记忆系统是智能体的认知核心——它决定了智能体如何感知世界、存储经验、形成知识,并最终拥有一个连贯的、持续的“自我”。
上下文工程的实践揭示了一个深刻的事实:上下文即记忆。我们为模型提供的每一个Token,无论是用户的指令、工具的输出,还是历史对话,本质上都是在向其“喂养”一段临时的记忆。然而,一个真正智能的系统,不能只依赖于这种短暂、易失的“工作记忆”。它需要一个像人脑一样,分层、高效、能够进行长期存储和智能检索的复杂记忆系统。
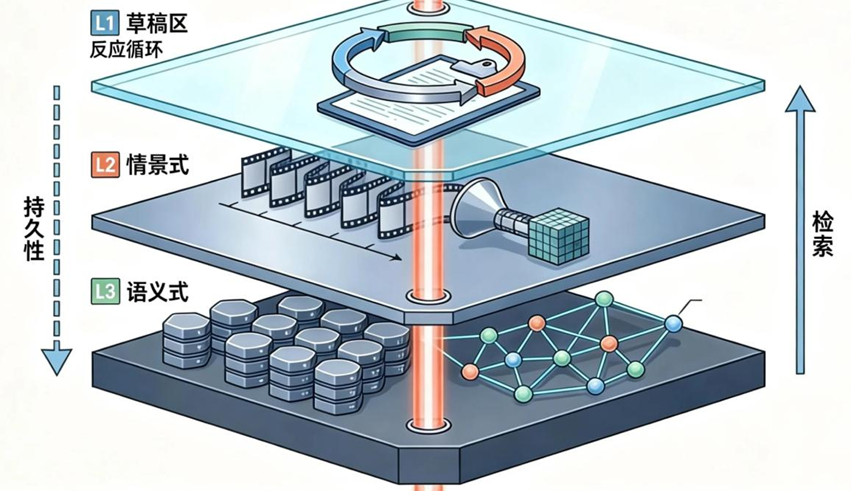
借鉴认知科学和计算机体系结构的灵感,我们可以提出一个三层记忆模型,分别是:
- L1 记忆:瞬时工作记忆(Scratchpad)——智能体当前任务的“草稿纸”,用于高速读写和推理。
- L2 记忆:情景记忆(Episodic Memory)——智能体交互历史的“录像带”,用于回溯和复盘。
- L3 记忆:语义记忆(Semantic Memory)——智能体长期知识的“知识库”,通过RAG和向量数据库实现。
这三层记忆协同工作,构成了智能体完整的认知循环。
L1 记忆:瞬时工作记忆(Scratchpad)
在三层记忆模型中,L1记忆是离模型计算核心最近、速度最快的一层。它是在单次任务执行期间,供智能体进行思考、规划和状态跟踪的瞬时工作记忆。在上下文工程的实践中,这一层通常被称为“草稿纸”(Scratchpad)。
1、L1记忆的本质:模型上下文窗口的动态应用
L1记忆的物理载体,就是大模型的上下文窗口本身。它不是一个外部系统,而是对模型核心能力的一种动态应用。它的核心特性可以类比于计算机CPU的高速缓存(L1 Cache)或我们人类在解决一个数学问题时使用的草稿纸:
- 高速读写:信息被直接写入Prompt,模型可以在一次推理中立即访问,读写速度只受限于模型的推理速度。
- 容量有限:其总容量受限于模型上下文窗口的大小。草稿纸写得越长,留给其他类型上下文(如用户指令、工具定义)的空间就越小。
- 任务期易失性:L1记忆是为当前任务服务的。一旦任务完成(或失败),草稿纸上的内容通常就会被丢弃,不用于跨任务的长期记忆。
L1记忆的核心作用,是为模型的推理过程提供一个可读、可写、可回溯的“思维轨迹”。它将模型“脑中”不可见的思考过程,外化(Externalize)为上下文中可见的文本,从而极大地增强了复杂任务的可控性和可靠性。
2、ReAct循环:L1记忆的核心读写机制
L1记忆最经典的读写机制,就是ReAct(Reason + Act) 框架。ReAct的“思考-行动-观察”循环,本质上就是一套在草稿纸上进行结构化读写的流程。
让我们从L1记忆的视角来解读这个循环:
- 初始状态:L1记忆(草稿纸)的初始内容通常是用户的目标和可用的工具列表。
- 写入思考(Write Thought):模型根据当前L1记忆中的全部内容,进行第一步推理,并将这个推理过程(Thought)作为一个结构化的文本块,追加到L1记忆的末尾。
- 写入行动(Write Action):基于刚刚的思考,模型决定执行一个动作(Action),并将这个代表行动意图的文本(如一个Tool Call),同样追加到L1记忆中。
- 写入观察(Write Observation):外部执行器(Agent Runtime)解析Action,调用相应的工具,并将工具返回的结果(Observation),追加到L1记忆的末尾。
- 循环迭代:此时,L1记忆已经变得更长,包含了第一轮“思考-行动-观察”的完整轨迹。模型在下一次推理时,会看到这个完整的轨迹,并在此基础上进行第二轮的思考。这个过程不断重复,直到任务完成。
通过这种持续追加(Append-Only)的模式,L1记忆(草稿纸)完整地记录了智能体为了达成目标而进行的每一步尝试、每一次工具调用和每一次结果观察。它就像一份详尽的“探案笔记”,让模型在任何一步都知道自己从哪里来,到过哪里,看到了什么。
3、L1记忆的最佳实践
要高效、可靠地使用L1记忆,需要遵循一些关键的最佳实践。
3.1 使用结构化分隔符
由于L1记忆是纯文本的,使用清晰、一致的结构化分隔符(如XML标签)至关重要。这能帮助模型更好地区分不同类型的信息,降低解析错误的概率。
反模式:使用非结构化、无分隔的思考记录。
1 我的想法是我应该寻找天气。然后我会用“旧金山的天气”来调用搜索工具。
2 工具返回:75度,阳光明媚。
3 现在我可以回答用户了。
最佳实践:使用明确的XML标签进行结构化。
