昨天还在看英伟达(NVIDIA)依靠GPU赚得盆满钵满,今天这位“AI教父”就带着一个足以改变数据中心市场格局的大招亮相了。
在刚刚结束的 GTC 2026 大会上,黄仁勋除了展示新一代显卡,更引人注目的是一款名为“Vera”的下一代数据中心CPU。并且,这次英伟达宣布将公开、独立地对外销售这款CPU,这无疑是对传统CPU巨头Intel和AMD的正面宣战。

说到CPU,这并不是英伟达的首次尝试。早在2022年,他们就推出了首款数据中心CPU Grace。不过,初代产品更像是为自家GPU服务的“配角”,并未在市场上独立掀起太大波澜。
而Vera的出现,标志着英伟达正式从“买GPU搭CPU”的模式,转向全面进军CPU市场,意图构建从计算、互联到内存的全栈式AI解决方案。这一转变将对整个智能 & 数据 & 云产业格局产生影响。

Vera CPU:为AI而生的性能怪兽
首先来看看Vera的核心规格。其底层架构代号为“Olympus”,基于Armv9.2-A指令集打造。它集成了多达88个英伟达完全自研的定制核心,并且每个核心都支持“空间多线程技术”,实现了88核176线程的顶级规格。
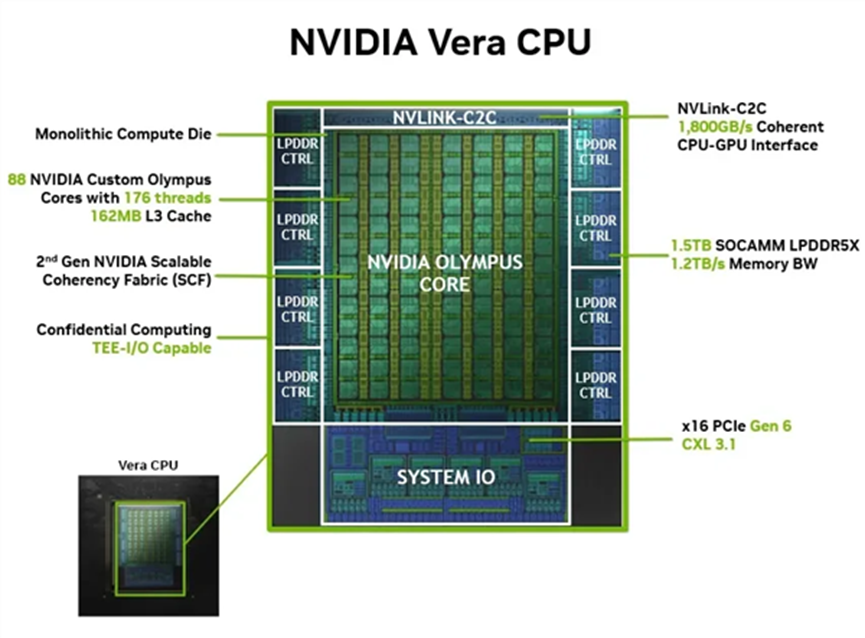
相较于上代Grace的72核144线程,Vera在核心规模上有了显著提升。但真正让其脱颖而出的是其极致的内存和互联性能。
在AI计算中,数据搬运的“带宽墙”常常是瓶颈。Vera采用了第二代低功耗内存子系统,将内存带宽提升至惊人的1.2 TB/s。同时,通过NVLink-C2C互连技术,Vera与GPU之间的数据一致性带宽进一步提升到1.8 TB/s——这已经是PCIe 6.0带宽的7倍之多。
凭借这些优化,英伟达宣称Vera的IPC性能(每周期指令数)比上代Grace提升了1.5倍。在处理特定的大规模数据和AI任务时,其整体性能比标准架构CPU快50%,同时能效翻倍,功耗减半。

如果说单颗Vera CPU的威力还不够直观,那么基于MGX架构的Vera机架系统(可以理解为“超大杯”)则展现了其真正的野心。

单个机柜可集成256颗Vera CPU,总计22528个核心和45056线程。这套系统配备了最高400TB的LPDDR5X内存,总带宽高达300TB/s,并采用纯液冷散热。这样的设计,目标直指最高密度和效率的数据中心。
为何GPU巨头要杀入CPU战场?
一个显而易见的疑问是:英伟达在GPU领域已是绝对霸主,为何还要涉足竞争激烈的CPU市场?
这背后是AI技术范式的变迁。早期的AI大模型训练,主要依赖“大力出奇迹”,堆叠GPU算力即可,CPU主要负责任务调度和数据传输等辅助工作。
但未来属于智能体AI。在GTC 2026上,黄仁勋反复强调了这一点。未来的AI不仅需要强大的“计算”能力,更需要具备“思考、规划、自我纠错、调用外部工具”等复杂逻辑能力。

而这些复杂的逻辑控制、多并发任务处理,恰恰是CPU的传统强项。换言之,如果CPU性能成为瓶颈,GPU算力再强也无法完全释放。
英伟达的思路很清晰:构建一个从CPU到GPU,再到网络和存储的全栈优化平台。不让任何一环(尤其是来自竞争对手的环节)拖累自家GPU的性能。Vera的出现,正是为了补全其AI数据中心版图的最后一块关键拼图。

对Intel和AMD的冲击与Arm生态的崛起
这波操作,无疑让在数据中心市场“相爱相杀”多年的Intel和AMD感到压力。当两家还在x86架构内激烈竞争时,一个来自GPU领域的“降维打击”已然到来。

Vera最深远的影响在于,它标志着Arm架构在高端数据中心市场真正站稳了脚跟。过去,Arm架构常与移动设备、轻量级服务器关联。而Vera以其恐怖的能效比和内存带宽证明:在AI与大模型时代,经过深度定制的Arm架构完全有能力在性能上正面对抗传统x86。这对于学习计算机基础的开发者而言,也意味着技术格局的演变。
更关键的是,英伟达并非“纸上谈兵”。据报道,Vera CPU目前已进入全面量产阶段,计划于今年下半年开始交付。包括Meta、甲骨文、字节跳动、阿里等头部科技公司均已出现在其合作客户名单中。

当这些大客户发现,采用英伟达全栈方案(CPU+GPU)的AI集群在性能、功耗和空间效率上更具优势时,传统x86 CPU的市场份额面临被侵蚀的风险。
结语
英伟达Vera CPU的独立发布,不仅是一款新产品的问世,更是一次清晰的战略宣言。它意味着英伟达不再满足于只做AI计算的“加速器”,而是要成为整个AI基础设施的“定义者”和“构建者”。
从Grace到Vera,英伟达正在将其在GPU和AI软件生态上的领先优势,向更底层的CPU和系统架构延伸。这无疑将加剧数据中心处理器市场的竞争,同时也将加速以AI为中心的硬件设计理念普及。对于整个行业和广大开发者广场的从业者来说,一个由异构计算和全栈优化主导的新时代正加速到来。
*资料、图片来源:GTC 2026、NVIDIA、网络。
 发表于 2026-3-20 03:56:36
|
查看: 260|
回复: 0
发表于 2026-3-20 03:56:36
|
查看: 260|
回复: 0
