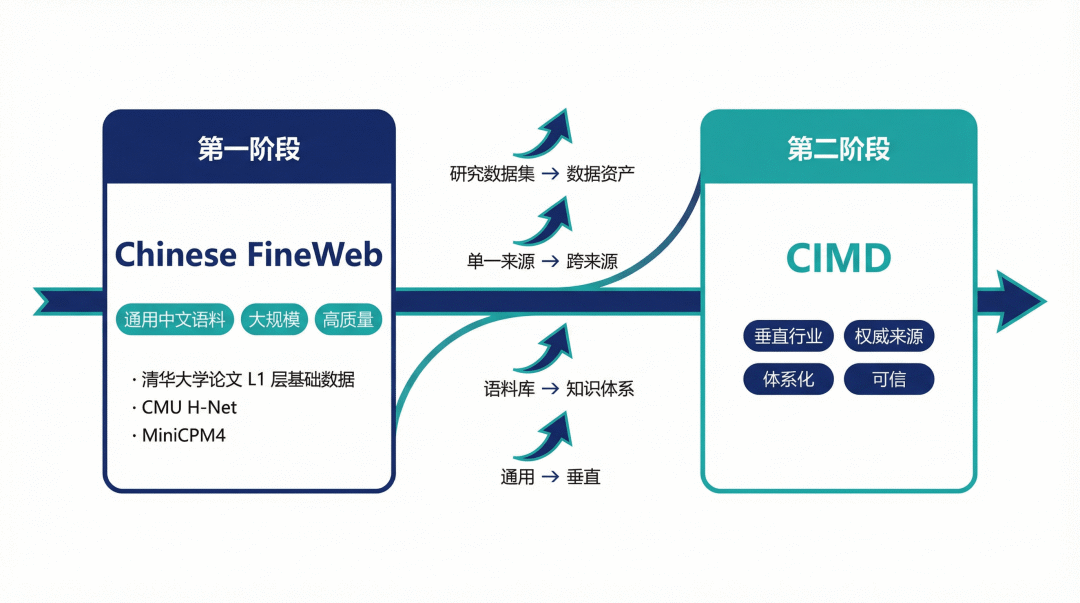
当通用中文数据集Chinese FineWeb在业界持续发光发热时,OpenCSG完成了一次重要的战略转身——从通用语料走向垂直行业,从语言模型基座延伸到产业智能底座。
2026年3月,OpenCSG正式开源 CIMD(Cross-Source Industry Corpus for Iron Ore, Mining, Metallurgy, Policy, and Market Intelligence),一个面向铁矿石及矿冶产业链的跨来源文本数据集。这不仅是OpenCSG数据战略的关键升级,更是行业AI从“具备对话能力”迈向“真正理解行业”的重要一步。
为什么是铁矿石?垂直行业AI的破局之道
在大模型热潮中,一个现实问题逐渐凸显:通用大模型能够流畅对话,但在面对复杂的专业行业问题时,其回答往往显得“隔靴搔痒”,缺乏深度和准确性。
以铁矿石产业为例,一个看似简单的合规性问题,实则需要调用来自不同维度的信息进行交叉验证:
- 法规层面:国家环保法律、地方政策、行业管理办法。
- 技术层面:采选工艺标准、排放标准、安全生产规范。
- 学术层面:矿石品位分析、选矿技术论文、环境影响评估。
- 市场层面:产能产量数据、价格走势、企业经营状况。
- 舆论层面:行业协会报告、券商研究、公众舆情。
传统的单一来源数据库(如政策库、论文库、市场库)只能提供局部信息,而真实的行业问题往往需要一条跨越多领域的连续证据链。这正是CIMD的核心价值:将制度、技术、研究、经营和市场文本置于同一数据体系内,使得AI能够像行业专家一样,进行“制度依据 + 技术原理 + 市场证据”的联合推理。