<scratchpad>
<thought>我需要找到旧金山的天气来回答用户的问题。我将为此使用搜索工具。</thought>
<action><tool_name>search</tool_name><parameters><query>旧金山的天气</query></parameters></action>
</scratchpad>
<observation>旧金山的天气是75度,阳光明媚。</observation>
<scratchpad>
<thought>我有天气信息。我现在可以为用户制定最终答案。</thought>
<action><tool_name>final_answer</tool_name><parameters><text>旧金山的天气目前是75度,阳光明媚。</text></parameters></action>
</scratchpad>
3.2 坚持“仅追加”原则
在一次任务的生命周期内,L1记忆应该是仅追加(Append-Only)的。绝对不要在新的推理步骤中去修改或删除历史记录。这不仅破坏了思维轨迹的完整性,也可能让模型感到“困惑”。一个不可变的、线性的历史记录,是模型进行可靠推理的基础。
3.3 L1记忆的“垃圾回收”:向L2/L3的沉淀
L1记忆最大的挑战在于其有限的容量。在处理长周期、多步骤的复杂任务时,草稿纸会迅速膨胀,最终超出上下文窗口的限制。因此,一个成熟的记忆系统必须具备将L1记忆“垃圾回收”(Garbage Collection)或“沉淀”(Precipitation)到更深层记忆的能力。
这个过程本身,也可以由一个更高阶的“元认知Agent“来完成。例如,当L1记忆超过一定阈值时,系统可以触发一个特殊任务,指令如下:
“指令:请总结以下的‘草稿纸’内容,提取出与用户长期偏好、关键事实或成功/失败经验相关的核心信息,并将其结构化地存入L2情景记忆或L3语义记忆。”
这个“总结与沉淀”的过程,正是连接不同记忆层级的桥梁,也是智能体实现长期学习和成长的关键。
L2 记忆:情景记忆(Episodic Memory)
如果说L1记忆是智能体用于解决当前问题的“草稿纸”,那么L2记忆则是记录其过去所有经历的“日志”或“录像带”。在认知科学中,这被称为情景记忆(Episodic Memory),它存储的是关于特定事件、对话和交互的自传式信息——“我(智能体)在何时、何地、与谁、做了什么、结果如何?”。
L2记忆是连接瞬时工作记忆(L1)和长期知识(L3)的关键桥梁。它为智能体提供了自我反思、从经验中学习以及在长时间跨度上保持对话连贯性的能力。
1、L2记忆的本质:结构化的交互历史
L2记忆的核心,是对智能体与用户或其他智能体之间交互历史的持久化存储。与L1记忆的纯文本“草稿纸”不同,L2记忆通常以更结构化的方式存储,以便于后续的检索和分析。一个典型的情景记忆单元(一个”Episode”)至少应包含以下元数据:
- 时间戳(Timestamp):交互发生的时间。
- 参与方(Participants):参与这次交互的用户或智能体ID。
- 会话ID(Session ID):标识这次交互所属的会话或任务。
- 交互内容(Content):完整的交互记录,包括用户输入、智能体的思考过程(L1草稿纸的快照)、工具调用、观察结果以及最终输出。
- 事件标签(Event Tags):用于描述该事件关键特征的标签,如#user_feedback, #task_success, #api_error等。
这种结构化的存储,使得L2记忆库不再是一个杂乱的聊天记录,而是一个可以被精确查询和分析的“经验数据库”。
2、L2记忆的实现机制
L2记忆的实现,关键在于如何高效地存储和管理日益增长的交互历史。由于对话历史可能非常长,直接将其全部塞入L1上下文窗口是不可行的。因此,必须采用“压缩”和“摘要”的策略。
- 滑动窗口(Sliding Window):最简单的方法是只保留最近的N轮对话。这种方法实现简单,但缺点是会完全丢失早期的重要信息。
- 令牌长度限制(Token Length Limit):按Token总长度来限制历史记录的大小。它会从对话历史的开头开始,不断删除旧的交互,直到总Token数小于设定的阈值。这比滑动窗口更灵活,但同样会丢失早期信息。
- 摘要化(Summarization):为了在保留长期信息的同时控制上下文长度,摘要化是一种更高级的策略。它通过调用LLM自身,来逐步地、滚动地对对话历史进行总结。
