LangGraph 介绍
LangGraph 是LangChain团队推出的开源框架,专为构建有状态、长时间运行的AI工作流而生。它不像别的工具那样封装太多细节,而是给你底层控制权,像搭积木一样组装AI系统。
LangGraph 核心思想很简单:用“图”来建模AI行为,节点是动作,边是跳转逻辑,状态是记忆。
LangGraph is a low-level orchestration framework for building, managing, and deploying long-running, stateful agents.
图结构三要素
- 节点(Nodes):每个节点是一个独立任务。比如调用大模型、查数据库、执行工具函数。
- 边(Edges):每一条边是Python函数,根据当前状态决定下一步去哪,支持条件判断和循环。
- 状态(State):全局共享的数据结构,记录所有关键信息,相当于AI的“短期记忆”。
有了这图结构三要素,就能画出一条条清晰的执行路径,不怕逻辑混乱,也不怕断电重启丢数据。
from langgraph.graph import StateGraph, END
# 示例:定义一个简单图
graph = StateGraph(dict)
def node_a(state):
return {"value": "from A"}
def node_b(state):
return {"value": "from B"}
graph.add_node("A", node_a)
graph.add_node("B", node_b)
graph.set_entry_point("A")
graph.add_edge("A", "B")
graph.add_edge("B", END)
app = graph.compile()
上面这段代码就是一个最简单的流程图:A → B → 结束。这是一个简单的顺序执行流程:
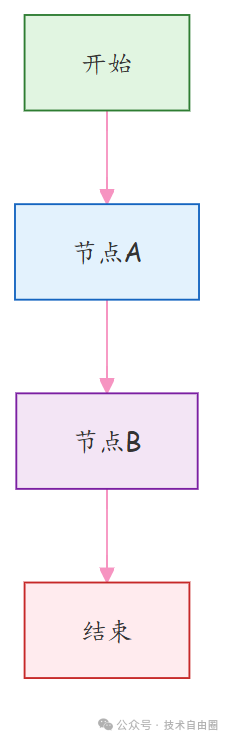
图结构说明:
- 开始节点 → 由
graph.set_entry_point("A")设定入口
- 节点A → 执行
node_a(state)函数,返回 {"value": "from A"}
- 节点B → 执行
node_b(state)函数,返回 {"value": "from B"}
- 结束节点 → 由
graph.add_edge("B", END)设定终点
LangGraph 的核心优势
LangGraph 本质是一个“带记忆的、AI 任务图、执行器”。更技术一点说:它是一个有状态、可持久化、基于图的工作流引擎,灵感来自两种老但牛的技术:
- 数据流编程(Dataflow Programming):数据推着计算走
- Actor 模型:每个节点像个独立小演员,收到消息才行动
这就让它特别适合做复杂AI流程,比如自动规划任务、多Agent协作、出错自动重试、用户中途修改需求也能接得上。
LangGraph 的设计哲学很简单粗暴:把AI应用当成一个永远在线的“活系统”,而不是一次性的函数调用。 你可以把它想象成一个会记住上下文、能持续反应、还会自己做决定的智能机器人,而不是一个“问一句答一句”的问答机。
LangChain 和 LangGraph 的区别?
我们来对比一下:
- LangChain:像是流水线工人。原料(输入)进来 → 经过几道工序(处理)→ 成品(输出)出去 → 完事,关机器。下次再来?从头开始。
- LangGraph:像是一个值班经理,24小时在岗。他记得昨天客户说了啥,今天问题进展到哪了,还能根据情况叫同事帮忙、重试任务、甚至主动发消息提醒你。
LangGraph核心是:状态一直在线,流程可以反复跳转。
LangGraph 的关键组件
问题根源:多个AI任务,各模块各干各的,逻辑乱、状态丢、没法 debug。
解决思路:以“状态图”为核心,靠节点、边、状态三件套,构建可控可溯的工作流。
三大支柱:
- 节点(Nodes):执行单元,比如调大模型、查库;
- 边(Edges):控制流程走向,可以固定跳转,也能条件判断;
- 状态(State):共享内存,全程保存数据,上下文不断。
- 支持循环:AI生成内容后问用户“满意吗?” 不满意就回退修改,直到通过。
- 支持人工干预:在流程中插入“等待确认”节点,处理完再继续。
- 集成RAG,先检索再回答,不说胡话;
- 用LangSmith监控全过程,像DevTools一样看执行轨迹。

LangGraph 五大能力
- 状态保持、持久执行(Durable Execution)
跑一半断电了怎么办?重头再来?那用户不得疯了?LangGraph把每一步状态存下来,哪怕服务挂了,重启也能接着干,就像游戏存档一样靠谱。
- 人机协同、人机协作(Human-in-the-loop)
AI再聪明也有拿不准的时候。这时候可以让人类插一脚,看看状态、改改参数、点个确认,然后再继续。这种设计特别适合审批流、客服质检这类高风险场景。
- 持久化存储、全面记忆管理(Comprehensive Memory)
有的框架只记最近几句话,LangGraph不一样,它可以同时管:
- 短期记忆:本次会话的状态
- 长期记忆:跨会话的历史数据(结合向量库或数据库)
这就让AI不仅能“接话”,还能“认人”,提供个性化体验。
- 调试能力(Debugging)
复杂的AI流程就像迷宫,光看日志根本找不到问题在哪。LangGraph配合LangSmith,能生成可视化轨迹图,每一步走到哪、状态变成啥样,清清楚楚。
- 工具集成 & 多智能体支持
想让AI查天气、订机票、写报告?没问题,接API就行。而且它天生支持多个AI协同工作,比如一个负责分析,一个负责决策,一个负责汇报。
使用 LangGraph 构建基础多智能体聊天机器人
核心痛点:想搭聊天机器人,但不会把大模型塞进一个能扩展的流程里,代码乱、状态散,没法往复杂应用走。
核心方案:用LangGraph搭个状态驱动的流水线,把大模型调用变成简单节点,实现“输入→处理→输出”的清晰控制流。
环境准备
做AI项目,第一步就是选个靠谱的大模型。别一上来就烧钱,咱们先试试免费的路子。百度千帆和硅基流动这两个平台,都有不错的国产模型可以白嫖。
Deepseek 调用方式
