觉的结论,戳破的不仅仅是“AI能否自己造数据”的技术幻想,更挑战了一个更深层的行业假设——“只要有人工审核过,数据质量就有保障”。
核心结论
研究团队用严谨的案例和数据分析证明了一点:要获得高质量的编程训练数据,既不能依赖AI的全自动生成,也不能迷信于简单的“人工复核”。必须是 “真正懂行的领域专家” 与一套 “严格、科学的质量管理流程” 相结合,二者缺一不可。
我在之前的文章中提到过,未来AI公司最大的护城河可能是“高质量的人类专家数据”。现在为了贪图成本便宜而往训练数据里大量“掺水”(低质量合成数据),短期看是解决了数据量的燃眉之急,长期看无异于饮鸩止渴。这样训练出来的模型,可能在Benchmark榜单上看起来很美,但一到真实业务场景中就“原形毕露”;把掺杂了泥沙的合成数据作为模型底座,等于将客户的信任置于火山口上。模型每一次看似微小的“幻觉”或逻辑错误,在真实的金融、医疗、法律等业务中,都可能酿成无法挽回的灾难。
这正是像“智能知识”这类新型数据标注公司创立的底层逻辑:它们不再只是提供廉价劳动力,而是致力于招募顶尖的领域专家,并通过一整套科学的流程化、工程化方法,来“提纯”人类智慧,最终为客户沉淀下真正坚实、可靠的商业护城河。
附录:数据来源与案例索引
本文引用的具体案例,均来自智能知识研究团队对以下两个公开数据集的抽样审查。
数据集来源:
- SETA(Camel-AI):github.com/camel-ai/seta-env
- Terminal-Bench Pro(阿里开源):github.com/alibaba/terminal-bench-pro
引用案例详细出处:
- Harbor-Dataset/25:Dockerfile引用缺失文件,容器构建失败。 (github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/25)
- Harbor-Dataset/82:测试脚本硬编码文件名,导致功能正确的方案被判错。 (github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/82)
- Harbor-Dataset/836:
--dry-run功能完全未被测试覆盖。 (github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/836)
- Harbor-Dataset/849:Bug原因直接写在题面注释中,模型照抄即可。 (github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/849)
- build-python-sokoban-solver:方向坐标复制粘贴错误,且测试覆盖不足。 (github.com/alibaba/terminal-bench-pro/tree/main/build-python-sokoban-solver)
- build-nginx-1-24-production-server:限流测试设计存在根本缺陷,无法验证功能。 (github.com/alibaba/terminal-bench-pro/tree/main/build-nginx-1-24-production-server)
如果你想深入了解大数据处理与高质量数据集构建背后的技术与挑战,欢迎在云栈社区与更多开发者交流探讨。
 发表于 2026-3-17 03:29:23
|
查看: 284|
回复: 0
发表于 2026-3-17 03:29:23
|
查看: 284|
回复: 0