CIMD核心特性:不只是数据堆砌,而是行业知识体系
1. 跨来源整合:打破数据孤岛
CIMD最大的创新在于其跨来源整合能力。数据集汇集了来自52种不同来源的权威文本,具体包括:
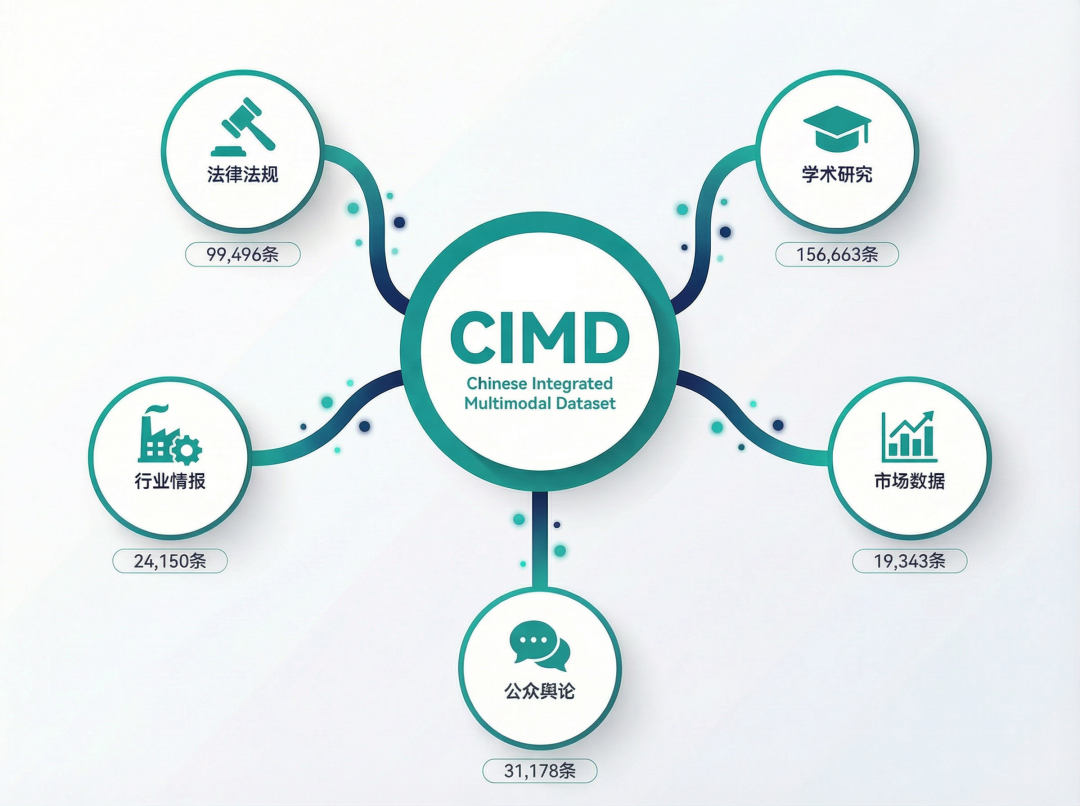
- 制度层面:包含99,496条法律法规记录。
- 学术层面:覆盖28,266条中文期刊论文、58,221条国内会议论文、37,961条博士学位论文,以及32,215条国际期刊文献。
- 产业层面:整合了超过14,000条行业研究报告、11,656条企业经营信息、6,282条产能产量数据。
- 舆情层面:纳入了31,178条社会公众与自媒体舆情数据。
这种设计使得同一个主题(例如“环保政策”)可以在法律法规、学术研究、行业报告等多个来源中找到相关信息,形成连续的上下文证据链,显著减少了因跨库检索造成的语义割裂。
2. 权威来源支撑:质量与可信度的双重保障
CIMD并非简单的网络爬虫数据,其内容来源于国家法律法规、行业标准、核心学术期刊、知名科研院所及行业协会等权威主体,深度覆盖从铁矿石资源、采选加工到炼铁生产的完整产业链。每条记录都保留了来源详情,确保数据可追溯。这种权威性是构建可信赖行业AI模型的重要基础。
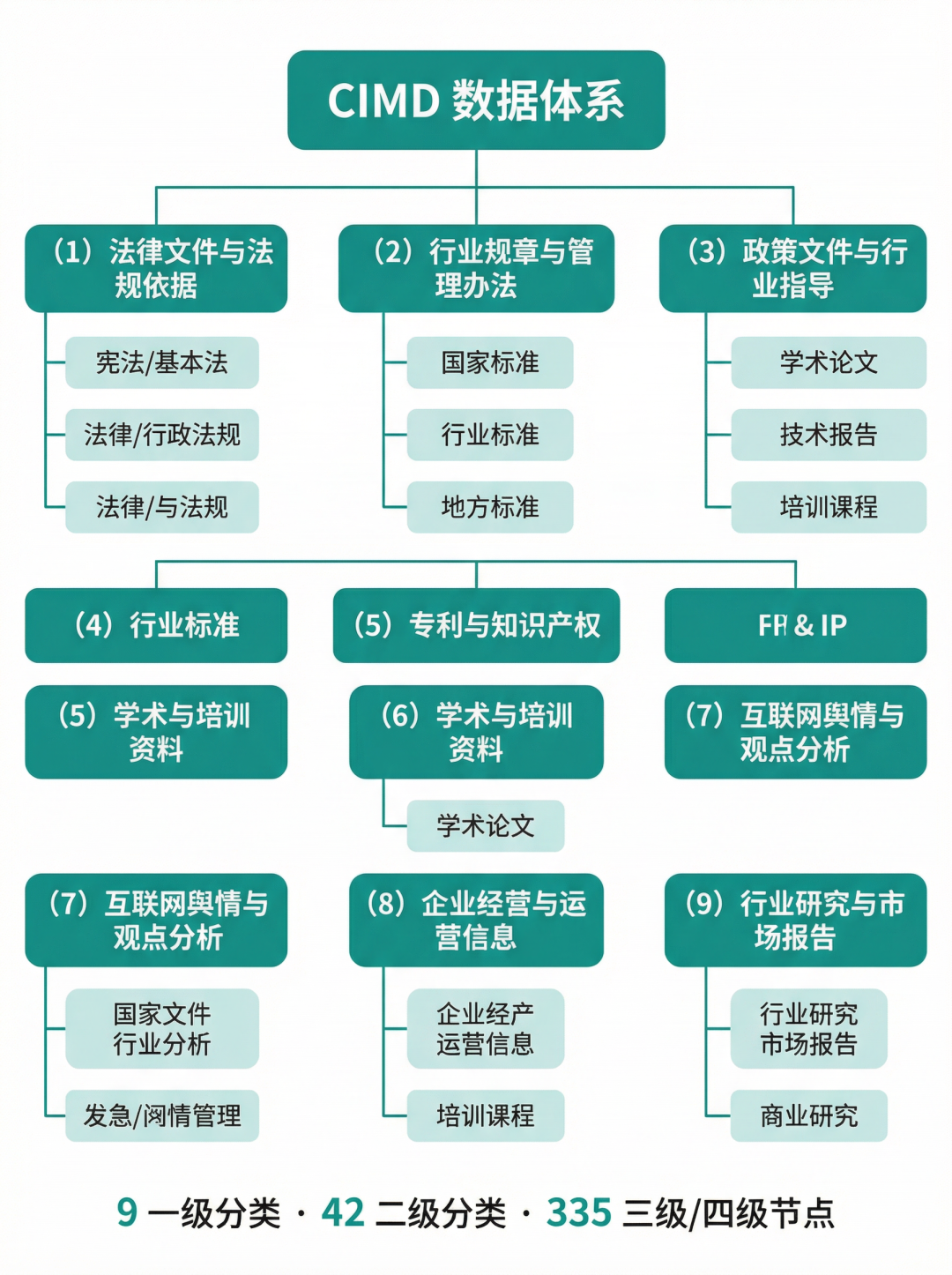
3. 完整数据体系:结构化知识图谱
CIMD不是文件堆砌,而是围绕铁矿石及矿冶产业构建的结构化知识体系。整个体系包含9个一级分类、42个二级分类和335个三/四级节点,覆盖法律文件、行业规章、政策指导、学术资料、市场报告等核心门类。这种体系化组织为后续的专题扩展、增量更新和任务设计提供了清晰的框架。
4. 元数据完整:从“能用”到“好用”的关键