Deepseek 支持多款开源大模型,且提供兼容 OpenAI API 格式的调用方式,迁移成本低,直接复用ChatOpenAI即可快速接入:
from langchain_openai import ChatOpenAI
import os
# Deepseek 调用(兼容 OpenAI 接口格式)
llm = ChatOpenAI(
model="deepseek-chat", # 可选模型:deepseek-chat(通用)、deepseek-coder-v2(编程)等
streaming=True, # 支持流式输出,按需开启
api_key=os.getenv('DEEPSEEK_API_KEY', ''), # 从环境变量读取密钥(推荐)
base_url="https://api.deepseek.com/v1", # Deepseek 官方 API 基础地址
temperature=0.7, # 随机性调节:0~1,值越低输出越确定
max_tokens=4096 # 单次生成最大令牌数(按需调整,不同模型上限不同)
)
前置准备:注册 Deepseek 账号,获取DEEPSEEK_API_KEY,建议将密钥存入环境变量。
痛点:API 密钥写死在代码里?不安全!依赖安装慢还冲突?新手直接卡住。
解决方案:用uv快速装包,.env文件管密钥,环境干净又安全,一次配好反复用。
# 安装 LangGraph 和周边依赖
uv pip install -U langgraph langchain python-dotenv typing-extensions
# .env 文件存密钥
DEEPSEEK_API_KEY=your_deepseek_api_key_here
自动加载配置,密钥不进代码,不怕泄露。
实现基础聊天机器人
痛点:直接调大模型?没流程、没记忆,对话像复读机,体验差。
解决方案:用 LangGraph 维护消息列表作为状态,串起“用户输入 → 模型回复”的复杂路线,让对话有上下文、能连贯。
LangGraph的核心,就是把业务逻辑画成一张“流程图”。每个节点干一件事,边来决定执行顺序。就像工厂流水线,零件从这头进,那头出成品。
from typing import Annotated
from langchain.chat_models import init_chat_model
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
import os
from dotenv import load_dotenv
# 加载.env文件中的环境变量
load_dotenv()
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
llm = init_chat_model(
"deepseek-chat", # 使用DeepSeek模型
api_key=os.environ.get("DEEPSEEK_API_KEY")
)
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
except KeyboardInterrupt:
print("\nGoodbye!")
break
一句话概括:定义状态 → 创建图 → 添加节点 → 编译运行 → 流式输出。
核心的代码如下:
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()
基础聊天机器人 代码解析
痛点:LangGraph 组件太多,看不懂谁干啥,学得迷糊。
解决方案:盯死两个核心:状态累积和流程编排,其他都是配角。
-
引入依赖:导包是第一步,为状态、模型、流程打基础。
-
加载环境变量:从.env读密钥,绝不硬编码。
-
定义状态结构:
class State(TypedDict):
messages: Annotated[list, add_messages]
所有消息存在一个可累加的 list 里,新消息自动追加,上下文不断。这行代码是LangGraph 中定义「可自动累加对话状态」的核心语法。专门解决「对话历史持久化」问题。它让messages字段能自动追加新消息(用户提问、AI 回复),而不是被覆盖。在 LangGraph 流程中,State是流转的数据载体,而messages是存储「对话历史」的关键字段。这行代码的本质是:用 TypedDict 约束状态结构,用 Annotated + add_messages 给 messages 字段绑定「自动追加」规则。最终实现「对话历史不丢失、上下文可复用」—— 这正是 LangGraph 能支持多轮对话、复杂流程的基础,也就是提到的「不怕断电重启丢数据」(状态可持久化,历史都在messages中)。
-
创建图构建器:graph_builder = StateGraph(State),初始化一个共享状态的流程图,所有节点都能看到最新消息。这行代码是LangGraph 流程图的 “地基构建”: 创建一个「绑定了状态结构」的流程图构建器。核心作用是:明确流程图中流转的「数据格式(State)」,让后续节点、边的定义都遵循这个格式,避免数据混乱。
-
初始化大模型:接入 DeepSeek 当回答引擎。
-
编写节点逻辑:输入当前消息,让模型生成回复,返回新消息对象。
-
搭建流程图:注册节点,连上起点,形成一条直线流程:问了就答。
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()
这些代码是LangGraph 构建对话流程图的核心逻辑。核心作用是:定义一个「对话节点」,让流程从 “开始” 直接进入该节点,最终形成一个「 任务流程」(启动 → 对话 → 结束)。
-
流式输出响应:回复边生成边打印,像真人打字,体验丝滑。
-
主循环交互:命令行入口,支持持续对话,按 q 或 Ctrl+C 优雅退出。
运行聊天机器人
痛点:跑完不知道成没成功?一脸懵。
解决方案:运行脚本,输入问题,看到流式回复——就成了!
uv run 1-build-basic-chatbot.py
示例输出:
User: who are you?
Assistant: I’m DeepSeek Chat, your AI assistant created by DeepSeek!
