
一月底,OpenClaw刚火起来的时候,我就在自己的腾讯云服务器上部署了一个。
装完之后,我先在它的Web端玩了一会儿。当时的感受与其说是“功能强大”,不如说是困惑:这不就跟用ChatGPT或者Claude Code聊天差不多吗?我盯着屏幕琢磨了很久,最后冒出一个非常现实的问题:我到底该拿它来做什么?
有几天它几乎被我闲置了。偶尔打开,问几个问题,然后关掉。新鲜感一过,它就像个不知道怎么玩的高级玩具,没能真正融入我的日常。
后来我才逐渐明白,许多人用不好OpenClaw,问题往往不在于安装或配置,而在于没有找到合适的使用场景。它不是一个装上就能自动生效的工具,它需要你去“喂养”具体的场景,定义它的工作。
经过一个半月的摸索,我把它从一个“能聊天的机器人”,逐渐培养成了能真正接入工作和生活流程的助理。现在我和家人都在用它,它已经成为我们日常技术文档协作的一部分。
如果你也装了OpenClaw,但还停留在偶尔提问的阶段,我想直接分享目前最常使用的六个真实场景。
场景一:随手记录与自动归档,降低记录门槛
以前,我脑子里闪过一个想法或观察到一件事,总会卡在一个心理环节:这条信息该记在哪里?值得专门记录吗?算了,晚点再说吧。结果往往是“晚点”就忘了。
现在,我会随手把各种碎片信息丢给AI助手(我称它为“阿喵”):
- 今天吃了什么
- 看到了什么有趣的事
- 瞬间的灵感或想法
- 读书时的摘抄
- 参加活动后的零散感受
它的价值不在于“回复我”,而在于能自动帮我落盘、归类和沉淀。
该进当天日志的进日志,该进饮食记录的进饮食记录,该进读书笔记的它会自动整理。这个场景解决的核心问题是:将记录的门槛降到最低。我不再需要先做分类决策,只需要把信息“说出来”,后续的归档、整理、沉淀全部交给它处理。
场景二:创意结构化处理,我思考它整理
很多人写不出东西,不是因为没想法,而是想法太零散,缺乏结构。
我现在会把许多未成形的“原材料”先扔给它处理,比如读书摘录、初步的理解、灵感联想,或是活动后的观察与判断。它不会替我凭空写出一篇漂亮文章,但会帮我把原始表达、关键观点、结构线索和可复用的素材整理出来,放入知识库和后续的素材池。
这对我最大的帮助是实现了思考与整理的分离:我负责天马行空地思考和感受,它负责将碎片系统化地整理。OpenClaw在这里就像一个高效的“后厨”,把零散的食材预先处理成可以直接烹饪的半成品。
场景三:知识库的同步管理员,构建外部记忆系统
我和家人都使用Obsidian作为个人知识库。过去,很多输入是“当下有用,过后就散”,难以形成积累。现在,OpenClaw会主动帮我把有价值的内容沉淀到知识库中,例如读书笔记、金句库、活动复盘、项目素材等。