摘要化工作流示例:
- 初始状态:L2记忆为空。
- 交互1-5:完整地存储在缓冲区中。
- 交互6:当缓冲区满时,触发摘要任务。调用LLM:”请总结以下对话:[交互1-5的内容]“。
- 生成摘要1:LLM返回摘要S1。
- 更新L2:L2记忆现在包含摘要S1和最新的交互6。
- 交互7-10:继续添加到缓冲区。
- 交互11:缓冲区再次满。调用LLM:”已知之前的摘要是[S1],请结合以下新对话[交互6-10的内容],生成一个新的、更全面的摘要。“
- 生成摘要2:LLM返回更新后的摘要S2。
这个过程不断持续,确保了无论对话多长,总有一个相对紧凑的摘要来代表完整的历史背景。
3、L2记忆的作用:从经验中学习
L2情景记忆不仅仅是为了维持对话的连贯性,它更是智能体实现自我反思和从经验中学习的基础。通过对L2记忆库的分析,智能体可以:
- 优化失败的任务:当一个任务失败时,智能体可以“复盘”L2中记录的完整L1草稿纸,分析是哪一步的思考或行动出了问题,并在下一次遇到类似任务时避免犯同样的错误。
- 提取用户偏好:通过分析与特定用户的长期交互历史,智能体可以总结出该用户的沟通风格、兴趣偏好、常用工具等,从而提供更具个性化的服务。这些总结出的偏好,可以被进一步沉淀到L3语义记忆中。
- 构建Few-Shot示例:成功的任务交互记录,是构建高质量Few-Shot示例的绝佳素材。当遇到新任务时,智能体可以从L2记忆中检索出最相似的成功案例,并将其作为示例放入L1上下文中,以引导模型更好地完成任务。
4、最佳实践:基于LangChain官方文档的消息摘要实现
本节将基于LangChain官方文档提供的代码示例,展示如何实现L2情景记忆的消息摘要功能。
4.1 使用SummarizationMiddleware
LangChain提供了内置的SummarizationMiddleware中间件来自动处理消息摘要:
# 来源: LangChain官方文档 https://docs.langchain.com/oss/python/langchain/short-term-memory
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
# 创建摘要中间件
# max_messages: 保留的最大消息数
# max_tokens: 摘要的最大token数
summarization = SummarizationMiddleware(
max_messages=10, # 当消息超过10条时触发摘要
max_tokens=500 # 摘要的最大长度
)
agent = create_agent(
"gpt-4.1-mini",
tools=[],
middleware=[summarization], # 使用摘要中间件
checkpoint=InMemorySaver(),
)
# 运行agent, 消息会自动被摘要管理
result = agent.invoke(
{"messages": [{"role": "user", "content": "Hello, my name is Alice"}]},
{"configurable": {"thread_id": "1"}}
)
4.2 使用LangGraph Store实现长期记忆存储
对于需要跨会话持久化的情景记忆,可以使用LangGraph的Store机制:
# 来源: LangChain官方文档 https://docs.Langchain.com/oss/python/langchain/long-term-memory
from langgraph.store.memory import InMemoryStore
def embed(texts: list[str]) -> list[list[float]]:
# 替换为实际的embedding函数或langChain embeddings对象
return [[1.0, 2.0] * len(texts)]
# InMemoryStore将数据保存到内存字典中。生产环境请使用数据库支持的store。
store = InMemoryStore(index={"embed": embed, "dims": 2})
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
# 存储一条情景记忆
store.put(
namespace,