大模型已通,基本对话能力到手。
小结
痛点:教程太碎,学完还是不会搭真正的 AI 应用。
解决方案:记住三个词:状态、节点、边—— 这就是 LangGraph 的骨架。
这个机器人虽小,五脏俱全:
- 状态:存上下文(比如聊天记录)
- 节点:干活的(比如调模型)
- 边:定流程(下一步去哪)
往后要加记忆、分支、工具调用?直接往上堆就行。
使用 LangGraph 完成工具调用
我们之前用 LangGraph 做了个聊天机器人,但它只能“空想”,没法查天气、搜资料、算数学。现在要让它能思考,也能动手——比如你问“明天天气咋样?”,它会主动去“查一下”再告诉你。
想让大模型查新鲜事、找实时数据?得给它接个“外挂大脑”。这外挂,就是工具(Tools)。接上了,大模型就能上网搜、调接口、拿最新信息,不再靠死记硬背过日子。这就叫工具调用(Tool Calling)。
完整可运行代码
# 1. 基础依赖导入
import asyncio
from typing import Literal, List
from langchain_core.tools import tool
from langchain_core.messages import SystemMessage, HumanMessage, ToolMessage
from langchain_core.utils.function_calling import convert_to_openai_function
from langgraph.graph import StateGraph, END, MessagesState # MessagesState是LangGraph内置的消息状态类
from langgraph.prebuilt import ToolNode
# 导入LLM(以Deepseek为例,可替换为百度千帆/硅基流动等,用法一致)
from langchain_openai import ChatOpenAI
import os
# 2. 初始化LLM(需提前配置环境变量 DEEPSEEK_API_KEY)
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY", ""),
base_url="https://api.deepseek.com/v1",
streaming=True, # 支持流式输出
temperature=0.3 # 降低随机性,让工具调用更稳定
)
# 3. 定义工具:用@tool装饰器将普通函数转为AI可识别的工具
@tool # 核心装饰器:自动生成工具描述,供LLM判断是否调用
def get_weather(query: str) -> List[str]:
"""
用于获取指定地区、指定时间的天气信息(工具描述很重要!LLM靠这个判断是否调用)
:param query: 查询条件,格式示例:"北京 今明两天天气"、"上海 明天是否下雨"
:return: 天气信息列表,包含每天的天气描述
"""
# 这里是模拟工具返回(真实场景替换为调用天气API,如高德/百度天气接口)
if "今明两天" in query or "今天" in query or "明天" in query:
return ["今天天气晴朗,温度20~28℃,微风", "明天天气多云转晴,温度22~30℃,南风3级"]
elif "后天" in query:
return ["后天天气小雨,温度18~25℃,东北风2级"]
else:
return [f"已查询到:{query} 的天气为晴朗,温度20~28℃(模拟数据)"]
# 工具列表:可添加多个工具(如搜索、计算等)
tools = [get_weather]
# 4. 绑定工具到LLM:告诉模型"你现在拥有这些工具"
# bind_tools:LangChain的工具绑定方法,让LLM能识别工具并生成工具调用指令
llm_with_tools = llm.bind_tools(tools)
# convert_to_openai_function:将工具转为OpenAI格式的函数描述(兼容多数LLM)
functions = [convert_to_openai_function(tool) for tool in tools]
# 5. 定义对话节点(chat_bot):让模型判断"要不要调工具"
async def chat_bot(state: MessagesState):
"""
核心思考节点:接收对话状态,让LLM判断是否调用工具,或直接生成回复
:param state: 流程状态,包含messages(对话历史)
:return: 更新后的状态(添加LLM的思考结果)
"""
# 从状态中获取完整对话历史
messages = state["messages"]
# 调用绑定工具的LLM,关键参数说明:
# ainvoke:异步调用(适配流式和异步流程)
# functions:工具的OpenAI格式描述,供LLM参考
# function_call="auto":让LLM自主决定:直接回复 或 调用工具
response = await llm_with_tools.ainvoke(
messages,
functions=functions,
function_call="auto"
)
# 返回更新后的状态:将LLM的响应(思考结果)添加到对话历史
return {"messages": [response]}
# 6. 定义路由节点(tool_router):判断"下一步去哪"(分流逻辑)
def tool_router(state: MessagesState) -> Literal["tools", "end"]:
"""
流程路由(类似交通交警):根据LLM的输出,决定下一个节点
:param state: 流程状态
:return: 下一个节点名称("tools" 或 END)
"""
# 获取最新一条消息(LLM的思考结果)
messages = state["messages"]
last_message = messages[-1]
# 关键判断:如果最新消息包含tool_calls(工具调用指令),则跳转到工具节点
if last_message.tool_calls:
return "tools" # 去工具节点执行工具调用
return END # 没有工具调用,直接结束流程
# 7. 创建工具节点(ToolNode):执行工具调用的"操作员"
# ToolNode是LangGraph预构建节点,功能:解析tool_calls → 调用对应工具 → 生成ToolMessage
tool_node = ToolNode(tools)
# 8. 编排完整流程(状态图):将节点和路由串成流水线
# StateGraph(MessagesState):创建状态图,指定状态格式为MessagesState(内置的消息列表结构)
workflow = StateGraph(MessagesState)
# 8.1 添加节点
workflow.add_node("chat_bot", chat_bot) # 思考节点:判断是否调工具
workflow.add_node("tools", tool_node) # 工具节点:执行工具调用
# 8.2 设置流程入口:流程从chat_bot节点开始(用户提问后先让模型思考)
workflow.set_entry_point("chat_bot")
# 8.3 定义节点流转规则
# 工具节点执行完成后,返回chat_bot节点:让模型基于工具结果生成最终回复
workflow.add_edge("tools", "chat_bot")
# 条件流转:从chat_bot节点出发,由tool_router决定下一步
workflow.add_conditional_edges(
source="chat_bot", # 起点:chat_bot节点
condition=tool_router, # 条件判断函数:tool_router
# 无需手动映射目标节点(tool_router直接返回节点名)
)
# 8.4 编译流程:生成可执行的流程图应用
app_graph = workflow.compile()
# 9. 测试:流式运行流程(实时查看每一步输出)
async def run_streaming_demo():
"""流式运行工具调用流程,模拟用户交互"""
# 初始对话状态:系统提示 + 用户提问
initial_messages = [
SystemMessage(content="你是一个智能助手,能回答问题和调用工具。"
"如果需要查询天气,请调用get_weather工具,不要瞎编数据。"),
HumanMessage(content="帮我查一下深圳今明两天的天气,谢谢~")
]
initial_state = {"messages": initial_messages}
print("=== 工具调用流程启动(流式输出)===")
print(f"User: {initial_messages[-1].content}")
print("Assistant: ", end="", flush=True)
# 异步流式迭代流程输出(stream_mode='messages':按消息粒度输出,便于调试)
async for event in app_graph.astream(initial_state, stream_mode='messages'):
# 解析事件:LangGraph的流式事件是元组,第一个元素是消息块
if isinstance(event, tuple):
chunk = event[0]
# 只打印AI的回复内容(过滤工具调用、系统消息等中间过程)
if isinstance(chunk, HumanMessage):
continue # 跳过用户消息
elif isinstance(chunk, ToolMessage):
# 工具调用结果(用户不可见,可选打印用于调试)
print(f"\n[调试] 工具返回结果:{chunk.content}", flush=True)
elif chunk.type == 'AIMessageChunk':
# 流式输出AI的最终回复(打字机效果)
print(chunk.content, end="", flush=True)
print("\n=== 流程结束 ===")
# 10. 运行测试(异步函数需用asyncio.run启动)
if __name__ == "__main__":
asyncio.run(run_streaming_demo())
接下来,开始代码核心组件详解(按执行顺序):
先搞个“假”天气工具:让AI知道它能干啥
痛点:模型不知道自己有啥技能,就像助理没说明书,啥也不会干。
方案:用@tool给函数打标签,变成 AI 能识别的“工具”。
@tool # 核心装饰器:自动生成工具描述,供LLM判断是否调用
def get_weather(query: str) -> List[str]:
# ... 工具实现 ...
# 工具列表:可添加多个工具(如搜索、计算等)
tools = [get_weather]
# 绑定工具到LLM:告诉模型"你现在拥有这些工具"
llm_with_tools = llm.bind_tools(tools)
# 创建工具节点(ToolNode):执行工具调用的"操作员"
tool_node = ToolNode(tools)
@tool:把普通函数包装成 AI 工具bind_tools:告诉模型“你现在会这些技能”ToolNode:负责真正执行工具调用,相当于给机器人配了“工具箱 + 操作员”
LLM 工具绑定(bind_tools):
llm.bind_tools(tools):给 LLM “挂载” 工具,让模型知道自己拥有这些能力,能生成符合工具调用格式的指令。convert_to_openai_function:将工具转为 OpenAI 标准的函数描述格式,兼容绝大多数支持工具调用的 LLM。
创建工具执行节点 ToolNode:
ToolNode 角色是流程的 “手脚”,负责执行工具调用的全流程(无需手动写解析逻辑)。ToolNode 内置逻辑:
- 解析 LLM 的
tool_calls指令(提取工具名、参数)
- 调用对应的工具函数
- 将工具返回结果包装为
ToolMessage
- 自动将
ToolMessage添加到对话历史,供后续节点使用
ToolNode 优势:无需关心工具调用的细节(如参数解析、异常处理),LangGraph 已封装好。
改造 chat_bot:让模型学会“要不要动手”
痛点:模型只会硬答,不会判断“这事我能不能办”,要么瞎编,要么说“我不知道”。
方案:让它输出“我要调哪个工具”,而不是直接回复。
async def chat_bot(state: MessagesState):
# 从状态中获取完整对话历史
messages = state["messages"]
# 调用绑定工具的LLM,关键参数说明:
# function_call="auto":让LLM自主决定:直接回复 或 调用工具
response = await llm_with_tools.ainvoke(
messages,
functions=functions,
function_call="auto"
)
return {"messages": [response]}
关键是function_call="auto":让模型自己决定是否调工具。它不再嘴硬,而是说:“我要调get_weather,参数是‘今明两天天气’”。
加个 add_conditional_edges 条件边,实现节点路由
痛点:模型有时直接回,有时要调工具,系统懵了:接下来该干啥?
方案:加个判断器,看消息里有没有tool_calls,有就调工具,没有就结束。
def tool_router(state: MessagesState) -> Literal["tools", "end"]:
# 获取最新一条消息(LLM的思考结果)
messages = state["messages"]
last_message = messages[-1]
# 关键判断:如果最新消息包含tool_calls(工具调用指令),则跳转到工具节点
if last_message.tool_calls:
return "tools" # 去工具节点 tool_node 执行工具调用
return END # 没有工具调用,直接结束流程
路由条件角色:流程的 “交通警察”,解决 “下一步去哪” 的问题。判断逻辑:检查 LLM 的最新输出是否包含 tool_calls(工具调用指令):
- 有 → 跳转到
tools节点执行工具调用
- 无 → 直接结束流程(返回最终回复)
流程编排(StateGraph)核心逻辑:构建 “思考→判断→执行→再思考” 的闭环:
入口 → chat_bot(思考)→ tool_router(判断)→
① 无工具调用 → 结束
② 有工具调用 → tools(执行)→ chat_bot(基于工具结果生成回复)→ 结束
回顾langgraph 关键 API:
add_node:添加节点(思考节点、工具节点)set_entry_point:设置流程入口(从chat_bot开始)add_edge:固定流转(工具执行后返回chat_bot)add_conditional_edges:条件流转(由tool_router决定下一步)
工具到底怎么被调的?拆开看流程
痛点:中间环节太多,容易断链,结果丢了都不知道。
方案:ToolNode一把梭,解析 → 执行 → 返回结果,全自动接回对话。
当模型输出:
tool_calls=[{'name': 'get_weather', 'args': {'query': '今明两天天气'}}]
→ 路由发现tool_calls → 跳转到tool_node
→ 自动调本地方法get_weather()
→ 结果作为ToolMessage写入历史
→ 再回到chat_bot,模型结合真实数据生成最终回复。
串成完整工作流:大脑 + 手脚 合体
痛点:逻辑散,不成环,难维护。
方案:用状态图把“思考→判断→执行→再思考”串成自动流水线。
workflow = StateGraph(MessagesState)
workflow.add_node("chat_bot", chat_bot)
workflow.set_entry_point("chat_bot")
workflow.add_node("tools", tool_node)
workflow.add_edge("tools", "chat_bot")
workflow.add_conditional_edges(
"chat_bot",
tool_router,
)
app_graph = workflow.compile()
两条路径自动切换:
- 直接回答 → 结束
- 需查数据 → 调工具 → 回模型 → 出答案
相当于给AI装上了“手脚”,从嘴炮王变实干家。
测试运行:看看它是怎么一步步干活的
痛点:看不到过程,出问题没法 debug。
方案:开流式输出,实时监听每一步。
async for event in app_graph.astream(initial_state, stream_mode='messages'):
if isinstance(event, tuple):
chunk = event[0]