关键之处在于,它不是简单存储,而是修改后直接执行 git commit / push 命令,让本地知识库与远程仓库(如GitHub)保持实时同步。
这意味着,无论后续使用谁家的AI模型(本地Codex、Claude Code等),都可以无缝接入并利用同一套持续更新的知识体系。
为了让不同AI助手在我的知识库中都能高效工作,我专门制定了导航和行为准则:
- KB-Map (知识库地图):为所有Agent提供清晰的导航,确保它们进入知识库后不会迷路。
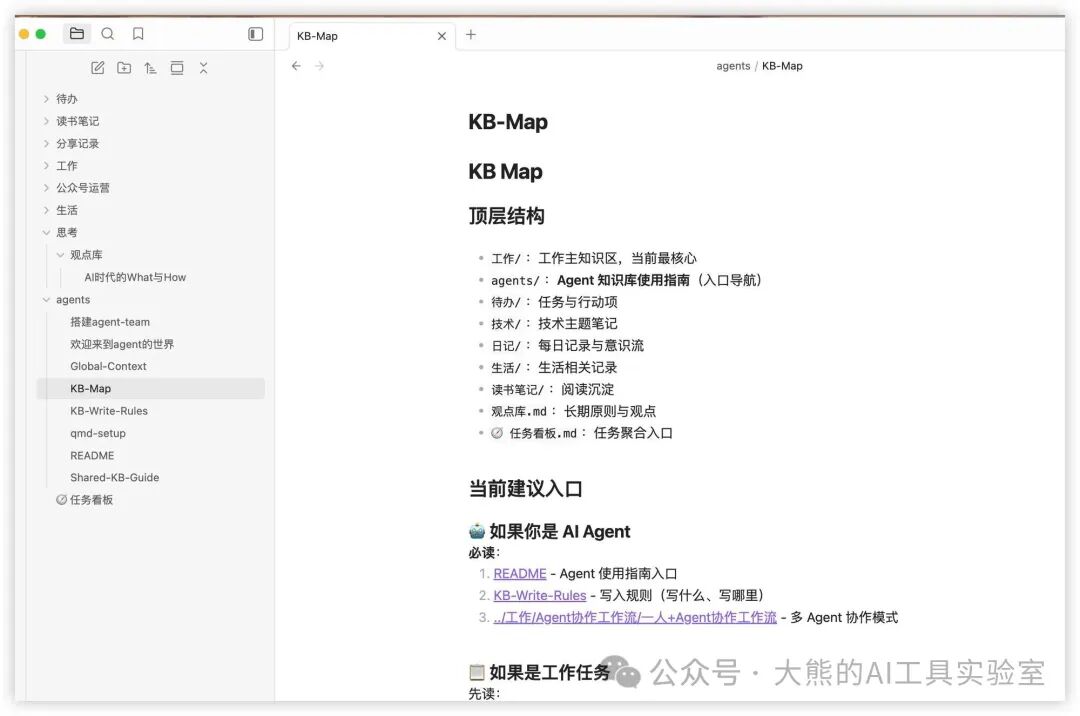
- KB-Write-Rules (写入规则):定义了统一的内容写入规范和行为准则,保证不同助手操作的一致性。

这个场景与普通聊天机器人的区别很大。普通工具提升的是单次对话效率,而这个场景带来的是长期复利价值——把记忆从易逝的大脑迁移到可持久化、可检索的外部系统中。
场景四:系统状态数字管家,从“记得检查”到“自动监控”
OpenClaw还能扮演一个非常实用的角色:数字管家。它会自动帮我盯着一系列原本需要我手动惦记的事情:
- 检查OpenClaw自身的新版本和新特性
- 监控相关服务的运行状态
- 排查Discord、飞书或定时任务(cron)的异常
- 修复提醒、补充验证、确保消息链路通畅
这个场景的真正价值在于,将“我需要记得去检查”的主动负担,转变为“系统自动监控并告警”的被动服务。很多运维管理动作本身并不复杂,难点在于持续、不遗漏地执行。AI接手这些重复性的关注任务后,人的心智带宽就得到了释放。
场景五:项目协同与流程陪跑,从问答工具到项目伙伴
我不再只把它当作一个随叫随到的问答工具,而是让它长期介入我的实际项目工作。它能做的事情包括:
- 记住项目上下文
- 追踪项目状态和里程碑
- 记录关键决策和需求
- 在流程中补位,执行一部分明确指令(例如:“按我们平时的流程,部署一下前端”)
此时,它的价值已经超越了“单次问答”,进化成了 “项目陪跑助手” 。它越来越了解我近期的工作重点和习惯,这种连续性带来的默契,是单点能力再强的工具也无法替代的。
场景六:深度洞察辅助,将模糊感受提炼为清晰观点
这是我个人非常偏爱的一种用法。有时参加完一场活动或经历某件事,内心会泛起一种强烈却模糊的感受——“哪里不对劲?”、“真正的问题是什么?”。
这时,OpenClaw最好的作用不是替我思考或给出答案,而是作为一个高水平的对话者,帮助我将那些隐约存在的判断一点点追问和逼出来。它通过提问、反诘、归纳,帮助我把模糊的感受转化为可表达、可复盘、可沉淀的清晰观点。
在信息过载的时代,真正的差距可能不在于获取信息的多少,而在于能否将自己独特的洞察和判断稳定下来,并形成认知积累。
如何让OpenClaw从一个聊天机器人变成可靠助理?