"episode-001", # 情景ID
{
"timestamp": "2026-02-04T10:30:00Z",
"summary": "用户询问了关于夏威夷旅行的建议",
"key_facts": [
"用户名字是Alice",
"计划去夏威夷旅行",
"对冲浪和当地美食感兴趣",
],
},
)
# 按ID获取情景记忆
item = store.get(namespace, "episode-001")
# 在命名空间内搜索记忆,按向量相似度排序
items = store.search(
namespace,
query="夏威夷旅行建议" # 语义搜索
)
4.3 在工具中读取情景记忆
# 来源: Langchain官方文档 https://docs.langchain.com/oss/python/langchain/long-term-memory
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.tools import tool, ToolRuntime
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
store = InMemoryStore()
# 预先写入一些情景记忆
store.put(
("episodes",), # 命名空间
"user_123_ep_001", # 情景ID
{
"summary": "用户讨论了AI项目的记忆系统设计",
"timestamp": "2026-02-03T14:00:00Z",
}
)
@tool
def recall_past_episodes(query: str, runtime: ToolRuntime[Context]) -> str:
"""回忆与查询相关的过去情景"""
store = runtime.store
user_id = runtime.context.user_id
# 搜索相关的情景记忆
episodes = store.search(
("episodes",),
query=query,
filter={"user_id": user_id} # 可选: 按用户过滤
)
if episodes:
return f"找到相关记忆: {[ep.value for ep in episodes]}"
return "没有找到相关的过去记忆"
agent = create_agent(
model="gpt-4.1-mini",
tools=[recall_past_episodes],
store=store,
context_schema=Context
)
# 运行agent
agent.invoke(
{"messages": [{"role": "user", "content": "我之前和你讨论过什么?"}]},
context=Context(user_id="user_123")
)
4.4 从工具写入情景记忆
#来源:LangChain官方文档 https://docs.langchain.com/oss/python/langchain/Long-term-memory
from dataclasses import dataclass
from typing_extensions import TypedDict
from datetime import datetime
from langchain.agents import create_agent
from langchain.tools import tool, ToolRuntime
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
@dataclass
class Context:
user_id: str
class EpisodeInfo(TypedDict):
summary: str
key_facts: list[str]
@tool
def save_episode(episode_info: EpisodeInfo, runtime: ToolRuntime[Context]) -> str:
"""保存当前对话的情景记忆"""
store = runtime.store
user_id = runtime.context.user_id
