凌晨五点,一个百万级用户规模的生产数据库,其关键业务链路突然遭遇“性能塌陷”。而问题的导火索,竟是一个常被忽视的序列属性。同样的INSERT语句,处理同样的9万条数据,为何在上午手动测试时耗时3分钟,到了凌晨批量执行却频繁超时报错?在系统毫秒级响应的实时交易面前,这笔“万级数据”的批处理,为何成了无法逾越的鸿沟?
本文将复盘这次SQL超时问题的完整“破案”过程。专家通过秒级采样的V$ACTIVE_SESSION_HISTORY精准定位到数据字典争用,并由此构建了一套从瞬时阻塞细节出发,覆盖应用、环境及数据库配置的全维度诊断与解决方案。
离奇的性能矛盾:百万级背景与万级数据的反差
事件发生在一个拥有百万级基础数据量的生产环境。客户反馈,其一条处理非实时批量缴费的INSERT语句,在处理大约8-9万条数据时,频繁触发SQL超时报警。
矛盾点在于:对于这个体量的数据库而言,处理几万条数据本应是常规操作。更蹊跷的是,客户在上午进行手动测试时,执行同样的数据量耗时约3分钟,虽然较慢但并未超时。然而,在凌晨的批处理任务中,该语句却持续失败。
这个现象暗示,瓶颈很可能并非来自SQL逻辑本身,而是触及了某种底层资源的争用极限。在特定时间窗口或并发条件下,这种争用被急剧放大,导致性能“崩塌”。

深度审计:排除“显性”诱因
面对如此诡异的超时,第一步是对问题SQL进行全方位的“排除法”审计。
- SQL语句本身:检查确认,该语句书写规范,使用了绑定变量,不存在隐式类型转换等常见陷阱。
- 执行计划稳定性:通过回溯AWR报告,确认该SQL的执行计划保持稳定,未发生意外改变。
- 环境基线:我们注意到,该数据库所在的服务器IO基础环境较为薄弱,平均等待延迟经常高达数百毫秒。由于涉事SQL属于低频的批量操作,其潜在的IO消耗特征在日常巡检中容易被掩盖。这成为了我们锁定的第一个突破口。
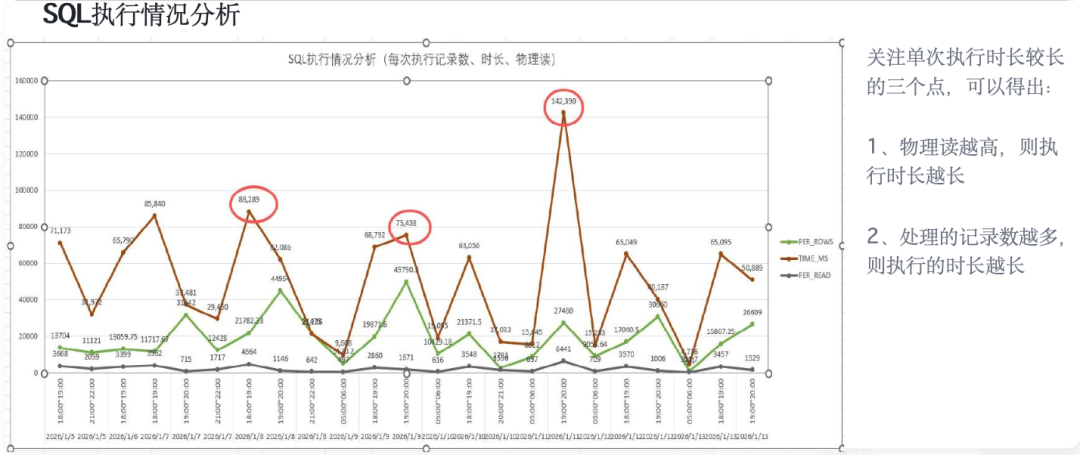
根因捕捉:凌晨5点的“实时抓捕”
常规的AWR报告采样间隔为10秒,对于捕捉这种瞬时、高并发的阻塞事件极易漏检。为了抓到“现行”,我们决定在问题高发的凌晨时段进行准点蹲守,并启用采样频率高达1秒一次的V$ACTIVE_SESSION_HISTORY视图进行实时分析。
-
根因锁定:Sequence NOCACHE 引发的 row cache lock