if chunk.type == 'AIMessageChunk':
print('event里监听到的流式输出------>', chunk.content)
stream_mode='messages':逐字打印输出,调试神器。
自验证:看看结果长啥样
痛点:用户以为模型“天生就知道”,根本看不出用了工具。
方案:通过日志看清全过程:指令 → 执行 → 回复。
用户输入:帮我查一下今明两天的天气
模型第一步不是回答,而是发指令:
last_message.tool_calls ------> [{'name': 'get_weather', 'args': {'query': '今明两天天气'}, ...}]
→ 触发工具 → 获取真实数据 → 模型整合输出:
“好的,我来帮您查询一下。经过查询,今天天气晴朗,温度20度,明天天气多云,温度25度……”
用户无感,但背后已完成一次“AI + 工具”的协同作业。
核心流程图
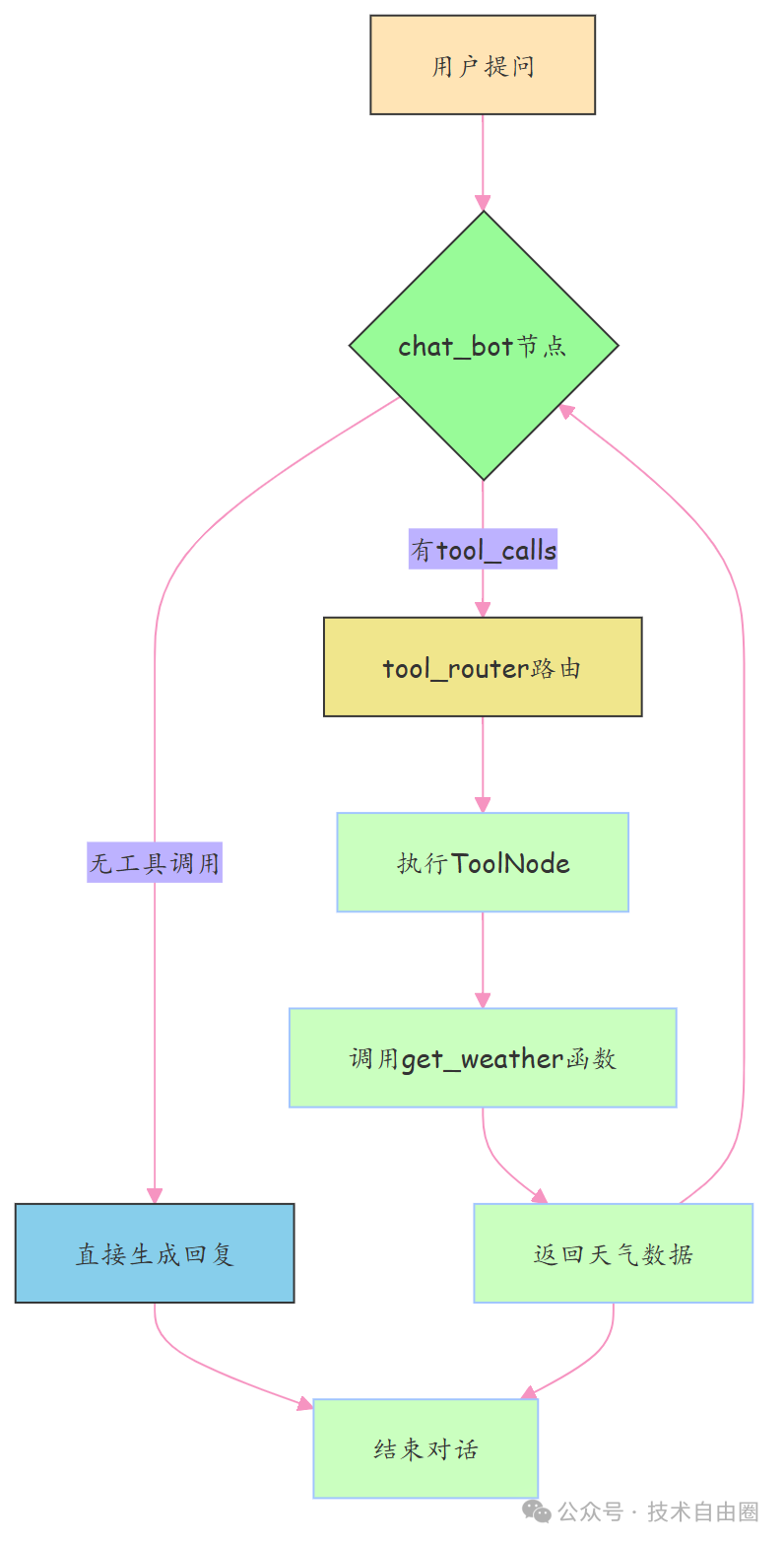 两条路自动走:能干就干,不能就调工具,全程无人干预。
两条路自动走:能干就干,不能就调工具,全程无人干预。
总结:工具调用核心五步
| 步骤 |
组件 |
干啥用 |
| 1. 定义工具 |
@tool |
把函数变成 AI 能调的“能力” |
| 2. 绑定工具 |
bind_tools() |
告诉模型:“你现在有这技能” |
| 3. 判断是否调 |
tool_router |
看有没有tool_calls,决定走哪条路 |
| 4. 执行工具 |
ToolNode |
自动跑函数,拿结果回来 |
| 5. 整合回复 |
回到chat_bot |
模型基于真实数据生成人话 |
从此,机器人从“只会说”升级为“又能说又能做”。可接入数据库、搜索、计算器……想连啥连啥。
为 LangGraph 应用添加记忆功能
在写聊天机器人时,没有记忆就像金鱼,游两下就忘了自己是谁。咱们上一节给机器人装了工具,能查资料、能干活,但它还是记不住聊过啥。这不行啊,用户说一遍名字,下次还得重新介绍,体验直接掉地上。所以这一节,咱给它加上“脑子”,让它记住对话历史,真正实现多轮连贯交流。
添加记忆功能
加记忆功能,不需要额外装包,LangGraph 自带这个本事。它用的是langgraph.checkpoint.memory模块里的MemorySaver,说白了就是个内存快照工具。每次对话一结束,它就把当前状态拍个照存起来,下次接着用。开发阶段用它正合适,简单又省事,就跟手机临时存图一样。
解决方案:用 LangGraph 的MemorySaver当临时笔记本,自动存对话记录。靠thread_id区分不同用户,互不串台。LangGraph 自带MemorySaver它就像一个会自动记笔记的助理:每次聊完记一笔,下次见你先翻本子再开口。
怎么加记忆?三步搞定:
- 定义状态:消息列表支持累积
class State(TypedDict):
messages: Annotated[list, add_messages]
add_messages是关键:新消息不是覆盖,而是追加到历史里,上下文不断档。
- 创建 MemorySaver,当内存记事本
memory = MemorySaver()
- 编译图时传 checkpointer,开启自动保存
graph = graph_builder.compile(checkpointer=memory)
每次对话结束,系统自动拍个“状态快照”存进去,下次按thread_id找回来继续聊。
多人聊天不串台?靠 thread_id
每个用户分配唯一thread_id,相当于独立聊天室:
config = {"configurable": {"thread_id": "1"}}
- 用户A用
"1",B用 "2" → 各聊各的,不干扰
- 回到
"1" → 记忆还在,接着上次聊
注意:开发阶段用MemorySaver(内存存储),重启就丢。生产建议换SqliteSaver或数据库持久化。
使用记忆增强聊天机器人
新建一个文件叫3-add-memory.py,开始搞有记忆的机器人。
"""LangGraph 教程: 添加记忆功能的聊天机器人
本示例展示了如何使用 LangGraph 的检查点功能为聊天机器人添加记忆功能,使其能够记住对话历史并在多轮对话中保持上下文。
"""
from typing import Annotated
from langchain.chat_models import init_chat_model
from langchain_tavily import TavilySearch
from langchain_core.messages import BaseMessage
from typing_extensions import TypedDict
# 导入 MemorySaver 用于实现记忆功能
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
import os
from dotenv import load_dotenv
# 加载.env文件中的环境变量
load_dotenv()
# 定义状态类型,使用 add_messages 注解来自动合并消息列表
class State(TypedDict):
messages: Annotated[list, add_messages] # 消息列表将使用 add_messages reducer 自动合并
# 初始化 DeepSeek 聊天模型
llm = init_chat_model(
"deepseek-chat", # 使用DeepSeek模型
api_key=os.environ.get("DEEPSEEK_API_KEY") # 从环境变量中获取API密钥
)
# 创建状态图构建器
graph_builder = StateGraph(State)
# 初始化Tavily搜索工具
print("\n初始化Tavily搜索工具...")
tool = TavilySearch(max_results=2) # 设置最多返回2个搜索结果
tools = [tool]
# 将工具绑定到LLM
llm_with_tools = llm.bind_tools(tools)
# 定义聊天机器人节点函数
def chatbot(state: State):
"""LLM节点函数,处理用户输入并生成响应"""