# 生成唯一的情景ID
episode_id = f"{user_id}_ep_{datetime.now().strftime('%Y%m%d%H%M%S')}"
# 存储情景记忆
store.put(
("episodes",),
episode_id,
{
"timestamp": datetime.now().isoformat(),
"user_id": user_id,
**episode_info,
}
)
return f"情景记忆已保存, ID: {episode_id}"
agent = create_agent(
model="gpt-4.1-mini",
tools=[save_episode],
store=store,
context_schema=Context
)
# 运行agent保存情景
agent.invoke({
"messages": [{"role": "user", "content": "请记住我们今天讨论了AI记忆系统"}]
},
context=Context(user_id="user_123")
)
# 直接访问store获取保存的值
print(store.search(("episodes",), query="AI记忆系统"))
这种“摘要+持久化存储”的混合策略,是目前在长对话场景中平衡上下文长度和信息保真度的最佳实践之一。它确保了智能体既不会忘记对话的开端,也能清晰地记得最近的细节,从而实现真正连贯和智能的长期交互。
L3 记忆:语义记忆(Semantic Memory)
L1和L2记忆解决了智能体“如何思考”和“经历过什么”的问题,但一个真正智能的实体,还需要一个关于世界事实、概念和规则的庞大知识库。这便是L3记忆,即语义记忆(Semantic Memory)。它存储的不是个人经历,而是关于世界的、普遍的、抽象的知识,例如“巴黎是法国的首都”、“水在100摄氏度时沸腾”或者“公司内部规定,超过1000元的报销需要主管审批”。
L3记忆是智能体知识能力的基石。它让智能体能够超越其有限的交互经验,利用全人类或特定领域的知识来回答问题、做出决策。在上下文工程中,L3语义记忆几乎总是通过检索增强生成(Retrieval-Augmented Generation, RAG)来实现的。
1、L3记忆的本质:外部化的、可检索的知识库
与内置于模型参数中的“隐性知识”不同,L3语义记忆是一种外部化的、显性的知识存储。它的核心思想是将知识与模型本身解耦,存放在一个独立的、可随时更新和查询的外部数据库中。这个数据库,通常就是向量数据库。
L3记忆的工作流程,就是经典的RAG流程:
- 知识注入(Ingestion):将原始的知识文档(如PDF、网页、数据库记录)进行分块(Chunking),然后通过一个嵌入模型(Embedding Model),将每个文本块转换成一个高维的数学向量(Embedding)。这些向量代表了文本块的语义含义。
- 向量存储(Storage):将这些文本块及其对应的向量,存储在向量数据库中,并建立索引。
- 实时检索(Retrieval):当用户提出问题时,首先将用户的问题也转换成一个查询向量。然后,在向量数据库中进行相似度搜索,找出与查询向量在语义上最接近的N个文本块。
- 上下文增强(Augmentation):将这些检索到的文本块,作为上下文信息,连同用户的原始问题,一起注入到LLM的Prompt中。
- 生成答案(Generation):要求LLM基于提供的上下文来生成答案,而不是仅仅依赖其内部知识。
通过这个流程,L3记忆为智能体提供了一个可无限扩展、可实时更新、且内容完全可控的“外部大脑”。
2、L3记忆的核心技术栈
构建一个高效的L3记忆系统,需要一个精心设计的技术栈。
2.1 向量数据库:语义检索的核心
向量数据库是L3记忆的心脏。与传统数据库基于关键词匹配不同,向量数据库通过计算向量之间的距离(如余弦相似度)来进行搜索,能够真正理解“语义相关性”。例如,用户搜索“美国最高的山”,它能够检索到包含“麦金利峰”的文档,即便查询中并未出现这个词。
市面上有多种成熟的向量数据库可供选择,包括开源的(如FAISS, Chroma, Weaviate)和商业化的(如Pinecone, Zilliz)。它们提供了高效的向量索引和检索能力,是构建L3记忆系统的基础。
2.2 RAG vs. 微调:正确的知识更新姿势
当需要向模型注入新知识时,开发者常常面临一个选择:是通过RAG(更新L3记忆)还是通过微调(Fine-tuning,更新模型参数)?