CIMD每条记录都包含丰富的元数据字段,如file_id、title、source_type、author、language、keywords等。使用者可以轻松按来源、时间、语言进行筛选,并能将检索到的文本片段回溯至原始文件。这对于长文档检索、来源归因、质量控制和数据资产管理至关重要。
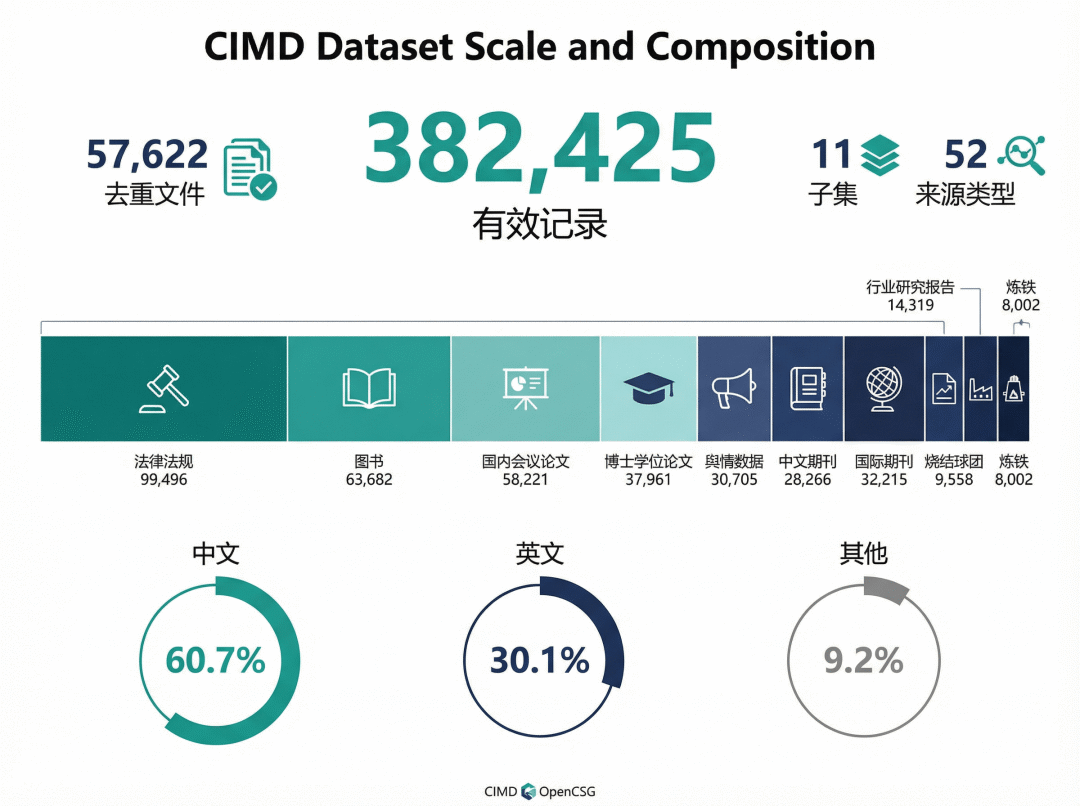
数据规模:38万+记录,覆盖完整产业链
| 项目 |
数值 |
| 有效 JSONL 记录 |
382,425 条 |
| 去重文件数 |
57,622 个 |
| 子集数量 |
11 个 |
| 来源类型 |
52 种 |
| 数据体系层级 |
9个一级分类,42个二级分类,335个三级/四级节点 |
从语言分布看,中文记录占60.7%,英文记录占30.1%。从来源类型看,期刊论文、国家法律法规和学术出版物是主要构成部分。
应用场景:从检索到Agent的全链路支撑
CIMD以统一的JSONL格式发布,旨在直接赋能模型与应用开发,尤其适用于人工智能领域的关键任务。
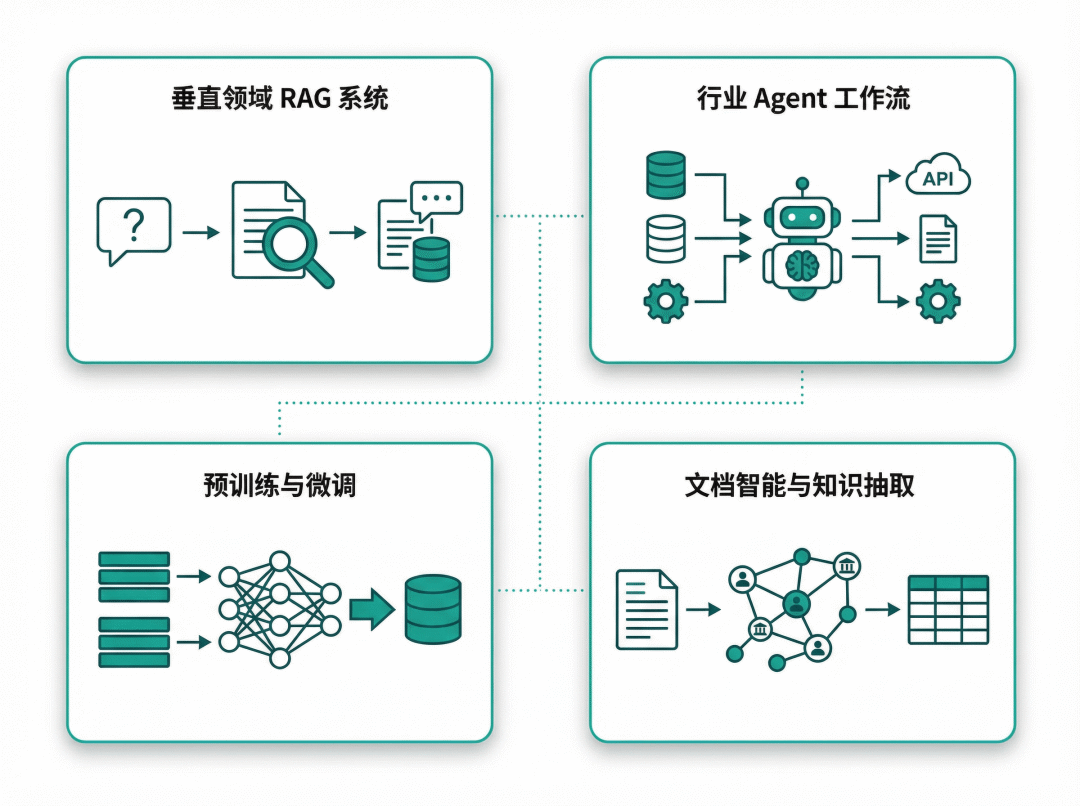
场景一:垂直领域RAG系统
构建铁矿石产业智能问答助手时,系统可基于CIMD的跨来源证据链,从法规、政策、市场等多维度检索信息,生成完整且可溯源的答案。
场景二:行业Agent工作流
在矿企合规审查Agent中,系统可以调用CIMD中的法规、企业数据、行业标准等信息,完成复杂的多步推理,生成可信的评估报告。
场景三:领域继续预训练与SFT
CIMD的全量38万+记录可用于垂直大模型的领域知识注入,其结构化元数据便于构建高质量的指令微调(SFT)数据和行业基准测试集。