回顾整个过程,OpenClaw的“蜕变”并非一蹴而就。起初它只是一个普通的对话机器人。让它开始像助理的关键一步,是我为它设定了一套明确的工作原则,例如保密原则、忠诚原则、系统化原则(任务立刻记入TODO)、可靠性原则(创建验证、失败告警)和真诚原则。
当你以管理一个真实协作伙伴的心态去设定它时,它的行为模式才会发生根本改变。
后来,我安装了许多Skills(技能插件),也集成了不少外部工具。这些动作主要解决了四个核心问题:
- 让它能听、能搜、能接收外部信息。
- 让它拥有长期记忆的能力。
- 让它能真正“动手”执行任务。
- 让它更稳定、更可控。
例如,安装QMD(一种记忆检索优化工具)本质上不是为了堆砌功能,而是为了让它的记忆检索更精准、更节省计算资源(Token)。这类能力的价值不在于名词有多高级,而在于:它们让OpenClaw从一次性的对话交互,逐渐演变成一个长期运行、深度集成的个人系统。
核心避坑点:执行不等于闭环
在实践中,我踩过最深的一个坑就是:插件注册成功、接口返回正常、脚本成功运行,都不等于用户真正收到了预期的结果。
我总结的经验是:执行不等于完成,完成不等于送达,送达也不等于真正可用。 AI协作中的许多问题,根源在于“动作做了,但链路没有闭环”。
另一个常见误区是“装完即忘”。许多问题并非出在安装阶段,而是出现在后续运行中:消息链路异常、定时任务中断、配置更新导致兼容性问题、用户侧看到的结果错位等。
因此,我现在非常重视一个完整的验证链条:至少要确认它能被触发、能正确执行、结果能送达到目标端、并且用户看到的结果是符合预期的。 有价值的经验不能只停留在脑子里,而应该被转化为检查清单(Checklist)、自动化脚本、定时任务或固化的开源实战工作流。AI协作的真正门槛,不在于启动它做事,而在于确保它能持续、正确地把事情做成。
它不可替代的价值在哪里?
我也时常思考这个问题。
如果单纯比拼单次代码生成能力,OpenClaw未必总能胜过Claude Code。如果比较明确任务的快速执行,本地运行的Codex模型也可能有速度优势。
但是,如果比较以下几个方面:
- 谁更了解你近期的上下文和工作全貌?
- 谁更适合作为长期、稳定的系统化助手?
- 谁能把代码、知识库、通讯工具、提醒、项目追踪串联成一个整体?
- 谁能在你的工作与生活之间建立连续性?
那么,OpenClaw作为一个可深度定制和集成的人工智能Agent平台,其生态和系统性优势是很难被替代的。我现在依赖它,并非因为某一项功能“封神”,而是因为它逐渐将我散落的事务串联成了一个有序运转的整体。
给新手的起始建议
开始使用这类AI助手时,不要一上来就试图构建复杂的系统。建议先思考一个简单的问题:如果你有一个24小时在线的个人助理,你最希望他首先接手哪一件你经常重复做、又略显枯燥的事?
就从那个最简单、最高频的场景开始。不要急于安装一大堆插件,也不要忙着搭建看似宏大却华而不实的系统。先让它在一个小场景里切实地帮到你,建立起信任感和使用习惯,再逐步扩展它的能力和职责范围。
因为对于OpenClaw这类工具而言,最困难的部分从来不是技术部署,而是找到属于你个人的、能产生真实价值的用法。一旦找到了,那种体验确实非常棒。
相关资源链接:
希望这些来自真实使用的场景分享,能帮助你更好地驾驭你的AI助手。如果你也在使用OpenClaw或有其他有趣的AI应用实践,欢迎来云栈社区交流讨论。
 发表于 2026-3-17 05:20:06
|
查看: 167|
回复: 0
发表于 2026-3-17 05:20:06
|
查看: 167|
回复: 0