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 添加聊天机器人节点
graph_builder.add_node("chatbot", chatbot)
# 添加工具节点
tool_node = ToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
# 添加条件边
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
# 工具调用完成后,返回到聊天机器人节点
graph_builder.add_edge("tools", "chatbot")
graph_builder.set_entry_point("chatbot")
print("\n构建图并添加记忆功能...")
# 创建内存保存器
print("\n创建 MemorySaver 实例作为检查点保存器...")
memory = MemorySaver() # 在内存中保存状态,适用于开发和测试
# 使用内存保存器编译图
print("使用检查点保存器编译图...")
graph = graph_builder.compile(checkpointer=memory) # 将内存保存器传递给图
# 打印图结构
print("\n图结构如下:")
print(graph.get_graph().draw_mermaid())
# 定义对话线程ID
print("\n设置对话线程 ID = '1'...")
config = {"configurable": {"thread_id": "1"}} # 使用线程ID来标识和区分不同的对话
# 示例 1: 第一次对话
print("\n示例 1: 第一次对话 - 用户介绍自己")
user_input = "Hi there! My name is Will."
print(f"\n用户输入: '{user_input}'")
# 注意: config 是 stream() 函数的第二个参数!
print("使用线程 ID '1' 调用图...")
events = graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config, # 传递包含 thread_id 的配置
stream_mode="values",
)
print("\n助理回应:")
for event in events:
event["messages"][-1].pretty_print() # 打印助理的回应
# 示例 2: 测试记忆功能
print("\n\n示例 2: 第二次对话 - 测试记忆功能")
user_input = "Remember my name?"
print(f"\n用户输入: '{user_input}'")
# 使用相同的线程ID再次调用图
print("使用相同的线程 ID '1' 再次调用图...")
events = graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config, # 使用相同的配置,图将加载之前保存的状态
stream_mode="values",
)
print("\n助理回应 (应该记得用户名字):")
for event in events:
event["messages"][-1].pretty_print()
# 示例 3: 新对话线程
print("\n\n示例 3: 新对话线程 - 测试线程隔离")
print("创建新的线程 ID = '2'...")
# 使用不同的线程ID
print("使用新的线程 ID '2' 调用图...")
events = graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
{"configurable": {"thread_id": "2"}}, # 使用新的线程ID
stream_mode="values",
)
print("\n助理回应 (不应该记得用户名字):")
for event in events:
event["messages"][-1].pretty_print()
# 示例 4: 返回第一个线程
print("\n\n示例 4: 返回第一个线程 - 验证记忆持久性")
print(f"\n用户输入: '{user_input}'")
# 再次使用第一个线程ID
print("再次使用线程 ID '1' 调用图...")
events = graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config, # 使用原始线程ID
stream_mode="values",
)
print("\n助理回应 (应该仍然记得用户名字):")
for event in events:
event["messages"][-1].pretty_print()
代码解析
关键改动点
from langgraph.checkpoint.memory import MemorySaver
这是新加的核心依赖,相当于给机器人配了个“小本本”。以前每次对话都像第一次见面,现在它会翻本本看看你们之前聊了啥。
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory)
这两行是关键操作:第一行,创建一个内存记录员;第二行,把这个记录员塞进图里,让它自动拍照存档每一步状态。只要你不关服务,它就能一直记住。生产环境别用这个,得换成数据库版的SqliteSaver或PostgresSaver,不然重启就全丢了。
config = {"configurable": {"thread_id": "1"}}
这个thread_id就像是对话身份证。同一个 ID,读的是同一份记忆;换个 ID,就是全新对话。多用户场景下,靠它实现隔离,不会张冠李戴。
events = graph.stream(..., config, stream_mode="values")
注意啊,config是第二个参数,位置不能错。传进去之后,图就知道该去哪找之前的快照,而不是从头开始。
运行聊天机器人
运行命令:
uv run 3-add-memory.py
你会看到输出长这样:
设置对话线程 ID = '1'...