场景四:文档智能与知识抽取
CIMD支持从海量行业文档中进行实体识别、关系抽取和事件抽取,是构建矿冶产业知识图谱的理想数据源。
从Chinese FineWeb到CIMD:数据战略演进
OpenCSG的数据开源路径呈现出清晰的战略演进:
- 第一阶段(通用):Chinese FineWeb系列,提供高质量通用中文预训练语料,支撑了多个前沿模型。
- 第二阶段(垂直):CIMD,标志着从通用走向垂直、从单一来源走向跨来源整合、从语料库走向知识体系的关键转变。
这反映了对AI发展脉络的洞察:通用大模型是基础,垂直行业AI是未来价值所在。
开源承诺:商业友好,推动产业智能化
CIMD采用 OpenCSG数据集许可协议。该协议明确支持商业用途,用户可将数据集用于研究、内部开发、模型训练及商业产品。OpenCSG的目标是在保护数据来源方权益的同时,为开源实战和行业AI发展提供必要的数据支撑,建立清晰的合规使用路径。
数据获取与使用指南
通过 Git 获取(推荐)
git lfs install
git clone https://opencsg.com/datasets/OpenCSG/CIMD.git
cd CIMD
git lfs pull
使用 ModelScope datasets
from modelscope.msdatasets import MsDataset
dataset = MsDataset.load(
dataset_name="CIMD",
namespace="opencsg",
subset_name="state_laws",
split="train",
)
11个子集说明
| 子集名称 |
记录数 |
文件数 |
内容 |
| state_laws |