| 特性 |
检索增强生成(RAG) |
微调(Fine-tuning) |
| 知识更新 |
实时、低成本。只需更新向量数据库。 |
周期性、高成本。需要重新训练模型。 |
| 事实准确性 |
高。答案基于检索到的、可验证的原文。 |
中等。仍可能产生幻觉。 |
| 可追溯性 |
强。可以明确指出答案来源。 |
弱。无法解释答案的具体来源。 |
| 能力学习 |
弱。主要用于注入“事实性”知识。 |
强。可以教会模型新的“技能”或“风格”。 |
| 适用场景 |
需要频繁更新知识、对事实准确性要求高的场景。 |
需要让模型学习特定行为模式、语言风格或复杂推理逻辑的场景。 |
在上下文工程的最佳实践中,RAG和微调并非互斥,而是互补的。RAG负责“知识”,微调负责“能力”。对于需要频繁更新的领域知识、产品文档、公司规定等,RAG是最佳选择。而对于需要模型掌握一种新的说话方式或推理范式(如学会遵循特定的ReAct格式),微调则更为合适。
2.3 知识图谱:超越向量的结构化记忆
尽管向量数据库在语义检索上表现出色,但它存储的仍然是独立的文本块,缺乏对知识之间关系的表达。为了构建更深层次的理解,知识图谱(Knowledge Graph)正在成为L3记忆的一个重要补充。
知识图谱将知识存储为“实体-关系-实体”(Subject-Predicate-Object)的三元组,形成一个巨大的关系网络。例如:
- (Elon Musk, is-a, Person)
- (Elon Musk, founder-of, SpaceX)
- (SpaceX, develops, Starship)
将知识图谱与RAG结合,可以实现更强大的“多跳推理”。当用户问“马斯克公司的火箭叫什么名字?”时,系统可以在图谱中进行关系推理,最终得出答案。这种基于关系推理的能力,是单纯的向量检索难以实现的。像Neo4j这样的图数据库,结合LangChain等框架,使得构建“知识图谱记忆”成为可能,为智能体提供了从“相关性”到“因果性”的认知飞跃。
3、L3记忆的构建与维护
构建和维护一个高质量的L3记忆库,是一个持续的、系统性的工程。
- 知识源管理:明确L3记忆需要覆盖哪些知识领域,并建立与这些知识源(如Confluence、SharePoint、数据库)的自动同步机制。
- ETL管道:建立一套稳健的ETL(Extract, Transform, Load)管道,自动地从知识源提取数据,进行清洗、分块、向量化,并加载到向量数据库中。
- 检索策略优化:持续优化检索算法,例如通过混合搜索(Hybrid Search,结合关键词和向量搜索)、重排(Re-ranking)等技术,提升检索结果的准确性。
- 反馈闭环:建立一个反馈机制,让用户可以评价检索结果的质量。系统可以利用这些反馈来不断优化嵌入模型或检索算法。
4、最佳实践:基于LlamaIndex官方文档的RAG实现
本节将基于LlamaIndex官方文档提供的代码示例,展示如何为Agent构建L3语义记忆系统。
4.1 安装依赖
# 安装LlamaIndex和相关库
pip install llama-index llama-index-llms-openai
4.2 准备知识源
首先准备一些文档作为L3记忆的知识来源:
# 创建数据目录并下载示例文档
mkdir data
wget https://raw.githubusercontent.com/run-llama/llama-index/main/docs/examples/data/paul_graham/paul_graham_essay.txt -O data/paul_graham_essay.txt
4.3 构建带RAG能力的Agent
# 来源:LlamaIndex官方文档 https://docs.llamaindex.ai/en/stable/getting_started/starter_example/
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.agent.workflow import FunctionAgent
from llama_index.llms.openai import OpenAI
import asyncio
import os
# Create a RAG tool using LlamaIndex
# 加载文档并创建向量索引(这是L3记忆的核心)
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
def multiply(a: float, b: float) -> float:
"""Useful for multiplying two numbers."""