通过分析高频率ASH采样数据,我们发现在SQL执行期间出现了row cache lock等待事件,其等待资源指向DC_SEQUENCES(数据字典序列项)。顺藤摸瓜,检查发现该INSERT语句所使用的序列 TPI_SEND_GROUP_SEQ 被设置为 NOCACHE。
-
技术定论
在IO延迟高达数百毫秒的薄弱环境下,NOCACHE属性强制要求序列的每一次NEXTVAL调用,都必须同步更新磁盘上的数据字典(Data Dictionary)。对于9万条数据的插入,这就意味着9万次同步的物理IO写入。在高并发批量场景下,对数据字典序列条目的争用(row cache lock)被线性放大,将原本可能毫秒级的单次操作,拖慢至整体分钟级,直接导致超时。
-
额外发现:19c 并行日志写的干扰
此外,分析中还发现数据库版本为19c,且开启了多LGWR进程特性。在存在IO瓶颈的环境中,该特性内部关于SCN的排序操作可能演变为二次阻塞,进一步劣化了系统响应能力。这属于数据库/中间件/技术栈层面特定版本下的配置优化问题。

优化与预防策略
根据诊断结论,我们立即执行了优化措施:
- 调整序列缓存:将序列的
CACHE值调整为200。
ALTER SEQUENCE CSM.TPI_SEND_GROUP_SEQ CACHE 200;
此举将9万次磁盘同步写入瞬间降至约450次,极大释放了数据字典锁的争用压力。
- 调整日志写参数:将数据库恢复为单LGWR进程模式。
alter system set "_use_single_log_writer" = TRUE scope=spfile sid='*';
alter system set "_max_outstanding_log_writes"=1 scope=spfile sid='*';
(注:参数修改需重启实例生效)
优化实施后,困扰多日的批量超时问题被彻底根治。
复盘与核心预防点:技术手段可以解决当前故障,但长治久安必须依赖流程化管控。在开发阶段引入自动化的SQL审核机制,严格检查并禁止为高频使用的序列设置NOCACHE,可以从源头杜绝此类问题。这正是构建稳健运维/DevOps/SRE体系的关键一环。
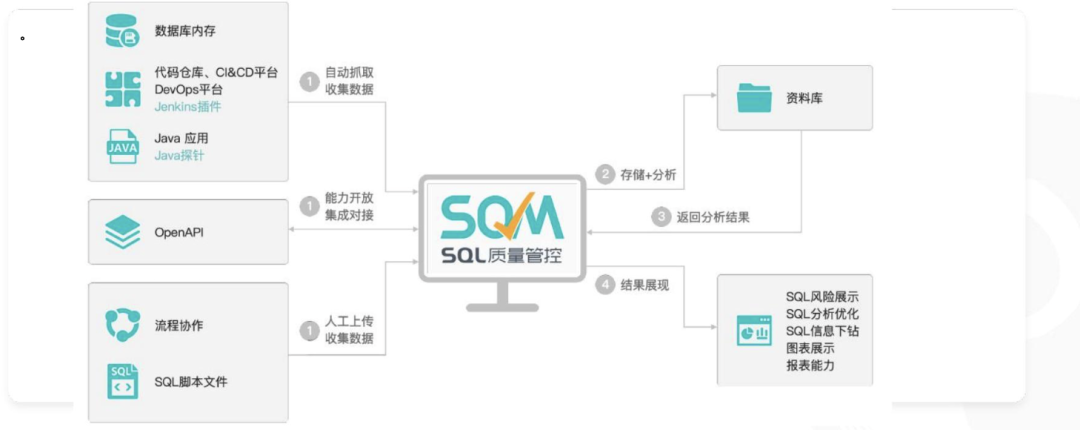
深度解析:通用SQL超时问题的全链路诊治方案
什么是SQL超时?