示例 1: 第一次对话 - 用户介绍自己
用户输入: 'Hi there! My name is Will.'
...
Assistant:
Hi Will! It's great to meet you. How can I assist you today?
示例 2: 第二次对话 - 测试记忆功能
用户输入: 'Remember my name?'
...
Assistant:
Of course, Will! I’ll remember your name for the rest of our conversation.
示例 3: 新对话线程 - 测试线程隔离
用户输入: 'Remember my name?'
...
Assistant:
I don’t have the ability to remember personal details like names between interactions.
示例 4: 返回第一个线程 - 验证记忆持久性
用户输入: 'Remember my name?'
...
Assistant:
Got it, Will! I’ll keep your name in mind while we chat.
你看:
- 同一个线程 ID,第二次还能叫出“Will”;
- 换个 ID,立马变脸不认人;
- 回到原来的 ID,记忆还在,没丢。
这就是线程级记忆的威力。
LangGraph 中 thread_id(线程 ID)的隔离原理
在 LangGraph 中,thread_id(线程 ID)的隔离能力核心依赖「检查点(Checkpointer)」的状态分区机制——简单说:thread_id是状态的「唯一索引」,不同thread_id对应独立的对话状态存储,彼此互不干扰。
简单记:LangGraph 的 thread_id 管 “对话记忆”,和 Python “并发干活”的线程 ID ,八竿子打不着。
核心原理:
Checkpointer(这里用的是MemorySaver)会把所有对话状态,按照thread_id进行「分区存储」—— 不同thread_id的状态存在完全独立的「命名空间」里,彼此不会覆盖或混淆。可以把它想象成「文件柜」:
Checkpointer = 一个文件柜thread_id = 文件柜里的「抽屉编号」- 每个抽屉(
thread_id)里存放对应对话的状态(messages 等)
- 打开抽屉时,只能看到当前
thread_id 下的文件(状态),看不到其他抽屉的内容
关键逻辑:状态的「存储」与「读取」都绑定thread_id
- 存储时:流程执行后,
Checkpointer 会把更新后的 state 与传入的 thread_id 绑定,存入对应分区;
- 读取时:下次调用流程传入相同
thread_id,Checkpointer 会自动加载该分区下的历史状态,继续推进对话;
- 隔离时:不同
thread_id 对应不同分区,加载状态时只会读取自己分区的内容,自然实现隔离。
小结
没记忆的AI,就像断片的人,聊一句忘一句。加了MemorySaver,它就开始记事了,能维持上下文,像个正常人聊天。
我们用了三个核心东西:
MemorySaver:内存存状态,开发够用;thread_id:区分不同用户的对话流;checkpointer:让图自动保存和恢复。
这三个组合起来,才算真正迈进了多轮对话的大门。面试官要是问你怎么做上下文管理,你就拿这套流程怼上去。流程:读历史 → 推理 → 工具调用 → 保存状态。一次完整带记忆的交互。
LangGraph 常见陷阱和解决方案
工具调用失败?三个坑别踩
问题在哪?LLM 没调工具,或参数乱传,功能直接“瘫痪”。
怎么解决?记住三件事:
状态数据丢了?别乱覆盖!
问题在哪?一更新状态,别的字段变 None?你可能“顺手删了”不该删的。
怎么解决?只返回你要改的字段!就像换灯泡,不用拆房子。
# 错误:清空了其他字段
def bad_node(state):
return {
"field_a": "new_value",
"field_b": None # 这会覆盖原有值
}
# 正确:只更新需要的
def good_node(state):
return {
"field_a": "new_value" # 其他字段原样保留
}
对话历史没了?别手动替换!
问题在哪?AI 忘事?因为你把messages列表整个替换了,历史全丢。
怎么解决?不要赋新列表,而是“追加”消息。只要字段用了Annotated[..., add_messages],框架自动帮你接在后面。
# 错误:清空历史
def bad_node(state):
new_message = AIMessage(content="回答")
return {"messages": [new_message]} # 历史没了
# 正确:自动追加
def good_node(state):
new_message = AIMessage(content="回答")
return {"messages": [new_message]} # 接到末尾
就像微信群聊,你是发一条新消息,不是把聊天记录全删了重写。
如何调试和诊断
1. 状态追踪:出问题?先打印看看
问题在哪?不知道状态哪一步变了,查 bug 全靠猜。
怎么解决?加个打印节点,进来看输入,出去看输出,一目了然。
def debug_node(state):
print(f"进入节点时的状态: {state}")
result = {"new_field": "value"}
print(f"节点返回: {result}")
return result
复杂流程建议临时加几个,跑一遍就知道卡在哪。
2. 工具没调用?先看 LLM 有没有“想调”
问题在哪?工具没反应,到底是模型没决策,还是后续断了?
怎么解决?第一步:打印生成结果,看有没有tool_calls。没有?说明 AI 根本没打算调——要么 prompt 不够强,要么工具描述太模糊。
def generate_response(state):
generation = llm_with_tools.invoke([...])
print(f"LLM回复内容: {generation.content}")
print(f"是否有工具调用: {hasattr(generation, 'tool_calls')}")
if hasattr(generation, 'tool_calls'):
print(f"工具调用详情: {generation.tool_calls}")
return {"generation": generation.content, "messages": [generation]}
3. 流程卡住了?检查图结构!