return a * b
async def search_documents(query: str) -> str:
"""Useful for answering natural language questions about an personal essay written by Paul Graham."""
response = await query_engine.aquery(query)
return str(response)
# Create an enhanced workflow with both tools
agent = FunctionAgent(
tools=[multiply, search_documents],
llm=OpenAI(model="gpt-4o-mini"),
system_prompt="""You are a helpful assistant that can perform calculations and search through documents to answer questions.""",
)
# Now we can ask questions about the documents or do calculations
async def main():
response = await agent.run(
"What did the author do in college? Also, what's 7 * 8?"
)
print(response)
# Run the agent
if __name__ == "__main__":
asyncio.run(main())
4.4 持久化RAG索引
为了避免每次重新处理文档,可以将索引持久化到磁盘:
# 来源: LlamaIndex官方文档
# https://docs.llamaindex.ai/en/stable/getting_started/starter_example/
# Save the index
index.storage_context.persist("storage")
# Later, load the index
from llama_index.core import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="storage")
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
4.5 添加对话历史
# 来源: LlamaIndex官方文档
# https://docs.llamaindex.ai/en/stable/getting_started/starter_example/
from llama_index.core.workflow import Context
# create context
ctx = Context(agent)
# run agent with context
response = await agent.run("My name is Logan", ctx=ctx)
response = await agent.run("What is my name?", ctx=ctx)
4.6 代码与L3记忆分析
这个官方示例完美地诠释了L3语义记忆的价值:
- 知识解耦:模型的推理能力(FunctionAgent)与知识本身(data目录中的文档)是分离的。你可以随时在目录中增加、修改或删除文档,然后重新运行索引构建,Agent就能立即获得更新后的知识,而无需重新训练或修改Agent代码。
- 减少幻觉:Agent的回答是基于从文档中检索到的真实文本,而不是仅仅依赖其内部知识。这使得它的回答更加可靠,并且具有可追溯性。
- 能力扩展:通过将RAG查询引擎包装成一个异步函数
search_documents,我们无缝地将整个L3记忆系统接入了Agent的工具集中。Agent现在不仅能“思考”,还能在思考过程中主动地去“查资料”。
- 持久化支持:通过
storage_context.persist(),索引可以被保存到磁盘,避免每次启动时重新处理文档,大大提升了生产环境的效率。
L3语义记忆,是智能体知识广度和深度的最终体现。它通过RAG、向量数据库和知识图谱等技术,为智能体构建了一个可扩展、可维护、可追溯的“外部大脑”,使其能够真正成为特定领域的专家。
至此,我们已经完整地剖析了L1、L2、L3三层记忆系统,并通过代码示例展示了如何使用主流框架来实现它们。这三层记忆协同工作,共同构成了AI智能体的认知核心,使其能够像人类一样,在瞬时思考、回顾过去和运用知识之间无缝切换。掌握了记忆系统的构建,我们就掌握了构建高级智能体的关键钥匙。希望这篇来自云栈社区的深度解析,能为你的AI项目带来启发。
 发表于 2026-3-20 09:23:00
|
查看: 134|
回复: 0
发表于 2026-3-20 09:23:00
|
查看: 134|
回复: 0