99,496 |
7,300 |
法律法规、规章制度、政策文本 |
| domestic_conference_papers |
58,221 |
18,826 |
国内会议论文与会议资料 |
| doctoral_dissertations |
37,961 |
804 |
博士学位论文 |
| public_opinion |
30,705 |
9,427 |
舆情与观点资料 |
| chinese_journals |
28,266 |
6,412 |
中文期刊论文 |
| international_journal_of_mining_science_and_technology |
16,824 |
2,435 |
英文学术期刊 |
| international_journal_of_minerals_metallurgy_and_materials |
15,391 |
2,461 |
英文学术期刊 |
| industry_research_reports |
14,319 |
1,182 |
行业研究、券商、企业与产能相关材料 |
| sintering_and_pelletizing |
9,558 |
3,783 |
烧结球团专题资料 |
| ironmaking |
8,002 |
3,871 |
炼铁与生产专题资料 |
| books |
63,682 |
1,121 |
图书资料 |
使用注意事项:
- 当前统计为解析记录数,不等同于去重后的原始文档数。
- 子集通过Git LFS管理,clone后需执行
git lfs pull。
- 不同来源间可能存在重复或解析噪声。
- 用于训练或商用前,需结合来源信息核验实际授权范围。
展望:从铁矿石到更多行业