SQL超时,本质是SQL执行时间突破了业务应用设定的最大等待阈值。其危害不仅是单次操作失败,更在于长时间运行的SQL可能长期持有行锁、表锁或字典锁,引发连锁阻塞,导致数据库性能“雪崩”。
常见原因的多维深度剖析

- SQL语句本身:最普遍的瓶颈来源。包括缺失关键索引、执行计划偏移(如本应走索引却全表扫描)。此外,
SELECT *、无LIMIT的大结果集查询等不良习惯,会在数据增长后导致资源消耗指数级上升。
- 数据库设计与结构:容易成为后期优化死角。例如,表关联字段的隐式类型转换导致索引失效;历史数据从未归档,导致表体积巨大,产生大量非必要的物理读。
- 配置与资源:系统的“天花板”。包括连接池配置不当、数据库内核参数未针对新版本(如19c)或业务特点调优。在高并发下,任何微小的锁争用在薄弱的基础设施(如慢IO)上都会被急剧放大,正如本次案例所示。
- 应用层与外部环境:问题有时在数据库之外。例如,在数据库事务中串行调用缓慢的外部接口,或应用程序未及时提交事务,导致锁持有时间过长。
系统性解决方案:全链路深度治理矩阵
解决SQL超时绝非单一维度的修补,需要一套覆盖代码、架构、系统、应用的组合拳。
1. SQL与索引:精准的“手术级”干预
- 瓶颈定位:通过执行计划分析,判断是否存在索引缺失或路径偏差。
- 精细治理:补建缺失索引,同时清理冗余索引以减轻DML负担。
- 常态化审计:利用慢查询日志建立定期巡检机制,持续监控Top SQL性能。
2. 库表结构:从底层释放架构压力
- 架构解压:在数据量或并发量极大时,考虑分库分表、读写分离,分散单点压力。
- 冷热分离:实施数据生命周期管理,将历史冷数据归档至低成本存储,确保热数据访问效率。
- 事前拦截:推行SQL审核,在表结构设计阶段就规避隐患。
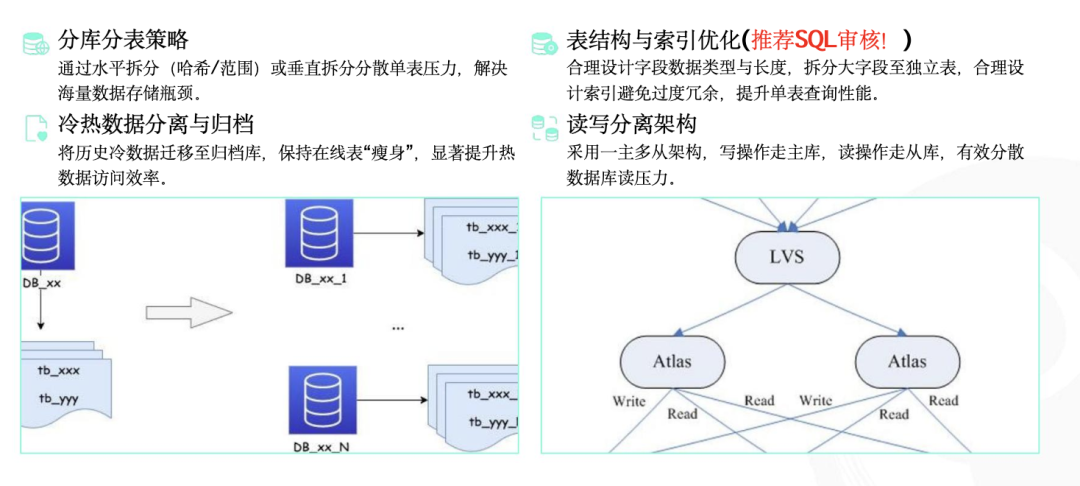
3. 配置与资源:优化系统运行底座
- 参数调优:针对性调整数据库内核、连接池参数,适应高并发场景。
- 锁争用治理:实时监控并解决行锁、表锁冲突。
- 理性扩容:坚持“先优化,后扩容”,仅在软件优化已达极限且资源确已饱和时进行硬件升级。
4. 应用与环境:打破性能闭环
- 缓存减负:对热点查询数据引入Redis等缓存,避免高频访问直接冲击数据库。
- 事务控制:遵守“短事务”原则,避免在事务中执行慢速外部调用。
- 防御体系:构建应用层的限流、熔断、降级机制,保障核心链路在压力下的稳定性。
构建长治久安的高性能体系
真正的性能治理应从“被动救火”转向“主动防御”。
建立全方位监控体系
监控应覆盖数据库性能(QPS/TPS、慢查询、锁等待)、服务器资源(CPU、IO、内存)、业务指标(P99响应时间、订单积压)。利用Prometheus+Grafana等工具实现可视化与智能告警,做到“早发现、早干预”。
规范化开发运维流程
- SQL审核(核心守门员):制定强制性开发规范,并通过自动化工具在CI/CD流程中拦截高危SQL,如禁止高频序列
NOCACHE、强制关联字段类型一致等。
- 压力测试(水位探测):上线前进行高仿真压力测试,真实评估系统容量与瓶颈,防患于未然。

总结而言,数据库性能优化是一场与业务增长相伴的持久战。它要求我们建立“全链路、系统化”的视角,从一次具体的问题排查(如本次的序列缓存案)中提炼出方法论,并固化为流程与规范。通过“多维度分析、组合拳解决、重监控预防、持续化优化”的闭环,才能确保系统始终运行在稳健的“高速路”上。技术社区如云栈社区正是分享和沉淀此类实战经验,推动共同进步的宝贵平台。 |  发表于 2026-3-18 08:43:28
|
查看: 165|
回复: 0
发表于 2026-3-18 08:43:28
|
查看: 165|
回复: 0