问题在哪?跑着跑着不动了?可能是节点连错了,或者成了“孤岛”。
怎么解决?上线前做一次图连通性检查:
- 每个节点都有入口(除了起点)
- 每个节点都有出口(除了终点)
- 没有孤立无用的节点
就像电路通电前测通断——提前发现90%的硬伤。
LangGraph总结与展望
通过这个教程,我们从零造出一个能聊、能查、能记事的聊天机器人。一开始它只会回话,后来学会了查资料、记事情,还能同时跟好几个人聊不串台。整个过程像搭积木,一步接一步,核心靠的就是LangGraph—— 它像个智能调度员,把各个功能串起来,让机器人真正“活”了起来。
我们搞清了五件事:
- LangGraph 是怎么工作的? 对话像流水线,每个环节是“节点”(比如理解问题、调工具),用“边”连执行顺序,“状态”带着数据一路传。结构清晰,逻辑可控。
- 上下文怎么记住? 用户说“改成后天”,机器人得知道改的是之前的订票。靠统一的状态管理,每次更新“记忆容器”,让它像人一样记得前因后果。
- 怎么让它会用工具? 遇到不会的问题,就去搜——我们接了搜索引擎。只要提前配置:“这类问题找这个工具”,它就能主动动手解决。
- 跨会话记忆怎么实现? 第一次说“我叫小王”,下次还能认出你。不是魔法,是给每个用户存独立状态,相当于给机器人配了个小本本,见面就翻记录。
- 多人聊天不串台? 靠“线程ID”区分不同用户。系统按ID加载对应状态,就像服务员看号码牌服务,张三的问题不会被李四听到。
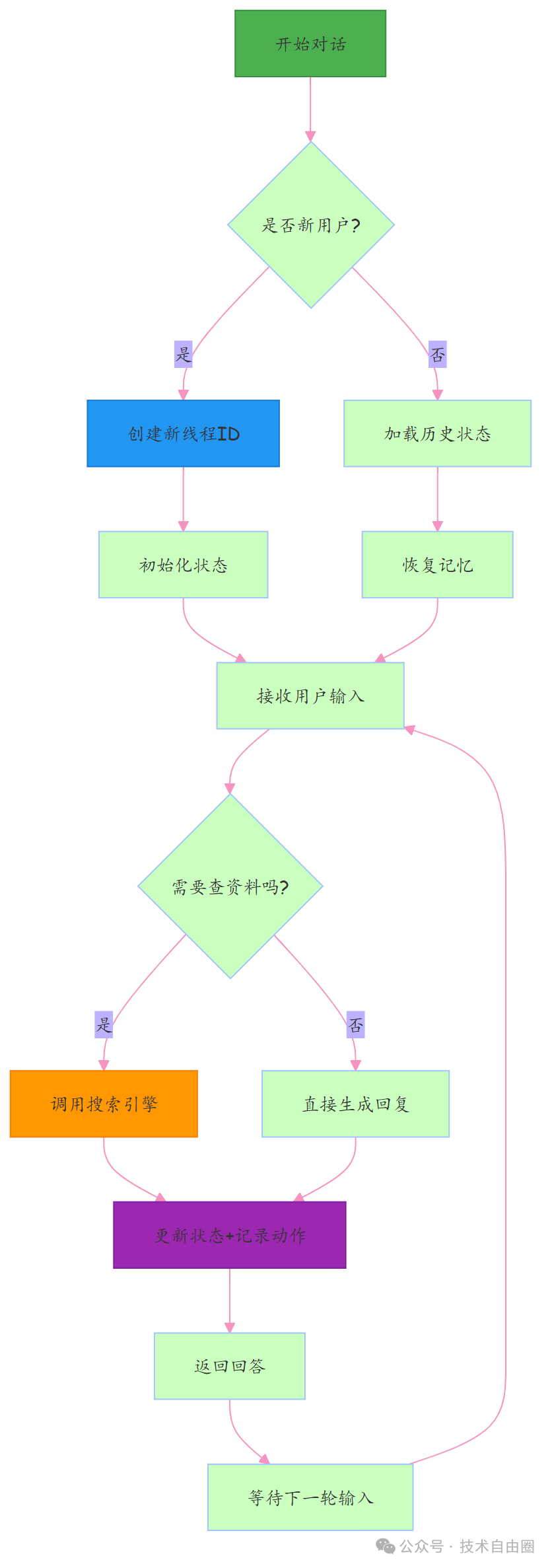 图解:识别身份 → 加载记忆 → 判断是否需查资料 → 更新状态并回复。颜色代表:初始化(绿)、线程处理(蓝)、工具执行(橙)、状态操作(紫),数据流向一目了然。
图解:识别身份 → 加载记忆 → 判断是否需查资料 → 更新状态并回复。颜色代表:初始化(绿)、线程处理(蓝)、工具执行(橙)、状态操作(紫),数据流向一目了然。
LangGraph 展望
痛点:现在机器人还是“本地玩具”:记忆一重启就丢、不能协作、也没安全机制,离上线还差得远。
以 LangGraph 状态机为核心,扩展持久化、协同和人工干预能力,升级成可落地的AI系统。
下一步可以深挖这些方向:
- 长期记忆落地:当前状态存在内存里,重启全丢。应该接入 Redis 或 PostgreSQL,实现持久存储——把便签本换成保险柜。
- 关键操作让人把关:转账、发布等敏感操作,不让AI自己决定。流程暂停,等人确认再继续,实现“人在回路”的安全兜底。
- 多个AI组队干活:一个干不过来?那就组团。比如一个接待、一个查资料、一个写报告。用 LangGraph 编排多个智能体协作,打造“AI员工团队”。
- 对话支持“撤销”:借助完整状态快照,能回到任意时刻,查看或修改中间步骤。就像加了个“Ctrl+Z”,调试优化超方便。
- 上生产环境扛高并发:本地跑得好,线上可能崩。要结合检查点 + 容器化部署,加上监控、容错、负载均衡,才能撑住真实流量。
LangGraph 正在飞速进化,功能越来越多。但万变不离其宗:用状态机管理AI流程。掌握了这一点,你就拿到了构建高级AI系统的钥匙。不管你是做企业客服、办公助手,还是玩AI项目,这套方法都通用。大模型越强,越需要有人来组织和调度它们——谁掌握编排,谁就掌握未来。
 发表于 2025-12-9 06:21:16
|
查看: 217|
回复: 0
发表于 2025-12-9 06:21:16
|
查看: 217|
回复: 0