CIMD的发布是OpenCSG垂直行业智能 & 数据 & 云战略的第一步。其设计方法论具备高度的可复制性,可扩展至能源、化工、金融、医疗等其他垂直领域。通过持续更新、深化细分和拓展产业链,OpenCSG正在探索一条从通用AI到行业AI、从研究数据集到可信数据资产的完整路径。
结语:行业AI的基础设施,从数据开始
在关注模型与算力之外,行业AI的落地更需要高质量的数据基础设施。CIMD给出了一个范本:它提供权威来源的专业语料、跨来源整合的知识体系、带有完整元数据的数据资产,以及商业友好的开源许可。

OpenCSG通过开源CIMD,正在为行业AI构建关键的数据基石。当越来越多的垂直领域拥有此类高质量、可流通的数据集时,AI技术从实验室到产业应用的跨越才能真正实现。
引用格式:
@dataset{opencsg_cimd_2026,
title = {CIMD: A Cross-Source Industry Corpus for Iron Ore, Mining, Metallurgy, Policy, and Market Intelligence},
author = {OpenCSG},
year = {2026},
url = {https://opencsg.com/datasets/OpenCSG/CIMD},
note = {OpenCSG dataset repository}
}
社区地址:
对垂直行业AI数据集开发和应用感兴趣?欢迎到云栈社区交流讨论,共同探索AI与产业结合的前沿实践。
 发表于 2026-4-7 03:47:13
|
查看: 230|
回复: 0
发表于 2026-4-7 03:47:13
|
查看: 230|
回复: 0
